

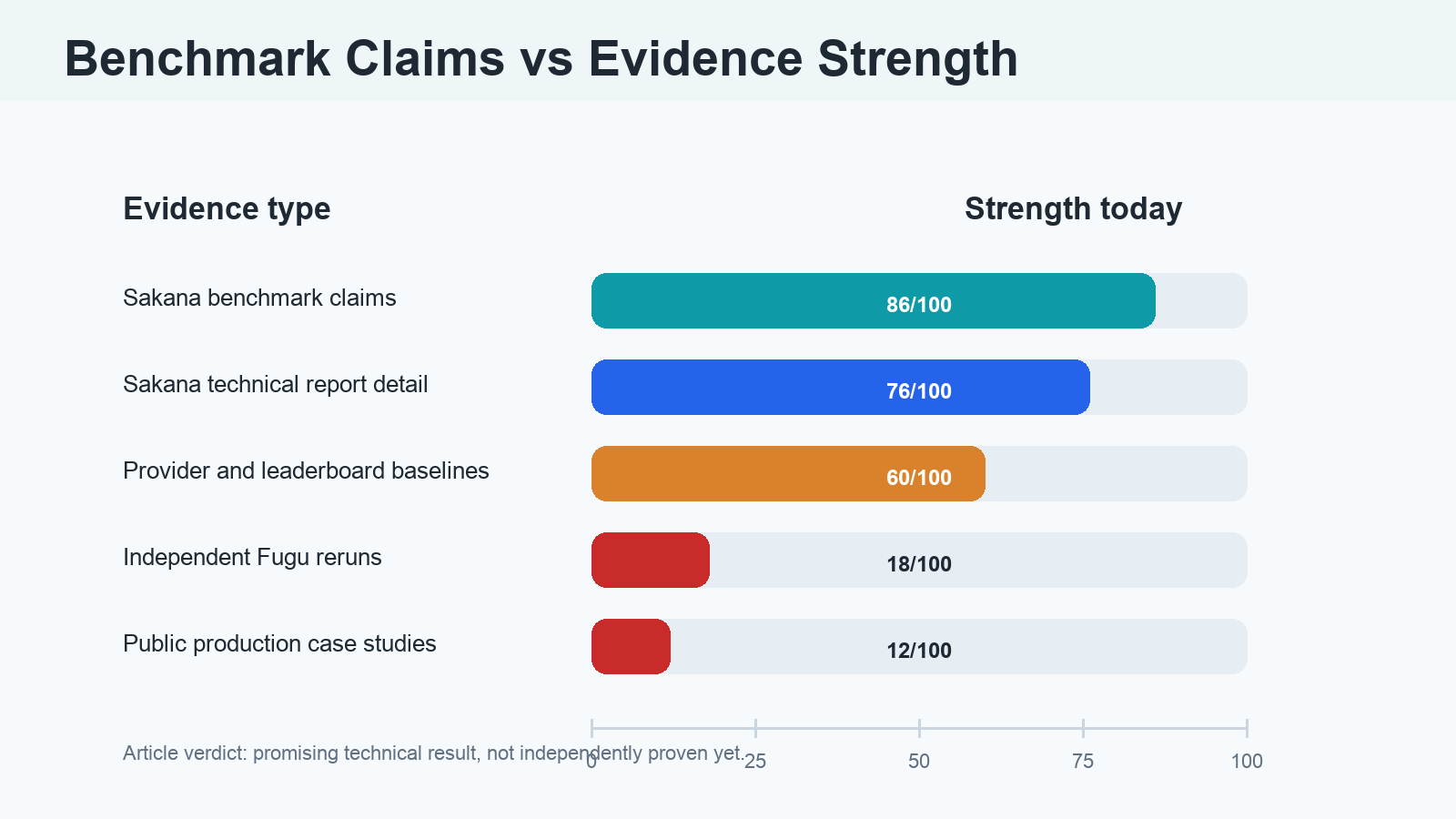
Short version: Sakana Fugu Ultra looks like a serious multi-agent orchestration result, not a normal model-launch hype cycle. But the evidence does not prove broad Fable 5 or Mythos 5 parity yet. The safest verdict is promising, benchmark-strong, and still unverified by broad independent testing.
Last updated: June 22, 2026. This investigation reviews Sakana’s official Fugu materials, the Fugu technical report, Anthropic’s Fable/Mythos system card, public benchmark sources, and available independent analysis.
Fast answer: Sakana AI has a serious technical result here. But the strongest fair verdict is not “proven frontier parity.” It is: Fugu Ultra looks promising, benchmark-strong, and strategically interesting, but the Fable/Mythos comparison is only partially supported and not yet independently verified.

Executive Summary
- What Sakana claims: Fugu Ultra uses learned orchestration to coordinate frontier model agents and reach Fable/Mythos-class benchmark performance on selected hard tasks.
- What the evidence supports: Fugu Ultra is very strong in Sakana’s official benchmark package, especially GPQA-Diamond, LiveCodeBench, and several agentic/coding evaluations.
- What remains unproven: broad independent reruns, production reliability, latency distribution, total cost per completed task, and direct apples-to-apples comparisons with Fable 5 and Mythos 5.
- Kingy verdict: evidence partially supports the claim. Fugu Ultra is worth testing, but not worth blindly replacing proven production workflows over benchmark charts alone.
Table Of Contents
- Fast Answer
- The Claim
- Benchmark Review
- Evidence For Sakana’s Claim
- Evidence Against Sakana’s Claim
- Is This Apples-to-Apples?
- Independent Evidence Review
- Should Businesses, Developers, and Creators Care?
- Final Verdict
- FAQ
- Sources
Fast Answer
Sakana’s official claim is that Sakana Fugu and Fugu Ultra use learned multi-agent orchestration to surpass publicly accessible frontier models on several hard benchmarks, and to sit “shoulder-to-shoulder” with Fable 5 and Mythos Preview on engineering, scientific, and reasoning evaluations.
That wording matters. The official Sakana page and technical report repeatedly compare against Fable 5 and Mythos Preview. The broader internet shorthand of “Fable 5 and Mythos 5” is a tougher claim, because Anthropic’s own Claude Fable 5 and Claude Mythos 5 system card reports very strong Mythos 5 results on several overlapping benchmarks.
The evidence supports this narrower statement: Fugu Ultra appears competitive with top frontier systems on selected official benchmarks, especially GPQA-Diamond, LiveCodeBench, and some agentic/coding evaluations.
The evidence does not yet prove the bigger statement: that a serious enterprise should treat Fugu Ultra as a fully validated replacement for Fable 5, Mythos 5, Claude, Gemini, OpenAI, Codex, or other production AI workflows.
Confidence rating: Plausible but unverified.
Final verdict: Evidence partially supports the claim. Fugu Ultra may be a real breakthrough in learned orchestration, but the safest conclusion is promising but not proven.
The Claim
The most important thing to separate is what Sakana explicitly claims from what readers may infer from benchmark charts.
| Claim | Evidence Available | Independent Verification? | Confidence |
|---|---|---|---|
| Fugu Ultra is a multi-agent orchestration system exposed through one API. | Sakana’s Fugu beta announcement, current Fugu page, and technical report describe a trained orchestrator that selects and coordinates frontier model workers. | Partially. External coverage has described the product, but this does not verify benchmark performance. | Well supported as a product description. |
| Fugu Ultra surpasses publicly accessible frontier baselines on several benchmarks. | The SakanaAI/fugu GitHub repository and technical report list results versus Opus 4.8, Gemini 3.1 Pro, and GPT-5.5. | Limited. Baseline scores are often provider-reported or from leaderboards; broad independent Fugu reruns are not yet visible. | Plausible but unverified. |
| Fugu Ultra is “shoulder-to-shoulder” with Fable 5 and Mythos Preview. | Sakana’s chart compares Fugu Ultra with Fable 5 and Mythos Preview where scores are available, and says those models are not in Fugu’s agent pool. | No broad independent Fugu-vs-Fable/Mythos rerun found at the time of writing. | Plausible but narrow. |
| Fugu Ultra matched or exceeded Mythos 5 overall. | This is not cleanly established by Sakana’s own wording. Anthropic’s system card reports Mythos 5 above Fugu Ultra on some overlapping benchmarks, including SWE-bench Pro, Terminal-Bench 2.1, and HLE. | No. | Unsupported as a broad claim. |
| Fugu Ultra’s benchmark gains prove real-world enterprise replacement value. | Sakana gives official benchmark and qualitative examples, including AutoResearch, kana reading order, Rubik’s Cube solver synthesis, CAD, and other tasks. | Not enough yet. Public case studies, developer reports, latency data, and failure-mode analysis remain thin. | Unproven. |
So the clean version is this: Sakana has shown an impressive benchmark case for orchestration. It has not yet shown the kind of broad, independent evidence that would make the Fable/Mythos parity claim settled.
Benchmark Review: What Did Fugu Ultra Actually Score?
Sakana’s current Fugu page and technical report report the following headline benchmark numbers for Fugu Ultra. The main caveat: Sakana says baseline scores are provider-reported wherever available, and references to Fable/Mythos results are collected from Anthropic material, official leaderboards, and third-party benchmark services when needed.
| Benchmark | What It Tests | Sakana Reported Result | Fable/Mythos Comparison | Limitations | Verdict |
|---|---|---|---|---|---|
| SWE Bench Pro | Long-horizon real software engineering tasks, run through an agent scaffold. | Fugu Ultra: 73.7. Fugu: 59.0. | Anthropic reports Mythos 5 at 80.3 and Fable 5 at 80 on SWE-bench Pro. | Harness choices matter. Sakana uses mini-swe-agent and reports many baselines from providers. | Strong versus public worker models in Sakana’s table, but not equal to Anthropic’s reported Fable/Mythos 5 score. |
| Terminal-Bench 2.1 | Hard terminal-based agent tasks involving command-line work, debugging, and environment feedback. | Fugu Ultra: 82.1. Fugu: 80.2. | Anthropic reports Mythos 5 at 88.0 and Fable 5 at 84.3. Sakana’s figure compares against Mythos Preview where available. | Agent harness, turn limits, and tool access can change results materially. | Competitive, but not proven parity with Mythos 5. |
| LiveCodeBench v6 | Competitive programming problems designed to reduce contamination risk. | Fugu Ultra: 93.2. Fugu: 92.9. | Sakana’s chart shows Fugu Ultra above its Fable 5 comparison point. | No broad independent Fugu rerun found. Competitive coding benchmarks can be sensitive to sampling, retries, and execution details. | One of the stronger official results. |
| LiveCodeBench Pro | Harder competitive programming tasks, text-only and without tools in Sakana’s setup. | Fugu Ultra: 90.8. Fugu: 87.8. | No clean public Fable/Mythos comparison found in the reviewed primary material. | Timeout handling and retry policy matter. Sakana says all baselines were run with five retries on timeouts or max-token exhaustion. | Strong versus Sakana’s listed public baselines, but not a clean Fable/Mythos proof point. |
| GPQA-Diamond | Graduate-level science questions intended to be hard for non-experts and resistant to simple lookup. | Fugu Ultra: 95.5. Fugu: 95.5. | Sakana’s chart places Fugu Ultra at or above the Fable/Mythos comparison points. Anthropic reports Mythos 5 at 94.1 on GPQA Diamond. | Anthropic itself says GPQA Diamond is becoming saturated. A high score is useful, but not enough alone to prove frontier replacement value. | Strongest narrow support for Sakana’s claim. |
| Humanity’s Last Exam | Broad multimodal and multidisciplinary expert-level questions. | Fugu Ultra: 50.0. Fugu: 47.2. | Anthropic reports Mythos 5 at 59.0 without tools and Mythos Preview at 56.8. Sakana’s own chart shows a lower Fable comparison than Anthropic’s Mythos 5 number. | Tool settings, multimodal inputs, and contamination filtering matter. This is a broad benchmark, not a production workflow test. | Does not support broad Mythos 5 parity. |
| CharXiv Reasoning | Chart and scientific-figure reasoning, often judged by an LLM evaluator. | Fugu Ultra: 86.6. Fugu: 85.1. | Anthropic reports Mythos 5 at 88.9 without tools and Mythos Preview at 86.2. | LLM-judge methodology and image handling can affect results. | Close to Mythos Preview, below Anthropic’s reported Mythos 5. |
| SciCode | Scientific coding tasks curated by scientists. | Fugu Ultra: 58.7. Fugu: 60.1. | Sakana’s chart shows the Fable 5 comparison around the same range. | Sakana notes some test cases required package version updates because legitimate solutions could fail under outdated packages. | Partial support. Good result, but not a clean “Ultra beats all” story. |
| tau3 Banking | Conversational task completion in a banking environment with tool use. | Fugu Ultra: 20.6. Fugu: 21.7. | No direct Fable/Mythos comparison in the reviewed Sakana table. | Pass@4, simulated user, and task design matter. | Useful agentic signal, not a Fable/Mythos proof point. |
| Long Context Reasoning | Information retrieval and reasoning over long documents. | Fugu Ultra: 73.3. Fugu: 74.7. | No direct Fable/Mythos comparison in the reviewed Sakana table. | Sakana uses an equality checker and timeouts. Long-context evals are sensitive to formatting and grading. | Solid but not central to the Fable/Mythos claim. |
| MRCRv2 | Needle retrieval up to long context lengths. | Fugu Ultra: 93.6. Fugu: 86.6. | No clean Fable/Mythos comparison in the reviewed Sakana table. | GPT-5.5 is listed above Fugu Ultra at 94.8 in Sakana’s table. | Strong, but not best in Sakana’s own comparison table. |
| CTI-REALM | Cyber threat intelligence or related reasoning, as presented in Sakana’s figure. | Fugu Ultra appears around 69.4 in the technical report figure. | Sakana’s figure places it slightly above a Mythos comparison point and near Opus 4.8. | More detail is needed on setup, access, and whether the compared Mythos point is Mythos 5 or Mythos Preview. | Interesting, but too chart-level to carry the claim alone. |
The broad pattern: Fugu Ultra looks impressive against public frontier baselines, but the Fable/Mythos comparison is mixed. It depends heavily on which benchmark, which Anthropic model point, and which evaluation configuration you use.
Evidence For Sakana’s Claim
The fair pro-Sakana case is stronger than a normal launch blog claim. This is not just “we made a model and it feels smart.” Sakana published a technical report, a benchmark table, a product page, pricing, qualitative examples, and related research history.
| Evidence For | Why It Matters | How Strong Is It? |
|---|---|---|
| Published benchmark results across coding, reasoning, science, long-context, and agentic tasks. | The breadth is meaningful. Fugu Ultra is not only presented on one cherry-picked benchmark. | Strong as official evidence, limited as independent proof. |
| Fugu and Fugu Ultra are orchestrators, not just prompt wrappers. | The technical report describes trained language models that decide which agents to call and how to structure workflows. | Well supported by Sakana’s materials. |
| Fable 5 and Mythos Preview are not in Fugu’s worker pool, according to Sakana. | If true, Fugu is not simply outsourcing the comparison to the exact compared models. | Officially stated; not independently audited. |
| Multi-agent orchestration has a plausible technical advantage. | Different models have different strengths. A good planner/router/critic/verifier system can outperform a single model on some tasks. | Plausible and supported by the broader multi-agent research literature. |
| Prior Sakana research fits the product story. | Sakana’s work on Trinity, Conductor, The AI Scientist, model merging, and evolutionary search gives Fugu a coherent research lineage. | Good contextual support. |
| Fugu Ultra is designed to spend more test-time compute on hard tasks. | That is exactly where multi-agent systems can shine: planning, debate, critique, verification, and retry loops. | Technically plausible, but cost and latency need measurement. |
The strongest pro-Sakana argument is simple: if frontier models are already specialized, then a trained system that knows when to use each specialist could beat any one of them on certain tasks. That is not hype. That is a real design space.
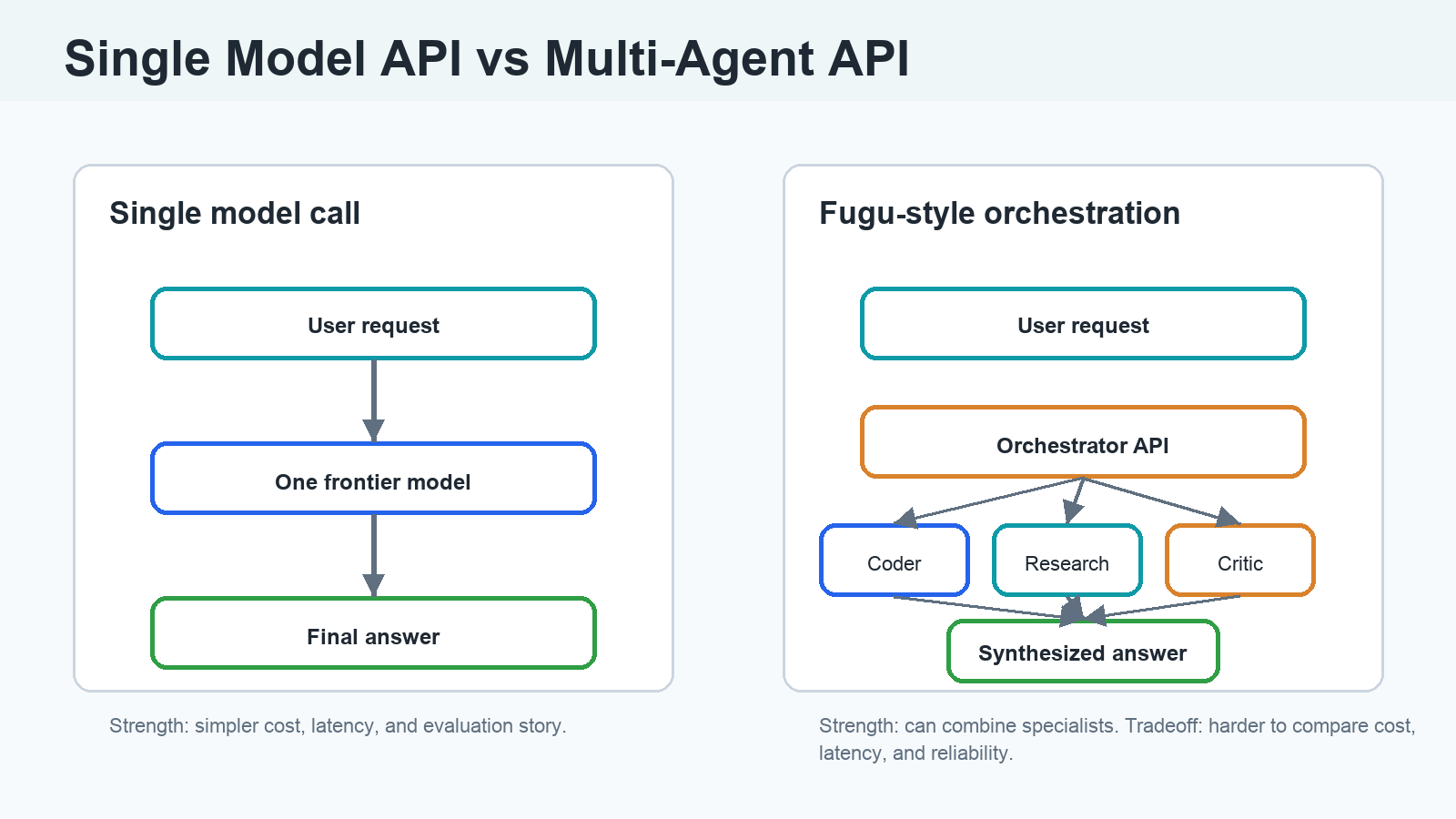
Evidence Against Sakana’s Claim
The skeptical case is just as important. Benchmark charts can be useful, but they are not the same thing as independent operational proof.
| Evidence Against | Why It Matters | Current Read |
|---|---|---|
| Lack of broad independent Fugu Ultra benchmark reruns. | Until outside labs, developers, and enterprises reproduce results, the evidence mostly comes from the launch source. | Major caveat. |
| Provider-reported baselines. | Sakana explicitly says many non-Fugu scores are provider-reported. That is common in AI launches, but it limits comparability. | Important caveat. |
| Single-model vs multi-agent comparison problem. | Fugu Ultra may call several agents, use deeper workflows, and spend more compute per task. That can be fair for quality, but not for cost or latency. | Central issue. |
| Unknown latency distribution. | Sakana says Fugu Ultra prioritizes answer quality and trades additional latency for performance, but public latency data is not enough to judge production fit. | Unproven. |
| Published token pricing does not fully settle task cost. | Sakana lists Fugu Ultra token pricing and says model fees are not stacked, but real cost depends on context size, output length, retry patterns, and workload mix. | Partly known, partly unproven. |
| Benchmark optimization risk. | Any model or system can look stronger on the benchmarks it was optimized around than in messy production workflows. | Normal but real risk. |
| API stability and enterprise readiness remain unclear. | Developers need rate limits, SLAs, privacy posture, support, observability, and failure-mode documentation. | Still needs evidence. |
| Fable/Mythos availability and policy context changed quickly. | Anthropic’s Claude API docs include a June 12 update saying access to Claude Fable 5 and Claude Mythos 5 had been suspended. That makes clean competitive testing harder. | Complicates comparison. |
Would a serious enterprise replace Fable, Mythos, Claude, Gemini, OpenAI, or Codex workflows based only on the current evidence?
No. A serious enterprise should test Fugu Ultra against its own work, with its own latency limits, cost model, privacy constraints, and reliability bar.
Is This Apples-to-Apples?
This is the heart of the investigation.
Fable 5 and Mythos 5 are described by Anthropic as configurations of a new Claude model. Fable 5 is the generally released form with additional safeguards. Mythos 5 is the less-restricted version made available to a small set of trusted partners, at least as originally announced.
Fugu Ultra is different. It is not best understood as one standalone model trying to beat another standalone model. It is a multi-agent orchestration system that can call a pool of frontier models and coordinate them through a learned workflow.
That makes the comparison both exciting and tricky.
If the user only cares about final answer quality, a multi-agent system can absolutely compete with a single frontier model. In fact, that may be the next big shift in AI: not only bigger models, but better systems wrapped around models.
But if the user cares about cost, latency, repeatability, observability, and operational trust, a multi-agent system is harder to compare.
A single model call has one model, one latency profile, one safety policy, one price card, and one failure mode. A multi-agent system may involve planner calls, specialist calls, critic calls, verifier calls, retries, longer outputs, hidden tool loops, and task-dependent paths. That can produce better answers. It can also make the system harder to reason about.
So the question is not just: “Did Fugu Ultra score higher?”
The better question is: “Did Fugu Ultra deliver better task success per dollar, per minute, and per operational risk unit?”
That evidence is not yet public enough.
Independent Evidence Review
At the time of writing, the strongest evidence appears to come from Sakana’s own materials, not broad third-party testing.
| Source | What It Found | Supports Sakana? | Credibility |
|---|---|---|---|
| Sakana Fugu official page | Reports Fugu Ultra benchmark results, product positioning, pricing, qualitative examples, and the Fable/Mythos Preview comparison. | Yes, but it is first-party evidence. | Primary source, not independent. |
| SakanaAI/fugu GitHub and technical report | Gives methods, benchmark setup, tables, and appendix details for evaluation configuration. | Yes, with caveats. | Primary technical source, not independent verification. |
| Anthropic Fable 5 and Mythos 5 system card | Reports Anthropic’s own Fable/Mythos scores and safety context. Some Mythos 5 scores exceed Fugu Ultra on overlapping benchmarks. | Mixed. It strengthens the comparator side and weakens broad Mythos 5 parity claims. | Primary comparator source. |
| Andon Labs Vending-Bench test | Ran Fable/Mythos-style models through a business simulation and found behavioral issues. This tests Anthropic’s model behavior, not Fugu Ultra. | Indirectly. It shows benchmarks do not fully predict business behavior. | Independent but not a Fugu test. |
| Vellum benchmark explainer | Summarizes Fable/Mythos benchmark claims and business implications. | Indirectly useful for context, not a Fugu rerun. | Credible secondary analysis, not primary validation. |
| Vals AI LiveCodeBench, Terminal-Bench, and Artificial Analysis style leaderboards | Provide benchmark context and some baseline data sources referenced by Sakana. | Useful for comparison, but not enough unless Fugu results are independently listed and reproduced. | Credible benchmark infrastructure, limited as Fugu evidence. |
| Public developer reports | I did not find enough broad, credible, reproducible Fugu Ultra developer testing to treat the launch claims as independently proven. | No. | Evidence gap. |
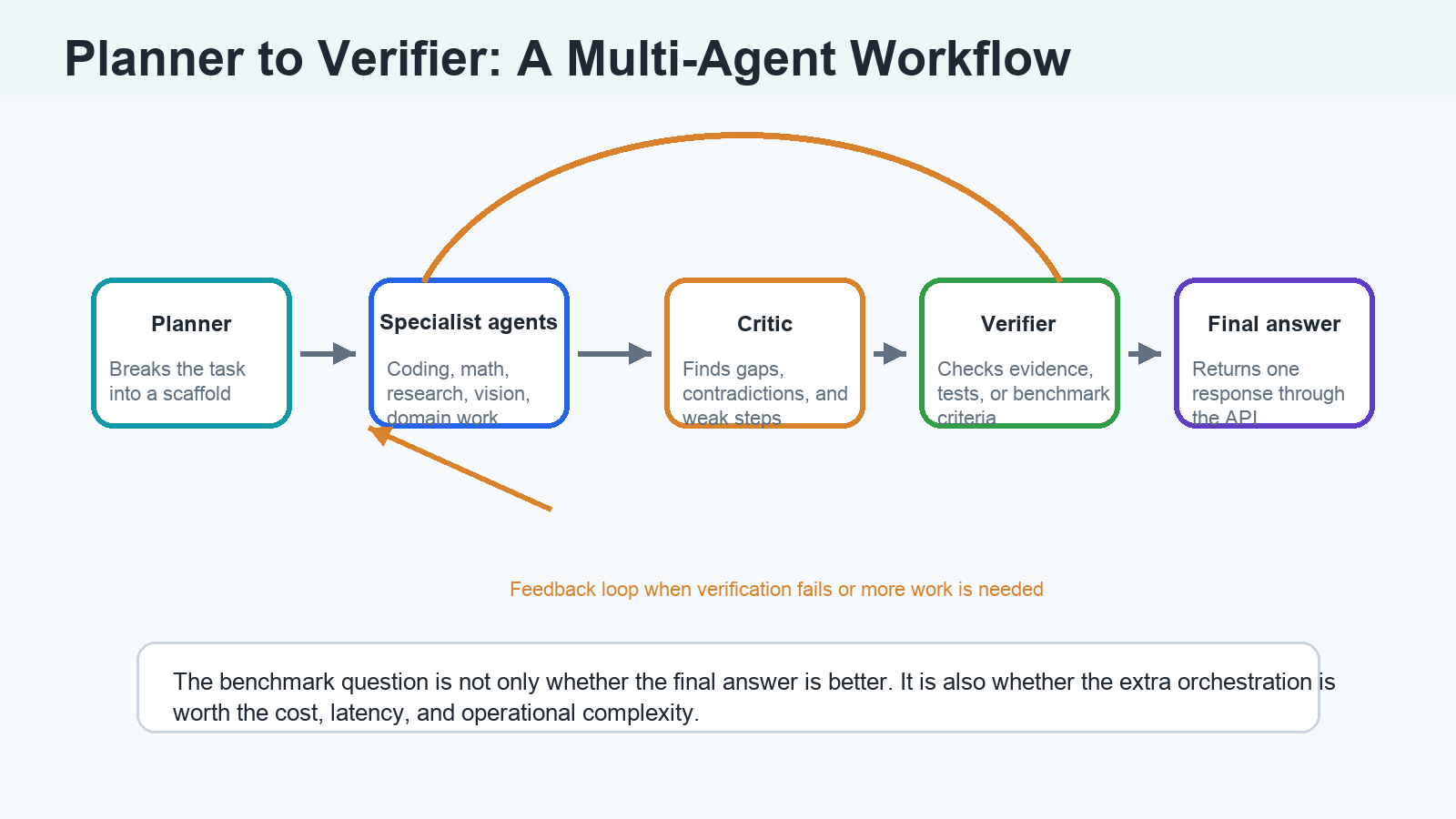
What Is Sakana Fugu?
Sakana Fugu is Sakana AI’s commercial multi-agent orchestration product. It is designed to look simple from the outside: one API, one response. Behind the scenes, it can route work to different models, assign roles, coordinate multiple attempts, synthesize outputs, and use critic or verifier patterns.
That means Fugu is not just a normal model name. It is closer to a model-driven system: a trained orchestrator plus a pool of model workers plus task-dependent scaffolding.
Sakana currently describes two main modes:
- Fugu: the faster variant, designed to balance performance and latency. In the technical report, Fugu often selects a single worker per input.
- Fugu Ultra: the quality-first variant, designed to coordinate a deeper pool of expert agents for hard problems.
The phrase “one API, many agents” means the developer does not manually choose every model, role, and workflow. The orchestrator decides how to use the model pool for a given query.
That is powerful if it works. It means a coding task might get a builder, debugger, and verifier. A science task might get a math-heavy model, a factual model, and a critic. A research task might get independent attempts followed by aggregation.
It also means Fugu Ultra is not a clean substitute for a single model benchmark. It is a system competing with models.
Why Multi-Agent AI Could Matter
The bigger trend is clear: AI is moving from single prompts toward agentic workflows.
For more context, Kingy has already covered practical AI agent adoption, the AI coding agent stack, and how teams should evaluate new AI launches with an AI launch evaluation framework.
Fugu fits that trend. The bet is that orchestration may matter as much as raw model size.
Planner, critic, verifier, and specialist-agent systems can improve complex work because they create friction inside the AI process. Instead of one model producing one answer, multiple agents can challenge, repair, or extend each other’s work.
That is why the Fugu story is worth watching even if the Fable/Mythos comparison is not fully proven. The future AI race may not only be “who has the biggest model?” It may also be “who has the best AI system around the model?”
Where Fugu Could Be Useful
If Fugu Ultra performs in real workflows the way it performs in Sakana’s best official evidence, the likely use cases are high-value, hard-to-automate tasks.
- Coding: repo repair, debugging, test generation, migration, and difficult issue resolution.
- Research: paper reproduction, literature review, hypothesis exploration, and experimental loops.
- Scientific reasoning: technical Q&A, analysis, and domain-specific problem solving.
- Enterprise automation: complex workflows where one model call is too brittle.
- Long-running tasks: multi-step jobs where planning and verification matter.
- Data analysis: workflows that benefit from specialist checks, code execution, and critique.
- AI agents: autonomous systems where routing and verification can reduce failure rates.
- Business workflows: tasks where the cost of a bad answer is higher than the cost of extra inference.
But do not measure Fugu with vibes. Measure task success rate.
What Feels Unproven
The unproven parts are straightforward:
- Independent benchmark reruns.
- Real-world reliability across messy business workflows.
- Latency distributions for Fugu Ultra.
- Total cost per completed task, not just token price.
- Production case studies.
- Enterprise adoption.
- Failure modes.
- API stability, rate limits, and support quality.
- Direct, controlled Fugu Ultra vs Fable/Mythos 5 comparisons.
Sakana does publish Fugu Ultra pricing on the current Fugu page, including fixed token rates and higher rates for context above 272K. That is useful. But token pricing is not the same thing as total workflow economics.
A system that produces a better answer after more orchestration can still be worth it. It just needs to be evaluated as a system, not as a single-model call.
Should Businesses Care?
Yes. But they should care in the disciplined way.
Businesses should monitor Fugu closely, especially if they run high-value coding, research, analysis, or automation workflows. But they should not switch based only on benchmark charts.
| Decision Area | What To Test | Pass Bar | Decision Guidance |
|---|---|---|---|
| Task success | Run Fugu Ultra on your real work, not toy prompts. | Higher completion rate than your current model or agent stack. | Consider adoption if gains are repeatable. |
| Cost | Measure cost per completed task, including retries and long context. | Worth the quality gain for high-value tasks. | Use selectively if expensive but better. |
| Latency | Track p50, p90, and p99 latency for your workflows. | Acceptable for the business process. | Fugu Ultra may fit async work better than live chat. |
| Reliability | Measure regressions, hallucinations, tool errors, and failure recovery. | Clear improvement or lower operational risk. | Do not adopt if failures are harder to debug. |
| Privacy and compliance | Review data handling, model pool behavior, retention, and enterprise terms. | Matches internal policy and customer commitments. | Required before sensitive workflows. |
| API stability | Test rate limits, error modes, uptime, versioning, and observability. | Stable enough for production or clearly scoped pilots. | Start with controlled pilots. |
| Support | Evaluate docs, escalation paths, enterprise support, and roadmap clarity. | Good enough for business-critical usage. | Do not rely on launch buzz. |
The right posture is: test it, benchmark it, and keep receipts.
Should Developers Care?
Yes, especially developers already using Claude Code, Codex, Cursor, Gemini, OpenAI models, or custom agent frameworks.
Fugu is interesting because it offers a different abstraction. Instead of you manually deciding when to call Claude, GPT, Gemini, a critic model, a coding model, or a verifier, Fugu tries to make that decision inside the API.
Developers should test it on:
- Repo tasks with real tests.
- Bug-fixing tasks where the first attempt often fails.
- Long-context research tasks.
- Code review and refactoring workflows.
- Multi-file debugging.
- Scientific or data-heavy notebooks.
- Tasks where critic and verifier loops help.
Compare Fugu against your current Claude, Codex, Gemini, OpenAI, and local/open-source AI model workflows. Kingy readers who already follow AI coding agent comparisons should treat Fugu as a new system-level competitor, not just another chatbot.
Do not ask: “Did it sound smart?”
Ask: “Did it finish the task correctly, with tests, at acceptable cost and latency?”
Should Creators Care?
Yes. The creator angle is excellent because Fugu makes the AI race easier to explain.
The old story was: one model versus another model.
The new story is: one model versus an agent team.
That is a strong explainer topic for videos, newsletters, podcasts, and comparison posts. It also fits the larger AI Launch Radar narrative: the most important launches are increasingly about systems, workflows, agents, and evaluation discipline.
Creators should focus less on “Fugu beats X” hype and more on benchmark truth-testing:
- What exactly was tested?
- Was it independently reproduced?
- Was it a single model or a system?
- How much compute did it spend?
- Would it help a real user finish real work?
That is more useful than launch-chart cheerleading.
Final Verdict
Evidence partially supports the claim.
Sakana Fugu Ultra appears to be a serious technical result. The benchmark table is broad. The multi-agent orchestration approach is plausible. The research lineage is coherent. The official data suggests Fugu Ultra can compete with and sometimes beat top public frontier baselines.
But the strongest version of the claim – that Fugu Ultra really matched Fable 5 and Mythos 5 overall – is not proven.
On some benchmarks, Fugu Ultra looks close to or above the Fable/Mythos-class comparison points Sakana cites. On others, Anthropic’s own Mythos 5 and Fable 5 numbers are higher. And across the whole picture, independent Fugu Ultra reruns remain too limited.
The best conclusion:
Fugu Ultra is promising, benchmark-strong, and strategically important. It is not yet independently proven to be a Fable/Mythos replacement.
Related Kingy Reading
For broader context, read Kingy’s guide to which AI model you should use, our best open-source AI models guide, the AI stack audit guide, and our recent Claude Fable 5 benchmarks explainer. For launch context, follow the AI Launch Radar, AI launch tracker, and AI News.
FAQ
Did Sakana Fugu Ultra beat Fable 5?
On some Sakana-reported benchmark comparisons, yes or close enough to be notable. But not across every relevant benchmark, and not with broad independent reruns yet.
Did Sakana Fugu Ultra beat Mythos 5?
Not as a broad claim. Sakana’s official comparison often references Mythos Preview, while Anthropic’s Mythos 5 system card reports stronger numbers on several overlapping benchmarks.
Is Fugu Ultra a model or an agent system?
It is best understood as a trained orchestration system exposed through a model-like API. It can coordinate multiple model workers behind one interface.
Is Fugu Ultra independently verified?
Not enough yet. At the time of writing, the strongest public evidence comes from Sakana’s own page, GitHub report, and technical material.
Should businesses switch to Fugu Ultra now?
They should test it, not blindly switch. Benchmark it against real workflows and compare cost, latency, reliability, privacy, API stability, and support.
Sources
- Sakana Fugu official page
- Sakana Fugu beta announcement
- SakanaAI/fugu GitHub repository and technical report
- Sakana AI official website
- Trinity: An Evolved LLM Coordinator
- Learning to Orchestrate Agents in Natural Language with the Conductor
- Sakana AI Scientist
- Anthropic Claude Fable 5 and Claude Mythos 5 announcement
- Anthropic Claude API docs: Introducing Claude Fable 5 and Claude Mythos 5
- Claude Fable 5 and Claude Mythos 5 system card
- Andon Labs: What We Learned Testing Claude Fable/Mythos 5 on Vending-Bench
- Vellum: Claude Fable 5 and Mythos 5 Benchmarks Explained
- Vals AI LiveCodeBench benchmark page
- Terminal-Bench
- LiveCodeBench paper
- GPQA paper
- Humanity’s Last Exam paper
- CharXiv benchmark repository








