Anthropic just launched Claude Fable 5, and this is not a normal model refresh.
This is the first generally available Mythos-class Claude model: a new capability tier that Anthropic says sits above its Opus class. Fable 5 launched alongside Claude Mythos 5, but the two are not available in the same way. Fable 5 is the version Anthropic has made broadly available for general use. Mythos 5 is the more restricted version for selected trusted-access programs, starting with Project Glasswing and approved cybersecurity partners. Anthropic says the two share the same underlying model, but Fable 5 ships with additional safeguards that can route some sensitive requests to Claude Opus 4.8 instead.
That distinction matters because this launch is really two stories at once.
The first story is capability. Anthropic says Fable 5 exceeds every model it has previously made generally available and shows state-of-the-art performance across software engineering, knowledge work, vision, scientific research, computer use, legal tasks, automation, and agentic workflows. The second story is control. Anthropic is not simply giving everyone unrestricted Mythos 5. It is releasing Mythos-level capability through Fable 5, but wrapping the public model in classifiers, fallback behavior, and a new data-retention requirement for certain business and zero-data-retention configurations.
For developers, the headline is simple: Claude Fable 5 looks like Anthropic’s strongest public coding model by a wide margin.
The numbers that matter most are the coding and agentic software-engineering evals: 80.3% on SWE-bench Pro, 95.0% on SWE-bench Verified according to Vals, 29.3% on FrontierCode Diamond, 72.9% on CursorBench 3.1 at max effort, and 88.0% on Terminal-Bench 2.1 for the Mythos/Fable column in Anthropic’s table, with the important caveat that some starred results reflect Mythos-level capability more than the fully safeguarded public Fable experience.
But that is not the whole picture. The better way to understand Fable 5 is not “Claude got a better benchmark score.” It is this:
Claude Fable 5 is Anthropic’s public test of what happens when frontier models become long-horizon agents instead of chatbots.
Claude Fable 5 Specs
Here are the core specs Anthropic has publicly listed for Claude Fable 5.
| Spec | Claude Fable 5 |
|---|---|
| Model class | Mythos-class |
| API model ID | claude-fable-5 |
| Context window | 1 million tokens |
| Max output | 128k tokens |
| Base input price | $10 per million tokens |
| Base output price | $50 per million tokens |
| 5-minute cache write | $12.50 per million tokens |
| 1-hour cache write | $20 per million tokens |
| Cache hit / refresh | $1 per million tokens |
| Batch API input price | $5 per million tokens |
| Batch API output price | $25 per million tokens |
| Adaptive thinking | Always on |
| Traditional extended thinking toggle | No |
| Raw chain-of-thought output | Not returned |
| Summarized thinking | Available through thinking.display: "summarized" |
| Supported launch features | Effort, task budgets, memory tool, context editing, compaction, vision |
| Claude Code model name | claude-fable-5 |
| Public availability | Generally available |
| Restricted sibling model | Claude Mythos 5 |
| Fallback model for certain flagged requests | Claude Opus 4.8 |
| Data retention for covered-model traffic | 30 days in affected ZDR / covered-model contexts |
Anthropic’s Claude API docs list Claude Fable 5 as claude-fable-5, describe it as the company’s most capable widely released model, and say Fable 5 and Mythos 5 support a 1M-token context window and up to 128k output tokens per request. The same docs say adaptive thinking is always on, raw thinking is never returned, and Fable 5 supports effort, task budgets, memory, context editing, compaction, and vision at launch.
Anthropic’s pricing page lists Fable 5 at $10 / MTok input and $50 / MTok output, with cache hits at $1 / MTok, 5-minute cache writes at $12.50 / MTok, and 1-hour cache writes at $20 / MTok. The same page says Batch API processing gives a 50% discount, bringing Fable 5 to $5 / MTok input and $25 / MTok output for batch jobs.
The pricing page also says Claude Fable 5 includes the full 1M-token context window at standard pricing, meaning a 900k-token request is billed at the same per-token rate as a 9k-token request. Prompt caching and batch discounts apply across the full context window.
There is also a U.S.-only inference pricing caveat. Anthropic says that for Claude Opus 4.6, Sonnet 4.6, and later models, using inference_geo: "us" applies a 1.1x pricing multiplier on token pricing categories. Since Fable 5 is later than those models, that matters for teams that require U.S.-only routing.
What Anthropic has not publicly disclosed in the materials I found: parameter count, model size, exact training compute, architecture details, or the composition of the training data. So any article claiming “Claude Fable 5 has X trillion parameters” or “was trained on Y tokens” should be treated as speculation unless Anthropic publishes those details later.
Availability: Who Can Use Claude Fable 5?
Anthropic says Claude Fable 5 is available through the Claude API, Claude Platform on AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry. Claude Mythos 5 is not generally available and is limited to approved Project Glasswing customers and future trusted-access programs.
For subscription users, the launch window is more complicated. Anthropic says Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans at no extra cost from launch through June 22, 2026. Starting June 23, Anthropic says it plans to remove Fable 5 from those plans unless capacity allows an extension, and continued use will require usage credits until the company can restore it as a standard subscription-plan model.
For Claude Code users, Anthropic’s Claude Code model configuration page lists Fable 5 as a supported model. You can change to it inside Claude Code with /model, launch a one-time session with claude --model claude-fable-5, or set ANTHROPIC_MODEL="claude-fable-5" in your shell configuration.
That matters because Fable 5 is not just another chat model. Anthropic’s own Fable model page says it is meant for ambitious, long-running projects, including agent harnesses like Claude Code and Claude Managed Agents, where it can plan across stages, delegate to sub-agents, and check its own work.
The Most Important Caveat: Fable 5 Is Not Unrestricted Mythos 5
Before getting into benchmarks, this has to be clear.
Anthropic’s official benchmark table uses a combined “Claude Mythos 5 / Fable 5” column in some places. The footnote on the benchmark image says reported scores are usually within a 1–3 percentage point difference between Mythos 5 and Fable 5, but starred benchmarks show larger differences because of blocking safeguards for cybersecurity and biology-related questions. For those starred benchmarks, public Fable 5 performs closer to Claude Opus 4.8 because of fallbacks.
That means you should not read every Mythos/Fable number as “the public Fable 5 experience in every domain.”
For normal coding, product development, document work, vision tasks, business analysis, and long-horizon agentic workflows, the Fable 5 numbers appear to represent what users should broadly expect. But in sensitive domains like offensive cybersecurity, biology, chemistry, and distillation-style model extraction, Anthropic says Fable 5 uses classifiers that can route the request to Claude Opus 4.8 instead.
Anthropic says the fallback rate is below 5% of sessions on average, and that more than 95% of Fable sessions involve no fallback at all. For those sessions, Anthropic says Fable 5’s performance is effectively the same as Mythos 5.
So the clean interpretation is:
Claude Fable 5 is the broadly available Mythos-class model. Claude Mythos 5 is the restricted version with some safeguards lifted. The same underlying intelligence is there, but the public product has safety routing.
That routing is not a footnote. It is one of the defining features of the launch.
Full Benchmark Snapshot: The Official Anthropic Table
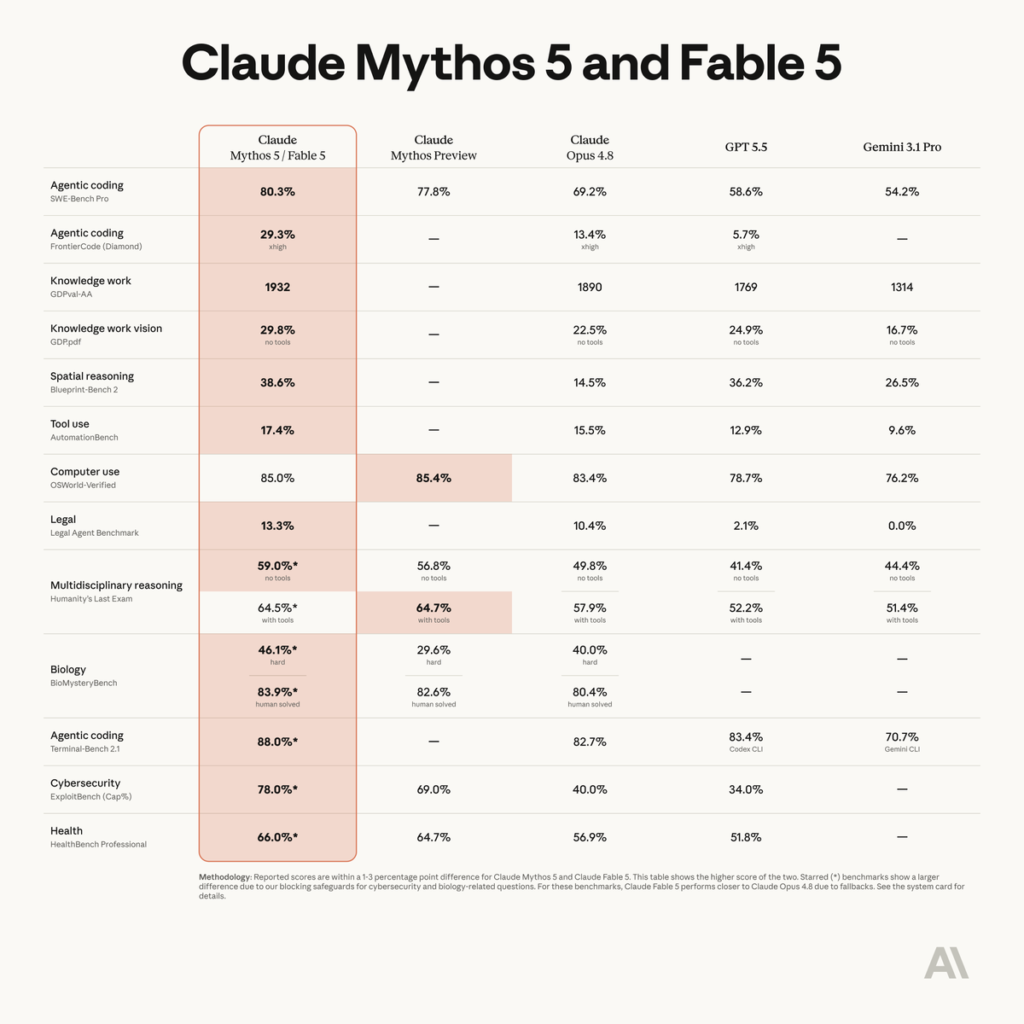
Anthropic’s official benchmark image compares Claude Mythos 5 / Fable 5 against Claude Mythos Preview, Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro across coding, knowledge work, vision, automation, computer use, legal, reasoning, biology, cybersecurity, and health benchmarks. The detailed source for these results is Anthropic’s Claude Fable 5 and Claude Mythos 5 system card.
| Category | Benchmark | Claude Mythos 5 / Fable 5 | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| Agentic coding | SWE-bench Pro | 80.3% | 69.2% | 58.6% | 54.2% |
| Agentic coding | FrontierCode Diamond | 29.3% | 13.4% | 5.7% | — |
| Knowledge work | GDPval-AA | 1932 | 1890 | 1769 | 1314 |
| Knowledge work / vision | GDP.pdf | 29.8% | 22.5% | 24.9% | 16.7% |
| Spatial reasoning | Blueprint-Bench 2 | 38.6% | 14.5% | 36.2% | 26.5% |
| Tool use | AutomationBench | 17.4% | 15.5% | 12.9% | 9.6% |
| Computer use | OSWorld-Verified | 85.0% | 83.4% | 78.7% | 76.2% |
| Legal | Legal Agent Benchmark | 13.3% | 10.4% | 2.1% | 0.0% |
| Multidisciplinary reasoning | Humanity’s Last Exam, no tools | 59.0%* | 49.8% | 41.4% | 44.4% |
| Multidisciplinary reasoning | Humanity’s Last Exam, with tools | 64.5%* | 57.9% | 52.2% | 51.4% |
| Biology | BioMysteryBench, hard | 46.1%* | 40.0% | — | — |
| Biology | BioMysteryBench, human-solved | 83.9%* | 80.4% | — | — |
| Agentic coding | Terminal-Bench 2.1 | 88.0%* | 82.7% | 83.4% | 70.7% |
| Cybersecurity | ExploitBench Cap% | 78.0%* | 40.0% | 34.0% | — |
| Health | HealthBench Professional | 66.0%* | 56.9% | 51.8% | — |
The asterisk matters. Anthropic’s own footnote says starred benchmarks show a larger difference between Mythos 5 and Fable 5 because safeguards affect cybersecurity and biology-related questions, and that Fable 5 performs closer to Opus 4.8 on those benchmarks because of fallback behavior.
So the article’s benchmark framing should be:
- For coding, knowledge work, vision, automation, computer use, and legal, Fable 5 appears to be the new high-end public Claude.
- For cybersecurity and biology, the table shows Mythos-class capability, but public Fable 5 is deliberately constrained.
- For general users, the practical model is Fable 5 plus safeguards, not unrestricted Mythos 5.
Coding Benchmarks: The Main Event
The most important part of the Claude Fable 5 launch is coding.
Anthropic is clearly positioning Fable 5 as a model for long-horizon software engineering. Its Fable model page says the model is built for ambitious coding projects, including large migrations, complex implementations, and multi-day autonomous sessions. Anthropic also says Fable 5 can write its own tests, implement designs with high fidelity, and use vision to check outputs against the original goal.
That is the right frame. Coding in 2026 is no longer just “write me a function.” The best AI coding workflows now look more like loops:
- Read the repo.
- Understand the goal.
- Plan the work.
- Edit files.
- Run tests.
- Read errors.
- Fix mistakes.
- Repeat.
- Stop only when the code is working.
Fable 5 appears to be built for that kind of work.
For a broader look at how these tools fit together, Kingy.ai has a detailed guide to Codex vs Claude Code vs Cursor in 2026, which is the exact category where Fable 5 will matter most.
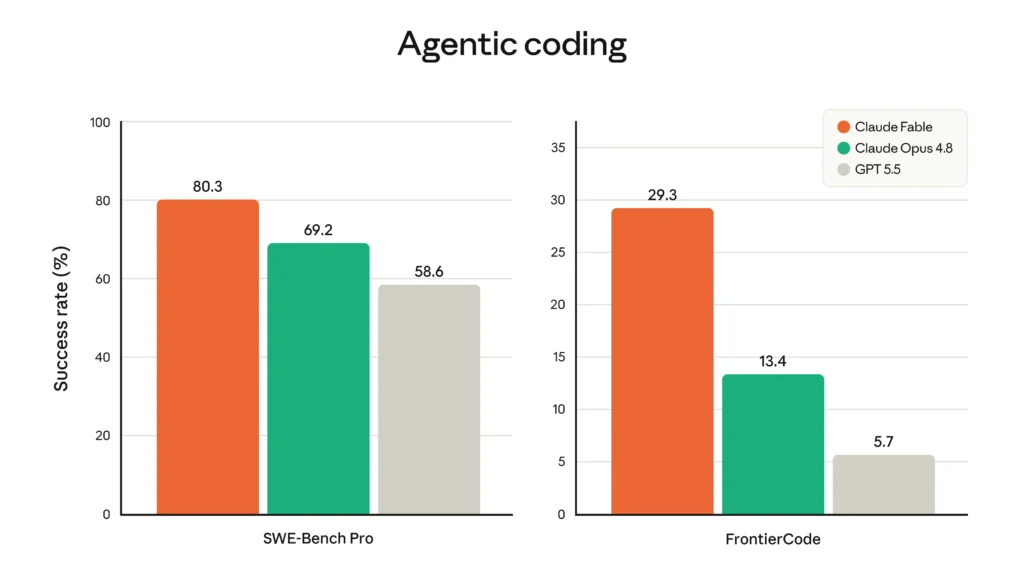
SWE-bench Pro: 80.3%
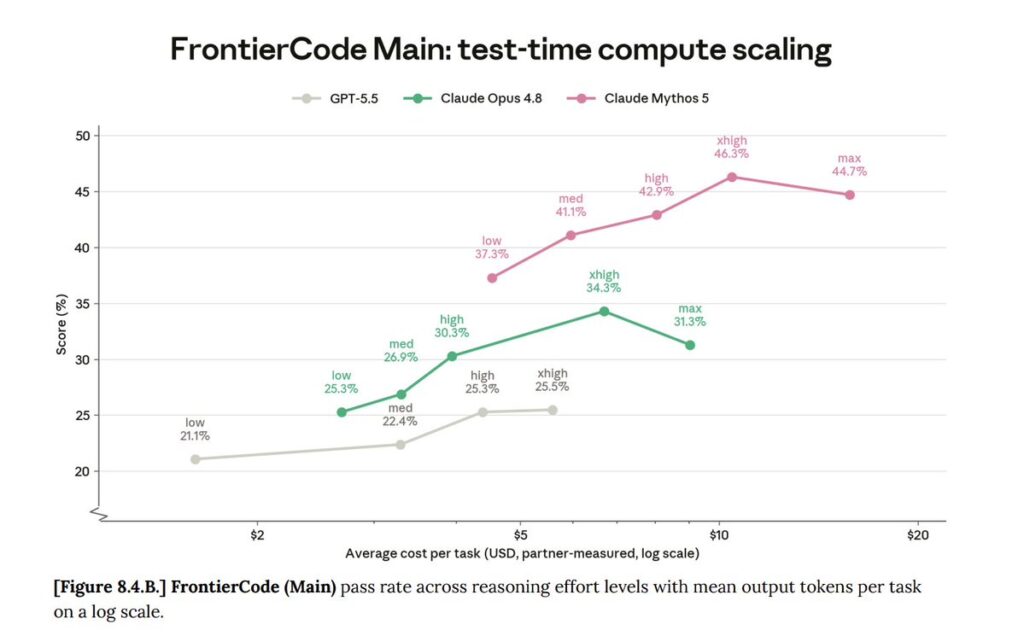
SWE-bench has become one of the central benchmarks for AI software engineering because it tests whether models can resolve real software issues rather than simply answer coding trivia. Anthropic’s official launch chart reports 80.3% for Claude Fable 5 / Mythos 5 on SWE-bench Pro, compared with 69.2% for Claude Opus 4.8, 58.6% for GPT-5.5, and 54.2% for Gemini 3.1 Pro.
That is a big jump over Opus 4.8. It also matters because SWE-bench Pro is more interesting than easier, more saturated coding benchmarks. As frontier models get better, the old benchmark question — “can it write correct code?” — becomes too easy. The harder question is whether the model can handle larger, messier, multi-step software tasks that require context, search, editing, testing, and recovery.
Still, SWE-bench is not the whole coding story. A model can do well on SWE-bench and still write code that a human maintainer would reject. That is why the other coding evals in this launch matter so much.
SWE-bench Verified: 95.0%
Vals’ SWE-bench Verified page reports Claude Fable 5 at 95.00%, ahead of Claude Opus 4.8 at 88.60% and GPT-5.5 at 82.60%. Vals describes SWE-bench Verified as a benchmark for solving production software engineering tasks and explains that it uses a minimal bash-tool-only agent harness so the evaluation burden falls more on the model than on a specialized scaffold.
That 95% number is impressive, but it should be interpreted carefully. When a benchmark gets this saturated, the margin between “great model” and “benchmark ceiling” starts to compress. It is still useful, but the most interesting evaluation signal moves toward harder, less saturated, more production-like tasks.
That is where FrontierCode, CursorBench, and Terminal-Bench become more important.
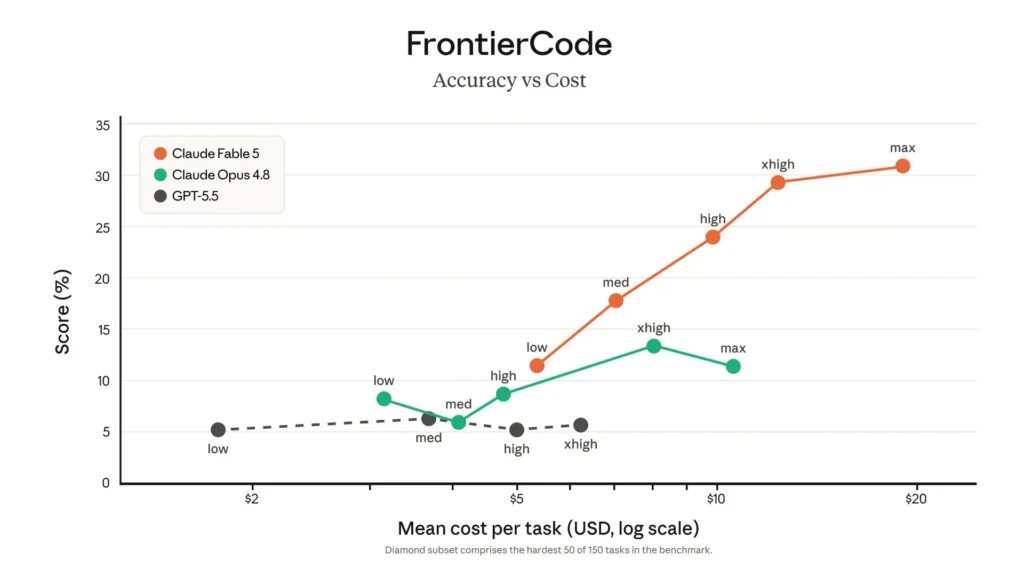
FrontierCode Diamond: 29.3%
The most interesting coding benchmark in the Fable 5 launch may be FrontierCode, Cognition’s benchmark for production-grade software engineering. Cognition describes FrontierCode as a benchmark designed to measure whether a model can produce code that would actually meet the standards of high-quality production codebases. It evaluates mergeability, correctness, test quality, scope discipline, style, and adherence to codebase standards.
Anthropic’s launch chart reports 29.3% for Claude Fable 5 on FrontierCode Diamond, compared with 13.4% for Claude Opus 4.8 and 5.7% for GPT-5.5. The Diamond subset is the hardest 50 tasks in the benchmark.
This is a much more meaningful signal than a simple code-generation benchmark.
FrontierCode does not merely ask, “Did the tests pass?” It asks something closer to, “Would the maintainer merge this PR?” Cognition says the benchmark was built with 20+ open-source maintainers, involved more than 40 hours of effort per task, and is designed to reduce false positives compared with SWE-bench Pro.
That is why Fable 5’s FrontierCode result is so important. It suggests the model is not just better at getting code to run. It may also be better at producing code that fits the codebase, respects constraints, writes meaningful tests, and avoids unnecessary changes.
For anyone using Claude Code, Cursor, Codex, or other coding agents, that is the real shift.
CursorBench 3.1: 72.9% at Max Effort
CursorBench 3.1 is especially useful because it comes from the environment where many developers actually use frontier models: an AI coding IDE. Cursor says CursorBench evaluates agents on ambiguous, multi-file tasks from real Cursor sessions, and that higher scores are better.
Cursor’s leaderboard puts Fable 5 Max at 72.9%, followed by Fable 5 Extra High at 72.0%, Fable 5 High at 70.6%, and Fable 5 Medium at 69.8%. GPT-5.5 Extra High is listed at 64.3%, while Opus 4.8 Max is listed at 63.8%.
That is a strong real-world coding-agent signal.
It is also useful because Cursor reports cost, tokens, and steps. Fable 5 Max scored highest, but it also used more budget: Cursor lists Fable 5 Max at $18.02 average cost per task, 63,842 tokens per task, and 76 steps per task. GPT-5.5 Extra High scored lower at 64.3%, but Cursor lists it at $4.37 per task and 17,905 tokens per task.
That creates the real buying decision for developers:
Fable 5 may be the strongest model, but the right model depends on cost per successful task, not just benchmark score.
For hard tasks, paying more for a model that succeeds may be cheaper than paying less for several failed runs. For routine tasks, Fable 5 may be overkill.
Cursor also warns that results are subject to variance and that small differences in scores may not be statistically meaningful. That is an important caveat for any benchmark-driven model comparison.
Terminal-Bench 2.1: 88.0% in Anthropic’s Table
Anthropic’s official benchmark table reports 88.0% for the Claude Mythos 5 / Fable 5 column on Terminal-Bench 2.1, compared with 82.7% for Claude Opus 4.8, 83.4% for GPT-5.5 using Codex CLI, and 70.7% for Gemini 3.1 Pro using Gemini CLI.
This benchmark matters because coding agents increasingly work inside terminals, not just chat windows. They inspect files, run commands, install packages, execute tests, read stack traces, and recover from failures.
The Terminal-Bench 2.0 paper describes the benchmark as a carefully curated set of 89 hard tasks in computer terminal environments inspired by real workflows. Each task includes a unique environment, human-written solution, and comprehensive tests. The authors say frontier models and agents scored below 65% on Terminal-Bench 2.0 at the time of the paper, showing how difficult the environment was before this new generation of models.
Terminal-Bench is also valuable because it checks whether an agent can work through a realistic command-line environment. The paper describes tasks with Docker environments, tests, oracle solutions, and review processes designed to reduce shortcuts and ensure solvability.
The reason this matters for Fable 5 is simple: a strong terminal agent is closer to a useful software engineer than a model that only writes isolated snippets.
What the Coding Results Actually Mean
The coding numbers point in the same direction:
| Coding eval | Fable / Mythos result | Why it matters |
|---|---|---|
| SWE-bench Verified | 95.0% on Vals | Real GitHub issue resolution, now near saturation |
| SWE-bench Pro | 80.3% in Anthropic chart | Harder software engineering tasks |
| FrontierCode Diamond | 29.3% | Production-style mergeability and code quality |
| CursorBench 3.1 | 72.9% max effort | Real-world ambiguous multi-file coding tasks |
| Terminal-Bench 2.1 | 88.0% in Anthropic chart | Terminal-based agentic workflows |
The real story is not one benchmark. It is the pattern.
Fable 5 appears strongest where the work looks like real engineering: long context, many files, ambiguous instructions, test execution, code review, terminal use, planning, and recovery. That is why this release matters more for Claude Code, Cursor, and coding-agent users than for people who only ask AI to write simple snippets.
The best Fable 5 use cases are likely:
- large codebase migrations
- multi-file refactors
- framework upgrades
- complex bug hunts
- frontend implementation from screenshots
- test generation and test repair
- documentation from code
- technical debt cleanup
- “take this repo and make it production-ready” workflows
- long-running Claude Code sessions
- codebase-wide transformations that require repeated verification
The bad use cases are also obvious:
- simple one-file edits
- regex fixes
- basic scripts
- boilerplate
- low-value summarization
- routine copywriting
- cheap classification tasks
Fable 5 is not the model you use because every task needs maximum intelligence. It is the model you use when cheaper models keep getting stuck.
For readers still learning the basics of AI coding workflows, Kingy.ai’s OpenAI Codex Course for Beginners is a useful starting point because the same principles apply across Codex, Claude Code, Cursor, and other agentic coding tools: define the goal, provide context, constrain the task, review the diff, and test before publishing.
The Stripe Example: Impressive, but Not a Public Benchmark
Anthropic says Stripe reported that Fable 5 compressed months of engineering into days. In a 50-million-line Ruby codebase, Anthropic says the model performed a codebase-wide migration in a day that would otherwise have taken a team more than two months by hand.
That is one of the most attention-grabbing parts of the launch. It is also not the same thing as a reproducible public benchmark.
The right way to frame it is:
Stripe’s report is strong early-customer evidence that Fable 5 can help with large codebase migrations, but it should not be treated as a controlled benchmark until the task, harness, baseline, review process, and success criteria are public.
Still, it fits the broader pattern. The public benchmarks say Fable 5 is strong at long-horizon coding. The customer feedback says the same thing in a real codebase.
Fable 5 for Claude Code: Why This Release Changes the Coding Workflow
For Claude Code users, Fable 5 should not be treated as “the new default for everything.” It should be treated as the escalation model.
Claude Code already supports changing models with /model, launching a session with claude --model claude-fable-5, or setting the model through ANTHROPIC_MODEL.
A practical workflow might look like this:
- Start with Sonnet or Opus for routine work.
- Use Fable 5 when the task spans many files or requires sustained reasoning.
- Ask Fable 5 to create a plan before editing.
- Make it write or update tests.
- Make it run the tests.
- Make it inspect failures.
- Make it continue until the acceptance criteria are met.
- Review the final diff yourself.
That last step matters. Fable 5 is stronger, but it is still not a reason to stop reviewing code.
A good Fable 5 prompt for Claude Code would look less like this:
Fix this app.
And more like this:
Inspect the repo. Identify why the dashboard route is failing in production. Create a concise plan first. Then implement the smallest safe fix. Add or update tests. Run the relevant test suite. If tests fail, debug and repair. Do not make unrelated changes. At the end, summarize files changed, tests run, and remaining risks.
That is the kind of loop Fable 5 appears built for.
This is also where context engineering becomes important. The better your project instructions, CLAUDE.md, AGENTS.md, constraints, acceptance criteria, and testing rules are, the more useful a model like Fable 5 becomes.
Vision Benchmarks: Why Fable 5 Matters for UI, PDFs, Charts, and Screenshots
Fable 5 is not just a coding model. Anthropic’s model page says Claude Fable 5 understands diagrams, charts, and tables nested in files and PDFs. It also says the model can use vision to help evaluate its own coding work by checking outputs against an original design or goal.
That matters because a lot of real work is multimodal.
Developers do not only work from text prompts. They work from screenshots, mockups, design notes, PDFs, diagrams, bug reports, browser renderings, and product requirements. Business users do not only work from plain text. They work from reports, dashboards, charts, slide decks, scanned documents, tables, and messy exported PDFs.
Anthropic’s official benchmark chart reports:
| Vision / multimodal benchmark | Claude Mythos 5 / Fable 5 | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| GDP.pdf | 29.8% | 22.5% | 24.9% | 16.7% |
| Blueprint-Bench 2 | 38.6% | 14.5% | 36.2% | 26.5% |
| OSWorld-Verified | 85.0% | 83.4% | 78.7% | 76.2% |
The GDP.pdf result matters for document-heavy work. The Blueprint-Bench 2 result matters for spatial reasoning and reconstruction. OSWorld-Verified matters for computer-use tasks where a model must understand and act in visual software environments.
The practical takeaway is that Fable 5 should be especially useful for tasks like:
- turning UI screenshots into code
- comparing a built page against a design
- debugging visual layout issues
- extracting numbers from dense charts
- answering questions from long PDFs
- reading tables embedded in reports
- analyzing dashboards
- understanding diagrams
- building tools from rough visual references
This is where coding and vision start to merge. The model is not just writing code. It can inspect the thing the code produced.
Knowledge Work: GDPval-AA, GDP.pdf, Office-Style Tasks, and Finance
Anthropic’s official table reports 1932 for Claude Mythos 5 / Fable 5 on GDPval-AA, compared with 1890 for Claude Opus 4.8, 1769 for GPT-5.5, and 1314 for Gemini 3.1 Pro. It also reports 29.8% on GDP.pdf, compared with 22.5% for Opus 4.8, 24.9% for GPT-5.5, and 16.7% for Gemini 3.1 Pro.
This is important because the enterprise market does not only care about coding. It cares about work products.
A model that can reason through long documents, charts, tables, and business context is useful for:
- financial research
- legal review
- diligence
- market analysis
- procurement
- board materials
- internal reporting
- spreadsheet-heavy workflows
- compliance review
- operations planning
- long-form research synthesis
Anthropic also says early testers reported strong finance and analytics performance. The Fable model page includes customer feedback saying it was the strongest finance-first model tested by one team, that it broke 90% on a complex analytics benchmark in another team’s testing, and that it performed strongly on trading-analysis evaluations. These are customer reports, not public standardized benchmarks, but they are directionally consistent with the official knowledge-work results.
The right conclusion is not “Fable 5 can replace analysts.” The right conclusion is more practical:
Fable 5 looks much better suited for document-heavy, multi-step professional work than earlier Claude models.
That makes it interesting for businesses that have workflows where the hard part is not generating text, but holding lots of messy context in mind and producing a usable deliverable.
AutomationBench and Tool Use: Still Hard, but Better
The official Anthropic table reports 17.4% for Claude Mythos 5 / Fable 5 on AutomationBench, compared with 15.5% for Opus 4.8, 12.9% for GPT-5.5, and 9.6% for Gemini 3.1 Pro.
At first glance, 17.4% does not sound impressive.
But that is the point.
Real automation is hard. It requires using tools, preserving context, avoiding destructive actions, calling the right APIs, making judgment calls, recovering from errors, and not getting lost halfway through a workflow.
The low absolute score says this category is still early. The relative score says Fable 5 is moving in the right direction.
For businesses, this is a good reminder: agentic automation is powerful, but it still needs guardrails. You should not give any model broad permissions over production systems without logging, sandboxing, review steps, and rollback plans.
If you are evaluating AI automation from a business value perspective, a simple ROI model like Kingy.ai’s AI ROI Calculator for Businesses can help frame whether a workflow is worth automating before you spend serious time building it.
Legal Agent Benchmark: Fable 5 Leads, but Legal Agents Are Not Solved
Anthropic’s benchmark image reports 13.3% for Claude Mythos 5 / Fable 5 on the Legal Agent Benchmark, compared with 10.4% for Opus 4.8, 2.1% for GPT-5.5, and 0.0% for Gemini 3.1 Pro.
This is a fascinating result because it shows both progress and limitation.
A 13.3% all-pass-style legal-agent result can still be meaningful if the benchmark is strict. But it also means the category is nowhere near solved. Legal work requires precision, grounding, domain knowledge, judgment, citation, format compliance, and awareness of risk.
So the right framing is:
Fable 5 may be meaningfully stronger at legal-agent workflows, but human legal review remains mandatory.
That is true for legal, finance, healthcare, and any other high-stakes domain.
HealthBench Professional and Biology: Strong Capability, Strong Restrictions
Anthropic’s official table reports 66.0% for Claude Mythos 5 / Fable 5 on HealthBench Professional, compared with 56.9% for Opus 4.8 and 51.8% for GPT-5.5. It also reports 83.9% on the human-solved subset of BioMysteryBench and 46.1% on the hard subset, but those biology numbers are starred in the official table.
The star matters.
Anthropic explicitly says Fable 5 falls back to Opus 4.8 on most requests related to biology and chemistry for now. The company says it chose broad safeguards to release Fable safely as soon as possible, even at the cost of false positives. It also says it plans trusted-access biology programs where some approved biomedical researchers and companies can access Mythos-class biology capabilities with biology and chemistry safeguards removed, while cyber safeguards remain in place.
That means the public article should not say:
Claude Fable 5 gives everyone full Mythos-level biology capability.
That would be wrong.
A better version is:
The underlying Mythos-class model appears very strong in biology and health-related evaluations, but public Fable 5 is intentionally restricted in many biology and chemistry workflows.
That distinction is essential.
Cybersecurity: Why Mythos 5 Is Restricted
The cyber story is where Anthropic’s launch becomes unusual.
Anthropic’s official benchmark chart reports 78.0% for Claude Mythos 5 / Fable 5 on ExploitBench Cap%, compared with 40.0% for Claude Opus 4.8 and 34.0% for GPT-5.5. But this is also starred, and Anthropic’s table footnote says starred benchmarks show larger differences because safeguards affect cybersecurity and biology-related questions.
Anthropic says Mythos-class models can discover and exploit software vulnerabilities and can perform multiple parts of cyberattack workflows. Because of that, Fable 5 includes classifiers for cybersecurity, biology and chemistry, and distillation. When those classifiers detect covered requests, Anthropic says the response is automatically handled by Claude Opus 4.8 instead, and users are informed.
This is one of the clearest examples of why Fable 5 and Mythos 5 have different names.
Mythos 5 is the restricted trusted-access model. Fable 5 is the public model with safeguards.
Anthropic also says it extensively red-teamed the classifiers, including an external bug bounty that produced no universal jailbreaks in more than 1,000 hours of testing.
The responsible way to cover this is high-level. The article should not teach misuse. The point is not “here is how strong Fable is at hacking.” The point is that Anthropic believes the underlying model’s cyber capability is strong enough to require a different release structure.
Data Retention: The Enterprise Tradeoff
Fable 5 also comes with a data-handling tradeoff.
Anthropic’s data retention help page says prompts submitted to, and outputs generated by, Mythos-class models are retained for 30 days for trust and safety purposes on every platform where these models are offered. The page says this applies to Mythos-class models and future models with similar capabilities that Anthropic designates as covered models.
The same page clarifies that this change mainly affects organizations using zero data retention configurations in Claude Console, Claude Code with ZDR in Claude Enterprise, or cloud access through AWS Bedrock, Google Cloud Agent Platform, or Microsoft Foundry with ZDR. Consumer plans are unaffected by this update because Anthropic says those surfaces already retain inputs and outputs for safety purposes.
Anthropic says retained data is not used to train new Claude models for non-safety purposes. It also says employee access is limited to serious-harm flags or written customer request, that access is logged, and that data is deleted after 30 days except in rare safety-investigation or legal cases.
For enterprise buyers, this is not a minor detail.
If your company uses strict zero-data-retention workflows, Fable 5 may require a separate evaluation. The model may be worth it, but the retention requirement needs legal, security, and procurement review.
Fable 5 Pricing: Expensive, but Not Automatically Bad Value
At $10 / MTok input and $50 / MTok output, Claude Fable 5 is twice the base token price of Claude Opus 4.8, which Anthropic lists at $5 / MTok input and $25 / MTok output.
That sounds expensive. It is expensive.
But the more useful question is not “what is the token price?” The more useful question is:
What is the cost per successful task?
A cheaper model that fails three times may be more expensive than a stronger model that succeeds once. That is especially true for coding agents, where the real cost includes:
- developer supervision
- failed edits
- broken tests
- review time
- regression risk
- context resets
- time spent prompting around mistakes
Fable 5 becomes most attractive when the task is hard enough that weaker models waste time.
Prompt caching also matters. Anthropic says cache reads cost 10% of the standard input price and that caching pays off after one read for a 5-minute cache duration or after two reads for a 1-hour duration. For long codebase or document workflows, caching can materially change the economics.
Batch processing also matters. Anthropic says the Batch API gives a 50% discount on input and output tokens, bringing Fable 5 to $5 / MTok input and $25 / MTok output for asynchronous batch jobs.
So the practical pricing rule is:
- Use Fable 5 for hard, valuable, failure-prone work.
- Use Opus, Sonnet, or Haiku for routine work.
- Use caching when sending large repeated context.
- Use Batch API when the job is large and not time-sensitive.
- Measure cost per successful task, not cost per token.
Fable 5 vs Opus 4.8
Claude Opus 4.8 is still very relevant.
Anthropic’s model overview says Opus 4.8 is its most capable Opus-tier model for complex reasoning, long-horizon agentic coding, and high-autonomy work, while pointing users to Claude Fable 5 for workloads that need the highest available capability.
That gives the clean model-selection logic:
Use Claude Fable 5 when:
- the task is long
- the repo is large
- the task spans many files
- the project requires planning
- the work requires tool use
- the model must verify its own output
- weaker models keep failing
- the output is valuable enough to justify the price
- you need the best public Claude model available
Use Claude Opus 4.8 when:
- you need high quality but lower cost
- the task is hard, but not extreme
- you want strong reasoning without Fable pricing
- the task might touch restricted areas where Fable falls back anyway
- data-retention requirements are a blocker for your workflow
Use Sonnet or Haiku when:
- the task is simple
- latency matters
- cost matters
- you are doing high-volume summarization or classification
- the work does not require frontier-level planning
That is probably the right way to treat Fable 5 in production: not as the default model for everything, but as the top-tier escalation model for serious work.
Fable 5 vs GPT-5.5 and Gemini 3.1 Pro
Anthropic’s own chart shows Fable 5 / Mythos 5 ahead of GPT-5.5 and Gemini 3.1 Pro on the listed benchmarks that matter most to this launch: SWE-bench Pro, FrontierCode Diamond, GDPval-AA, GDP.pdf, Blueprint-Bench 2, AutomationBench, OSWorld-Verified, Legal Agent Benchmark, Terminal-Bench 2.1, HealthBench Professional, and several starred reasoning, biology, and cyber rows.
CursorBench adds another real-world coding-agent comparison. Cursor reports Fable 5 Max at 72.9%, GPT-5.5 Extra High at 64.3%, and Opus 4.8 Max at 63.8% on CursorBench 3.1.
The caveat is that model comparisons are never universal.
Different benchmarks use different harnesses, budgets, prompts, tools, grading methods, and effort levels. Some benchmark results come from model labs. Some come from independent benchmark providers. Some are partner evals. Some are public leaderboards. Some are internal or private. A good article should not declare a universal winner across all AI tasks based only on one launch table.
The more careful conclusion is:
Claude Fable 5 appears strongest in the areas Anthropic is targeting: long-horizon coding, agentic workflows, vision-heavy work, computer use, and complex professional tasks.
That is narrower than “best model at everything,” but it is also more useful.
What Feels Proven
The coding story feels the strongest.
Fable 5 has strong public numbers across SWE-bench Pro, SWE-bench Verified, FrontierCode, CursorBench, and Terminal-Bench. Those are not identical benchmarks. They test different parts of the coding-agent stack. The fact that Fable 5 looks strong across all of them is the most important signal in the launch.
The long-horizon agent story also feels credible. Anthropic’s own product positioning, customer comments, Claude Code support, and benchmark choices all point in the same direction: Fable 5 is built for tasks that require many steps, many files, tools, memory, planning, and verification.
The vision-plus-coding story may be underrated. Fable 5’s ability to work from screenshots, diagrams, PDFs, charts, and visual goals could matter just as much as its raw coding ability, especially for app builders and frontend workflows.
What Still Feels Unproven
Independent replication matters. Some results come from Anthropic’s launch materials, some from partner or product-specific evals, and some from benchmark providers. Real-world performance will depend heavily on harness, effort level, prompt quality, tools, context management, and review process.
The safeguard experience also needs time in the wild. Anthropic says fallback happens in less than 5% of sessions on average, but false positives could still frustrate users in edge cases.
And the enterprise data-retention requirement is a real adoption issue for some organizations. Fable 5 may be worth it, but it is not a drop-in replacement for every zero-data-retention workflow.
How Developers Should Test Claude Fable 5
Do not test Fable 5 with toy prompts.
A model like this should be tested on work that cheaper models struggle with. A practical developer eval should include five tasks from a real repo:
| Task type | Example |
|---|---|
| Multi-file bug | Fix a bug that requires reading logs, tests, and several files |
| Refactor | Move a feature to a cleaner architecture without breaking tests |
| Migration | Upgrade a dependency or framework across the repo |
| Frontend vision task | Recreate a UI from screenshot and compare output visually |
| Test loop | Write tests, run them, debug failures, and repair implementation |
Track:
- success or failure
- number of turns
- total cost
- files changed
- tests passed
- tests added
- review issues
- human interventions
- regressions
- whether the final diff was actually mergeable
The winner is not the model with the prettiest first answer. The winner is the model that produces the best reviewed, tested, working result at the lowest total human-plus-token cost.
How Businesses Should Test Claude Fable 5
For business users, the best Fable 5 tests should involve messy context and real deliverables.
Use tasks like:
- analyze a 100-page PDF
- extract key risks from contracts
- build a market research brief from multiple sources
- summarize a board deck and flag inconsistencies
- compare financial tables across documents
- create an implementation plan from rough notes
- turn messy meeting notes into a project plan
- perform a multi-step spreadsheet or operations workflow
Score the outputs on:
| Criterion | Question |
|---|---|
| Accuracy | Did it get the facts right? |
| Grounding | Did it point back to the right source material? |
| Completeness | Did it cover all required issues? |
| Judgment | Did it make sensible tradeoffs? |
| Format | Was the final output usable? |
| Supervision | How much correction was needed? |
| Cost | Was the result worth the model spend? |
| Risk | Did the task touch restricted or high-stakes areas? |
For business teams, Fable 5 should not be judged as a chatbot. It should be judged as an expensive but powerful knowledge-work engine.
Final Verdict: Claude Fable 5 Is the First Public Sign of the Mythos Era
Claude Fable 5 is Anthropic’s most important public model release in a while because it changes the shape of the product.
This is not just “Claude got smarter.” It is Anthropic releasing a public, safeguarded version of its Mythos-class capability tier. The model is stronger on long-horizon coding, agentic software engineering, vision-heavy workflows, document-heavy knowledge work, computer use, legal tasks, automation, and professional reasoning. The most convincing evidence is the coding stack: SWE-bench Pro, SWE-bench Verified, FrontierCode, CursorBench, and Terminal-Bench all point toward a model that can handle more serious software work than previous public Claude models.
But Fable 5 is also a new kind of release.
It has fallbacks. It has domain-specific safeguards. It has 30-day retention requirements for covered-model traffic in affected business contexts. It is not unrestricted Mythos 5. And for some users, that will matter just as much as the benchmark scores.
The simplest conclusion is this:
Claude Fable 5 is the model to test when the work is too hard, too long, too visual, too multi-step, or too important for cheaper models.
For simple prompts, it is probably overkill.
For serious coding agents, long migrations, difficult codebase cleanup, design-to-code workflows, complex PDF analysis, professional research, and multi-stage business deliverables, Fable 5 may be the new model to beat.
The Mythos era is here. Fable 5 is the version most people can actually use.
Kingy Launch Brief
Put the week’s verified AI launches in your inbox.
Every Friday, the verified AI launches, apps, funding rounds, pricing changes and under-the-radar moves worth knowing—source-linked and explained in five minutes.
Free · Every Friday · Unsubscribe anytime · No daily email