

Open-source AI models are no longer a side quest. For many teams, they are now the practical default for private assistants, local coding, RAG, model experiments, internal automation, and cost-controlled production systems. But the phrase “open-source AI model” is messy. Some models are genuinely open source. Some are open weight. Some are permissively licensed. Some are research-only. Some are downloadable but restricted enough that calling them open source is misleading.
This guide is Kingy.ai’s practical map to the best open source AI models and open-weight AI models in 2026. It is written for founders, creators, developers, technical marketers, power users, and business teams who need to choose models, not just admire benchmark charts. If you want broader site context, pair it with the token budgeting and model selection guide, the AI stack audit guide, and the Kingy AI open-weight model launch tracker.
It covers open weight AI models, open source language models, best local AI models, best small language models, open source coding models, open source vision language models, Ollama models, llama.cpp models, and vLLM open source models in one place. The point is not keyword stuffing. It is that these searches are really the same decision: which model can you legally, affordably, and reliably use for the job in front of you?

Table of Contents
- Quick answer: which model should you use?
- Open source vs open weight
- Major model families
- Specs comparison table
- Benchmarks and rankings
- Storage and memory requirements
- Hardware requirements
- Ollama, llama.cpp, vLLM, SGLang, and other stacks
- Capabilities
- When to use which model
- Open models vs closed frontier models
- Fine-tuning and customization
- Recommended model stacks
- FAQ
Quick Answer
If you only need a starting point, use the table below. The recommendations are deliberately practical: they separate local laptop use from server-class open weights, and they treat license risk as part of model quality.
| Use case | Model family | Why it wins | Hardware needed | License notes | Caveat |
|---|---|---|---|---|---|
| Best overall open-weight model | GLM-5.2 / MiniMax M3 | Use GLM-5.2 when live benchmark position and long-horizon reasoning matter; use MiniMax M3 when multimodal coding-agent work and 1M context are central. | Server or hosted | MIT for GLM-5.2; review MiniMax M3 license | Too large for normal laptops. |
| Best local laptop model | Gemma 4 12B or Phi-4-mini | Strong small-to-mid models with local-first design and manageable memory needs. | 16-32 GB unified/RAM | Apache 2.0 for current Gemma 4; MIT for Phi | Smaller models still lose to big server models on hard reasoning. |
| Best for coding | Qwen3-Coder / Devstral 2 | Qwen3-Coder is built for agentic coding and tool use; Devstral is coding-agent focused with permissive options. | Hosted or multi-GPU for largest; 24B/32B for local | Apache/custom depending checkpoint | Benchmark on your repo before trusting automated edits. |
| Best for agents | GLM-5.2, Kimi K2.6, MiniMax M3 | Long-horizon task execution, tool use, and multimodal context are the core design targets. | Hosted or server-class | MIT/modified/community licenses | Agent reliability depends on tools, sandboxing, and evals, not only the model. |
| Best for reasoning | DeepSeek-R1 / Magistral Small | R1 remains a strong open reasoning reference; Magistral Small is a practical 24B reasoning option. | R1: server/hosted; Magistral: high-end local | MIT for R1; Apache 2.0 for Magistral Small | Reasoning models can be slower and more verbose. |
| Best long context | DeepSeek V4, MiniMax M3, Llama 4 Scout | These families publish very large context windows; Scout is notable for 10M context, while DeepSeek/MiniMax target 1M. | Server or hosted | Varies by family | Long context raises KV cache and latency costs. |
| Best vision-language | Qwen3-VL, InternVL3.5, Gemma 4 | Strong open VLM choices across OCR, documents, image reasoning, and multimodal agents. | 8B-30B local to server | Model-specific | Vision accuracy is task-specific; test with your images. |
| Best permissive commercial stack | Qwen, Gemma 4, Phi, Mistral 3, GLM | These families include Apache 2.0 or MIT checkpoints suitable for many commercial deployments. | Depends on size | Apache 2.0/MIT on selected checkpoints | Always verify the exact checkpoint license. |
| Best low-VRAM machines | Phi-4-mini, Gemma 4 E2B/E4B, Qwen small | Small models are practical for 8-16 GB machines and low-latency local tools. | 8-16 GB RAM/VRAM | Permissive options available | Use RAG or tools to compensate for smaller model knowledge. |
| Best for embeddings/RAG | BGE-M3, Nomic Embed v2, Jina v3, Arctic Embed 2.0 | Dedicated embedding/reranking models usually beat chat models for retrieval. | CPU/GPU depending throughput | Model-specific | Evaluate on your actual corpus. |
Open Source vs Open Weight
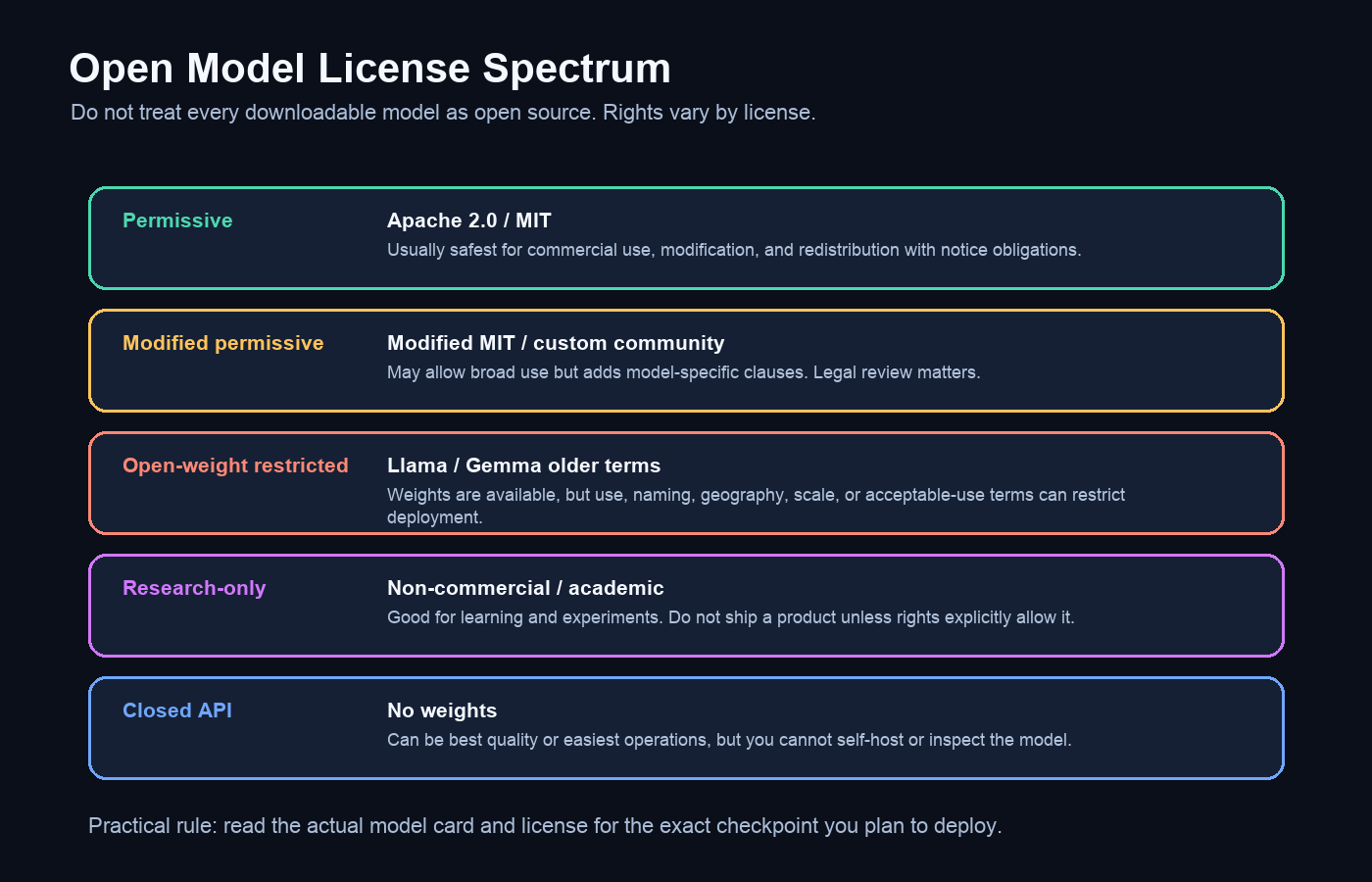
The terminology is the first trap. The Open Source AI Definition says an open source AI system should provide enough information to understand, use, modify, and share the system, including code and data information used to derive the parameters. In everyday AI discourse, however, many people call a model “open source” when only the trained weights are downloadable. That is often better described as open weight.
Weights are the learned numerical parameters of a model. Training code is the software used to produce those weights. Inference code is the software that runs the model after training. Datasets, data filters, tokenizer choices, training recipes, post-training data, reward models, and evaluation harnesses are also part of reproducibility. If a lab publishes weights but keeps training data and training code private, builders can run and fine-tune the model, but cannot fully reproduce it.
That distinction matters because licensing is not an academic footnote. It decides whether you can put a model inside a SaaS product, fine-tune it on customer workflows, serve it to millions of users, use outputs for synthetic data, or redistribute derivatives. When a model is Apache 2.0 or MIT, the default posture is usually permissive. When a model is under a community license, modified MIT, research license, or acceptable-use policy, the right answer is: read the exact license for the exact checkpoint.
| License type | Plain-English meaning | Commercial use? | Examples | Watch out for |
|---|---|---|---|---|
| Apache 2.0 | Permissive open source license | Yes | Apache 2.0; current Gemma 4, Mistral Small 3.2, many Qwen/Mistral checkpoints | Keep notices; patent language is useful for enterprise review. |
| MIT | Short permissive license | Yes | MIT; DeepSeek-R1, Phi, GLM-5.2 | Simple, permissive, but still preserve license/copyright notices. |
| Modified MIT | Permissive-like custom license | Usually, but read terms | Kimi K2.6, Devstral 2 | Not the standard MIT license. Treat as legal-review required for products. |
| Llama Community License | Open-weight restricted license | For many users, but not unrestricted | Llama 4 | Not OSI open source according to OSI criticism; restrictions include scale and policy terms. |
| Research-only/custom | Limited use license | Often no | Older or specialized research checkpoints | Do not deploy commercially unless the license explicitly permits it. |
How To Choose
A good model decision starts with constraints. Ask these questions in order: must the model run locally? Must the license allow commercial use? Is the task mostly coding, reasoning, retrieval, writing, vision, or customer support? How much context do you really need? What latency is acceptable? How many users will hit the model at once? What will you do when the model is wrong?
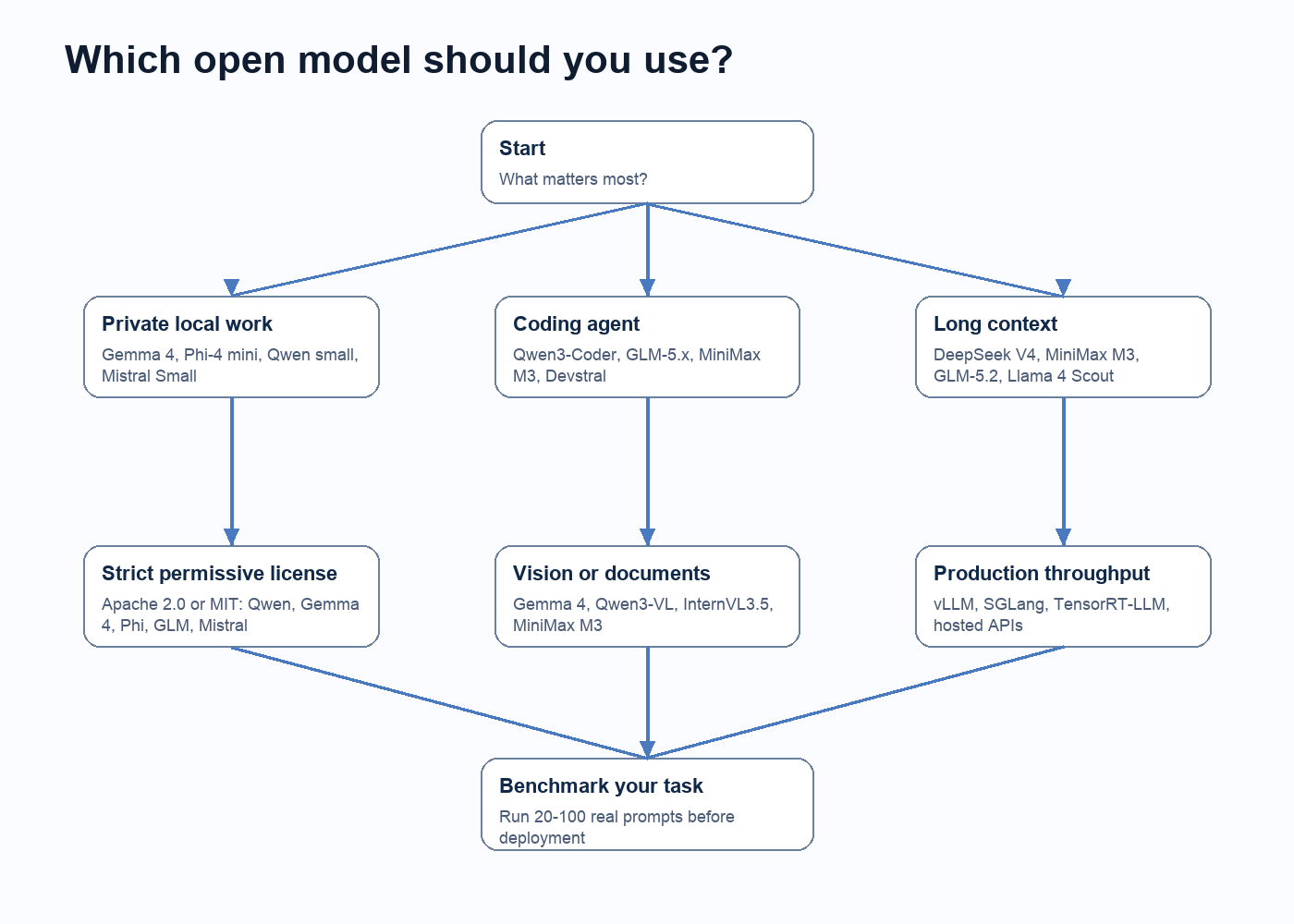
- Use small local models when privacy, offline access, and low cost matter more than frontier reasoning.
- Use 24B-32B class local models when you need stronger coding, summarization, or document work on a workstation.
- Use hosted or server-class open weights when you need agentic coding, long context, multimodal reasoning, or many concurrent users.
- Use embeddings and rerankers for retrieval. Do not force a chat model to be your search engine.
- Use closed frontier APIs when the task is high value, ambiguous, multimodal, safety-sensitive, or not yet reliable on open models.
Major Model Families
Meta Llama
Meta’s Llama line remains one of the most important open-weight ecosystems because it has broad tooling, fine-tunes, quantizations, and community support. The current Llama 4 family includes Scout and Maverick, described in the official Llama 4 model card as mixture-of-experts, natively multimodal models for multilingual, coding, tool-calling, and agentic systems. Meta says Scout uses 17B active parameters with 16 experts and offers a 10M context window; Maverick uses 17B active parameters with 128 experts, according to the Llama 4 announcement.
Llama is best treated as open weight, not fully open source. The license is useful for many builders, but it is not a standard permissive license. The Open Source Initiative has explicitly objected to Meta’s open-source terminology for Llama licenses. Use Llama when you want ecosystem reach, multimodal support, and strong local/server deployment options, but check the license before building a large commercial product.
Qwen
Qwen is one of the strongest families for practical builders because it covers tiny local models, dense mid-size models, MoE flagships, vision-language models, embeddings, and coding models. The Qwen3 release introduced a broad suite of dense and MoE models, with Qwen3-235B-A22B as a flagship. Qwen3-Coder is specifically aimed at agentic coding, browser-use, and tool-use workloads, according to the Qwen3-Coder release.
Qwen is often a first stop for open source LLMs because many checkpoints are Apache 2.0, perform well across English and multilingual workloads, and are supported by vLLM, SGLang, Transformers, GGUF tooling, Ollama, and hosted providers. The caveat is license variance across older releases. The Qwen2.5-Coder table shows why you must check exact checkpoints: most sizes were Apache 2.0, but some older models used Qwen Research or Qwen custom licenses.
DeepSeek
DeepSeek is now a core open-weight family for reasoning, coding, and long context. DeepSeek-R1 remains a landmark open reasoning release, with MIT-licensed code and weights. DeepSeek-V3 is a 671B total / 37B active MoE model and supports commercial use under its model license. In 2026, the DeepSeek V4 preview added V4-Pro at 1.6T total / 49B active and V4-Flash at 284B total / 13B active, both with 1M context.
The practical takeaway: DeepSeek belongs on any shortlist for reasoning, coding, and long-context experiments, but the largest models are not laptop models. They are hosted or server-class deployments. R1 distillations can be useful locally, but do not assume a small distilled model behaves like the full model.
Mistral
Mistral has one of the clearest builder-friendly open model portfolios. Mistral Small 3.2 is a 24B multimodal model with 128K context under Apache 2.0. Magistral Small is a 24B reasoning model under Apache 2.0. Devstral 2 targets coding agents, with Devstral Small 2 under Apache 2.0 and the larger Devstral 2 under a modified MIT license. Mistral 3 adds small dense models and Mistral Large 3, described as a 675B total / 41B active MoE family under Apache 2.0.
Mistral is especially attractive when you want a permissive license and practical local sizes. The 24B class sits in a useful middle ground: much more capable than tiny laptop models, but still plausible on a 32GB Mac or 24GB GPU when quantized.
Google Gemma
Gemma has become one of the best local AI model families for builders who care about small, efficient, multimodal models. The Gemma 4 model card describes a multimodal family with up to 256K context, 140+ language support, and Apache 2.0 licensing for current Gemma 4 releases. Gemma 4 12B is especially interesting because Google describes it as a mid-sized encoder-free multimodal model with native audio input, designed to bring agentic multimodal intelligence to laptops.
Gemma is a top recommendation for local laptop use, private writing, image/document understanding, and edge experiments. The caveat is that older Gemma generations used Google-specific terms, so do not assume the license of one Gemma release applies to another.
Microsoft Phi
Phi is the small-language-model family to know. Microsoft describes Phi as open source through the MIT License and designed for on-device use cases. Phi-4-mini-instruct supports a 128K context window and is MIT licensed. Phi-4-multimodal-instruct handles text, image, and audio inputs and also has 128K context.
Phi is not the model family you pick when you need the best possible open reasoning on a huge server. It is the family you pick when small, cheap, private, and fast are the point. It is useful for assistants, classification, structured extraction, mobile/edge prototypes, and local workflows where a 70B model would be absurd.
Z.ai GLM
Z.ai’s GLM line is now one of the strongest open-weight families for agentic engineering. The GLM-4.5 docs describe GLM-4.5 as 355B total / 32B active and GLM-4.5-Air as 106B total / 12B active. GLM-5 scales to 744B total / 40B active and targets long-horizon agentic tasks. The newest GLM-5.2 announcement emphasizes MIT licensing and 1M-token long-horizon work.
For buyers comparing model families, GLM is a serious candidate for best overall open-weight model in server-class deployments. The current Artificial Analysis leaderboard snapshot lists GLM-5.2 as the top open-weight model by its Intelligence Index. Do not treat that as universal truth; treat it as a strong signal to include GLM in your own eval.
Kimi and MiniMax
Moonshot AI’s Kimi and MiniMax’s M-series are important because they focus on agentic work, long-horizon coding, and multimodal context rather than ordinary chat alone. Kimi K2 is a 1T total / 32B active MoE model optimized for agentic capabilities, and Kimi K2.6 extends that direction into native multimodal, long-horizon coding and autonomous execution. MiniMax M3 is even newer: the MiniMax M3 model card lists it as 428B total / 23B active with 1M context and native multimodality.
The model-selection note is simple: Kimi and MiniMax are not casual local downloads for most people. They are agentic frontier-style open-weight candidates for hosted or serious server environments. Their licenses are not plain Apache/MIT defaults, so review terms before commercial deployment.
Vision, Embedding, Speech, and Older Models
Open vision-language models now deserve their own shortlist. Qwen3-VL covers 4B, 8B, and 30B-A3B vision-language variants. InternVL3.5 focuses on open multimodal reasoning and efficiency. LLaVA-OneVision remains important historically and for fully open multimodal research, although you should verify data and license terms for each derivative.
For RAG, use embedding models rather than chat models. BGE-M3 supports dense, sparse, and multi-vector retrieval in one model. Nomic Embed Text v2 MoE is Apache 2.0 and supports flexible embedding dimensions. Jina embeddings v3 targets multilingual long-context retrieval. Snowflake Arctic Embed 2.0 adds multilingual retrieval and Matryoshka representation learning.
For audio, Whisper remains a foundational open speech recognition family, while NVIDIA Parakeet and similar open ASR models are worth checking for throughput and domain-specific transcription. Older families such as Grok-1, Falcon, Yi, Code Llama, and StarCoder still matter historically or in narrow workflows, but they are rarely the first recommendation for a new 2026 build unless you need their exact license, fine-tune ecosystem, or compatibility.
Llama vs Qwen vs Mistral vs DeepSeek
A large share of open model selection comes down to Llama vs Qwen vs Mistral vs DeepSeek, even though 2026 also adds GLM, Gemma, MiniMax, Kimi, and Phi to the serious shortlist. The short answer is: choose Llama for ecosystem reach, Qwen for breadth and practical permissive releases, Mistral for clean commercial deployment in useful local sizes, and DeepSeek for reasoning, coding, and long-context server-class work.
Llama is attractive when you want broad community support. You will find tutorials, fine-tunes, GGUF quantizations, adapters, cloud deployments, and local tool support everywhere. That matters for teams that need hiring familiarity or community-tested recipes. The drawback is license precision: Llama is not the cleanest answer when a procurement team asks for a standard permissive license. It is an open-weight ecosystem, not the same thing as Apache 2.0 or MIT.
Qwen is usually the most balanced default for developers who want open source LLMs across many sizes. It covers small local models, mid-size local models, huge MoE models, code-specialized models, vision-language models, embeddings, rerankers, and multilingual use. The practical caveat is that Qwen licensing has varied across older checkpoints, so a buyer should check the exact model card rather than saying ‘Qwen is Apache’ as a blanket statement.
Mistral is the clean deployment pick when you want a useful model size and a license that is easy to explain. Mistral Small, Magistral Small, Devstral Small, and Mistral 3 give teams options for writing, coding, reasoning, and production serving without jumping straight to a giant MoE. That makes Mistral especially good for small businesses, internal assistants, and startups that want self-hosting without turning infrastructure into the main product.
DeepSeek is the heavyweight reasoning and long-context option. R1 made open reasoning mainstream, V3 showed how competitive MoE design could be, and V4 pushes the long-context server tier. Use DeepSeek when quality and cost/performance matter more than laptop convenience. Avoid it when you need a tiny local assistant or when your legal team wants only standard MIT/Apache terms and the checkpoint uses a custom model license.
For the exact queries readers use – best AI model for coding, best AI model for local inference, best small language models, AI model hardware requirements, how much VRAM do AI models need, running LLMs locally, Ollama models, llama.cpp models, vLLM open source models, open source vision language models, and open source coding models – the answer changes by hardware tier. A 9B model on a laptop can be the best local inference choice even if a 700B model is best on a leaderboard. A coding model that edits your repo correctly is better than a higher-ranked chat model that cannot use tools consistently.
Specs Comparison
The table below intentionally favors verified public specs over rumor. Where a field varies by checkpoint, provider, or quantization, it says so. That is better than pretending every model has one universal deployment footprint.
| Model | Architecture | Parameters | Context | License | Best strengths | Typical hardware | Source |
|---|---|---|---|---|---|---|---|
| GLM-5.2 | MoE | Not fully summarized in this guide | 1M | MIT | Open-weight agentic reasoning, coding, long context | Server/hosted | Z.ai |
| GLM-5 | MoE | 744B / 40B active | 200K | MIT | Long-horizon agentic engineering | Multi-GPU/hosted | HF |
| MiniMax M3 | MoE | 428B / 23B active | 1M | MiniMax community/license terms | Coding, agents, multimodal long context | Multi-GPU/hosted | HF |
| DeepSeek V4 Pro | MoE | 1.6T / 49B active | 1M | DeepSeek model license | Reasoning, coding, long context | Hosted/server | DeepSeek |
| DeepSeek V4 Flash | MoE | 284B / 13B active | 1M | DeepSeek model license | Cost-sensitive long context | Server/hosted | DeepSeek |
| Qwen3-Coder 480B-A35B | MoE | 480B / 35B active | 128K to 256K+ depending provider | Apache 2.0 on public release | Agentic coding and tool use | Hosted/server | Qwen |
| Qwen3-235B-A22B | MoE | 235B / 22B active | Varies by checkpoint | Apache 2.0 on many releases | General chat, math, code, multilingual | Server/hosted | Qwen |
| Llama 4 Scout | MoE | 17B active / 16 experts | 10M | Llama Community | Long-document multimodal work | Single H100 class per Meta’s claim with quantization | Meta |
| Llama 4 Maverick | MoE | 17B active / 128 experts | 10M family context | Llama Community | Multimodal assistant and cost/performance | Single H100 host class | Llama |
| Mistral Large 3 | MoE | 675B / 41B active | Model-specific | Apache 2.0 | Frontier open Mistral option | Server/hosted | Mistral |
| Mistral Small 3.2 | Dense | 24B | 128K | Apache 2.0 | Local multimodal assistant | 32GB Mac / 24GB GPU when quantized | Mistral |
| Devstral Small 2 | Dense | 24B | Model-specific | Apache 2.0 | Local coding agent | High-end laptop/workstation | Mistral |
| Gemma 4 12B | Dense/unified multimodal | 12B | Up to 256K family | Apache 2.0 | Laptop multimodal and audio-aware work | 16-32GB unified/RAM | |
| Phi-4-mini | Dense | Small model | 128K | MIT | Low-resource instruction following | 8-16GB | HF |
| Phi-4-multimodal | Dense multimodal | Small model | 128K | MIT | Text, image, audio inputs | 8-16GB+ | HF |
| Kimi K2.6 | MoE | 1T / 32B active | Large context; verify checkpoint | Modified MIT | Agent swarms, coding, multimodal | Hosted/server | HF |
| Qwen3-VL | VLM/MoE variants | 4B, 8B, 30B-A3B variants | Large context variants | Model-specific | Vision, OCR, video, GUI/agents | Local to server | GitHub |
| InternVL3.5 | VLM family | 1B to large variants | Model-specific | Model-specific | Open multimodal reasoning | Local to server | HF |
Benchmarks and Rankings
Benchmarks are useful, but they are not commandments. LMArena captures human preference across broad tasks. Artificial Analysis combines intelligence, speed, price, and other dimensions. SWE-bench is a better signal for software engineering agents than generic code completion. LiveCodeBench is useful because it continuously collects coding problems over time to reduce contamination.
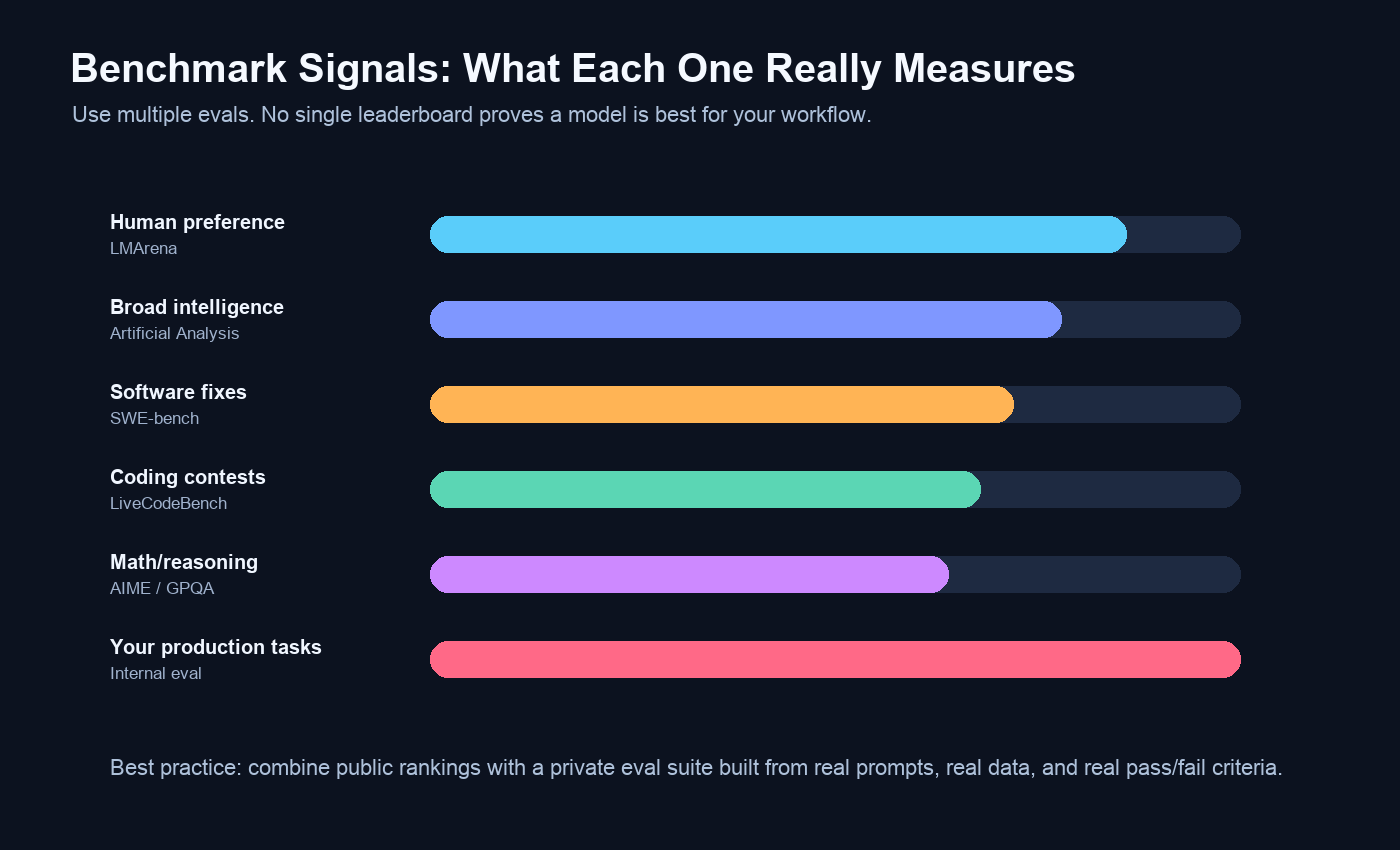
The failure mode is choosing the model with the highest public number and discovering it fails your actual workflow. Benchmark contamination, prompt sensitivity, system prompts, inference stack differences, quantization loss, MoE routing, context length, and evaluation harness details can change outcomes. A 4-bit local quant of a model is not the same product as a hosted FP8 deployment. A coding benchmark score does not prove the model can safely edit your repo. A long-context benchmark does not prove the model will faithfully use the 900th page of your legal document.
Storage and Memory
Storage is easier to estimate than runtime memory. In FP16 or BF16, each parameter is roughly 2 bytes. In 8-bit, it is roughly 1 byte. In 4-bit, it is roughly half a byte before metadata and format overhead. Quantization reduces memory and compute by lowering precision; Hugging Face summarizes this plainly in its quantization documentation. GGUF is a common local format optimized for loading and inference, according to the Hugging Face GGUF docs.
| Parameter count | FP16/BF16 weights | INT8 weights | 4-bit/GGUF estimate | Important note |
|---|---|---|---|---|
| 1B | 2 GB | 1 GB | 0.6 GB | MoE storage follows total parameters; compute follows active parameters, but serving usually still needs the experts available. |
| 3B | 6 GB | 3 GB | 1.7 GB | MoE storage follows total parameters; compute follows active parameters, but serving usually still needs the experts available. |
| 8B | 16 GB | 8 GB | 4.4 GB | MoE storage follows total parameters; compute follows active parameters, but serving usually still needs the experts available. |
| 14B | 28 GB | 14 GB | 7.7 GB | MoE storage follows total parameters; compute follows active parameters, but serving usually still needs the experts available. |
| 32B | 64 GB | 32 GB | 17.6 GB | MoE storage follows total parameters; compute follows active parameters, but serving usually still needs the experts available. |
| 70B | 140 GB | 70 GB | 38.5 GB | MoE storage follows total parameters; compute follows active parameters, but serving usually still needs the experts available. |
| 100B | 200 GB | 100 GB | 55.0 GB | MoE storage follows total parameters; compute follows active parameters, but serving usually still needs the experts available. |
| 400B MoE | 800 GB | 400 GB | 220.0 GB | MoE storage follows total parameters; compute follows active parameters, but serving usually still needs the experts available. |
KV cache is the hidden memory bill. The longer the context window and the more concurrent users you serve, the more memory goes to cached attention keys and values. NVIDIA’s TensorRT-LLM docs discuss FP8 and lower-precision KV cache options because KV cache can occupy persistent memory under large batch sizes or long contexts. This is why a model that fits at 4K context can fail at 128K context.

Hardware Requirements
For local AI, the most important number is usable memory. NVIDIA users usually think in VRAM. Apple Silicon users think in unified memory; MLX documentation notes that Apple Silicon CPU and GPU share the same memory pool. AMD data-center users increasingly have ROCm paths; AMD’s ROCm vLLM documentation covers optimized vLLM images for Instinct MI300X-class GPUs. Consumer AMD can work, but CUDA support remains smoother for many local tools.
| Hardware tier | Practical model class | Examples | Reality check |
|---|---|---|---|
| 8 GB Mac/PC | 1B-4B Q4 | Phi-4-mini, Gemma E2B, Qwen small | Good for simple local chat; not serious coding agents. |
| 16 GB MacBook | 4B-9B Q4, some 12B with care | Gemma E4B/12B, Phi, Qwen small | Good private assistant; watch context size. |
| 32 GB MacBook/Mac mini | 12B-24B Q4 | Gemma 12B, Mistral Small quantized, Magistral Small | Solid local work tier. |
| 24 GB NVIDIA GPU | 24B-32B Q4/Q5; 70B with compromises | Qwen 32B, Devstral Small, Mistral Small | Best single-consumer-GPU tier. |
| 48 GB GPU | 70B Q4 or multiple smaller users | Llama/Qwen 70B class, larger context | Good workstation/server bridge. |
| 80-96 GB GPU | 70B FP8/INT8 or large MoE slices | H100/H200/H200-class deployments | Production single-GPU or multi-GPU node. |
| Multi-GPU server | 100B+ and modern MoE | DeepSeek V4, GLM, MiniMax, Qwen flagship | Use vLLM/SGLang/TensorRT and measure throughput. |
CPU-only inference is possible, especially with llama.cpp, but it is usually a patience exercise for anything beyond small models. Unified memory lets Macs load models that would not fit in a discrete GPU’s VRAM, but loading is not the same as fast generation. For production, tokens per second, time to first token, batch size, prefill speed, and cache behavior matter as much as whether the model loads.
Inference Stacks
Model choice and inference stack choice are linked. The same checkpoint can feel fast, slow, cheap, expensive, reliable, or brittle depending on how it is served. Beginners should not start with Kubernetes. Production teams should not stop at a desktop GUI.
| Stack | Best for | Use when | Notes |
|---|---|---|---|
| Ollama | Fastest beginner path | Mac/Windows/Linux local models | Ollama wraps model management and local serving. |
| LM Studio | Desktop GUI | Non-developers testing GGUF models | Good for prompt testing and local APIs. |
| llama.cpp | Local engine and GGUF ecosystem | CPU, Apple Silicon, NVIDIA/AMD paths | GGUF and quantization make it the local backbone. |
| MLX | Apple Silicon native | Mac inference and fine-tuning | MLX benefits from unified memory. |
| vLLM | High-throughput serving | Production APIs and batching | vLLM is a default production serving choice. |
| SGLang | Low-latency agent serving | Structured output and multimodal serving | SGLang is strong for agentic production stacks. |
| TensorRT-LLM | NVIDIA-optimized deployment | Enterprise NVIDIA GPU serving | TensorRT-LLM adds optimized kernels, batching, and quantization. |
| OpenRouter/Together/Fireworks/Groq/Cerebras | Hosted access | Fast experiments and production without owning GPUs | Use when hardware/ops would slow the product down. |
Capabilities
| Capability | Best model families | Practical guidance |
|---|---|---|
| Writing and chat | Gemma, Qwen, Mistral, Llama | Use a mid-size model for everyday work; benchmark tone and factuality. |
| Coding | Qwen3-Coder, Devstral, GLM, MiniMax, Kimi | Use repo-based evals and never allow blind production edits. |
| Agents and tools | GLM, Kimi, MiniMax, Qwen, DeepSeek | Tool design, sandboxing, retries, and logging matter as much as the base model. |
| Long documents | DeepSeek V4, MiniMax M3, GLM-5.2, Llama 4 Scout | Long context is expensive; retrieval plus summarization can be better. |
| RAG and search | BGE-M3, Jina, Nomic, Arctic Embed, rerankers | Use embeddings for retrieval, a reranker for precision, and an LLM for synthesis. |
| Vision/OCR | Qwen3-VL, InternVL3.5, Gemma 4, MiniMax M3 | Evaluate on your actual PDFs, screenshots, charts, and forms. |
| Audio | Whisper, Parakeet, Phi multimodal, Gemma audio variants | Separate ASR from reasoning unless a unified multimodal model is clearly better. |
| Fine-tuning | Qwen, Mistral, Gemma, Phi, Llama derivatives | Use LoRA/QLoRA for behavior and domain style; use RAG for fresh facts. |
When To Use Which Model
Use Qwen or Devstral for coding when you want permissive checkpoints and strong tool-use behavior. Use GLM, MiniMax, Kimi, or DeepSeek when you are testing server-class coding agents or long-horizon autonomous workflows. Use Gemma, Phi, or small Qwen variants when you need local privacy and responsiveness. Use Mistral Small or Magistral when you want a practical 24B local model with clear licensing. Use Llama when ecosystem reach and community support matter, but label it open-weight and review license obligations.
- For customer support: start with RAG plus a 8B-24B model, then add human handoff and citations.
- For summarizing documents: use a model with enough context for the document, but prefer chunked workflows for reliability.
- For commercial SaaS: favor Apache 2.0 or MIT checkpoints unless legal approves custom licenses.
- For internal business knowledge bases: use embeddings, reranking, citations, and access controls before fine-tuning.
- For AI startup prototypes: use hosted open models first, then self-host only when cost, privacy, or control justifies it.
- For small devices: use Phi, Gemma, and Qwen small variants; design workflows around their limits.
Open Models vs Closed Frontier Models
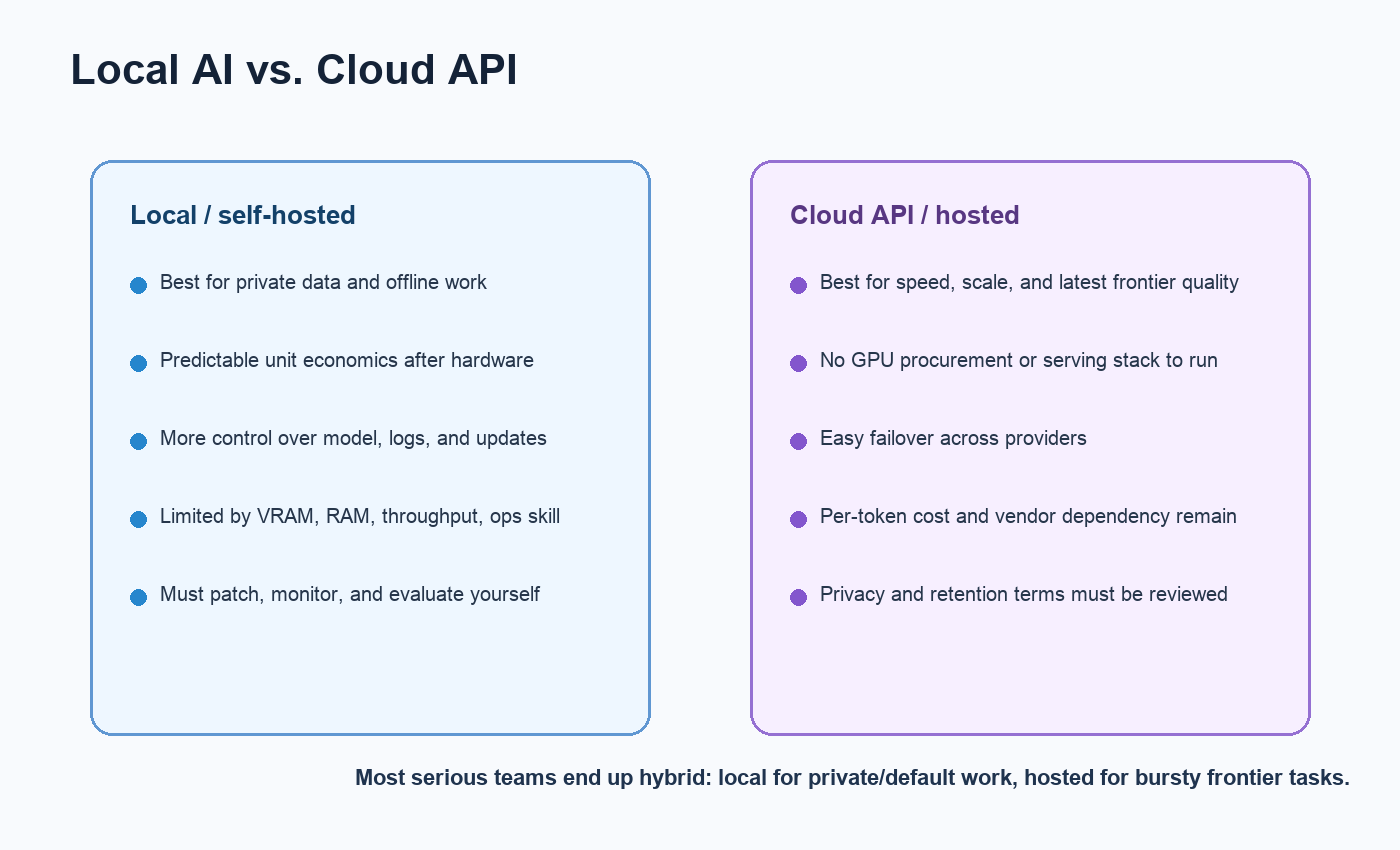
Open models are now good enough for many serious workflows: local copilots, RAG, support drafts, structured extraction, document review, private search, coding assistance, data transformation, and many agent prototypes. Closed frontier models still often win on broad reliability, hardest reasoning, newest multimodal capability, managed safety tooling, and the convenience of not running infrastructure.
The business tradeoff is not ideology. Open weights give you control, privacy, deployment flexibility, and sometimes lower marginal cost. Closed APIs give you speed, model freshness, simple scaling, and less operations burden. Hybrid is usually the grown-up answer: run cheaper local or open models by default, route hard cases to a frontier API, and log enough eval data to know when that routing should change.
Fine-Tuning and Customization
Fine-tuning is useful when you need a model to follow a stable style, output format, domain convention, or narrow behavior that prompting cannot reliably enforce. LoRA and QLoRA are the usual practical paths because they avoid full retraining. Full fine-tuning is expensive and risky unless you have a serious ML team, clean data, and a repeatable evaluation harness.
Use RAG instead of fine-tuning when the problem is knowledge freshness, document access, or citation. Fine-tuning does not magically update a model with reliable facts. It changes behavior. RAG retrieves evidence. Most business systems need both: RAG for the facts, light tuning or strong prompting for format and tone, and evals for regression control.
Constraints and Risks
Open models still hallucinate. They can be outdated, brittle under prompt injection, weak at tool use, or overconfident with long context. Quantization can reduce quality. Running locally can leak data if logs, browser tools, vector stores, or plugins are careless. Community fine-tunes vary wildly in quality. Model cards can be incomplete. Leaderboards can be gamed. Licenses can change between base, instruct, quantized, and derivative releases.
- Do not ship a model because a social post says it beats a frontier model.
- Do not assume a quantized GGUF has the same behavior as the original checkpoint.
- Do not use research-only weights in commercial products.
- Do not let agents execute code, browse, send email, or edit repositories without sandboxing and audit logs.
- Do not put sensitive data into a hosted API without reviewing retention, training, privacy, and regional terms.
Recommended Model Stacks
| Stack | Model choices | Inference tool | Hardware | Use case |
|---|---|---|---|---|
| Beginner local AI | Gemma 4 E2B/E4B, Phi-4-mini, Qwen small | Ollama or LM Studio | 16 GB RAM laptop | Private assistant, notes, simple RAG |
| Local coding | Qwen 32B class, Devstral Small, Mistral Small | llama.cpp/Ollama/LM Studio | 24 GB GPU or 32-64 GB unified memory | Repo Q&A, patches with human review |
| Private business assistant | Mistral Small, Gemma 4, Qwen, BGE-M3 | OpenWebUI + Ollama/vLLM + vector DB | Workstation or small server | Internal docs and support drafts |
| Startup MVP | Qwen/GLM/DeepSeek hosted plus local fallback | LiteLLM/OpenRouter/Together/Fireworks/vLLM | Cloud first | Speed to launch with eval logging |
| Production RAG | BGE-M3/Jina/Nomic + Qwen/Gemma/Mistral | vLLM/SGLang + reranker | Single to multi-GPU | Search, answer, cite, audit |
| Enterprise self-host | GLM, DeepSeek, Qwen, Mistral, Gemma | vLLM, SGLang, TensorRT-LLM, Kubernetes | H100/H200/B200 or MI300/MI350 class | Governed internal AI platform |
Kingy readers building product workflows should also connect model choice to distribution and measurement. The AI product demo playbook helps explain AI products clearly, while the AI search visibility guide helps teams think about being found in AI answers. Model choice is only one layer of the product stack.
Related Kingy AI Resources
Use these Kingy.ai resources to turn model selection into a real build, launch, or purchasing decision:
- AI Guides for practical AI tutorials and buying frameworks.
- AI model profiles for model-specific launch and profile coverage.
- AI Launches for structured launch intelligence.
- AI Tools Directory for finding software around your chosen model stack.
- AI coding agents for non-developers if you are choosing models for code automation.
- AI launch evaluation guide if you need a repeatable testing process.
- local LLMs and AI sovereignty guide for the privacy and ownership angle.
- AI Courses for deeper training paths.
FAQ
What is the best open-source AI model?
For server-class open weights as of June 2026, GLM-5.2, MiniMax M3, DeepSeek V4, Qwen flagship models, and Kimi K2.6 deserve evaluation. For local laptops, Gemma 4, Phi-4-mini, Mistral Small, and Qwen small/mid models are more practical.
What is the best open-weight AI model for coding?
For large hosted or server deployments, start with Qwen3-Coder, GLM-5.x, MiniMax M3, Kimi K2.6, DeepSeek V4, and Devstral 2. For local work, try Qwen 32B-class models, Devstral Small, and Mistral Small.
What is the best model to run locally?
For ordinary laptops, Gemma 4 small/12B, Phi-4-mini, and Qwen small models are good starting points. For 24GB GPUs or 32-64GB Macs, Mistral Small, Magistral Small, Qwen 32B-class models, and Devstral Small become realistic.
Can open-source AI models beat ChatGPT or Claude?
Sometimes on specific benchmarks or workflows, but not universally. Closed frontier models still tend to be stronger on broad reliability and difficult multimodal reasoning. Open models can win on privacy, control, cost, and customization.
How much VRAM do I need to run an AI model locally?
Roughly, 4-bit 7B-8B models fit in 8-12GB, 24B-32B models want 16-24GB, and 70B models want 48GB or more for a comfortable experience. Context length and KV cache can increase requirements.
Can I run a 70B model on my laptop?
Sometimes, especially on high-memory Apple Silicon or with CPU offload, but speed may be poor. For daily use, a strong 12B-32B model is often more pleasant.
What is quantization?
Quantization represents model weights and sometimes activations at lower precision, such as 8-bit or 4-bit, to reduce memory and compute. It can make local inference practical but may reduce quality.
What is GGUF?
GGUF is a model file format used heavily in llama.cpp and local inference tools. It is optimized for efficient loading and running of quantized models.
What is the difference between open source and open weight?
Open source should provide the freedoms and preferred forms needed to study, modify, and share the system. Open weight usually means the trained weights are available, while training code, data, or full reproducibility may not be.
Are open models safe for business use?
They can be, but only with license review, evaluation, access controls, logging, red-teaming, and a deployment plan. The model alone is not the safety system.
Can I use open models commercially?
Many Apache 2.0 and MIT models can be used commercially, but custom, modified, community, Llama, Gemma older, or research licenses need exact review.
Should I fine-tune a model or use RAG?
Use RAG for knowledge and citations. Use fine-tuning for stable behavior, style, and domain-specific output patterns. Many production systems use both.
What is the best model for AI agents?
For serious agents, evaluate GLM-5.x, Kimi K2.6, MiniMax M3, Qwen3-Coder, DeepSeek V4, and Devstral. Agent success depends heavily on tools, memory, permissions, and evals.
What is the best model for private company data?
Use a local or self-hosted model with a permissive license, plus a secured RAG stack. Gemma, Qwen, Mistral, Phi, and GLM checkpoints are common candidates depending on hardware.
What is the best small AI model?
Phi-4-mini, Gemma small variants, and Qwen small models are strong starting points. The best one depends on language, context, latency, and device.
What is the best open vision-language model?
Start with Qwen3-VL, InternVL3.5, Gemma 4, and MiniMax M3, then test on your actual images, PDFs, screenshots, and videos.
What is the easiest way to run an open model?
Use Ollama or LM Studio for local experiments. Use vLLM or SGLang for production serving. Use hosted providers when you need speed without GPU operations.
Final Verdict
Open models are now core infrastructure. They are good enough for many serious workflows, and in some narrow areas they are excellent. But no single model wins everything. Choose by task, license, hardware, context, privacy, latency, and cost. Beginners should start with Ollama or LM Studio and a small Gemma, Phi, Qwen, or Mistral model. Startups should benchmark open models against their real product tasks before buying GPUs. Enterprises should plan hybrid architectures, because the best answer is often local for private default work and hosted frontier models for the hardest edge cases.
The winning habit is not memorizing the current leaderboard. The winning habit is building a repeatable model-selection loop: shortlist, verify license, test on real tasks, estimate hardware, measure latency and cost, add safety controls, and revisit when the model landscape changes.







