

Updated June 24, 2026. This analysis is based on OpenAI’s announcement, Broadcom’s investor release, Reuters reporting, and public technical material from NVIDIA, Google Cloud, AWS, Microsoft, Meta, AMD, and other primary sources.
The OpenAI Jalapeño inference chip is the clearest sign yet that OpenAI wants more control over the hardware layer behind ChatGPT, the API, agents, and future model products. It is not a consumer gadget. It is not a GPU. It is not a finished public cloud product. It is a custom AI accelerator, designed with Broadcom and built into a larger deployment plan that OpenAI says should begin serving customer workloads by the end of 2026.
That distinction matters. Jalapeño is important not because it has a spicy codename, though that did make the headline writers’ job easier. It matters because inference is where AI economics compound. Every ChatGPT answer, every API completion, every coding-agent step, every enterprise copilot response, every voice turn, and every background agent action has to run through an inference stack. If OpenAI can make that stack cheaper, faster, and more power-efficient at huge scale, the effect could show up in product latency, margins, pricing, model availability, and the kinds of AI workflows that become practical.
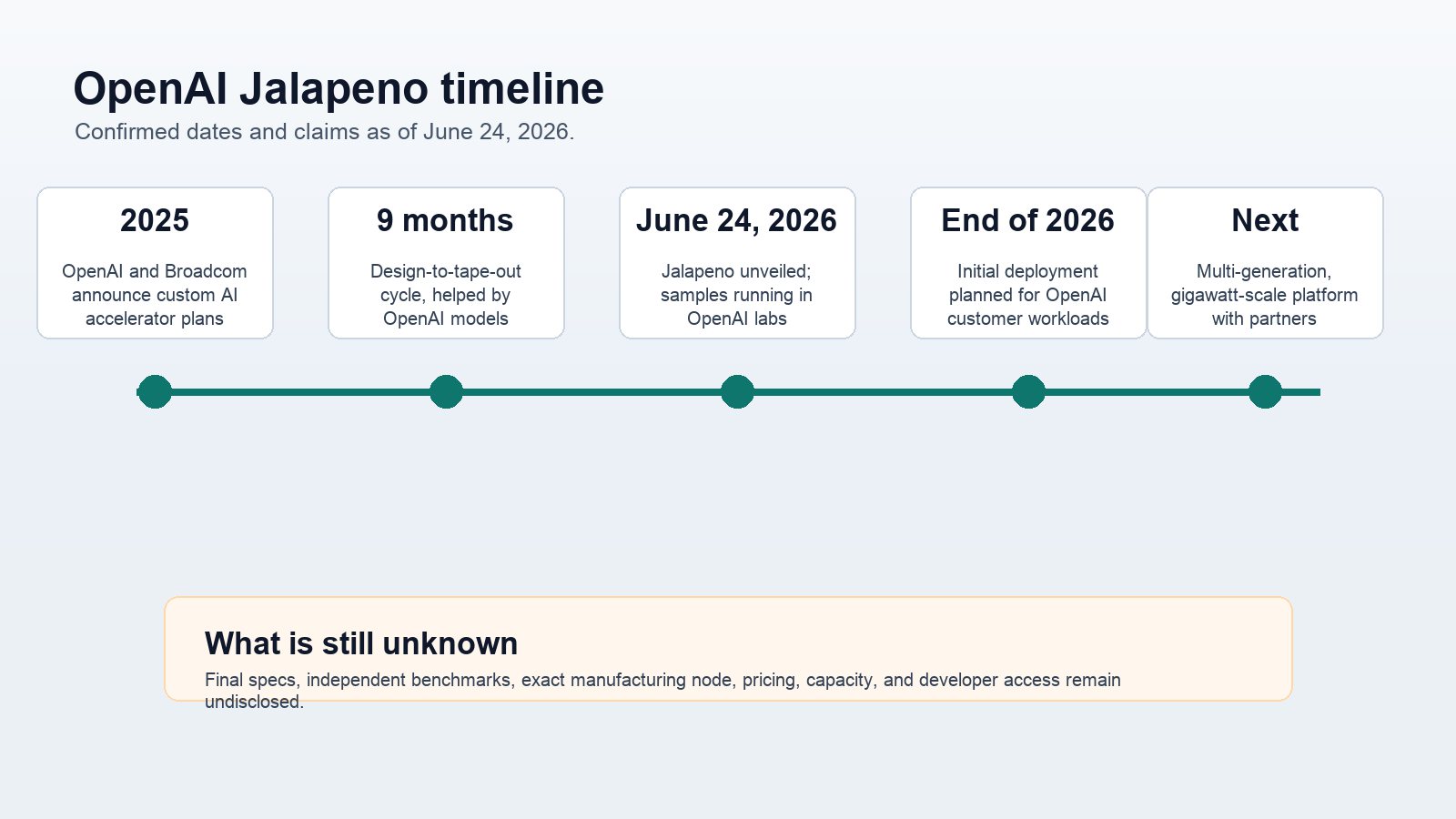
But this is also a moment to be careful. OpenAI has announced working samples and a deployment target. It has not published final architecture diagrams, memory capacity, manufacturing node, price, independent benchmark results, or a complete developer-access model. Reuters reported early performance and power claims, but those are not the same as independently replicated production numbers. The honest version is simple: Jalapeño is a credible, strategically important custom inference ASIC, and many of the most interesting details are still unknown.
Key Takeaways
- Jalapeño is an inference chip. Its job is to run trained models for live users, not to replace every GPU used in model training.
- OpenAI says samples are already running internal workloads. The announced deployment target is the end of 2026 for initial customer workloads.
- Broadcom is the silicon partner. Celestica is involved in boards, systems, and rack-level production integration.
- The chip is an ASIC. That means it can be more efficient for a narrow workload than a GPU, but less flexible across many workloads.
- OpenAI has not released full specs. Memory, process node, networking bandwidth, token throughput, cost, and independent performance per watt remain unverified.
- This does not replace NVIDIA overnight. It gives OpenAI another lane for internal serving economics while GPUs remain essential for training, experimentation, and broad accelerator supply.
- The biggest product effect may be invisible. If Jalapeño works, users may experience it as lower latency, more generous usage limits, cheaper inference tiers, or faster rollout of AI agents rather than as a chip brand they directly buy.
Table Of Contents

What Is OpenAI’s Jalapeño?
Jalapeño is OpenAI’s custom AI inference accelerator, developed with Broadcom and designed around OpenAI’s own large language model workloads. OpenAI describes it as part of a broader effort to build infrastructure capable of serving increasingly capable models at massive scale. Broadcom’s release calls it an LLM-optimized intelligence processor, which is a useful phrase if you strip away the marketing: this is silicon tuned for running language models repeatedly and efficiently.
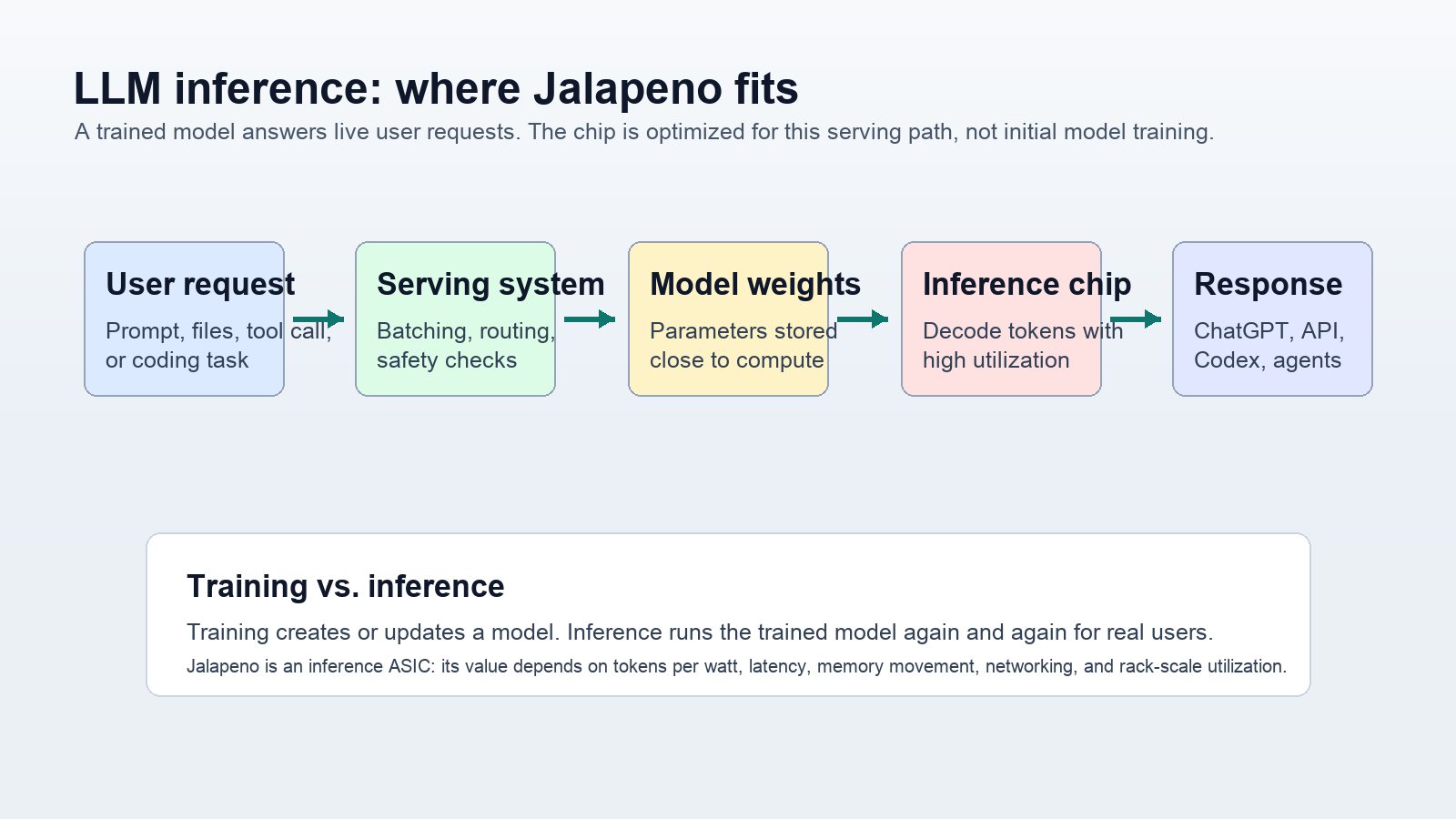
The important word is inference. Training is the expensive process of creating a model by processing enormous datasets and updating parameters. Inference is what happens after training, when the model answers prompts, reads documents, calls tools, writes code, analyzes images, or responds in a voice conversation. For a company like OpenAI, inference is not a side workload. It is the factory floor.
OpenAI says Jalapeño samples are already running OpenAI workloads in its labs. The company also says it plans to deploy the chip by the end of 2026, starting with customer workloads. Reuters added that early samples were hitting internal targets on power and performance and that one test workload involved a coding-oriented GPT model. Those are meaningful early signals, but they are not equivalent to a public benchmark suite.
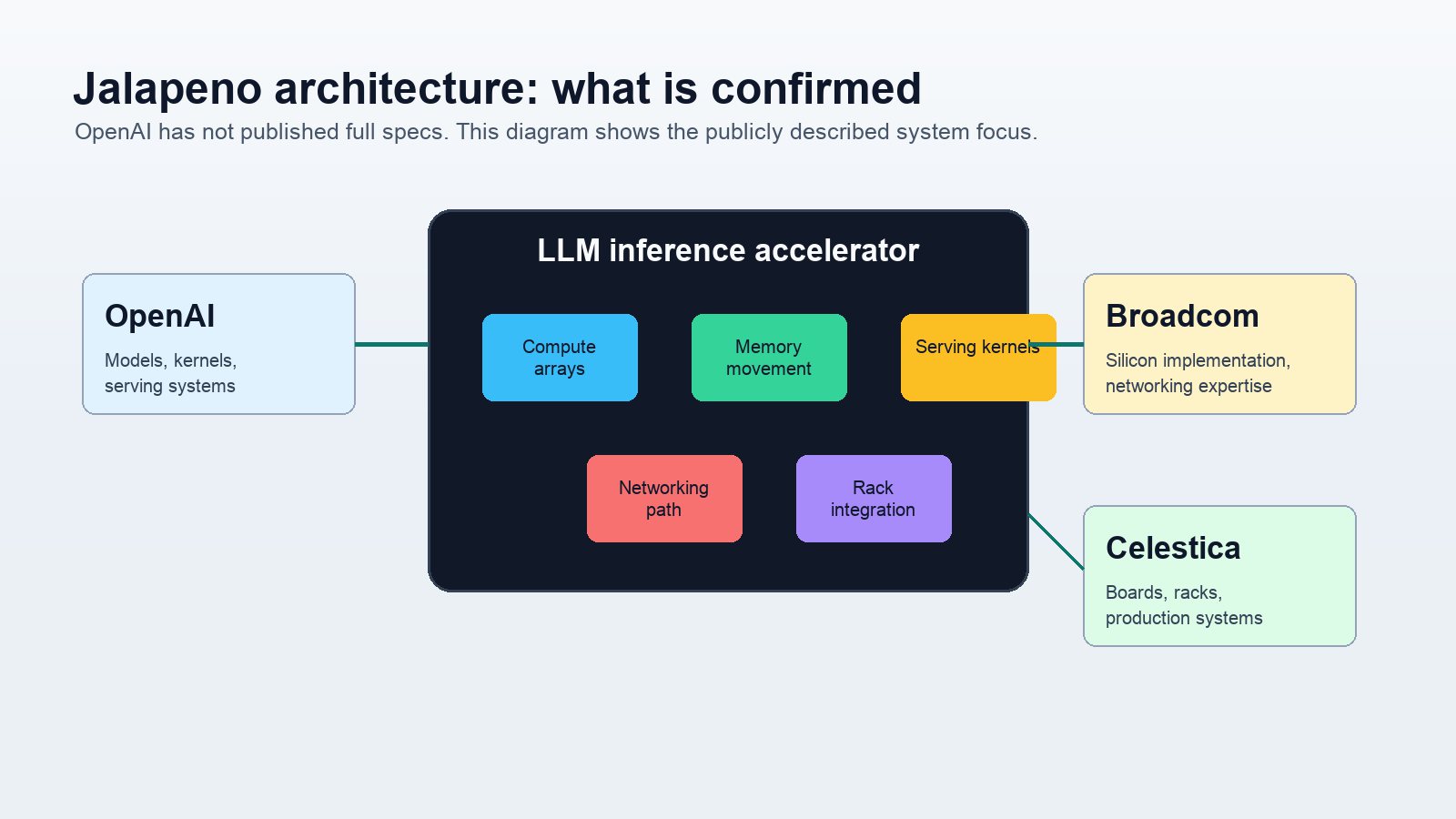
The chip is also best understood as a system project, not just a die. OpenAI is not merely buying a custom part and plugging it into generic servers. The company is working with Broadcom on the silicon and Celestica on production boards and rack-level systems. That matters because inference performance depends on the whole pipeline: memory, networking, thermals, routing, batching, software kernels, model architecture, and deployment operations.
Confirmed Facts Vs Unknowns
| Question | What is confirmed | What is not yet public |
|---|---|---|
| What is Jalapeño? | A custom OpenAI inference accelerator developed with Broadcom for LLM workloads. | The full microarchitecture, chiplet strategy, die size, manufacturing node, and model-specific kernel details. |
| What workload is it for? | Inference: serving trained models for users and customers. | Which exact OpenAI models will run on it at launch, and how workloads will be split across GPUs and custom silicon. |
| Does it work? | OpenAI says lab samples are running internal workloads. Reuters reported samples hitting internal power and performance targets. | Independent benchmarks, production utilization, real-world reliability, and long-running fleet data. |
| Who is involved? | OpenAI, Broadcom, and Celestica are named partners. | Foundry, process node, packaging vendors, memory vendors, and total contracted capacity. |
| When will it deploy? | OpenAI says initial deployment is planned by the end of 2026. | Exact date, region, volume, and whether it will be used first for ChatGPT, API, enterprise, or internal workloads. |
| Will developers get it? | No direct developer product has been announced. | Whether OpenAI will expose Jalapeño-backed inference tiers, lower-cost endpoints, or performance guarantees in the API. |
Why OpenAI Built Its Own AI Chip
The strategic reason is control. OpenAI has become one of the world’s largest buyers and consumers of AI compute. Its products are not occasional demos; they are always-on services used by consumers, developers, enterprises, schools, media companies, software teams, and automated agents. That creates three hard problems: supply, cost, and latency.
Supply is the most obvious. Frontier AI companies have spent years competing for accelerator capacity from NVIDIA, cloud providers, and data-center partners. Even when chips are available, the total system requires networking, power, cooling, racks, operations, and financing. Kingy.ai covered this larger infrastructure pressure in our piece on the AI compute race moving inside data centers. Custom silicon does not solve every supply problem, but it can give OpenAI a more direct roadmap for the workloads it understands best.
Cost is the second reason. Inference is a recurring expense. A model that is used billions of times does not merely need to be smart; it has to be economically servable. If a custom ASIC can deliver more useful tokens per watt, better utilization, lower memory movement, or tighter batching for OpenAI’s actual traffic, the savings can be enormous. That does not mean OpenAI will immediately pass those savings through to users, but it changes the room in which pricing decisions are made.
Latency is the third. Modern AI products are moving from one-shot chat answers toward interactive voice, coding agents, research agents, real-time assistants, and tool-using workflows. Those workflows feel different when each model call is slightly faster, cheaper, and more predictable. A system that saves seconds across multi-step agent loops can make an entire product category feel more usable.
The deeper reason is hardware-software co-design. NVIDIA GPUs are powerful partly because they are flexible and have a mature software stack. A custom ASIC tries the opposite bargain: give up broad flexibility to gain efficiency on a known workload. OpenAI has unusually rich knowledge of its model architectures, serving patterns, token distributions, kernel bottlenecks, context-window behavior, and traffic spikes. That knowledge is the raw material for a custom inference chip.
Inference Vs Training
Training and inference are often collapsed into “AI compute,” but they are different engineering problems. Training is the process that produces a model. It is dominated by enormous parallel compute jobs, high-bandwidth networking between accelerators, massive datasets, checkpointing, failure recovery, and long-running experiments. Training chips need to move gradients, coordinate huge clusters, and sustain performance across complex schedules.
Inference starts after the model is trained. A user sends a prompt. The system loads or references model weights, processes the input, generates tokens, applies safety and routing layers, maybe calls tools, and returns an answer. At small scale this sounds simple. At OpenAI scale it becomes an industrial process: millions of requests, varied context lengths, different model sizes, different latency expectations, and a constant need to keep expensive hardware busy.
Inference accelerators care about arithmetic, but they also care about memory bandwidth, cache behavior, token generation, quantization, batching, scheduling, interconnects, and energy. A chip can be theoretically fast and still waste money if model weights have to move inefficiently or if real traffic cannot keep the hardware utilized. That is why the system around Jalapeño is just as important as the silicon itself.
Why Inference Chips Matter
Training gets more attention because it produces new model generations. Inference may matter more to the business. Once a model is trained, every user interaction becomes an operating-cost event. If usage grows faster than efficiency, AI companies either absorb margin pressure, raise prices, introduce tighter caps, or steer users toward smaller models. Better inference hardware changes those tradeoffs.
This is why the phrase “performance per watt” matters. Data centers are constrained not only by the number of chips they can buy, but by how much power they can secure and cool. A more efficient inference fleet can serve more requests inside the same power envelope. That is a major reason custom AI chips exist at Google, Amazon, Microsoft, Meta, Tesla, and now OpenAI. The question is not whether GPUs are good. They are. The question is whether a company running a very specific workload at huge scale can do better on that workload with custom silicon.
For users, the chip will probably be invisible. Nobody should expect a “Jalapeño mode” button in ChatGPT. The likely product effects are indirect: faster response times, more generous usage limits, lower-cost API tiers, higher availability during demand spikes, and more room for agentic workflows that call models many times in a row. For developers building on OpenAI, those small changes can matter a lot. Token budgeting, model selection, and multi-model stack decisions are already central to AI product design; see Kingy.ai’s token budgeting guide and open-source AI models guide for the software-side version of the same economic problem.
How Jalapeño Differs From NVIDIA GPUs
NVIDIA’s GPUs are general-purpose parallel accelerators with an enormous software ecosystem. They can train frontier models, run inference, accelerate scientific computing, support simulation, serve recommender systems, render graphics, and power a broad range of enterprise workloads. NVIDIA’s advantage is not only silicon. It is CUDA, libraries, networking, systems, developer mindshare, and availability through nearly every major cloud and server OEM.
Jalapeño is a different bet. It is an application-specific integrated circuit, or ASIC, designed around OpenAI’s serving needs. In theory, that lets OpenAI optimize hardware around its model formats, numerical choices, memory access patterns, kernel schedule, networking topology, and deployment software. In practice, it also creates risk: if the model architecture changes faster than the hardware roadmap, or if a new workload does not map well to the chip, the custom part may lose some of its advantage.
The right framing is not “Jalapeño versus NVIDIA.” It is workload segmentation. NVIDIA Blackwell and future GPU systems will remain central for training, research, model experimentation, and many inference workloads. Jalapeño could take over a growing slice of high-volume OpenAI-owned inference where flexibility is less important than efficiency. A mature OpenAI fleet may use custom ASICs, NVIDIA GPUs, AMD GPUs, cloud partner accelerators, and specialized networking together.

How It Compares With TPU, Trainium, Inferentia, Maia, MTIA, Dojo, Instinct, And Blackwell
Jalapeño belongs to a wider industry pattern: hyperscale AI companies are building or buying accelerators that match their internal economics. The closest conceptual comparison is Google’s TPU program, which has been optimized for Google’s machine-learning workloads across training and inference for years. Google’s newer TPU Ironwood generation is explicitly framed around inference and serving large models at scale.
Amazon has a two-track accelerator strategy with Trainium for training and Inferentia for inference. AWS pitches those chips as cost-performance options inside its cloud, especially for customers already building on AWS. Microsoft Maia is Azure’s custom AI accelerator effort, meant to support large AI workloads alongside NVIDIA and other infrastructure. Meta’s MTIA program is focused on Meta’s own ranking, recommendation, ads, and AI workloads, with the company emphasizing efficiency for internal services. Tesla’s Dojo is less directly comparable because it was designed around training for autonomous-driving workloads, not general LLM inference. AMD Instinct and NVIDIA Blackwell are more direct GPU competitors than ASIC analogues; they compete on broad accelerator performance, memory, networking, and software ecosystem.
| Platform | Owner | Main role | How to compare it with Jalapeño |
|---|---|---|---|
| Google TPU / Ironwood | Training and inference, with Ironwood framed for inference-scale workloads. | Most mature hyperscaler custom AI accelerator comparison. | |
| Amazon Trainium | AWS | Training accelerator for AWS customers. | Less direct because Jalapeño is inference-focused. |
| Amazon Inferentia | AWS | Inference accelerator for AWS workloads. | Conceptually close, though AWS exposes it as a cloud product. |
| Microsoft Maia | Microsoft | Custom Azure AI accelerator. | Similar strategic aim: reduce dependence and tune infrastructure to internal/cloud workloads. |
| Meta MTIA | Meta | Internal AI accelerator for Meta services. | Similar internal-efficiency logic, but Meta workloads include ranking and recommendation at enormous scale. |
| Tesla Dojo | Tesla | Training system for autonomy workloads. | Relevant as custom AI silicon, but not a clean LLM inference comparison. |
| AMD Instinct | AMD | General-purpose AI GPU accelerator. | A broad GPU alternative rather than a workload-specific OpenAI ASIC. |
| NVIDIA Blackwell | NVIDIA | High-end training and inference GPU platform. | The dominant general-purpose AI accelerator platform Jalapeño will coexist with, not simply replace. |
Architecture Overview
OpenAI has not published a full Jalapeño architecture paper, so any detailed block diagram would be speculation. What can be said safely is that a serious LLM inference ASIC has to solve several problems at once.
First, it needs enough compute for the operations used by modern transformer-like models and whatever architectural variants OpenAI is serving. Second, it needs to move model weights and activations efficiently. Memory movement is often the limiting factor in inference economics, especially during token generation. Third, it needs a networking story because large models and high-volume serving systems operate across multiple chips, boards, racks, and data centers. Fourth, it needs software co-design: kernels, compilers, quantization choices, routing, batching, monitoring, and fallback behavior.
Broadcom’s role is important here because the company has deep experience in custom silicon, networking, switch silicon, interconnects, and data-center systems. OpenAI brings the workload and model knowledge. Celestica brings manufacturing and systems integration experience for the board and rack layer. The combination suggests OpenAI is not treating Jalapeño as a lab chip. It is trying to build a deployable platform.
Performance, Power, Memory, Networking, And ASIC Design
The most tempting question is: how fast is Jalapeño? The responsible answer is: we do not know yet in a public, independently verifiable way. OpenAI says samples are running workloads. Reuters reported that internal targets were being met for power and performance. Broadcom emphasizes LLM optimization. None of that gives outsiders enough data to calculate tokens per second, tokens per watt, latency under real traffic, total cost of ownership, or performance versus Blackwell or Instinct in a production environment.
For inference, the headline benchmark may not even be the most important number. A chip can win a narrow throughput benchmark and still lose in production if it is hard to schedule, lacks memory headroom, wastes power at partial utilization, or creates operational friction. The numbers that matter include prefill throughput, decode throughput, batch efficiency, tail latency, cost per million tokens, power draw under realistic utilization, failure rates, rack-level density, and how quickly the software stack can support new model variants.
Memory is central. Large language models need fast access to parameters and context-related data. The longer the context window and the more concurrent users, the more the system has to manage memory pressure. Networking is central too. If OpenAI is serving very large models across many chips, the interconnect and rack fabric can determine whether compute units stay busy or wait on data. Broadcom’s networking background is therefore not a side detail. It may be one of the strongest reasons OpenAI chose the company.
The ASIC design tradeoff is durability. A GPU can adapt to many model architectures and software changes. An ASIC has to anticipate where the workload is going. OpenAI’s advantage is that it controls many of the models and serving systems it wants to accelerate. Its risk is that frontier AI is still changing quickly. Mixture-of-experts routing, multimodal models, tool-using agents, long-context workloads, real-time voice, code generation, and on-device/cloud hybrids can all stress inference hardware differently.
Why Broadcom Was Chosen, And The Role Of Celestica
Broadcom is one of the most important companies in custom data-center silicon. It is not just a chip supplier in the narrow sense. Broadcom has experience with application-specific integrated circuits, high-speed networking, switches, interconnects, and the kinds of infrastructure components that determine whether AI clusters work efficiently at scale. If OpenAI wanted a partner that could help turn a model-serving workload into a real hardware platform, Broadcom was a logical choice.
Celestica’s role points to another truth: deployment is the product. An inference chip has to live on boards, in servers, in racks, in data centers, inside power and cooling envelopes, with maintenance plans and supply chains. A chip that works in a lab but cannot be manufactured, serviced, or integrated at fleet scale does not solve OpenAI’s problem. Celestica’s involvement indicates that OpenAI and Broadcom are thinking beyond tape-out toward production systems.
The manufacturing process remains undisclosed. We do not yet know the foundry, node, packaging technology, memory configuration, yield expectations, or volume ramp. Those details will matter because custom silicon economics are unforgiving. A strong design still has to survive fabrication, packaging, validation, board production, software maturity, and data-center deployment.
Deployment Timeline And Supply Chain
The announced timeline is aggressive but not impossible. OpenAI and Broadcom announced the custom accelerator plan in 2025. The Jalapeño announcement says the chip moved from concept to tape-out in a compressed cycle, with OpenAI using its own models to help accelerate aspects of engineering work. As of June 24, 2026, samples are running internal workloads. The target is deployment by the end of 2026.
The end-of-2026 goal should be read as initial deployment, not instant global replacement. Even if everything works, a custom chip fleet takes time to ramp. Early deployments often focus on controlled workloads where the operator understands traffic patterns, software behavior, and failure modes. Over time, OpenAI can move more inference onto Jalapeño if the economics hold.
Supply chain is the hidden constraint. AI infrastructure depends on wafers, advanced packaging, high-bandwidth memory, networking gear, power equipment, cooling, skilled technicians, data-center space, and capital. Jalapeño gives OpenAI more control over one piece of the stack, but it does not make the rest of the stack disappear. The broader AI race is still constrained by electricity, deployment speed, and the ability to turn hardware plans into reliable services.
How OpenAI Plans To Use Jalapeño
OpenAI has framed Jalapeño as infrastructure for its own workloads. That likely means ChatGPT, API traffic, enterprise deployments, coding systems, research workloads, and future agent products could eventually run partly on Jalapeño-backed infrastructure. The company has not said whether developers will choose Jalapeño directly. The more likely path is that OpenAI exposes the benefit through model endpoints, latency improvements, pricing tiers, or capacity guarantees without asking developers to think about the hardware.
Could there eventually be a lower-cost inference tier powered by Jalapeño? Possibly. Could enterprise customers get dedicated capacity? Also possible. Could OpenAI offer a public “Jalapeño instance” the way AWS exposes Inferentia? There is no evidence for that yet. OpenAI’s business is selling models and AI products, not renting raw accelerators. Unless the strategy changes, the chip will probably remain an internal advantage rather than a product name in the API dashboard.
Does Jalapeño Replace NVIDIA?
No, not in any practical near-term sense. NVIDIA remains deeply embedded in AI training, research, inference, enterprise deployment, and cloud infrastructure. Its Blackwell platform is built for both training and inference, with a mature software ecosystem and a broad customer base. OpenAI will still need general-purpose accelerator capacity for many workloads, especially as models evolve.
What Jalapeño can do is reduce marginal dependence. If OpenAI can move a large share of stable, high-volume inference onto custom silicon, it gains bargaining power, capacity resilience, and internal efficiency. That matters even if NVIDIA remains a critical supplier. The right analogy is not replacing the highway. It is building a private lane for the route OpenAI drives most often.
What This Means For ChatGPT Users, Enterprises, Agents, Codex, And GPT Models
For ChatGPT users, the near-term change may be invisible. There is no reason to expect a consumer-facing Jalapeño setting. Over time, better inference economics could support faster responses, more generous usage limits, improved availability, and more capable default models. It could also help OpenAI offer richer multimodal and agentic experiences without every interaction becoming prohibitively expensive.
For enterprise AI buyers, Jalapeño matters because predictable inference economics are part of reliability. Enterprises care about latency, uptime, throughput, privacy controls, regional availability, and price stability. A custom inference platform could help OpenAI offer stronger service-level economics, though the company has not announced specific enterprise guarantees tied to Jalapeño.
For API developers, the key question is whether lower serving cost eventually becomes lower endpoint cost or higher model quality at the same price. Developers are increasingly designing products around cost per task rather than cost per token alone. Agents are the extreme case: one user request may trigger dozens of model calls, retrieval operations, tool calls, code edits, browser actions, and verification steps. If inference gets cheaper and faster, agent workflows become more practical.
For Codex-style coding agents, inference efficiency matters twice. First, coding models can be heavy users of long context, tool calls, file reads, and iterative reasoning. Second, coding agents often run in loops: inspect, patch, test, inspect again, fix, verify. A small latency or cost improvement per step can compound into a noticeably better developer experience. Kingy.ai has covered this shift in our Claude Code vs Codex comparison and Codex Record & Replay analysis.
For GPT models, custom inference hardware can influence model design. If OpenAI knows it has a particular serving platform, it can optimize future models around that platform’s strengths. That does not mean models will be designed only for Jalapeño; OpenAI still serves across heterogeneous infrastructure. But hardware-software co-design creates feedback loops. Model architecture, quantization, context handling, routing, and tool-use patterns can all evolve with the serving hardware.
Potential Impact On AI Pricing, Latency, And Agents
If Jalapeño succeeds, the biggest economic effect is likely cost per useful output. That is not exactly the same as raw cost per token. A model answer has value only if it arrives fast enough, passes safety and quality checks, and completes the user’s task. A cheaper chip that forces quality compromises would not help. A chip that lowers cost while preserving model quality would give OpenAI more options.
Potential outcomes include cheaper small-model tiers, more generous free or Plus limits, lower enterprise inference cost, faster high-demand models, or more aggressive agent products. But none of those outcomes is guaranteed. OpenAI may use efficiency gains to fund bigger models, absorb infrastructure costs, improve margins, or expand availability before cutting prices. The chip changes the possibility space; it does not dictate the business decision.
Latency may be the more noticeable effect. Voice assistants, coding agents, and workflow automations feel dramatically different when response times drop below user-frustration thresholds. If Jalapeño helps reduce tail latency under load, it could make AI feel less like waiting for a server and more like interacting with software. That is especially important for real-time agents and collaborative coding tools.
Industry Reaction, Market Implications, And Investment Implications
The industry implication is straightforward: AI infrastructure is becoming vertically integrated. Model companies are no longer satisfied with buying whatever accelerator capacity the market offers. They want hardware roadmaps that match their workloads. Cloud providers have known this for years. Google built TPUs. Amazon built Trainium and Inferentia. Microsoft built Maia. Meta built MTIA. OpenAI is now moving more visibly into the same pattern.
For Broadcom, Jalapeño reinforces the custom AI silicon opportunity. The company already benefits from networking and ASIC demand across the AI data-center boom. A high-profile OpenAI partnership strengthens its position as a custom silicon partner for companies that need more than off-the-shelf accelerators.
For NVIDIA, the story is more nuanced than “threat.” Custom inference chips can reduce some future demand for general-purpose GPUs, especially in mature workloads. But the total AI compute market is expanding, and GPUs remain essential for frontier training, experimentation, and many inference workloads. A growing AI market can support both custom ASICs and GPUs. The risk to NVIDIA is not immediate displacement; it is gradual segmentation of the highest-volume inference workloads by the largest AI customers.
For AMD, the custom ASIC trend is also a reminder that GPU competition is only one front. AMD Instinct can compete for general-purpose AI acceleration, but hyperscalers and AI labs are increasingly willing to build specialized hardware for their own economics. For investors, the key questions are volume, margin, power availability, software maturity, and whether custom silicon leads to durable cost advantages or simply another expensive infrastructure cycle.
Risks
The first risk is technical. Custom silicon can miss its target if model workloads change, software support lags, networking bottlenecks appear, yields disappoint, or production reliability falls short. Early lab success is necessary, but production fleets reveal problems that demos cannot.
The second risk is economic. ASIC development is expensive, and the benefit depends on deployment volume. If OpenAI cannot ramp enough chips, or if the cost of power, packaging, memory, and systems integration overwhelms the efficiency gain, the return may be slower than expected.
The third risk is strategic lock-in. Designing hardware around today’s workloads can constrain tomorrow’s models. OpenAI will need enough flexibility to support new architectures, modalities, context lengths, and agent behaviors. A chip optimized for one generation of LLM serving may be less ideal for the next.
The fourth risk is communication. Users and markets may overinterpret the announcement as a GPU replacement or a guaranteed price cut. It is neither. It is an infrastructure bet. The bet may be very important, but it still has to be proven in deployment.
FAQ
What is the OpenAI Jalapeño inference chip?
It is a custom AI accelerator designed by OpenAI with Broadcom for running OpenAI’s trained models more efficiently during inference.
Is Jalapeño a GPU?
No. It is an ASIC, a purpose-built chip for a narrower workload. GPUs are more flexible and remain important for training and many other AI workloads.
When will Jalapeño launch?
OpenAI says initial deployment is planned by the end of 2026. That should be read as an initial infrastructure rollout, not a consumer product launch.
Will developers be able to choose Jalapeño in the API?
OpenAI has not announced direct developer access. Developers may eventually feel the benefits through pricing, capacity, latency, or model availability rather than through a hardware selector.
Does Jalapeño replace NVIDIA Blackwell?
No. Jalapeño is best understood as a specialized internal inference lane. NVIDIA GPUs remain central to training, research, and broad AI acceleration.
Could Jalapeño make ChatGPT cheaper?
It could improve OpenAI’s cost structure if it performs well at scale. Whether that becomes lower prices, higher limits, faster models, or better margins is a business decision.
Sources And Further Reading
- OpenAI announcement: OpenAI and Broadcom Jalapeño inference chip
- Broadcom investor release on OpenAI and the LLM-optimized intelligence processor
- Reuters report, syndicated by WSAU, on OpenAI’s custom Broadcom chip
- The Verge coverage of OpenAI and Broadcom’s Jalapeño chip
- TechCrunch coverage of OpenAI’s first custom AI chip
- Wall Street Journal coverage of OpenAI’s custom AI chip plans
- NVIDIA Blackwell architecture overview
- Google Cloud on Ironwood TPU
- AWS Trainium and AWS Inferentia
- Microsoft Azure Maia announcement
- Meta on its next-generation MTIA accelerator
- AMD Instinct accelerators








