
The token hangover is here.
For a while, the default AI strategy was simple: put the smartest frontier model in every workflow and celebrate the usage chart. Strategy memo? Premium model. Code comment? Premium model. Lunch macros? Premium model. Five hundred thousand rows of low-stakes extraction? Premium model, because why not.
That made sense during the land-grab phase. Teams were proving that AI could work. They were training people to ask better questions. They were discovering use cases in the wild. But scale has a way of turning enthusiasm into invoices.
Gokul Rajaram recently framed the problem as “the token hangover” in his summary of Harry Stebbings’ 20VC interview with Factory CEO Matan Grinberg. The phrase works because it captures the awkward second morning of enterprise AI: usage went up, token bills went up, and business outcomes did not always rise in proportion.
The lesson is not “stop using frontier models.” That is the lazy backlash. Frontier models are extraordinary. The lesson is that frontier intelligence is too valuable to waste on work that a smaller, cheaper, open-weight, local, or task-specific model can do well enough.
The next serious question is not “Can we use AI?” It is: which model deserves this task?
That is the real AI stack problem. Not model worship. Model selection.
What Model Selection Actually Means
Before teams can route tasks intelligently, they need cleaner language. “Use an AI model” is too vague. Different model layers behave differently, cost differently, and create different operational risks.
Frontier models are the most capable general-purpose models from leading labs. They are the models you reach for when the job needs deep reasoning, complex planning, high-context synthesis, careful judgment, sophisticated coding, or agent orchestration.
Smaller proprietary models are hosted models from the same labs or platforms, optimized for speed, price, latency, and high-volume work. The official pricing pages make the spread obvious. OpenAI’s pricing, Anthropic’s pricing, and Google’s Gemini pricing all show materially different token rates across model tiers, service tiers, batch modes, and context options.
Open-weight models make model weights available under license, but that does not automatically make the model “open source.” Meta’s Llama family, for example, is distributed through official channels such as the verified Meta Llama organization on Hugging Face, with license terms users need to accept.
Open-source models should be treated more carefully. The Open Source Initiative’s Open Source AI Definition says an open-source AI system should provide freedoms to use, study, modify, and share, and the preferred form for modification includes data information, code, and parameters. In plain English: open weights are useful, but open weights alone are not always the same as open source.
Local models run on a laptop, workstation, private server, or dedicated cluster. They can be excellent for privacy-sensitive workflows, offline use, batch processing, internal document handling, and cost control, but they bring their own maintenance burden.
Hosted open models are open-weight or open models served through a cloud provider. They can reduce infrastructure pain while preserving some model flexibility, though the privacy and cost profile depends on the host.
Fine-tuned models are adapted to a narrow domain, brand voice, schema, tool use pattern, or support workflow. They can be powerful when the task is repetitive and measurable, but fine-tuning before the workflow is proven is usually theater with a training bill attached.
Embedding models do not write the final answer. They turn text, images, or other data into vectors for search, clustering, retrieval, deduplication, and recommendation. If your app has a knowledge base, product directory, or source-backed research layer, embeddings are part of the plumbing.
Multimodal models handle combinations of text, image, audio, video, documents, and sometimes screen or computer interaction. They matter when the input or output is not just text.
Agentic model stacks combine multiple models and tools. A frontier model might plan. A cheaper model might execute repetitive steps. An embedding model might retrieve context. A guardrail model might classify risk. The product is not one model. The product is the loop.
Frontier For Judgment, Smaller Models For Volume
The clean operating principle is this:
Use frontier models for judgment. Use open, local, smaller, and efficient hosted models for volume.
That does not mean every organization should mechanically force exactly 20% of usage through frontier models and 80% elsewhere. Treat the 10-20 / 80-90 split as a starting hypothesis, not a religion. Your real split depends on your work, risk tolerance, evaluation results, data sensitivity, latency needs, and willingness to operate infrastructure.
But as a default mental model, it is useful. Many organizations have a minority of work that truly requires frontier-level reasoning and a majority of work that is repetitive enough to route somewhere cheaper.

Use Frontier Models For
- Complex planning
- Multi-step reasoning
- Ambiguous strategic decisions
- Hard coding architecture
- Debugging unfamiliar failures
- Long-context synthesis
- Novel tasks where the workflow is not known yet
- High-value creative direction
- Agent orchestration
- Safety-sensitive review
- Important business decisions
- Any task where one bad answer is expensive
Use Smaller, Open, Local, Or Efficient Hosted Models For
- Summarization
- Classification
- Tagging
- Formatting
- Extraction
- Rewriting
- Simple customer support drafts
- Repetitive coding tasks
- Data cleanup
- Search query expansion
- Internal document chunking
- Batch processing
- Private local workflows
- Low-stakes automation
- Any task where volume matters more than brilliance
This is not anti-frontier. It is pro-discipline. A Ferrari is a wonderful machine. It is still a strange choice for delivering 40,000 identical envelopes across town.
A Practical Model-Routing Table
The table below is intentionally practical. It is not asking which model is “best.” It is asking which class of model is good enough for the job, what the risk is, and when to escalate.
| Job / task | Recommended model type | Why | Example workflow | Cost sensitivity | Risk level | When to escalate to frontier |
|---|---|---|---|---|---|---|
| Blog research | Small hosted plus frontier review | Source gathering is repetitive; synthesis needs judgment. | Cheap model summarizes sources, frontier model builds argument. | Medium | Medium | Conflicting sources, current events, or reputation-sensitive claims. |
| SEO content outline | Smaller hosted model | Structure and keyword mapping are patterned work. | Generate briefs from SERP notes, then editor reviews. | High | Low | High-stakes pillar page or complex positioning decision. |
| Final editorial polish | Frontier model | Taste, nuance, argument quality, and factual caution matter. | Run final draft through a frontier editor with source constraints. | Medium | Medium | Always for flagship content. |
| Code architecture | Frontier model | Architecture mistakes compound across the repo. | Use frontier model for design review before implementation. | Low | High | Always for unfamiliar systems or major changes. |
| Code refactoring | Smaller coding model plus tests | Many refactors are mechanical if tests exist. | Efficient model edits narrow functions; frontier reviews failures. | High | Medium | Cross-module behavior, security, data migration, or broken tests. |
| Test generation | Smaller coding model | Patterned, high-volume work with clear validation. | Generate unit tests, run suite, escalate failing logic. | High | Low to medium | When tests define critical business behavior. |
| Customer support | Smaller model with retrieval | Most drafts follow policy and knowledge-base context. | Retrieve account docs, draft reply, human approves edge cases. | High | Medium | Refund disputes, legal threats, safety, angry enterprise account. |
| Sales email personalization | Small hosted model | High-volume, low-stakes copy variation. | Personalize snippets from CRM fields and recent company notes. | High | Low | Strategic enterprise deal or sensitive relationship. |
| Contract summarization | Private/local extraction plus frontier review | Privacy and accuracy both matter. | Local model extracts clauses; lawyer and frontier model review. | Medium | High | Any interpretation, negotiation, or legal-risk call. |
| Legal review support | Frontier plus qualified human | Failure cost is high and regulated expertise matters. | AI flags issues; counsel makes the decision. | Low | High | Always. This is support, not legal advice. |
| Medical/health content support | Frontier plus expert review | High-stakes claims require careful sourcing. | AI drafts plain-English explanation; clinician reviews. | Low | High | Always for advice, diagnosis, treatment, or safety claims. |
| Data extraction | Small model or local model | Structured output is measurable and batchable. | Extract fields from invoices, resumes, PDFs, or product pages. | Very high | Low to medium | Ambiguous documents, low confidence, or compliance impact. |
| Image/video prompt generation | Smaller creative model | Variation matters more than deep reasoning. | Generate prompt variants, then use human taste for selection. | High | Low | Flagship campaign concept or strict brand/legal constraints. |
| Product strategy | Frontier model | The value is judgment, sequencing, tradeoffs, and synthesis. | Analyze users, market, constraints, and roadmap options. | Low | High | Always for strategic bets. |
| Financial analysis support | Frontier plus human review | Numerical and investment errors can be expensive. | Use AI for scenario summaries; finance owner validates. | Medium | High | Any forecast, investment, credit, or capital allocation decision. |
| Agent planning | Frontier planner | Bad plans waste every downstream tool call. | Frontier model decomposes goal, selects tools, sets checkpoints. | Medium | High | Always for long-horizon or external-action agents. |
| Agent execution | Cheaper executor model | Many steps are narrow once the plan is fixed. | Small model runs extraction, formatting, retries, and status updates. | High | Medium | Low confidence, tool error, permission change, or customer impact. |
| Embeddings / retrieval | Embedding model | Search needs representations, not essay writing. | Embed docs, retrieve passages, pass context to answer model. | High | Medium | When retrieval quality blocks the final answer. |
| Internal knowledge-base Q&A | Small model plus retrieval | Most answers should be grounded in company docs. | Retrieve source passages, answer with citations, escalate unknowns. | High | Medium | Policy, HR, legal, customer commitment, or no source found. |
| Social media repurposing | Smaller model | High-volume rewriting is not a frontier job. | Turn blog sections into posts, hooks, captions, and variants. | Very high | Low | Founder voice, crisis comms, or sensitive claims. |
| YouTube script writing | Frontier for outline, smaller for variants | Structure and originality matter; repurposing is routine. | Frontier builds arc; cheaper model creates intros, shorts, descriptions. | Medium | Medium | High-stakes sponsor, medical/finance topic, or public controversy. |
| AI product comparison pages | Small model for data, frontier for verdict | Extraction is volume; recommendation is judgment. | Collect pricing/features, then frontier model writes sourced analysis. | Medium | Medium | Ranking, “best” claims, pricing uncertainty, or affiliate risk. |
The Router Decides Better Than The Ego
Individual users often think their task deserves the best model. That is human. Everyone’s task feels special from inside the task.
At company scale, that impulse burns money. A healthy AI stack should classify the work before choosing the model. The router should ask boring questions before the employee can spend glorious tokens.
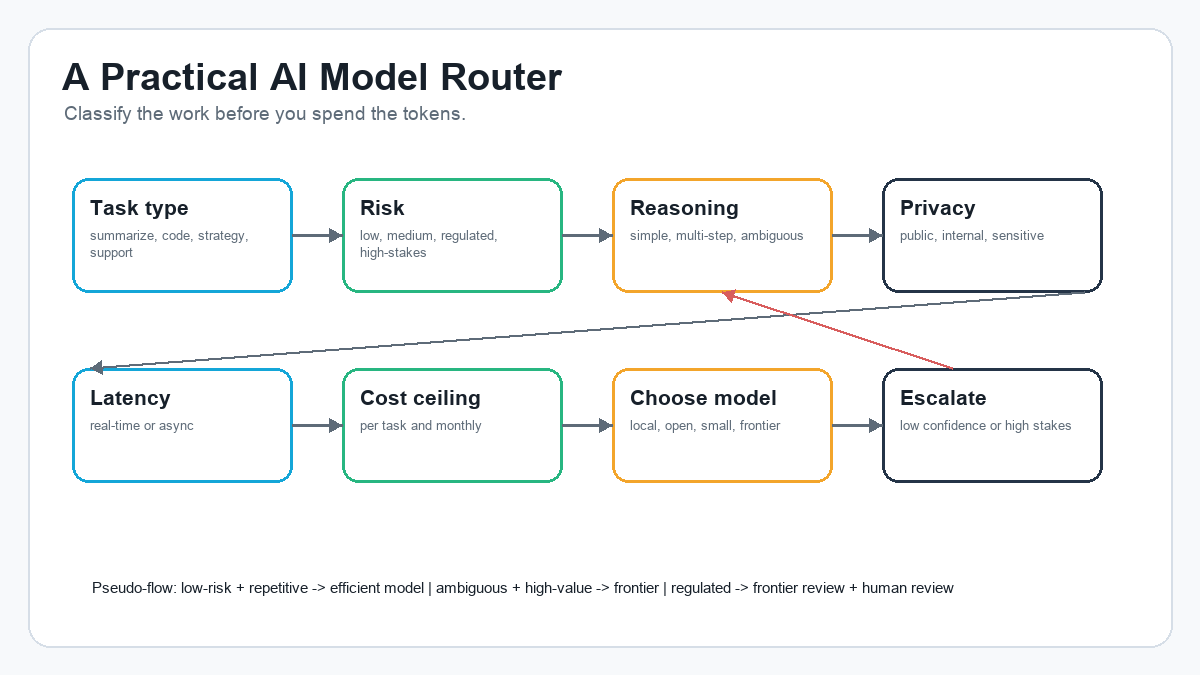
A simple router can work like this:
- Identify the task type.
- Estimate the risk level.
- Estimate the reasoning depth required.
- Check privacy and compliance needs.
- Check latency requirements.
- Check the cost ceiling.
- Choose the model class.
- Escalate only if confidence is low or stakes are high.
In pseudo-flow terms:
If task = low-risk + repetitive + structured -> use smaller/open/local model.
If task = ambiguous + high-value + requires planning -> use frontier model.
If task = private/sensitive + low reasoning -> use local/open/private model.
If task = high-stakes + regulated -> use frontier review plus human review.
If task = agent planning -> use frontier planner + cheaper executor model.This is where the application layer starts to matter. The user should not have to become a pricing analyst every time they ask for help. The app should know the workflow, the risk, the budget, the data context, and the escalation path.
The Frontier Model Layer Still Matters
The right reaction to token waste is not frontier nihilism. It is frontier respect.
Use the strongest models where intelligence changes the outcome. Anthropic’s own model-selection guidance frames model choice around capabilities, speed, and cost, with more capable models reserved for complex reasoning, scientific or mathematical work, nuanced understanding, accuracy-sensitive applications, advanced coding, and high-autonomy agentic work.
That is exactly the point. Frontier models are planners. They can decompose messy goals, identify hidden constraints, and decide which subtasks can be delegated.
Frontier models are reviewers. They can catch the subtle problem in a cheap model’s draft, the unstated assumption in an internal memo, or the risk hiding in a generated support policy.
Frontier models are architects. When a codebase is unfamiliar, the failure mode is not just a bad line of code. It is a bad mental model of the system. Spend the tokens there.
Frontier models are strategic copilots. They help founders, CIOs, marketers, and product teams reason through tradeoffs. For Kingy.ai readers building AI products, that is where the leverage lives: not in asking the most expensive model to add commas, but in using it to decide what deserves to exist.
Frontier models are escalation layers. When the cheap path is uncertain, route up. When the answer affects money, customers, safety, regulation, or reputation, route up. When one mistake costs more than the whole day’s token bill, route up.
The Open, Local, And Smaller Model Layer Is The Operating Layer
Open-weight, local, and smaller models matter because most production AI work is not glamorous. It is repetitive. It is bounded. It happens in volume. It has schemas. It has logs. It has pass/fail tests.
Mistral’s current model overview is a useful sign of where the market is going: a mix of frontier-class, open, efficient, coding, speech, OCR, moderation, and embedding-oriented models. The same pattern appears across the broader ecosystem. Teams do not need one hammer. They need a rack of tools.
Open and smaller models can help with cost control, privacy, customization, fine-tuning, local deployment, lower latency in some setups, batch processing, and vendor resilience. They also reduce the risk that one provider’s price change, model deprecation, policy change, rate limit, outage, or terms update becomes your product’s emergency.
But be balanced. Running local or open models is not free magic. Someone must handle infrastructure, hosting, security, monitoring, inference optimization, evaluation, data handling, patching, model updates, and incident response. A hosted frontier API has cost. A self-hosted open model has operational gravity.
The right question is not “open or closed?” It is “what is the total cost per successful workflow, with the risk level we can accept?”
The Application Layer Wins
If multiple frontier labs are roughly competitive, the application layer gains power. The model becomes a replaceable intelligence supplier. The durable moat shifts toward workflow, data, UX, routing, evaluation, trust, distribution, and business outcome.
That is why AI products should be model-flexible. A serious app should be able to swap models based on price, speed, quality, context length, coding ability, multimodal ability, tool-use reliability, data policy, and uptime.
This is already visible in infrastructure. Vercel’s AI Gateway, for example, presents the pattern of one application endpoint sitting over multiple models and providers, with docs for provider options, fallbacks, observability, usage, billing, and bring-your-own-key patterns. You do not need that exact product to understand the strategic direction: the app wants leverage over the model market.
For builders listed in the Kingy AI tools directory, this matters. If your app is welded to one model, your margins, latency, reliability, and roadmap are partially owned by that provider. If your app separates workflow from model, you can route intelligently and renegotiate every week.
This is also why AI Launch Intelligence tracks not just flashy model drops, but the tooling around launches: agents, evals, gateways, workflow infrastructure, and distribution. The real product is often the system that turns model capability into repeatable output.
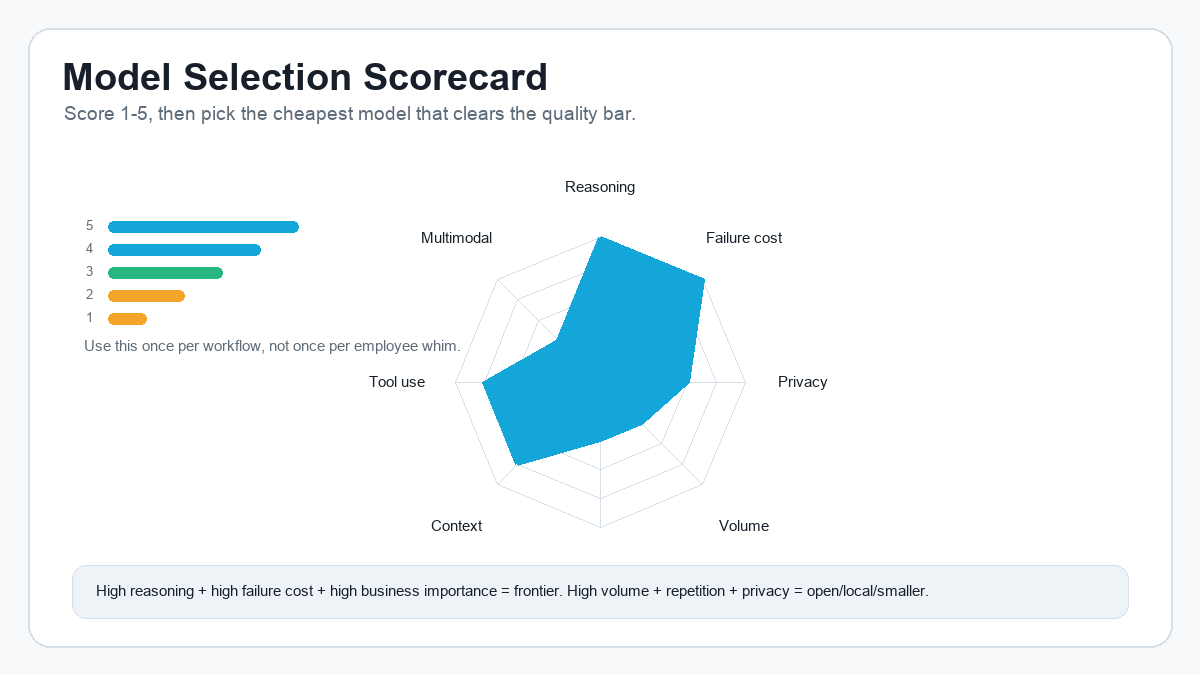
A Simple Model Selection Scorecard
Before choosing a model, score the workflow from 1 to 5 across these factors:
- Reasoning depth required
- Cost per task
- Volume
- Latency
- Privacy
- Context length
- Accuracy requirement
- Creativity requirement
- Tool-use requirement
- Multimodal requirement
- Fine-tuning requirement
- Failure cost
- Regulatory sensitivity
- Vendor lock-in risk
- Deployment complexity
Then apply the practical rule:
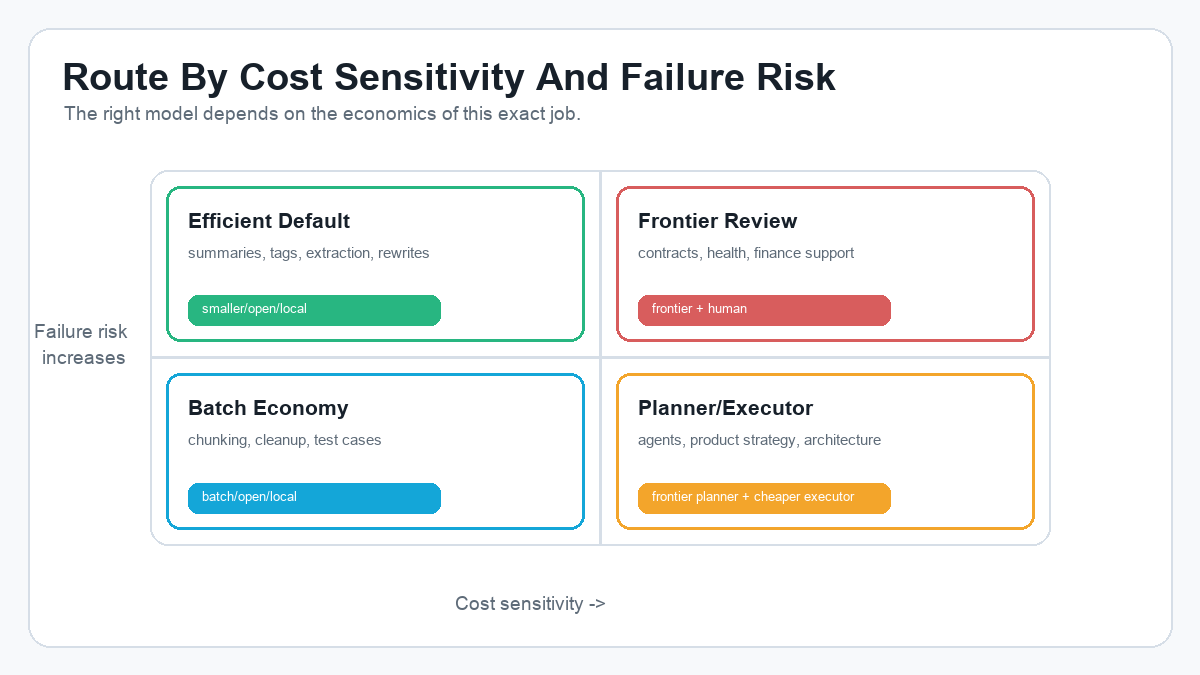
If reasoning depth, ambiguity, failure cost, and business importance are high, escalate to frontier. If volume, repetition, privacy, and cost sensitivity are high, consider open, local, or smaller models. If the task is regulated, treat AI as support and keep qualified humans in the accountability loop.
Example Stacks For Different Teams
Solo Creator Or Blogger
Use a frontier model for strategy, outline, angle selection, source skepticism, and final edit. Use smaller or open models for source summaries, title variants, formatting, metadata, social repurposing, and transcript cleanup. If you are building content workflows, pair this with a real publishing system rather than a folder of disconnected prompts. The goal is not more drafts. The goal is better finished work.
AI Startup
Use frontier models for product strategy, code architecture, agent planning, security review, and customer-facing high-stakes reasoning. Use open or smaller models for telemetry analysis, support drafts, internal tools, test generation, changelog drafts, PR summaries, and low-risk agent execution.
If you are in the “from code to customers” phase, the model is only part of the bottleneck. Kingy.ai has written about why distribution becomes the constraint for AI-built apps. Model routing helps margins, but positioning and adoption still decide whether the product matters.
Enterprise CIO
Use frontier models for high-stakes planning, cross-document synthesis, executive decision support, architecture review, and escalations. Use open, local, or smaller models for batch processing, internal Q&A, classification, compliance-controlled workflows, and repetitive document operations. The CIO version of AI maturity is not “everyone uses the biggest model.” It is observability, governance, routing, evaluation, and accountability.
Developer Team
Use frontier models for architecture, debugging unfamiliar failures, multi-repo planning, security review, and agent orchestration. Use smaller coding models for code completion, tests, documentation, PR summaries, refactors, type fixes, and routine migrations. For teams learning advanced AI workflows, the Kingy AI Codex course for beginners and the AI loops guide are useful companion reads.
Marketing Team
Use frontier models for campaign strategy, positioning, audience insight, offer design, and high-value creative direction. Use smaller models for repurposing, tagging, metadata, drafts, A/B variants, captions, and format conversions. A tool like the Kingy AI video prompt generator belongs in the volume layer; the strategy behind a campaign belongs closer to the frontier layer.
Legal Or Regulated Team
Use private or local models for first-pass extraction where appropriate. Use frontier models for issue spotting and structured review. Use qualified humans for interpretation, decisions, and accountability. This article is not legal, medical, or financial advice. In regulated domains, AI should support experts, not impersonate them.
Evaluation: The Router Needs Truth, Not Vibes
Model routing without evaluation is just vibes with a YAML file.
You need golden task sets: real examples of the work your organization does, with expected outputs, acceptance criteria, and edge cases. You need human review for ambiguous work. You need A/B tests between models. You need to measure cost per successful output, not just cost per token.
OpenAI’s evals documentation describes the basic pattern: compare model outputs against test inputs and ground truth labels. That idea is broader than any one provider. If your router sends tasks to cheaper models, you need to know whether quality held. If a provider updates a model, you need regression tests. If a workflow touches customers, you need escalation-rate tracking.
Track at least these:
- Task success rate
- Cost per successful output
- Latency
- Hallucination or unsupported-claim rate
- Escalation rate
- Human correction rate
- User satisfaction
- Business outcome metrics
- Regression failures after model changes
Do not over-optimize cost before the workflow works. First prove the model can create value. Then route, compress, batch, cache, downgrade, localize, and fine-tune. OpenAI’s cost optimization guidance points to simple levers such as reducing requests, minimizing tokens, selecting smaller models, batch processing, and flex processing. Those levers are useful after you know what quality means.
Common Mistakes
The first mistake is using the most expensive model for every task. It feels safe. It is often just lazy.
The second mistake is choosing models from leaderboard screenshots. Benchmarks are useful, but your workflow is the benchmark that pays the bill.
The third mistake is ignoring privacy and data retention. A cheap hosted model is not cheap if it sends sensitive data somewhere your policy does not allow.
The fourth mistake is ignoring latency. The best model on a benchmark may be the wrong model inside a real-time customer workflow.
The fifth mistake is ignoring output consistency. A model that is brilliant but unpredictable can be worse than a smaller model that reliably returns the right schema.
The sixth mistake is confusing open-weight with fully open-source. Use the OSI definition as a sanity check and read the license.
The seventh mistake is forgetting human review for regulated or high-stakes work. If the output affects health, law, finance, employment, safety, or material customer commitments, the accountability layer is human.
The eighth mistake is building custom infrastructure too early. You do not need a grand internal model platform for a workflow nobody uses.
The ninth mistake is over-optimizing cost before proving the workflow creates value. A cheap useless workflow is still useless.
The tenth mistake is vendor-locking the entire app to one provider. Build for optionality where it matters.
The eleventh mistake is letting engineers choose models manually forever. Manual choice is fine during discovery. Production wants routing logic.
What This Means For Kingy AI Readers
For AI founders: build model-flexible products. The model market will keep moving. Your durable value is the workflow, dataset, UX, trust layer, distribution channel, and evaluation harness.
For marketers: stop spending frontier tokens on bulk rewrites. Use frontier models for taste, positioning, campaign strategy, and narrative. Use cheaper models for volume.
For developers: use frontier models for architecture, unfamiliar debugging, agent planning, and review. Do not burn premium reasoning on every trivial code question.
For enterprises: build routing and evaluation into the AI stack early. If you do not classify tasks, the invoice will classify them for you later.
For creators: use frontier models for originality, structure, voice, and final judgment. Then let cheaper models help with formatting, variants, clips, descriptions, and metadata. If you are modeling sponsored content economics, the AI sponsored video ROI calculator is another place where structured workflow beats model worship.
For AI buyers: use the Kingy AI model intelligence hub and the open-source AI and local LLM guide as starting points, but make the final decision against your own tasks.
The Bottom Line
The best AI stack is not one model. It is a routing system.
Frontier models are the executive layer. Open, local, smaller, and efficient hosted models are the operating layer. Evaluation is the truth layer. Human experts are the accountability layer.
The winners will not be the companies that spend the most tokens. They will be the companies that know which tokens are worth spending.
Sources And Further Reading
- Gokul Rajaram’s “Token Hangover” summary
- 20VC episode with Matan Grinberg, Factory
- OpenAI API pricing and cost optimization guidance
- Anthropic guidance on choosing a model and Claude API pricing
- Google Gemini API pricing
- Open Source Initiative: Open Source AI Definition 1.0
- Meta Llama on Hugging Face
- Mistral model overview
- Vercel AI Gateway documentation
- OpenAI evals documentation
Kingy Launch Brief
Put the week’s verified AI launches in your inbox.
The public Friday pilot has not sent its first issue yet. Join for a source-checked launch briefing with a clear try, watch or skip verdict, then check your inbox and confirm your address.
Free · Friday pilot · Double opt-in · Unsubscribe anytime