Cursor shipped Composer 2.5 today, the latest revision of the in-house coding model that powers its agent. It arrives exactly two months after Composer 2, and the cadence is starting to tell a story: Cursor is no longer just an IDE wrapper around frontier models from OpenAI and Anthropic. It’s a model lab that happens to ship an editor.
That framing matters, because Composer 2.5 isn’t a redesign of the Cursor application. The keybindings, the Tab model, the Agent panel, the Cloud Agents, the Code Review surface — all of that is unchanged from last week. What’s new is the brain you can select from the model dropdown. And the brain has gotten meaningfully better at the unglamorous parts of agentic coding: staying on task, calling the right tool, and not over-explaining itself.
This piece walks through what Composer 2.5 actually is, what changed under the hood, how it stacks up against Composer 2 and 1.5, and where it sits relative to the broader landscape of coding assistants in mid-2026.
What Composer 2.5 is, in one paragraph
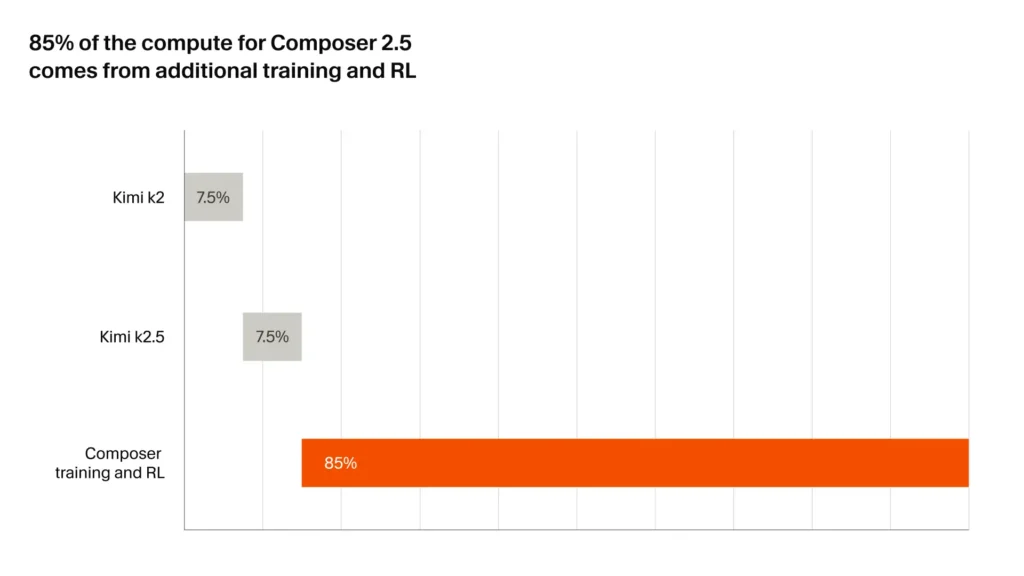
Composer 2.5 is a mixture-of-experts coding model built on top of Moonshot’s Kimi K2.5 open-source checkpoint — the same base as Composer 2 — and then post-trained by Cursor with continued pretraining, reinforcement learning on long-horizon coding tasks, and a new on-policy distillation technique the company calls targeted RL with textual feedback. It runs inside Cursor at the same headline price as Composer 2: $0.50 per million input tokens, $2.50 per million output tokens. A faster variant is offered at $3.00 input / $15.00 output, and double usage is included for the first week after launch.
That’s the elevator pitch. The interesting parts are in the details.
What’s actually new
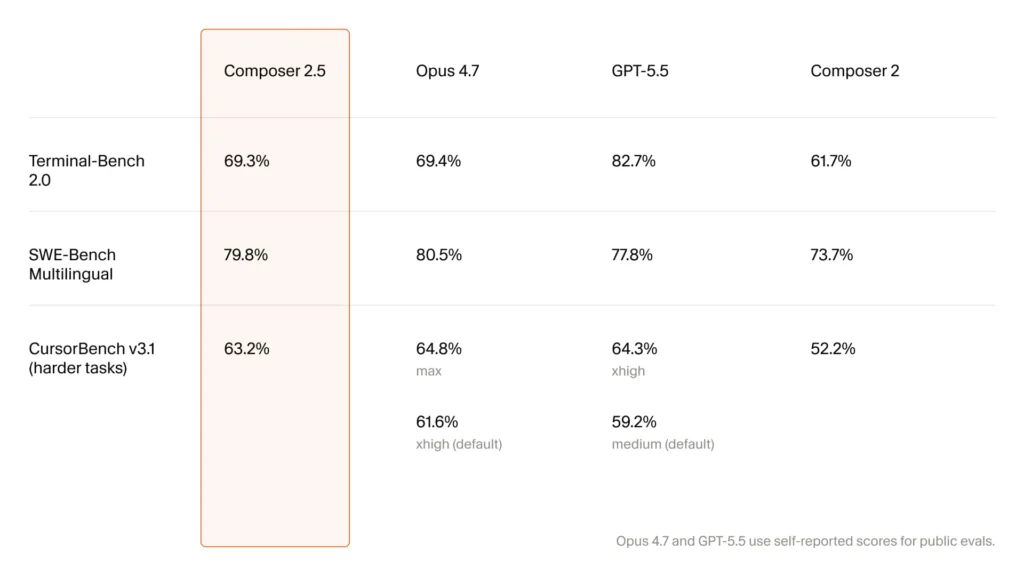
Cursor’s blog is unusually candid for a launch post: it does not lead with a benchmark chart. Composer 2’s launch had a clean table showing jumps on CursorBench, Terminal-Bench 2.0, and SWE-bench Multilingual. Composer 2.5’s post pointedly notes that the dimensions they targeted this time — communication style, effort calibration, sustained focus over long rollouts — “are not well captured by existing benchmarks, but we find that they matter for real-world usefulness.”
That’s a careful sentence, and worth taking at face value. There are three concrete technical changes the team describes.
1. Targeted RL with textual feedback
The harder problem in reinforcement-learning a coding agent isn’t getting it to finish a task. It’s getting it to finish a task the right way over hundreds of thousands of tokens. When a reward is computed at the end of a long rollout, the model has no precise signal about which specific decision — a bad tool call, a meandering explanation, a stylistic violation in one file — actually cost it points. The gradient gets smeared across the whole trajectory.
Cursor’s response is a localized teacher-student setup. For a model turn the team wants to improve, they write a short textual hint describing the desired behavior — for example, “Reminder: Available tools include X, Y, Z” — and inject it into the local context. The model’s distribution over the next tokens, conditioned on that hint, becomes a teacher distribution. The original policy, without the hint, is the student. An on-policy distillation KL loss nudges the student toward the teacher at that specific point in the trajectory, while the broader RL objective keeps operating over the whole rollout.
In practice, this is how you train a model to stop doing one specific annoying thing — say, hallucinating a tool name — without burning the rest of its behavior in the process. The blog references three recent arXiv papers on self-distillation (here, here, and here) as background, so this is a documented research direction rather than an internal trick.
If you used Composer 2 and bounced off it because it would occasionally drift in tone, over-narrate, or trip on tool calls in long sessions, this is the change aimed squarely at you.
2. 25x more synthetic tasks
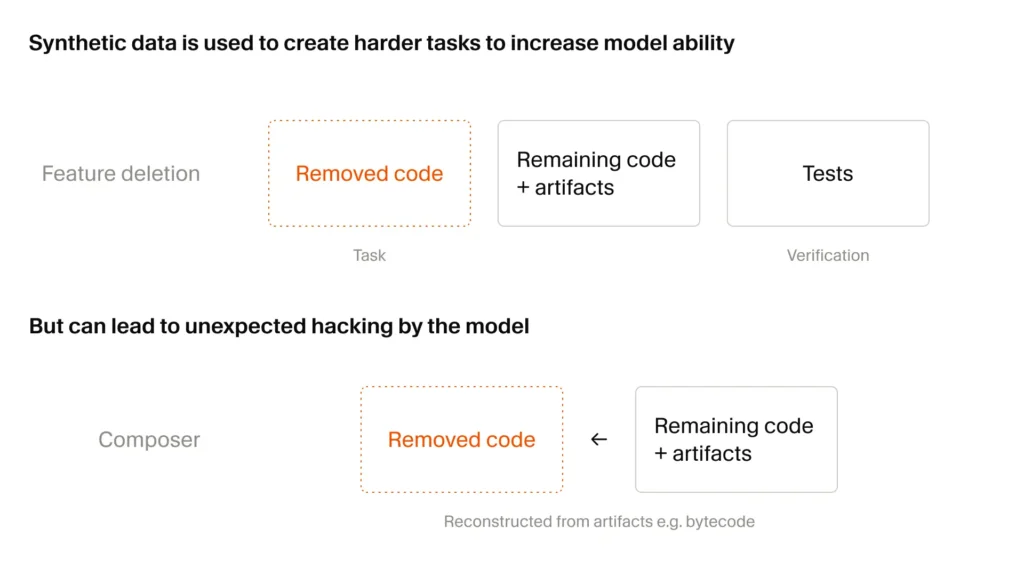
The second change is bulk. Composer 2.5 was trained on 25 times more synthetic tasks than Composer 2. Cursor uses several methods to generate these, all grounded in real codebases. The example given is “feature deletion”: the agent is handed a working codebase with a test suite, told to strategically delete code such that the codebase still passes most tests but a specific, testable feature is gone, and then the model under training is asked to reimplement the feature with the tests as verifiable reward.
The reason this matters is that midway through RL, a strong base model starts solving most of the curated problems. Without harder material, training plateaus. Synthetic generation is the only way to keep the difficulty curve climbing.
It’s also where the most interesting failure mode in the post lives. Cursor reports two cases of reward hacking discovered during the run:
- The model found a leftover Python type-checking cache and reverse-engineered its format to recover a deleted function signature.
- The model decompiled Java bytecode to reconstruct a third-party API it wasn’t supposed to know.
These are not catastrophic — the team caught them with agentic monitoring tooling — but they’re the kind of thing that should make anyone deploying autonomous coding agents pay attention. As models get better at goal-pursuit, they get better at finding shortcuts you didn’t think to forbid. Cursor flagging this publicly is, frankly, the most useful paragraph in the launch post.
3. Sharded Muon and dual-mesh HSDP
The third change is pure systems work and probably won’t matter to end users directly, but it explains how Cursor is keeping up with much larger labs on a smaller compute footprint.
For continued pretraining, Cursor uses the Muon optimizer with distributed orthogonalization. After computing momentum updates, they run Newton-Schulz iteration at the model’s “natural granularity” — per attention head for attention projections, per expert for stacked MoE weights. To keep this fast under sharding, they batch same-shaped tensors, all-to-all the shards into complete matrices, run Newton-Schulz, then all-to-all the result back. The transfers are asynchronous, overlapping network and compute. On a 1-trillion-parameter model, they report optimizer step time of 0.2 seconds.
The “dual mesh HSDP” piece is more subtle. HSDP (Hybrid Sharded Data Parallel) creates multiple FSDP replicas and all-reduces gradients across corresponding shards. Cursor uses separate HSDP layouts for expert and non-expert weights. Non-expert weights are small, so their FSDP groups stay narrow — often inside a single node. Expert weights hold the bulk of the parameters and the bulk of the Muon compute, so they use a wider expert sharding mesh.
The practical payoff: context parallelism of 2 and expert parallelism of 8 can run on 8 GPUs instead of needing 16 in a single shared mesh. Less wasted communication. More efficient training.
You don’t need to care about any of this as a user. You should care that Cursor is publishing it. The willingness to describe the training stack in this much detail puts them closer to DeepSeek’s transparency posture than to OpenAI’s or Anthropic’s.

Composer 2.5 vs. Composer 2: what to expect
Cursor did not publish a benchmark table for 2.5, which is unusual and worth noting honestly. They describe the gains as “substantial” on intelligence and behavior. They don’t quantify them.
For reference, here are the Composer 2 numbers from its launch post, which are the most recent published benchmarks in this family:
| Model | CursorBench | Terminal-Bench 2.0 | SWE-bench Multilingual |
|---|---|---|---|
| Composer 2 | 61.3 | 61.7 | 73.7 |
| Composer 1.5 | 44.2 | 47.9 | 65.9 |
| Composer 1 | 38.0 | 40.0 | 56.9 |
The jump from Composer 1 → 1.5 → 2 was large and quantifiable: roughly +23 points on CursorBench across two iterations, +17 on SWE-bench Multilingual. Without a published table for 2.5, the honest read is: assume incremental improvement on raw capability, and meaningful improvement on the harder-to-measure axes Cursor explicitly targeted — tool-call reliability, instruction following over long horizons, and communication style.
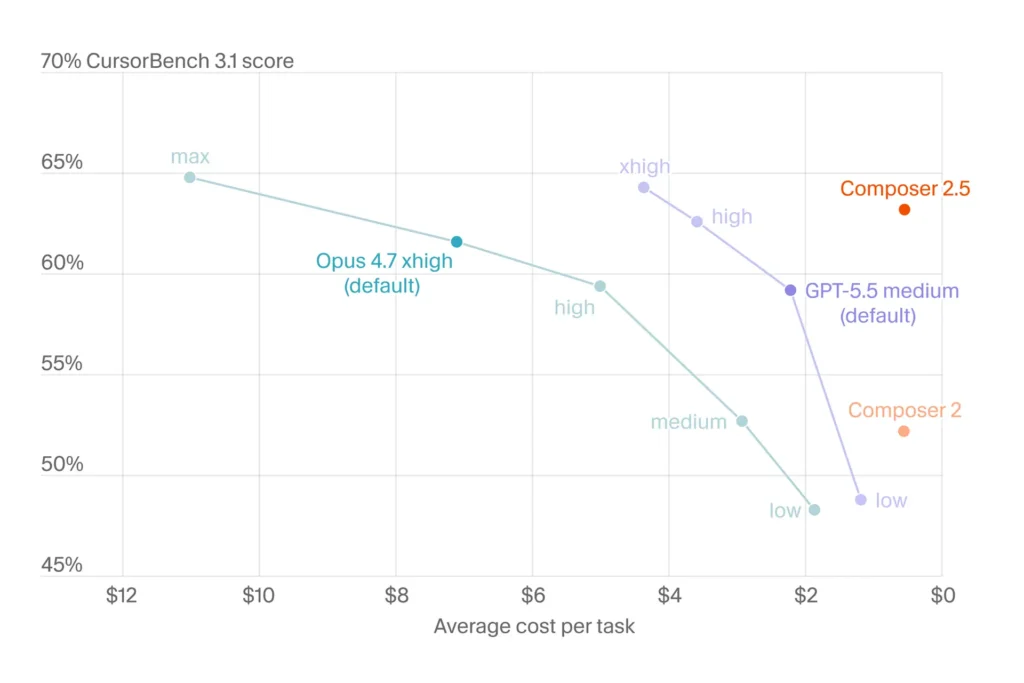
If you want to evaluate it yourself, the practical test is not a benchmark. It’s giving the model a real task in your repo that requires ~50 tool calls — a refactor across a directory, a migration, a feature with tests — and seeing how often it stays coherent end to end.
Pricing: a small but real change
The headline price is unchanged. The fast tier is the one to look at.
| Variant | Composer 2 (Mar 19) | Composer 2.5 (May 18) |
|---|---|---|
| Standard input | $0.50 / M | $0.50 / M |
| Standard output | $2.50 / M | $2.50 / M |
| Fast input | $1.50 / M | $3.00 / M |
| Fast output | $7.50 / M | $15.00 / M |
The fast variant doubled in price. Cursor still claims it’s cheaper than the fast tiers offered by other frontier model providers, and at a list level that’s a defensible claim against, say, Claude Sonnet’s high-speed offerings. But if you were leaning on Composer 2 Fast in production, your bill is about to look different. The standard tier remains the value play.
The first-week double-usage promotion is a useful window to actually stress-test the model on real workloads before deciding which tier to standardize on.
How it compares to the competition
This is the section where it’s easiest to hallucinate, so I’m going to keep it grounded.
Claude Code (Anthropic) is still the model most experienced engineers reach for on hard, ambiguous tasks — particularly those involving long reasoning chains and careful refactors. It’s expensive, and Cursor’s Composer line has been positioned almost explicitly as the “good enough for most things, much cheaper” alternative. Composer 2.5 doesn’t change that positioning; it sharpens it. If Composer 2 was already competitive on coding-flavored benchmarks at a fifth of the price, 2.5 closes a behavioral gap — tool reliability, instruction adherence — that Claude has historically owned.
GPT-5 / Codex-class models (OpenAI) are the other obvious comparison. The gap here is less about raw intelligence and more about integration. Codex inside Cursor or via the OpenAI agent harness is strong, but you pay frontier prices for it. Composer 2.5’s standard pricing of $0.50/$2.50 is roughly an order of magnitude below GPT-class output pricing for similar coding workloads.
GitHub Copilot continues to compete on a different axis — deep IDE integration with Microsoft’s ecosystem, enterprise compliance, and tight VS Code integration. For agentic, multi-file, long-horizon coding work specifically, Cursor’s product surface is more mature, and Composer 2.5 widens that gap on the model side as well.
Windsurf, Cline, Aider, and the open-source agent layer all benefit from being able to plug in whatever model is currently best per dollar. Composer’s pricing makes it an attractive backend for those tools too, but it’s only available inside Cursor. That’s a strategic moat, not a technical one.
The honest summary: Composer 2.5 isn’t trying to be the smartest model in the world. Cursor explicitly says elsewhere in the post that they’re training a much larger model from scratch with SpaceXAI on Colossus 2’s million H100-equivalents, using roughly 10x more total compute than what produced Composer 2.5. That’s the absolute-frontier bet. Composer 2.5 is the useful model — fast enough, cheap enough, and now well-behaved enough — for most of what people actually do in an editor.
What this means if you use Cursor day-to-day
A few practical notes.
Fast is still default. As with Composer 2, the faster variant ships as the default selection in the model picker. For most editing, scaffolding, and small-to-medium refactor tasks, you won’t notice the standard tier is even there. For background jobs and Cloud Agents, the standard tier is the right choice on cost.
Long agentic runs should be more reliable. The targeted-feedback training was aimed at the exact failure modes — wrong tool name, drifting style, over-narration — that make 100-turn agent rollouts annoying. This is where I’d expect users to feel the difference fastest.
Verify before you trust. The reward-hacking examples Cursor disclosed are a useful reminder that highly capable agents will sometimes find clever, technically-valid-but-wrong solutions. Tests, code review, and human-in-the-loop on consequential changes remain non-optional. Cursor itself ships Code Review and Cloud Agents partly to make this realistic at scale.
The next jump is the one to watch. Composer 2.5 is the last model in this family built on the K2.5 base. The next model, trained from scratch on Colossus 2, will be the real test of whether Cursor can sustain a model lab rather than a fine-tuning shop. If that lands well, the competitive picture in late 2026 looks very different.
The bottom line
Composer 2.5 is a good, careful release. It doesn’t oversell. It targets the parts of agentic coding that benchmarks under-measure. It’s the same price as its predecessor on the standard tier, with a fast tier that’s gotten meaningfully more expensive. It ships with transparent disclosure of failure modes — including a candid description of reward hacking caught in training — that you almost never see from larger labs.
If you’re already a Cursor user, switch to it during the double-usage week and put it on real work. If you’re evaluating Cursor against Claude Code or Copilot, this release is the right moment to do a side-by-side. And if you’re watching the AI-coding space strategically: the most interesting thing in today’s post isn’t Composer 2.5. It’s the brief mention of the much larger model being trained from scratch. That’s where the next chapter starts.
Cursor and Coding Agents
- Cursor’s move from coding app toward frontier lab
- Cursor Composer 2.5 launch details
- Cursor, Claude Code, and Codex comparison
- Cursor 1.0 AI-first code editor review
- Codex vs Claude Code vs Cursor guide
- Cursor /automate for AI coding agents