
For the better part of 2025 and into 2026, the narrative in frontier AI has been shaped by a rhythm: OpenAI ships, Anthropic counters, Google answers, and everyone else reads the footnotes. Moonshot AI has spent the last nine months quietly rewriting that script. With the official release of Kimi K2.6 on April 20, 2026, the Beijing-based lab is no longer just “the open-source option” — it is, on several benchmarks that matter most to working developers, the state of the art, full stop.
Announced via the @Kimi_Moonshot account on X and accompanied by a full technical blog at kimi.com/blog/kimi-k2-6, K2.6 isn’t a simple point release. It’s the first model in the K2 lineage that was built from the ground up around one conviction: that the bottleneck in real-world AI usage isn’t raw reasoning horsepower — it’s stamina. The ability of an agent to keep calling tools, correcting mistakes, and staying coherent for hours at a time without falling apart.
In this piece, I’ll walk through what K2.6 actually is — specifications, architecture, pricing — and then compare it head-to-head against the closed-source frontier (GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro) and its open-weight peers. I’ll also dig into the two features that everyone is going to be talking about: the scaled-up Agent Swarm architecture and the new Claw Groups preview.

The Specifications: A Trillion-Parameter MoE, Tuned for Endurance
Kimi K2.6 continues the architectural lineage that Moonshot established with the original Kimi K2 in July 2025 and refined across K2-Instruct-0905, K2-Thinking, and K2.5. It’s a Mixture-of-Experts (MoE) model with 1 trillion total parameters and 32 billion active parameters per token, a configuration that keeps per-token inference cost comparable to a dense 32B model while giving the system the knowledge capacity of something ten times larger.
The expert routing is fine-grained: 384 experts, with 8 activated per token, across 61 layers (one of them dense). The attention mechanism is Multi-head Latent Attention (MLA), the activation is SwiGLU, and the model uses a 160K-token vocabulary. The context window remains at 256K tokens, inherited from K2.5 — a size that sounds almost modest next to GPT-5.4’s rumored million-token window, but that in practice is sufficient for the long coding sessions K2.6 is optimized for.
Training was done on 15.5 trillion tokens, with a knowledge cutoff around April 2025. The model is shipped under a modified MIT license, which is notable: it allows largely free commercial use, with a single carve-out. According to The Decoder’s coverage, any company deploying K2.6 inside a commercial product with more than 100 million monthly active users or $20 million in monthly revenue must visibly credit “Kimi K2.6” in the user interface. For the 99.9% of teams below that threshold — which is to say, almost everyone — it’s effectively unencumbered.
One of the quieter but more important technical ingredients is the MuonClip optimizer, originally developed for K2 to stabilize training of trillion-parameter MoE models. MoE architectures are notoriously prone to attention explosions and loss spikes, and as the Kimi K2 technical writeups document, MuonClip was designed specifically to tame those failure modes. It’s part of why Moonshot can ship a 1T-parameter open-weight model without obvious training collapse artifacts — something that has tripped up several other labs attempting similar scales.
Pricing That Changes Behavior
Before diving into benchmarks, it’s worth pausing on the commercial surface area. The Moonshot API platform lists K2.6 at $0.95 per million input tokens, $4.00 per million output tokens, and $0.16 per million cache-hit tokens. That sits well below Claude Opus 4.6 and comfortably below GPT-5.4 on both input and output.
As the team at Novaknown argued in a skeptical preview piece earlier this month, one of the most consequential facts about Moonshot isn’t any single benchmark — it’s that Kimi API prices have dropped up to 75% across the K2 family. Cheap inference doesn’t just save money. It unlocks different product designs. You can afford retries. You can afford multi-step agent loops that burn thousands of tool calls. You can run background jobs that would be financially suicidal on Claude.
That’s the context for K2.6. Moonshot didn’t build a model that beats GPT-5.4 on one-shot reasoning. They built a model that makes long-running agent work economically viable, and then they made sure it’s also genuinely competitive on the benchmarks developers actually care about.
The Benchmark Picture: Where K2.6 Leads, and Where It Doesn’t
The headline numbers, as published by Moonshot and verified against third-party coverage from OfficeChai and The Decoder:
- Humanity’s Last Exam (with tools): 54.0 — ahead of Claude Opus 4.6 (53.0) and GPT-5.4 xhigh (52.1)
- SWE-Bench Pro: 58.6 — ahead of GPT-5.4 (57.7) and Claude Opus 4.6 (53.4)
- SWE-Bench Multilingual: 76.7 — essentially tied with Gemini 3.1 Pro (76.9)
- BrowseComp: 83.2
- Toolathlon: 50.0 — ahead of Claude Opus 4.6 (47.2) and Gemini 3.1 Pro (48.8)
- DeepSearchQA: 92.5 — ahead of Claude Opus 4.6 (91.3)
- Charxiv (with Python): 86.7
- Math Vision (with Python): 93.2
- SWE-Bench Verified: 80.2%
- Terminal-Bench 2.0: 66.7%
- V*: 96.9 — tied with Gemini 3.1 Pro
These are not cherry-picked from a single report; the Kilo Blog writeup from Ari cross-confirms the 80.2% on SWE-Bench Verified, 58.6% on SWE-Bench Pro, 92.5% on DeepSearchQA, and 66.7% on Terminal-Bench 2.0 from their own early-preview testing inside the Kilo Gateway.
The pattern that emerges is specific and important. K2.6 leads the frontier on the benchmarks that measure agentic, tool-augmented work — the ones where the model has to plan, call tools, read results, and correct course. It’s competitive on multilingual code editing and vision-with-tools workflows. And it’s roughly at parity on everything that looks like “long-context coding with tests.”
Where does it not lead? OfficeChai is direct about this: GPT-5.4 and Gemini 3.1 Pro still hold the lead on pure reasoning benchmarks — AIME 2026, GPQA Diamond, and raw BrowseComp without tool augmentation. K2.6 also does not top Gemini 3.1 Pro on raw vision tasks. If your use case is “ask the model a hard, self-contained graduate-level physics problem and expect a flawless answer in one shot,” Gemini and GPT-5.4 are still the safer bet.
But if your use case is “have the model work autonomously for twelve hours on a real codebase and produce a working improvement,” the data increasingly points in one direction — and it isn’t closed-source.
Long-Horizon Coding: The Real Differentiator
The reason Moonshot is pushing “long-horizon coding” as the central capability of K2.6, rather than any single benchmark, becomes obvious when you look at the two showcase runs the company published alongside the release.
In the first, documented by both OfficeChai and the Moonshot technical blog, K2.6 was pointed at the task of optimizing local inference of the Qwen3.5-0.8B model on a Mac using Zig — a deliberately low-level, relatively niche systems language. Over the course of 4,000+ tool calls and more than 12 hours of continuous execution, the model iterated on its approach, profiled hotspots, rewrote inner loops, and eventually delivered a result that outperformed LM Studio’s local inference throughput by roughly 20%.
That’s not a benchmark-gaming run. It’s the kind of work a competent systems engineer would spend a long weekend on — and K2.6 did it autonomously, in one shot, in a language the broader AI community has paid relatively little attention to.
The second run is, if anything, more impressive. K2.6 was given exchange-core, an eight-year-old open-source financial matching engine with a complex real-world codebase. Over 13 hours of autonomous work and 12 distinct optimization passes, the model made over 1,000 tool calls, modified more than 4,000 lines of code, and delivered a 185% improvement in median throughput (from 0.43 to 1.24 MT/s) along with a 133% gain in peak throughput. Kilo Code’s CEO Scott Breitenother reported that his team verified these improvements during their preview integration period.

These numbers are the product-market-fit of the year, if they hold up. As Kilo Code’s Ari put it in her launch post, K2.6 is “tremendously capable at handling the rigorous, day-to-day processing required to support an always-on agent.”
Partner validations reinforce the picture. Vercel reported more than 50% improvement on its Next.js benchmark when switching from K2.5 to K2.6. Ollama co-founder Michael Chiang said the model “raises the bar for open-source models” and “sustains long multi-step sessions with impressive stability.” Baseten and Factory.ai have similarly confirmed step-change improvements over K2.5 in their internal testing.
The engineering question that all of this implicitly answers is one that Novaknown highlighted in their pre-release skepticism piece: agents don’t fail because they’re too dumb to solve a problem. They fail because they mangle tool state on call #400, or the streaming format breaks on a partial JSON parse, or the planner gets distracted and wanders off-task. K2.6 is — at least on the evidence available in its first 48 hours — the first open-weight model where those failure modes appear to have been genuinely reduced, not just papered over with marketing.
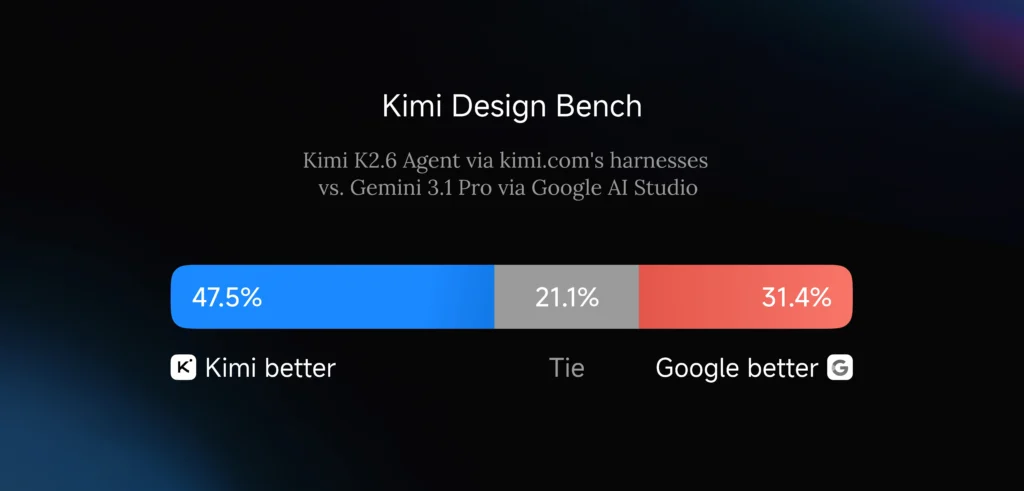
Motion-Rich Frontend: From Code Generator to Visual Artist
The other capability that Moonshot is emphasizing, somewhat surprisingly, is frontend craftsmanship. K2.6 isn’t positioned as just a “write me a React component” model. It’s positioned as a motion designer that happens to write code.
From the official Kimi announcement, the model can natively produce:
- Videos embedded in hero sections
- WebGL shaders
- GSAP + Framer Motion animations
- Three.js 3D scenes
The Decoder’s coverage includes a demonstration video where K2.6 spins up a complete website with animations and live database connections from a single text prompt, pulling in image and video generation tools to keep visual consistency across pages. The model handles sign-up flows, session management, and database operations — what Moonshot calls “basic full-stack” work but which is, in practice, the bulk of what small product teams actually ship.
This is a real shift in what open-source models have been optimized for. The previous generation — including K2.5, Qwen variants, and DeepSeek’s coding models — could write functional React. They could not, however, produce the kind of motion-rich, polished frontend output that you’d want to show a client. K2.6 is the first open-weight model where the output approaches something you’d actually ship without embarrassment.
Agent Swarms: 300 Sub-Agents, 4,000 Steps
If long-horizon coding is the “depth” story of K2.6, Agent Swarm is the “breadth” story. Moonshot’s launch materials confirm the new limits: 300 parallel sub-agents per run, each taking up to 4,000 coordinated steps. That’s a 3x increase in parallelism and nearly 3x increase in depth-per-agent over K2.5’s 100-agent, 1,500-step ceiling.
The architecture decomposes a complex prompt into heterogeneous subtasks — research, analysis, writing, design, coding — and routes each to a dynamically instantiated specialist agent. The swarm coordinates through a shared state and produces end-to-end deliverables: documents, websites, slide decks, spreadsheets, all from a single prompt.
One demo Moonshot published shows K2.6 producing a full pitch deck — complete with market analysis, custom charts, and animated transitions — entirely autonomously from a one-sentence brief. Another shows the swarm generating 100+ files of a coordinated application codebase from a single “build me X” prompt.
The commercial implication is significant. The Kilo Blog post points out that K2.6 also lets you convert files — PDFs, spreadsheets, slide decks, Word documents — into agent skills. That is: you give the swarm your company’s SOP doc, and it becomes a callable capability inside your agent. This moves agent infrastructure meaningfully toward the “plug-in your institutional knowledge” workflow that Microsoft, Google, and OpenAI have all been circling for a year.
Claw Groups: Humans, Agents, and Bring-Your-Own-Models
The most forward-looking — and frankly speculative — feature in K2.6 is Claw Groups, shipping as a research preview. The premise: you can bring agents from any device, running any model, into a shared operational space. K2.6 acts as the adaptive coordinator, routing tasks based on agent skill profiles, handling failures automatically, and keeping humans in the loop where appropriate.
Moonshot’s own marketing team reportedly uses Claw Groups to run end-to-end content production: specialized agents for demo creation, benchmarking, social media scheduling, and video editing, all orchestrated by K2.6. The Decoder’s launch coverage includes a demo video of the Claw Groups workflow in action.
It’s easy to be cynical about this kind of feature — “multi-agent orchestration” has been the hype term of choice for nearly two years, and most implementations have been disappointing. But the positioning here is notable: Claw Groups is explicitly heterogeneous. You’re not required to run pure K2.6. You can bring a Claude instance, a local Qwen, a custom fine-tune, and a human reviewer, and K2.6 coordinates them. If that actually works at production scale, it’s a meaningful step toward the mixed-model future that a lot of enterprise buyers have been asking for.
K2.6 also powers OpenClaw, Hermes Agent, and other proactive-agent products that Moonshot is positioning for 24/7 autonomous operation. These are agents that don’t wait to be prompted — they monitor queues, watch systems, and act on triggers. The stamina claims about K2.6 become much more relevant in that context: a 12-hour autonomous run isn’t a demo flourish, it’s the operational minimum.
How K2.6 Stacks Up: Frontier Closed Models
Let’s get specific about the comparison most readers care about.
Against GPT-5.4 (xhigh reasoning): K2.6 wins on SWE-Bench Pro (58.6 vs 57.7), HLE with tools (54.0 vs 52.1), Toolathlon (50.0), and DeepSearchQA. GPT-5.4 wins on AIME 2026, GPQA Diamond, and pure reasoning tasks where tool use isn’t the bottleneck. GPT-5.4 also has a larger context window (reportedly 1M tokens). If you’re buying a model for “solve a hard problem in one shot,” GPT-5.4 is still the stronger pick. If you’re buying for “execute a long coding task end-to-end,” K2.6 is arguably stronger and costs a fraction as much.
Against Claude Opus 4.6 (max effort): K2.6 leads on SWE-Bench Pro (58.6 vs 53.4), HLE with tools (54.0 vs 53.0), Toolathlon (50.0 vs 47.2), and DeepSearchQA (92.5 vs 91.3). Claude Opus 4.6 retains advantages in certain creative writing evaluations and enterprise-specific benchmarks. Anthropic’s upcoming Opus 4.7 is rumored to close or reverse the coding gap, but as of this writing, K2.6 is arguably the strongest coding model in production.
Against Gemini 3.1 Pro: This is the closest comparison. K2.6 essentially ties Gemini 3.1 Pro on SWE-Bench Multilingual (76.7 vs 76.9) and V* (96.9 vs 96.9), and beats it on Toolathlon (50.0 vs 48.8). Gemini 3.1 Pro retains the lead on raw vision and multi-modal reasoning, where Google’s infrastructure advantages in image and video understanding are still hard to match.
The summary: K2.6 is at or above frontier on the majority of agentic and coding benchmarks, while remaining behind on pure single-shot reasoning and advanced vision. For most software engineering work, it is, right now, the best model you can use — and it’s the only one of that cohort with open weights.
How K2.6 Stacks Up: Open-Source Peers
Against other open-weight models — DeepSeek V3.2, Qwen 3 variants, Llama 4 derivatives, GLM-5 — K2.6 pulls away decisively on long-horizon execution. The K2.5 baseline from Moonshot’s GitHub was already the top open model on the Artificial Analysis Intelligence Index, outperforming Claude 4.5 Sonnet according to aggregated rankings. K2.6 builds on that lead rather than defending it.
The key differentiators:
- Tool-use reliability at scale. Other open models can hit decent one-shot benchmark scores, but most degrade rapidly as tool chains extend past a few hundred calls. K2.6’s 4,000-call runs are a category difference.
- Agent Swarm native support. No other open-weight model ships with first-party orchestration tooling at the 300-agent, 4,000-step scale.
- Frontend visual quality. K2.6’s motion-rich frontend generation is, based on early demos, substantially ahead of open-source peers who still produce functional-but-plain React.
- Pricing economics. At $0.95 input / $4.00 output, it’s cheaper than essentially every closed frontier model while offering competitive or superior capability in its target domain.
As the skeptical Novaknown piece argued in the days leading up to the launch, the right question about Kimi was never “will it match GPT-5.4 on reasoning?” It was “does it get the boring things right — tool state, streaming, long chains, failure recovery?” The partner testimonials from Vercel, Baseten, Ollama, Factory.ai, and Kilo Code suggest the answer is, at last, yes.
The Ecosystem: Kimi Code, OpenClaw, Hermes, and the API
K2.6 is available through four distinct surfaces, each optimized for a different use case:
- kimi.com — Chat mode and agent mode, free to try, with K2.6 as the default model.
- Kimi Code — Moonshot’s production-grade coding environment, now recommended as the default pairing with K2.6 for software engineering work.
- platform.moonshot.ai — The full developer API, with OpenAI-compatible and Anthropic-compatible endpoints.
- Hugging Face — Weights and code for self-hosted deployment under the modified MIT license.
Beyond Moonshot’s first-party surfaces, K2.6 is integrated from day one into Kilo Code’s Gateway, accessible via the Kilo CLI, VS Code and JetBrains extensions, Hermes, and KiloClaw. OpenClaw — the increasingly popular open-source agent framework — uses K2.6 as one of its default backing models. Tencent’s CodeBuddy, Genspark’s agent platform, and AlphaEngine’s FinGPT Agent have all previously integrated K2 family models and are expected to migrate to K2.6 on similar timelines.
What This Release Actually Means
Zoom out for a moment. In the nine months between July 2025 (the original K2) and April 2026 (K2.6), Moonshot AI has shipped five major model updates. Each has pushed a specific capability forward: K2 established the trillion-parameter MoE baseline; K2-0905 sharpened coding; K2-Thinking introduced chain-of-thought reasoning; K2.5 added multimodal and Agent Swarm; K2.6 consolidates all of it around long-horizon, agentic execution.
That cadence — a major release every 2-3 months — is faster than any frontier closed lab has managed over the same period. And unlike the closed labs, Moonshot is shipping open weights every time.
The implication for developers is straightforward. If you’re building an agentic product, the question is no longer “should we consider open-source to save costs?” It’s “what is the closed model giving us that justifies the premium?” On coding, agent orchestration, long-horizon execution, and tool-use reliability — the four things that matter most for agent-first products — K2.6 either leads the frontier or is indistinguishable from it.
The implication for the broader market is thornier. OpenRouter data already shows Chinese open-source models displacing American open-source models as the developer community’s preferred choice, with sustained usage patterns (not just launch-week spikes). K2.6’s specific combination of open weights, frontier-level capability, and aggressive pricing makes it very hard to argue against in any new agent deployment.
It’s worth being careful about one thing. Novaknown’s pre-launch critique raised a valid point that applies to every new model: many of the headline numbers are still company-claimed. The partner testimonials help, but genuinely independent third-party evaluation — especially stress-testing the long tool-use chains that are K2.6’s signature capability — will take weeks to arrive. If there’s a gap between the marketing and the reality, it will show up there.
But on the evidence available 48 hours into the release, the gap looks small. And the upside for an open-weight model that genuinely matches GPT-5.4 and Claude Opus 4.6 on the benchmarks developers actually care about is enormous.
The Bottom Line
Kimi K2.6 is the first open-source release that seriously contests frontier closed models on the benchmarks that matter for real-world agentic software engineering. It is not the best model in the world on every axis — GPT-5.4 still leads on raw reasoning, Gemini 3.1 Pro still leads on vision — but on SWE-Bench Pro, HLE with tools, Toolathlon, long-horizon coding, and agent orchestration, it is either at the top or tied for it.
It’s also a quarter the price of the closed alternatives, fully open-weight, and available through kimi.com, Kimi Code, the Moonshot API, and Hugging Face today.
For the first time in the post-GPT-4 era, the most capable model for a well-defined, commercially important workload is open-source. That is not a small thing. It is, in fact, precisely the kind of moment that determines which platform layer the next decade of AI products gets built on.
Moonshot named the company after the word for a long, difficult, improbable goal. The K2.6 release is the first moment where that name feels like it’s being used descriptively rather than aspirationally.
Kingy Launch Brief
Put the week’s verified AI launches in your inbox.
Every Friday, the verified AI launches, apps, funding rounds, pricing changes and under-the-radar moves worth knowing—source-linked and explained in five minutes.
Free · Every Friday · Unsubscribe anytime · No daily email