
Every number in this article is sourced directly from Anthropic’s and OpenAI’s own publications, or from third‑party analyses that quote them. Where one lab reported a score and the other didn’t, that gap is called out explicitly — no fabrication, no “reasonable estimates.”
The setup: two very different launches, 16 days apart
On April 7, 2026, Anthropic announced Claude Mythos Preview, a new general‑purpose frontier model positioned above the Opus tier (internally codenamed “Capybara”). Rather than making it broadly available, Anthropic gated it behind Project Glasswing, a coalition with AWS, Apple, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks, plus ~$100M in usage credits for critical‑infrastructure defenders.
Sixteen days later, on April 23, 2026, OpenAI released GPT‑5.5 (internally “Spud”) to Plus, Pro, Business, and Enterprise users in ChatGPT and Codex, with the API rollout following shortly after. OpenAI framed it as “a new class of intelligence for real work” and its first fully retrained base model since GPT‑4.5.
The two launches weren’t coordinated, which matters for this comparison: OpenAI did not benchmark GPT‑5.5 against Mythos Preview directly. Instead, GPT‑5.5’s official comparison table pits it against Claude Opus 4.7 and Gemini 3.1 Pro. Anthropic, for its part, benchmarked Mythos Preview against Claude Opus 4.6, GPT‑5.4, and Gemini 3.1 Pro — not GPT‑5.5, which hadn’t been released yet.
So the cleanest way to compare them is to line up the benchmarks each lab independently chose to report, and see where they overlap.
Also, keep in mind that GPT 5.5 is actually usable by the public while Mythos is not. Real world usage matters, and GPT 5.5 wins there by definition (at least as of April 23rd, 2026).
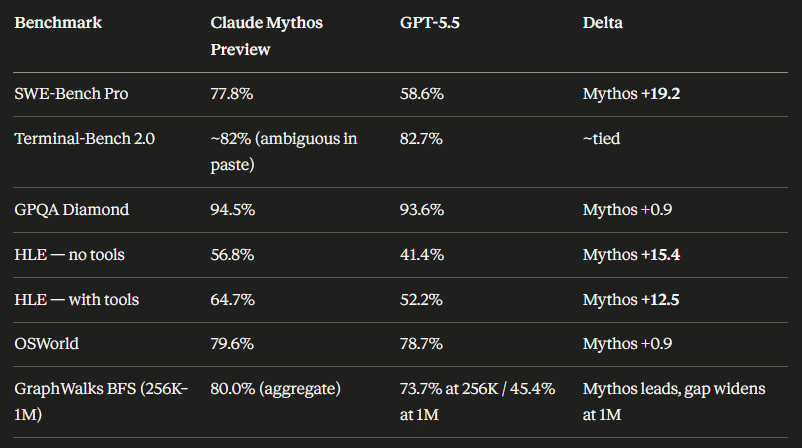
The head‑to‑head table (shared benchmarks only)
These are the benchmarks where both Anthropic’s Mythos system card and OpenAI’s GPT‑5.5 announcement reported scores:
| Benchmark | Claude Mythos Preview | GPT‑5.5 | Winner |
|---|---|---|---|
| SWE‑Bench Pro | 77.8% | 58.6% | Mythos (+19.2) |
| Terminal‑Bench 2.0 | 82.0% (92.1% extended timeout) | 82.7% | ~Tied (GPT‑5.5 +0.7 at default; Mythos +9.4 with extended timeout) |
| OSWorld‑Verified | 79.6% | 78.7% | Mythos (+0.9) |
| BrowseComp | 86.9% | 84.4% | Mythos (+2.5) |
| CyberGym | 83.1% (0.83) | 81.8% | Mythos (+1.3) |
That’s the entire set of directly comparable numbers. Five benchmarks. Every one of them goes to Mythos, though three of the five are within normal noise margins. The outlier is SWE‑Bench Pro, where Mythos’s 77.8% lead over GPT‑5.5’s 58.6% is a ~19‑point gap — massive by frontier‑model standards, and the number that Adam Holter’s pre‑launch analysis specifically flagged as the benchmark OpenAI was trying to close. Based on GPT‑5.5’s actual 58.6%, that gap is mostly intact.
Benchmarks Mythos reported but GPT‑5.5 did not
These are benchmarks in the Mythos system card (summarized in R&D World’s transcription of the table and on Anthropic’s Glasswing page) that have no corresponding GPT‑5.5 number in OpenAI’s launch materials:
| Benchmark | Mythos Preview | GPT‑5.5 |
|---|---|---|
| SWE‑Bench Verified | 93.9% | Not reported |
| SWE‑Bench Multilingual | 87.3% | Not reported |
| SWE‑Bench Multimodal (Anthropic internal implementation) | 59.0% | Not reported |
| USAMO 2026 (USA Math Olympiad) | 97.6% | Not reported |
| GPQA Diamond | 94.5% (Anthropic also cites 94.6% in Glasswing) | Not reported in GPT‑5.5 blog table* |
| Humanity’s Last Exam (no tools) | 56.8% | Not reported |
| Humanity’s Last Exam (with tools) | 64.7% | Not reported |
| GraphWalks BFS 256K–1M | 80.0% | Not reported |
| CharXiv Reasoning (no tools / with tools) | 86.1% / 93.2% | Not reported |
| LAB‑Bench FigQA (with tools) | 89.0% | Not reported |
| MMMLU | 92.7% | Not reported |
| Cybench | 100% (saturated) | Not reported |
*GPQA Diamond is one of the 10 evals inside the Artificial Analysis Intelligence Index that OpenAI references for GPT‑5.5’s composite score, but OpenAI does not publish a standalone GPQA Diamond number for GPT‑5.5 in the launch post — so for head‑to‑head purposes, it’s not directly comparable.
Vellum’s breakdown of the Mythos system card highlights the USAMO and BrowseComp numbers as “generational leaps”, and the fan‑operated archive Claude Mythos AI notes that 97.6% on USAMO 2026 is the number Anthropic’s own internal materials describe as “far ahead of any other AI model.”
One caveat worth reading carefully: Anthropic disclosed that its SWE‑Bench Multimodal score of 59.0% uses an internal implementation and is not directly comparable to public leaderboard scores. They also note that memorization screens flag a subset of problems on SWE‑bench Verified, Pro, and Multilingual, but that Mythos’s margin over Opus 4.6 holds even after excluding flagged items.
On Humanity’s Last Exam, Anthropic flags that Mythos “still performs well on HLE at low effort, which could indicate some level of memorization” — an unusually candid caveat that Vellum’s analysis notes is rare in the industry.
Benchmarks GPT‑5.5 reported but Mythos did not
Going the other direction, GPT‑5.5’s launch post leans heavily on a set of benchmarks Anthropic either didn’t report or reports differently for Mythos:
| Benchmark | GPT‑5.5 | Mythos Preview |
|---|---|---|
| Expert‑SWE (OpenAI internal, ~20‑hour long‑horizon coding tasks) | 73.1% | Not reported |
| GDPval (wins or ties across 44 occupations) | 84.9% (GPT‑5.5 Pro: 82.3%) | Not reported |
| Toolathlon | 55.6% | Not reported |
| FrontierMath Tier 1–3 | 51.7% (GPT‑5.5 Pro: 52.4%) | Not reported |
| FrontierMath Tier 4 | 35.4% (GPT‑5.5 Pro: 39.6%) | Not reported |
| Tau2‑bench Telecom (no prompt tuning) | 98.0% | Not reported |
| FinanceAgent | 60.0% | Not reported |
| Internal investment‑banking modeling tasks | 88.5% | Not reported |
| OfficeQA Pro | 54.1% | Not reported |
| GeneBench (multi‑stage genomics analysis) | Leading, exact number not specified in blog | Not reported |
| BixBench (bioinformatics) | “Leading performance among models with published scores” | Not reported |
Note that several of these — GDPval, Toolathlon, OSWorld‑Verified, BrowseComp — appear in GPT‑5.5’s comparison table against Claude Opus 4.7, not Mythos. Opus 4.7 is not Mythos; it is the newer, publicly released sibling of the Opus family. So even where OpenAI benchmarks against a “Claude” model, they are not benchmarking against the Claude model Anthropic itself calls its frontier.
Two GPT‑5.5 claims deserve their own line:
- On Artificial Analysis’s Coding Agent Index, OpenAI says GPT‑5.5 “delivers state‑of‑the‑art intelligence at half the cost of competitive frontier coding models.”
- OpenAI also claims an internal version of GPT‑5.5 with a custom harness “helped discover a new proof about Ramsey numbers,” later verified in Lean. This is a research artifact, not a benchmark, but it parallels Anthropic’s claim that Mythos autonomously discovered a 27‑year‑old OpenBSD vulnerability, a 16‑year‑old FFmpeg bug, and a 17‑year‑old FreeBSD NFS zero‑day.
The cybersecurity axis: Mythos is in a category of its own
This is the single biggest asymmetry in the two launches, and it’s worth handling as its own section.
Anthropic’s Frontier Red Team report describes Mythos Preview as the reason Project Glasswing exists at all. The specific numbers:
- Cybench: 100% (saturated) — Mythos solved every task. No other model has done this, per Vellum’s analysis.
- CyberGym: 83.1% vs Opus 4.6’s 66.6%.
- On Anthropic’s Firefox 147 exploitation benchmark, Opus 4.6 produced working exploits 2 times in several hundred attempts; Mythos produced 181 working exploits and achieved register control on 29 more.
- On ~7,000 OSS‑Fuzz entry points, Sonnet 4.6 and Opus 4.6 each achieved a single crash at Tier 3 severity. Mythos achieved full control‑flow hijack (Tier 5) on ten separate, fully patched targets.
- The UK’s AI Security Institute independently evaluated Mythos Preview and found it succeeds 73% of the time on expert‑level CTF tasks “which no model could complete before April 2025.” On AISI’s 32‑step “The Last Ones” simulated corporate‑network attack, Mythos is the first model to solve it end‑to‑end (3 of 10 attempts), averaging 22 of 32 steps. Opus 4.6, the next best, averaged 16 steps.
GPT‑5.5’s cyber story is much narrower. The official blog reports CyberGym: 81.8% (vs Claude Opus 4.7’s 73.1%) and notes “targeted testing for advanced cybersecurity and biology capabilities” with red‑teamers. There is no equivalent Cybench number, no Firefox exploitation benchmark, no OSS‑Fuzz tier breakdown, no AISI‑style multi‑step range report, and no zero‑day disclosure count. That’s not a claim that GPT‑5.5 is weaker — it’s an observation that the two labs are not competing on the same cyber axes publicly. Mythos’s 83.1% on CyberGym edges GPT‑5.5’s 81.8% by 1.3 points, which is the only apples‑to‑apples data point available.
Where GPT‑5.5 genuinely leads (or appears to)
The one benchmark on Mythos’s own sheet where Anthropic did not report a clear win was MMMLU, where Mythos scored 92.7% vs. Gemini 3.1 Pro’s 92.6–93.6% range — effectively a tie. R&D World’s analysis calls this the “lone outlier” among the 18 benchmarks in Mythos’s system card. OpenAI didn’t report MMMLU for GPT‑5.5 either.
For long‑horizon coding, GPT‑5.5’s Expert‑SWE (73.1%) is OpenAI’s nearest analogue to Mythos’s multi‑hour agentic coding claims, but the evaluation was designed in‑house and has no Mythos number, so no head‑to‑head is possible.
On knowledge work and desktop computer use, GPT‑5.5 posts GDPval 84.9% and OSWorld‑Verified 78.7%. Mythos reported OSWorld at 79.6% but did not report GDPval. So on OSWorld, Mythos leads by 0.9 points; on GDPval, GPT‑5.5 is the only one with a number.
On pure math, GPT‑5.5 reports FrontierMath Tier 1–3 (51.7%) and Tier 4 (35.4%). Mythos reports USAMO 2026 (97.6%) but does not report FrontierMath. These are not the same benchmark — FrontierMath is explicitly designed to be harder and less saturable than competition math like USAMO — so claiming one model is “better at math” based on these two datasets would be a fabrication.
The meta‑observation: they’re benchmarking different models
Anthropic’s system card compares Mythos against Claude Opus 4.6 and GPT‑5.4. OpenAI’s GPT‑5.5 blog compares against GPT‑5.4 and Claude Opus 4.7. Neither lab is benchmarking against the other’s frontier. Even the Adam Holter analysis written before GPT‑5.5 launched framed the whole question as “will Spud close the SWE‑Bench Pro gap to Mythos?” Based on the final numbers, the answer is: not really — GPT‑5.5 at 58.6% vs Mythos at 77.8% leaves most of the gap intact, though Terminal‑Bench 2.0, OSWorld‑Verified, BrowseComp, and CyberGym are all within a couple of points.
There’s also a release‑shape asymmetry worth naming. Mythos Preview is not broadly available — it ships only to Glasswing partners and ~40 critical‑infrastructure organizations, and Anthropic has explicitly said they do not plan to release it publicly. GPT‑5.5, by contrast, is rolling out to all paid ChatGPT tiers today. So “who’s better” depends partly on whether the model you can actually use counts for more than the one with higher numbers on a PDF.
Sources and further reading
Primary documents
- Introducing GPT‑5.5 — OpenAI (April 23, 2026)
- Claude Mythos Preview — red.anthropic.com (April 7, 2026)
- Project Glasswing — anthropic.com
- Claude Mythos Preview System Card (PDF)
Third‑party analysis
- R&D World: “Claude Mythos leads 17 of 18 benchmarks Anthropic measured” — the cleanest table of Mythos’s own vendor‑reported numbers against Opus 4.6, GPT‑5.4, and Gemini 3.1 Pro
- Vellum: “Everything You Need to Know About Claude Mythos” — analysis of the system card including welfare assessment and alignment findings
- UK AI Security Institute: “Our evaluation of Claude Mythos Preview’s cyber capabilities” — independent third‑party cyber eval (April 13, 2026)
- Adam Holter: “OpenAI Spud: Leaked April 16 Release, Mythos‑Level Benchmarks” — pre‑launch framing of the SWE‑Bench Pro gap
- The New Stack: “OpenAI launches GPT‑5.5, calling it ‘a new class of intelligence'”
- Trending Topics: “OpenAI’s GPT‑5.5 Is About to Launch Soon” — the “Spud” / fully‑retrained context
- NYT: “Anthropic’s New Mythos A.I. Model Sets Off Global Alarms”
- LLM Stats: Claude Mythos Preview profile
- Claude Mythos — Independent Archive & Analysis (unofficial fan site)
Bottom line
On the five benchmarks where both models have numbers, Mythos Preview leads on all five, with SWE‑Bench Pro being the only decisive one (the other four are within a few points). On the twelve additional benchmarks Anthropic reported, there is no GPT‑5.5 number to compare against. On the eleven additional benchmarks OpenAI reported, there is no Mythos number to compare against. The two labs are publishing on largely non‑overlapping axes, and the single biggest real divergence — Anthropic’s cyber and zero‑day findings — isn’t really a benchmark comparison at all; it’s Anthropic arguing its model is capable enough to require a restricted release, while OpenAI is shipping GPT‑5.5 to millions of ChatGPT subscribers today.
If you want a one‑sentence answer: on vendor‑reported overlap, Mythos Preview is ahead; on real‑world availability, GPT‑5.5 is the only one of the two you can actually use.
Compare
- Claude Mythos Preview Benchmarks – The AI That Scored 93.9% on SWE-bench and Still Won’t Be Released
- GPT-5.5 vs Claude Opus 4.8: The Evidence-Based 2026 Comparison
Recent Launches
Latest News
- Claude Mythos Preview System Card: A Comprehensive Summary
- Claude Fable 5 and Claude Mythos 5: Anthropic’s Mythos-Class Era Has Arrived
- Claude Opus 4.7 Is Here — And It’s Smarter, Safer, and Surprisingly Honest
Continue Reading
Kingy Launch Brief
Put the week’s verified AI launches in your inbox.
Every Friday, the verified AI launches, apps, funding rounds, pricing changes and under-the-radar moves worth knowing—source-linked and explained in five minutes.
Free · Every Friday · Unsubscribe anytime · No daily email