
On what it means when a frontier lab benchmarks its shipping product against the model it refuses to ship.
If you were scrolling through AI launch news on April 16, 2026 and felt something land sideways in your brain when you looked at Anthropic’s Opus 4.7 launch chart, you weren’t imagining it. Aakash Gupta called it “the most unusual launch chart in frontier AI history,” and he’s not wrong. The rightmost column — shaded in that tasteful, slightly mournful beige Anthropic’s design team loves — is labeled Mythos Preview. It wins almost every row. And you can’t have it.
Not “you can’t have it yet.” Not “join the waitlist.” You — the person reading this, the developer who pays $200/month for Max, the Fortune 500 CTO whose team lives inside Claude Code — cannot use Mythos Preview. It is gated to roughly fifty vetted cybersecurity and critical-infrastructure partners under an umbrella called Project Glasswing, announced a week earlier. Anthropic has decided its capabilities are, in their words, too dangerous for broad release.
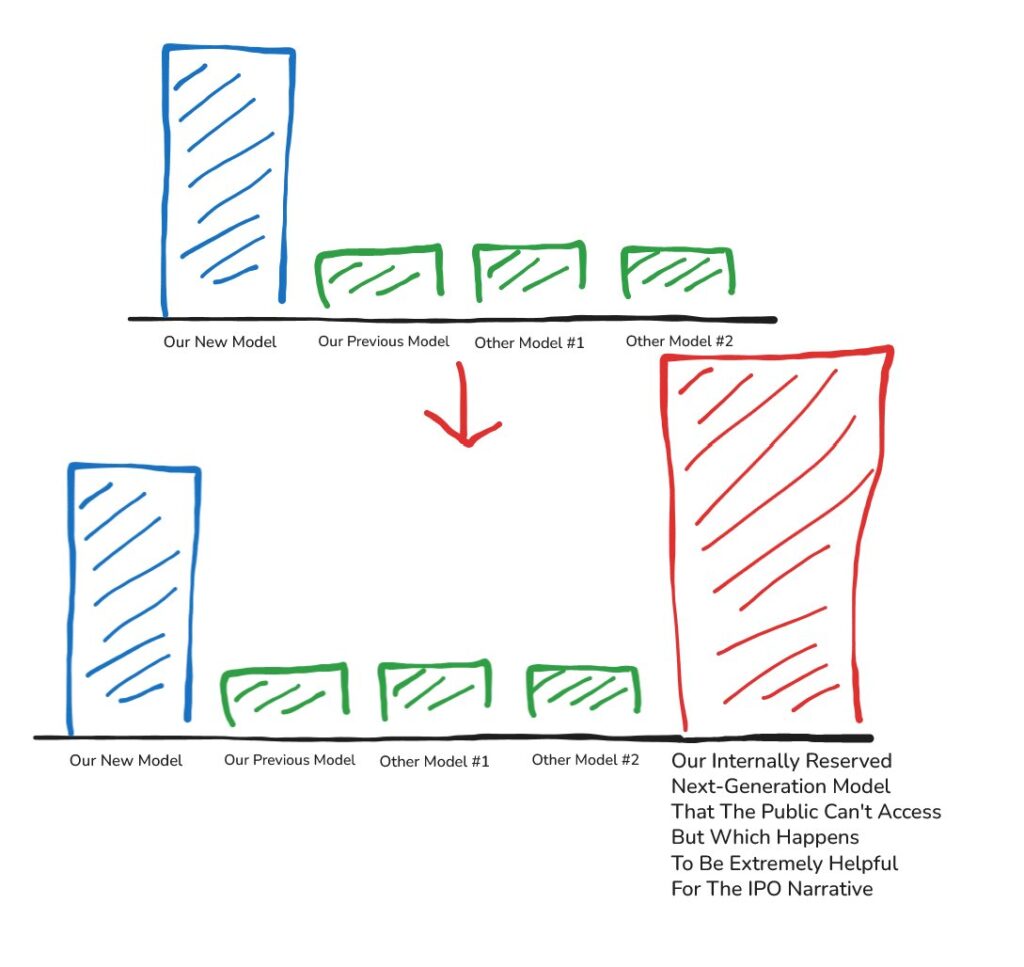
And yet there it sits, on the launch chart, comparing against the model you can buy. The frontier drawn on the ceiling, the product drawn on the floor, and the gap between them labeled, in effect, safety.
Let’s go through it, line by line, and then let’s talk about what on earth Anthropic thinks it’s doing.
The Benchmarks, Row by Row
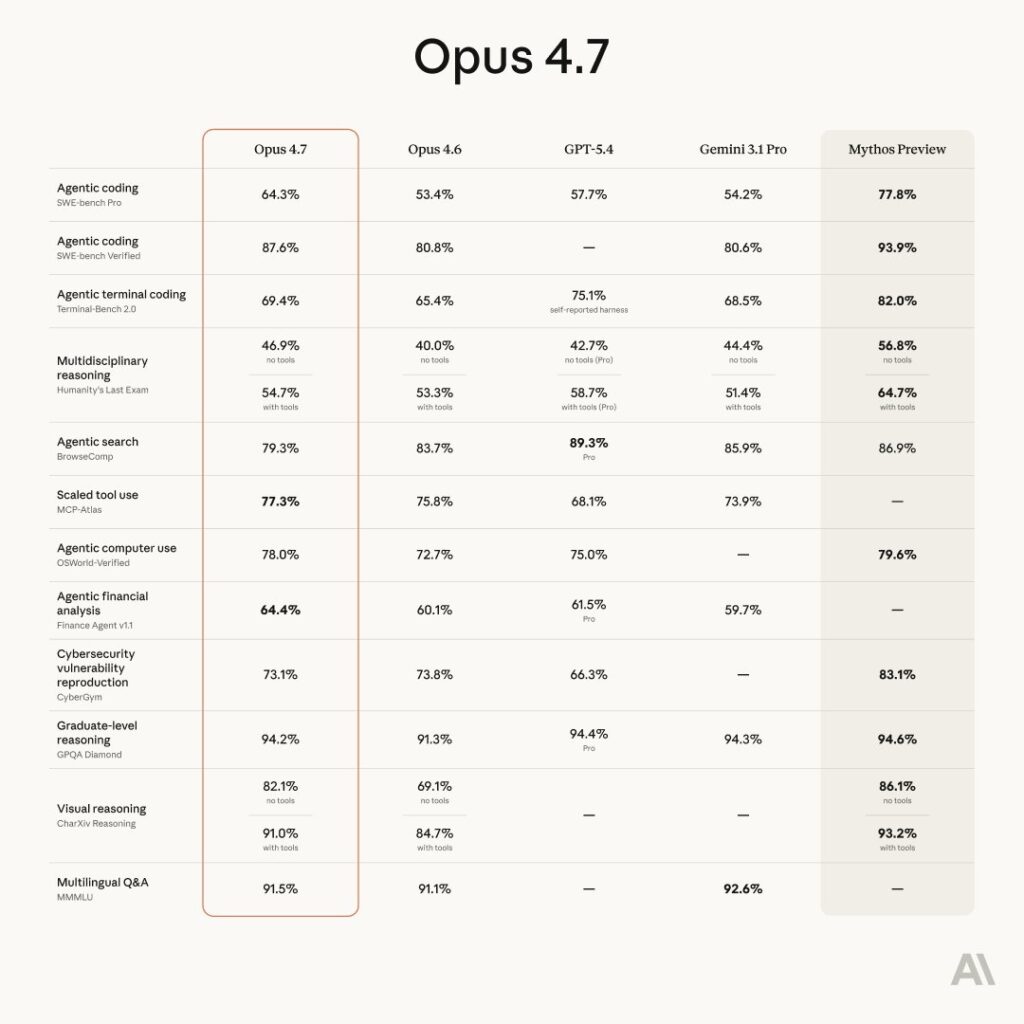
Here is the official comparison table from Anthropic’s Opus 4.7 announcement. Five columns: Opus 4.7 (the new thing), Opus 4.6 (last quarter’s thing), GPT-5.4, Gemini 3.1 Pro, and Mythos Preview.
1. Agentic coding — SWE-bench Pro
Opus 4.7: 64.3% | Mythos Preview: 77.8% | Gap: +13.5 points
SWE-bench Pro is the hard version of SWE-bench: real bugs from real open-source repositories, multi-file fixes, long context. Opus 4.7 beats GPT-5.4 (57.7%) and Gemini 3.1 Pro (54.2%) cleanly on this row. Mythos makes them all look like interns. 13.5 points on SWE-bench Pro is not a polish gap; it is a generational gap. This is where the “what you can’t have” story is loudest.
2. Agentic coding — SWE-bench Verified
Opus 4.7: 87.6% | Mythos Preview: 93.9% | Gap: +6.3 points
The benchmark the industry pretended was the ceiling two years ago. Opus 4.7 is very good here — state-of-the-art among released models. Mythos is almost at saturation. This is the single number most people will quote in tweets. Note that GPT-5.4 has no reported score.
3. Agentic terminal coding — Terminal-Bench 2.0
Opus 4.7: 69.4% | Mythos Preview: 82.0% | Gap: +12.6 points
Long-horizon agent work in a Linux shell — running builds, debugging processes, chaining tools. Note the asterisk on GPT-5.4’s 75.1%: “self-reported harness,” a delicate way of saying we don’t actually know. Gemini 3.1 Pro sits at 68.5%, just under Opus 4.7. Mythos is in its own tier.
4. Multidisciplinary reasoning — Humanity’s Last Exam
Opus 4.7: 46.9% / 54.7% (no tools / with tools) | Mythos Preview: 56.8% / 64.7% | Gap: +9.9 / +10.0 points
HLE is the cruel one — Olympiad-level problems across physics, math, law, linguistics, whatever else the authors could cook up to embarrass LLMs. A ten-point jump here means Mythos is crossing into reasoning territory no publicly available model has touched. GPT-5.4 Pro (with-tools) sits at 58.7%, closer to Mythos than Opus 4.7 is.
5. Agentic search — BrowseComp
Opus 4.7: 79.3% | Mythos Preview: 86.9% | Gap: +7.6 points
The one row where Opus 4.7 doesn’t win among released models — GPT-5.4 Pro takes it at 89.3%, Gemini at 85.9%. In fact, Opus 4.6 (83.7%) scores higher than Opus 4.7 here, which is an interesting tell that whatever Anthropic did to 4.7 made it worse at autonomous web browsing. That’s rare. It is also, arguably, the kind of regression you’d accept if you were deliberately dampening autonomy for safety reasons.
6. Scaled tool use — MCP-Atlas
Opus 4.7: 77.3% | Mythos Preview: — (not reported)
Opus 4.7 wins outright on the one benchmark Anthropic chose not to score Mythos on. Convenient? Maybe. Or maybe MCP-Atlas (Scale AI’s new tool-use benchmark) wasn’t stable when they tested Mythos. The asterisk on Anthropic’s page confirms Opus 4.6’s score was revised upward after a grading methodology change. Take scaled tool-use numbers with salt.
7. Agentic computer use — OSWorld-Verified
Opus 4.7: 78.0% | Mythos Preview: 79.6% | Gap: +1.6 points
Finally — a row where the gap closes. OSWorld measures GUI-driven computer use (clicking through actual desktop software to complete tasks). Mythos barely edges Opus 4.7. GPT-5.4 is right there at 75.0%. Gemini has no score.
This matters. If Mythos were uniformly a generation ahead, OSWorld would show it. It doesn’t. Whatever training recipe produced Mythos’s cyber dominance didn’t give it proportional gains in ordinary computer use. This is consistent with Anthropic’s Frontier Red Team blog post, which notes that Mythos’s cyber capabilities emerged as a downstream consequence of improvements in code reasoning, not a generally super-intelligent leap.
8. Agentic financial analysis — Finance Agent v1.1
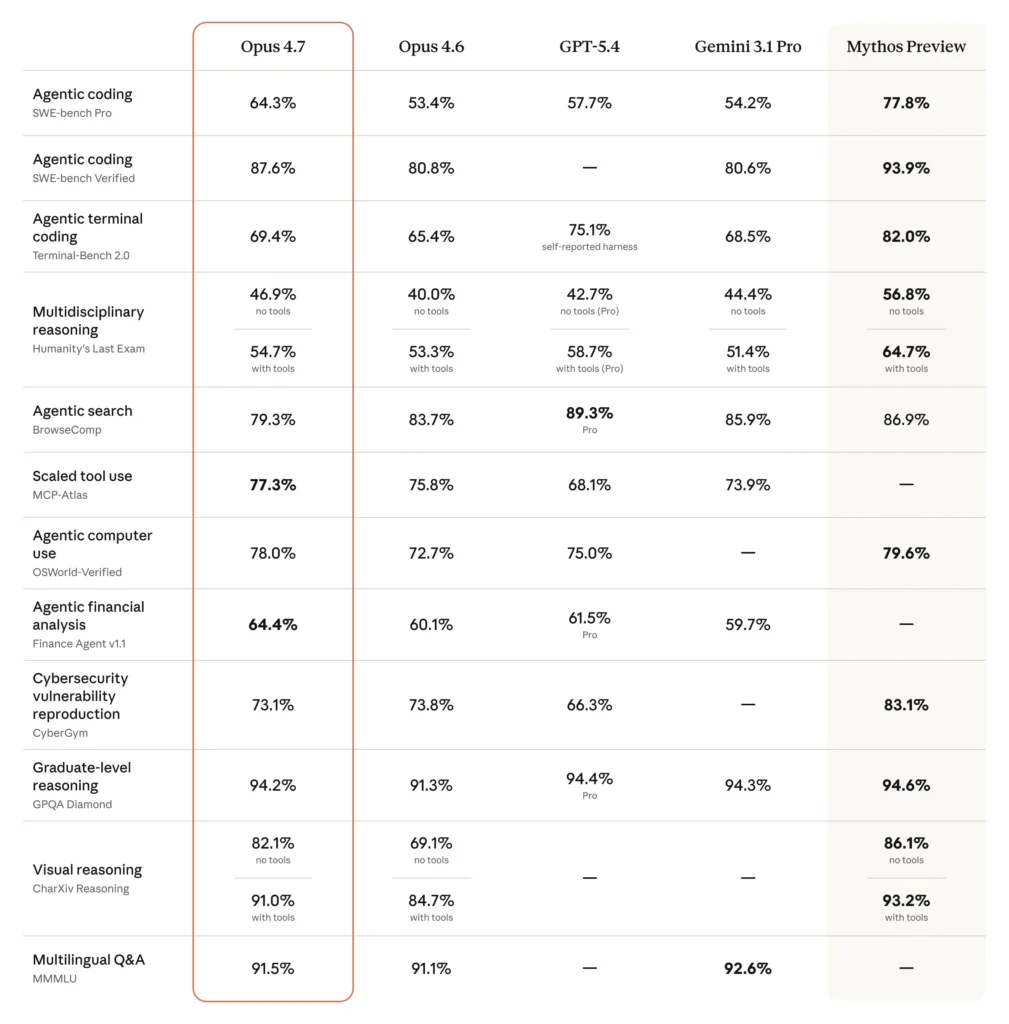
Opus 4.7: 64.4% | Mythos Preview: —
Opus 4.7 is actually best-in-class here, beating GPT-5.4 Pro (61.5%) and Gemini 3.1 Pro (59.7%). Anthropic doesn’t report Mythos. Again: convenient, or genuinely not evaluated? Given that finance-agent tasks don’t involve popping calc.exe through a JPEG parser, I believe the latter.
9. Cybersecurity vulnerability reproduction — CyberGym
Opus 4.7: 73.1% | Mythos Preview: 83.1% | Gap: +10.0 points
This is the row that explains the entire launch. CyberGym is the benchmark Anthropic used to trigger Project Glasswing in the first place. Note also: Opus 4.7 (73.1%) is lower than Opus 4.6 (73.8%). A regression. On cyber. A regression they didn’t even try to hide — it’s right there on the chart. Anthropic even confirms in the footnotes that Opus 4.6’s CyberGym number was revised upward from 66.6 to 73.8. So the “improvement” from 4.6 to 4.7 is actually a tiny step backward.
That’s the throttle. That’s the tax.
10. Graduate-level reasoning — GPQA Diamond
Opus 4.7: 94.2% | Mythos Preview: 94.6% | Gap: +0.4 points
Effectively identical. GPT-5.4 Pro ties at 94.4%. Gemini at 94.3%. GPQA Diamond is saturated. Everyone passes; this row no longer discriminates.
11. Visual reasoning — CharXiv Reasoning
Opus 4.7: 82.1% / 91.0% (no tools / with tools) | Mythos Preview: 86.1% / 93.2% | Gap: +4.0 / +2.2 points
Opus 4.7’s big improvement over 4.6 here (82.1% vs 69.1% without tools) is the “high-resolution vision” story Anthropic keeps selling. It’s a genuine capability jump — now capped at 2,576 pixels per edge, per Anthropic’s documentation. Mythos is better still, but not dramatically so. This is the chart row that suggests the Mythos-Opus gap is not uniform — it’s concentrated in code/cyber/reasoning, not perception.
12. Multilingual Q&A — MMMLU
Opus 4.7: 91.5% | Mythos Preview: —
Opus 4.7 barely loses to Gemini 3.1 Pro (92.6%). GPT-5.4 not reported. Mythos not reported. Boring row. Moving on.
Adding It Up
Across the rows where both models have scores, Mythos Preview beats Opus 4.7 by an average of roughly 8–9 percentage points, with the gap weighted heavily toward code, long-horizon agency, and cybersecurity. On perception (CharXiv) and graduate reasoning (GPQA), the gap narrows to noise.
This is a shape, not a ceiling. Mythos is not a smarter model in every direction. It is a much better coder and hacker, a meaningfully better long-horizon reasoner, and roughly comparable on everything else.
That shape matters for what comes next.
Why the Chart Is Weirder Than It Looks
Let’s be direct about what Anthropic just did, because nothing about this is accidental at a company that runs its launch copy through the Long-Term Benefit Trust.
They:
- Trained a model (Mythos Preview) that is clearly frontier-class.
- Decided it was too dangerous to ship because its cyber capabilities crossed a line — Logan Graham, head of the Frontier Red Team, told WIRED that Mythos can “accomplish things that a senior security researcher would be able to accomplish.”
- Trained Opus 4.7 and, per the launch blog post, “experimented with efforts to differentially reduce” its cyber capabilities during training. That’s the polite way of saying we nerfed it on purpose.
- Shipped Opus 4.7 as the product.
- Put Mythos on the launch chart anyway, in its own shaded column, as a visible ceiling you cannot buy.
Go read the Anthropic Opus 4.7 announcement yourself. The language is extraordinary:
“Opus 4.7 is the first such model: its cyber capabilities are not as advanced as those of Mythos Preview (indeed, during its training we experimented with efforts to differentially reduce these capabilities).”
No other frontier lab talks like this. OpenAI does not publish a “here’s our better internal model, which we have chosen not to release” chart. Google does not either. As Bruce Schneier observed in his take on Mythos, the standard industry playbook is the opposite: make the released product look like the frontier, and quietly sit on anything more capable. Anthropic has inverted the playbook. They have drawn a line on the floor labeled what we shipped, a line on the ceiling labeled what we have, and told you in footnote-polite English that the distance between them is a deliberate safety decision.
The Gupta thread calls this “Be Anthropic”:
Give people Opus 4.6. People love it. For 2 months you degrade Opus 4.6. You give back normal Opus 4.6 and call it Opus 4.7. People love it.
That’s unfair but not baseless. Look at CyberGym again: Opus 4.7 is a regression from Opus 4.6 on that row. That is the cost of the throttle, expressed in a benchmark number. Anthropic didn’t hide it; they footnoted the methodology change and let the number sit there. The result is a launch in which the most cyber-capable model you can run is, by Anthropic’s own reporting, the previous version.
Reading the Strategy Charitably
Before the whole thing gets written off as edging-as-a-service, it’s worth taking the charitable interpretation seriously, because I think some of it is actually correct.
1. It’s a policy move, not a marketing move.
Anthropic is built on the theory that frontier capability gaps will be dangerous before they are controllable. The Frontier Red Team’s Mythos post is a dense, technical document about chaining four vulnerabilities into a JIT heap spray that escapes both renderer and OS sandboxes. They achieved tier-5 control-flow hijack on ten fully-patched OSS-Fuzz targets — a class of capability that was essentially zero in Opus 4.6. The Firefox 147/148 exploit number is the one that rattles people: Opus 4.6 produced working exploits twice in several hundred attempts; Mythos produced 181, and achieved register control on 29 more.
If you believe — and I think you have to, at least on the evidence — that this is a real, generational jump in offensive cyber, then somebody on Earth is going to train a model like this in the next 6–18 months. Anthropic’s bet is that by publicly naming the capability gap, they force industry and government to plan for a world where a Mythos-class model is broadly available.
Putting Mythos on the launch chart, in that reading, isn’t flex. It’s evidence.
2. It’s a Responsible Scaling Policy in action.
Anthropic’s RSP is a public document that commits them to withhold capabilities above certain thresholds until they develop deployable safeguards. Mythos is the first model where a published threshold was actually triggered in a way that affected the shipping SKU. The Opus 4.7 announcement describes the new automatic detection/blocking safeguards for prohibited cybersecurity uses and the Cyber Verification Program that lets security teams apply for unfiltered access.
In other words: the chart says we had to make a choice, here is exactly how much we gave up, and here’s the program you can apply to if you are one of the people we actually trust with the full thing.
3. Project Glasswing is, if real, actually valuable.
Take at face value the claim that Mythos has already found thousands of high-severity zero-days across every major OS and browser, including a 27-year-old OpenBSD bug and a 16-year-old FFmpeg bug that automated tools had hit five million times without catching. Even the skeptics interviewed by Mashable — and there are many of them — largely agree the capability is real. The argument is about whether releasing it to AWS, Apple, Google, Microsoft, the Linux Foundation, Palo Alto Networks, CrowdStrike, and JPMorganChase under NDA is defense in depth or publicity theater.
Schneier splits the difference nicely: “Finding for the purposes of fixing is easier for an AI than finding plus exploiting. This advantage is likely to shrink, as ever more powerful models become available to the general public.”
So: defensive head start, real. Timeline, uncertain. PR benefit, enormous.
Reading the Strategy Uncharitably
Now the other side of the ledger, which I think the Gupta thread gets at even when it’s being glib.
1. Mythos on the chart is a commercial asset.
Every enterprise procurement conversation Anthropic has for the next three months now has a shadow column labeled “and this is what we’ve got behind the glass.” It’s very difficult to argue that’s accidental. The Mythos column tells a CIO: whatever OpenAI or Google offer you, we have more in the vault. That is worth real money. The safety framing doesn’t cancel the commercial framing; it just makes it classier.
2. The throttle has a number, and nobody has to tell you what it is.
This is the hard part. Anthropic says they “differentially reduced” cyber capabilities in Opus 4.7. How much? On CyberGym we can see it: ~10 points below Mythos, and functionally indistinguishable from Opus 4.6. On SWE-bench Pro, where Mythos scores 77.8% and Opus 4.7 scores 64.3%, you could frame the 13.5-point gap however you like — generational progress, safety tax, tokenizer change, methodology difference.
Which brings us to the rhetorical question in your prompt: if Opus 4.7 scores 64.3% on SWE-bench Pro and Mythos “scored a 93.9%,” what % of SWE-bench Pro is the too-dangerous percent?
Quick factual note: Mythos scored 77.8% on SWE-bench Pro. The 93.9% is SWE-bench Verified, which is a different, easier set. So the honest answer on Pro is:
- Too-dangerous delta = 77.8 − 64.3 = 13.5 percentage points (~21% of Opus 4.7’s raw score).
- On Verified = 93.9 − 87.6 = 6.3 points (~7%).
- On CyberGym = 83.1 − 73.1 = 10 points, which is the row Anthropic actually used to define “too dangerous.”
If you really want a single vibes-number for “the throttle,” across the rows where Mythos and Opus 4.7 both have scores, it averages roughly 8–10 percentage points. That’s the safety tax, on that day, by those benchmarks.
3. The “we degraded it on purpose” framing is unfalsifiable.
This is the sharpest point. There is no way — none — for an outside party to prove that Opus 4.7 was artificially held back rather than simply trained differently for other reasons (tokenizer changes, instruction-following improvements, alignment work, longer-horizon agent training). Anthropic’s claim to have deliberately suppressed capability is a claim, not a measurement. Heidy Khlaaf’s critique of the Mythos announcement in Mashable’s piece applies here too: “Releasing a marketing post with purposely vague language that clearly obscures evidence needed to substantiate Anthropic’s claims brings into question if they are trying to garner further investment.”
The chart is shaped like a safety disclosure. It functions as a marketing asset. Both things are true.
So Is Dario Edging Us?
I mean… kind of, yes.
That’s not even really the insult it sounds like. Every frontier lab is engaged in a months-long, public edging ritual now: tease a model, show some eval numbers, limit access, let the discourse build, release. What Anthropic has done differently is collapse the teasing phase of the next model into the launch slide of the current model. The ceiling and the floor on the same chart. Mythos is simultaneously the unreleased frontier and the star of a shipped product’s marketing page. That’s novel. It is also, arguably, a very clever way of selling the Opus 4.7 upgrade while pre-selling the Mythos relationship that eventually comes after Project Glasswing winds down.
There’s a corollary worth naming: Anthropic is making a bet that the public sees this kind of thing as trustworthy rather than smug. The CEO quoted in WIRED — Dario Amodei — says in the Glasswing launch video that Mythos wasn’t even trained to be good at cyber: “We haven’t trained it specifically to be good at cyber. We trained it to be good at code, but as a side effect of being good at code, it’s also good at cyber.” If that framing lands, Anthropic gets to be the adult in the room who warned us. If it doesn’t, they get to be the lab that wrote the first chart in AI history where the bragged-about model was literally unavailable.
What Opus 4.7 Actually Is, Once You Take the Mythos Column Off
If you cover the rightmost column with your hand — as, let’s be fair, almost every real user is going to — Opus 4.7 is a completely respectable upgrade:
- SWE-bench Pro: +10.9 over Opus 4.6, +6.6 over GPT-5.4, +10.1 over Gemini 3.1 Pro. Real gains.
- SWE-bench Verified: 87.6%, ahead of Opus 4.6’s 80.8% and Gemini’s 80.6%. GPT-5.4 didn’t report.
- Terminal-Bench 2.0: 69.4%, beating Opus 4.6 (65.4%) and Gemini (68.5%). GPT-5.4 is “ahead” at 75.1% but with a self-reported harness.
- HLE: Meaningful jumps both with and without tools, leading the released field without tools and very close to GPT-5.4 Pro with tools.
- Scaled tool use (MCP-Atlas): 77.3%, best among released models.
- Visual reasoning (CharXiv): massive jump from Opus 4.6, reflecting the new 3.75-megapixel vision.
- Finance Agent v1.1: best-in-class at 64.4%.
Partner quotes on the launch page hit the same notes over and over: instruction-following is better, tool-call accuracy is better, it stops agreeing with you, it doesn’t loop, it surfaces real bugs, it passes Terminal-Bench tasks no prior Claude could. Vercel’s Joe Haddad says it now “does proofs on systems code before starting work, which is new behavior we haven’t seen from earlier Claude models.” Cursor’s Michael Truell says CursorBench went from 58% on Opus 4.6 to 70% on Opus 4.7. XBOW’s Oege de Moor says a visual-acuity benchmark jumped from 54.5% to 98.5%. These are large numbers on workloads that pay people’s salaries.
The honest two-sentence review of Opus 4.7: it is the best released coding agent in the world right now, by a clear margin on the hardest benchmarks, and it is cheaper per-correct-answer than Opus 4.6. If you are already a Claude customer, you upgrade. The asterisks are the tokenizer change (same text costs 1.0–1.35× more tokens) and the fact that effort levels think harder, so your bills are going to get interesting until you re-tune your harnesses, as Anthropic’s own migration guide warns.
The Real Question Underneath
Here is what I think the Mythos-shaped column on the Opus 4.7 chart is really asking the industry — and the public — to answer:
If a frontier lab can measure the safety tax of its own shipping product, is it a requirement that they tell you, or a branding choice?
Anthropic has made it a branding choice. They’re betting that governments, enterprises, and developers will reward transparency with trust, access, and dollars. They are also betting that when OpenAI and Google eventually ship their own “too dangerous to release” story — and OpenAI has already reportedly followed with a cyber-focused GPT-5.4-Cyber variant — the industry norm will have shifted toward showing the ceiling. If that happens, Anthropic will be first-mover on the new discipline of safety-as-comparative-benchmark.
If it doesn’t happen, Anthropic will look like a company that decided to ship a weakened product and put the weakening on the box. The Gupta version.
Both futures are live.
A Last Note on the Edging Question
To return — one last time — to the blunt version of the thesis: yes, there’s something strange about a company whose business model is selling you access to Claude also showing you, in the same announcement, a model it has decided you can’t have. The strangeness doesn’t disappear if the safety case is legitimate. It just shifts.
Either Anthropic is doing capital-T Transparency in a field where no one else even pretends to, and we should reward them for it while watching carefully.
Or Anthropic has discovered that the most valuable object in modern AI marketing is a locked box that investors, regulators, and enterprise buyers can all project their favorite fear or fantasy onto — and they’re showing you the box because the box sells the products around it.
It is probably a little of both. The charts don’t lie about the capability jump. The footnotes don’t lie about the throttle. The partner quotes don’t lie about Opus 4.7 being a real upgrade. And the rightmost column doesn’t lie about the fact that somewhere in San Francisco there is a weight file that makes all the shipped frontier models look slow at code and lethal at exploits.
What the chart won’t tell you — what no chart can tell you — is whether drawing the ceiling makes us safer or just makes us more aware of how low the floor is.
Probably both.
Probably, for a while, both.
Kingy Launch Brief
Put the week’s verified AI launches in your inbox.
Every Friday, the verified AI launches, apps, funding rounds, pricing changes and under-the-radar moves worth knowing—source-linked and explained in five minutes.
Free · Every Friday · Unsubscribe anytime · No daily email