

How xAI’s latest voice model is rewriting the rules for enterprise voice AI — with benchmark-topping scores, real-time reasoning, and production deployments already running Starlink’s phone lines.
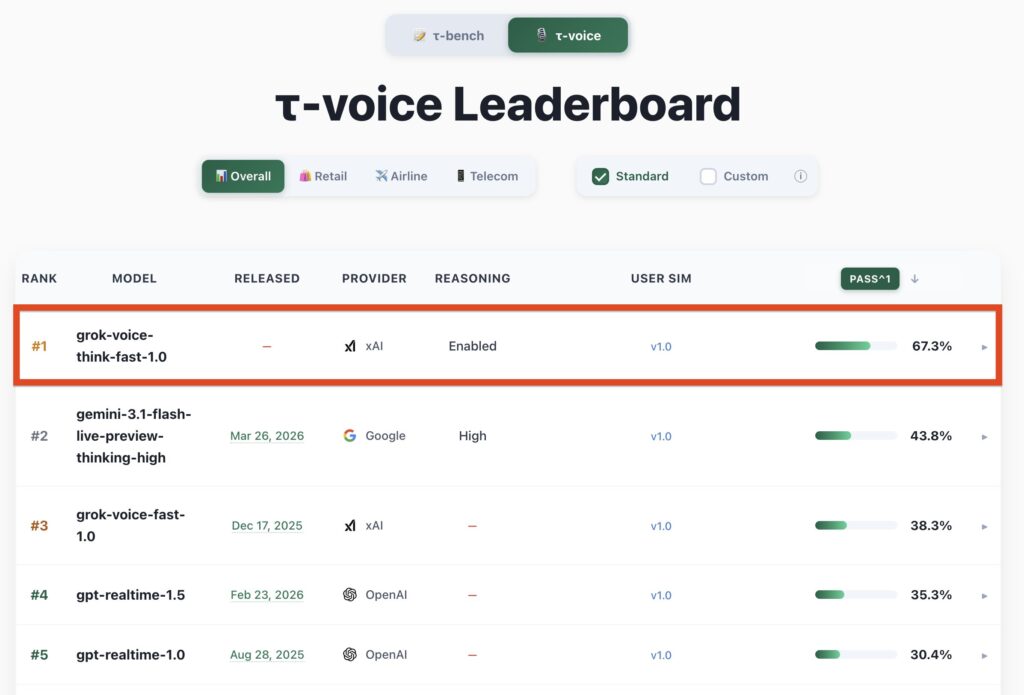
On April 23, 2026, xAI quietly shipped what may be the most consequential voice AI release of the year. Dubbed grok-voice-think-fast-1.0, the company’s new flagship voice model didn’t just arrive with marketing polish — it arrived holding the #1 position on the τ-voice Bench leaderboard, scoring 67.3% on pass^1 and leaving Google’s gemini-3.1-flash-live-preview-thinking-high (43.8%) and OpenAI’s gpt-realtime-1.5 (35.3%) firmly in the rear-view mirror.
For anyone who’s been tracking the voice AI race — from OpenAI’s Realtime API to Google’s Gemini Live to ElevenLabs’ Conversational AI — this is a watershed moment. xAI has moved from “fast follower” to “frontier leader” in under eighteen months, and the numbers behind Think Fast 1.0 tell a story that goes well beyond a single benchmark.
Let’s dig in.
What exactly is Grok Voice Think Fast 1.0?
At its core, grok-voice-think-fast-1.0 is xAI’s most capable voice agent, now available via API. xAI describes it as a “step change” in voice agent capabilities, purpose-built for complex, ambiguous, multi-step workflows across customer support, sales, and enterprise applications.
According to the official xAI announcement, the model was designed around four hard problems that have historically broken voice AI in production:
- High-stakes data entry — collecting email addresses, phone numbers, account numbers, and physical addresses without errors.
- High-volume tool calling — orchestrating dozens of tools across a single conversation.
- Real-time reasoning — thinking through edge cases without inflating latency.
- Real-world audio messiness — accents, background noise, telephony compression, and interruptions.
The previous generation of voice models (GPT Realtime, Gemini Live) have all struggled on at least two of those axes. Think Fast 1.0 is xAI’s attempt to solve all four simultaneously — and based on the benchmark data, they’ve largely succeeded.
The τ-voice Leaderboard: A Clean Sweep
The τ-voice Bench is the successor to the well-known τ-bench (Tau-Bench) framework — but purpose-built for full-duplex voice agents operating under realistic conditions. Unlike traditional text-based agent benchmarks, τ-voice evaluates models on:
- Noisy environments (background chatter, road noise, telephony compression)
- Heavy accents across 25+ languages
- Interruptions and turn-taking — the natural rhythm of human conversation
- Multi-turn tool use across Retail, Airline, and Telecom verticals
Here’s how the current overall leaderboard looks as of release day:
| Rank | Model | Provider | Reasoning | Pass^1 |
|---|---|---|---|---|
| #1 | grok-voice-think-fast-1.0 | xAI | Enabled | 67.3% |
| #2 | gemini-3.1-flash-live-preview-thinking-high | High | 43.8% | |
| #3 | grok-voice-fast-1.0 | xAI | — | 38.3% |
| #4 | gpt-realtime-1.5 | OpenAI | — | 35.3% |
| #5 | gpt-realtime-1.0 | OpenAI | — | 30.4% |
Let that gap sink in for a moment. Think Fast 1.0 doesn’t just edge out Gemini 3.1 Flash Live — it more than doubles GPT Realtime 1.5’s pass rate and lands 23.5 percentage points clear of Google’s best effort. In a benchmark ecosystem where 2-3 point gaps are often celebrated as “state of the art,” this is not incremental progress. It’s a discontinuity.
Vertical Breakdown
τ-voice publishes category-specific splits, and Think Fast 1.0 holds the top position across all three:
- Retail — Order handling, returns, and promotions in noisy environments
- Airline — Booking changes, flight delays, and complex itineraries
- Telecom — Plan changes, billing disputes, and technical troubleshooting
The telecom category is particularly noteworthy. It’s the same domain where xAI’s text model, Grok 4.1 Fast, previously scored near-perfect on τ²-bench Telecom with independent evaluation by Artificial Analysis. The pattern holds: xAI’s reinforcement learning in simulated customer-support environments appears to transfer cleanly from text to voice.
Benchmarks Beyond τ-voice: Big Bench Audio
Third-party benchmarking from Artificial Analysis (via the Artificial Analysis Speech-to-Speech Leaderboard) paints a consistent picture. On Big Bench Audio — which evaluates logic and reasoning using 1,000 adapted audio questions (object counting, navigation logic, spatial reasoning) — the Grok Voice lineage has been on a tear:
- 92.3% on Big Bench Audio — SOTA, taking the #1 spot from Gemini 2.5 Flash Native Audio
- 0.78 seconds average Time to First Audio — 3rd fastest on the leaderboard
- $0.05 per minute flat pricing — approximately half the cost of OpenAI’s Realtime API
That combination — SOTA reasoning, sub-second latency, and half the price of the nearest comparable offering — is rare in frontier AI. Usually you pick two. xAI appears to have picked three.
Under the Hood: “Thinking in the Background”
The “Think Fast” naming isn’t marketing fluff. It refers to a genuine architectural choice: real-time reasoning with zero added latency.
Most reasoning-enabled models (o1, Gemini 3 Pro Thinking, Claude Sonnet 4.5 extended thinking) pay a visible latency tax. You ask a question, you watch a spinner, and eventually you get an answer. That UX is tolerable in a chat window — but it’s fatal in a phone conversation, where half a second of silence makes the agent feel broken.
xAI’s solution is to run reasoning in the background, concurrently with the acoustic generation pipeline. Per the official blog:
“Grok Voice Think Fast performs reasoning in the background, allowing it to think through challenging queries and workflows in real-time with no impact on response latency.”
The practical effect is that the model can catch itself before confidently confabulating. xAI illustrates this with a deceptively simple example:
Prompt: “Which months of the year are spelled with the letter X?”
- Other models: “Only one month is spelled with the letter X. It’s February.”
- grok-voice-think-fast-1.0: “None of the months are spelled with the letter X. You can check them all, but X doesn’t appear in any month name.”
It’s the kind of trick question that reveals whether a voice model is actually reasoning or just pattern-matching to a plausible-sounding response. Voice models have historically been notorious for what xAI calls “confident, plausible-sounding answers, despite being completely wrong.” Think Fast 1.0 appears to be the first flagship voice model to meaningfully close that gap.
Data Entry: The Unglamorous Superpower
One of the most underrated sections of the xAI release post covers precise data entry and read-back — the unglamorous but business-critical workflow of collecting structured information over the phone.
If you’ve ever tried to spell your email address to an IVR system, you know how fragile this is. Accents, background noise, speech disfluencies (“uh, wait, I mean…”), and natural corrections (“no, that’s a B as in boy, not a D”) routinely break existing voice agents.
Think Fast 1.0 handles:
- Email addresses
- Physical street addresses
- Phone numbers
- Full names
- Account numbers
- Arbitrary structured data fields
It “gracefully handles speech disfluencies and accepts natural corrections as a human would,” then reads the normalized result back for confirmation. This is exactly the sort of capability that moves voice AI from “cool demo” to “deployable in a regulated industry.”
xAI’s earlier release of standalone Speech-to-Text and Text-to-Speech APIs is directly relevant here. On phone-call entity recognition benchmarks, Grok STT reports a 5.0% error rate vs ElevenLabs at 12.0%, Deepgram at 13.5%, and AssemblyAI at 21.3%. Think Fast 1.0 inherits that speech stack — which goes a long way toward explaining why its data-entry workflows feel so reliable.
The Starlink Deployment: Proof It Actually Works
Benchmarks are one thing. Production deployments are another. And this is where xAI’s release gets genuinely interesting.
Grok Voice Think Fast 1.0 isn’t being announced for Starlink — it’s already powering Starlink’s phone sales and customer support at +1 (888) GO STARLINK. The published metrics:
- 20% conversion rate. One in every five sales inquiries ends with a completed Starlink purchase — while the customer is still on the phone with Grok.
- 70% resolution rate. The majority of customer support inquiries are resolved autonomously, with no human handoff.
- 28 tools. A single agent orchestrates dozens of distinct tools across hundreds of support and sales workflows.
- High-stakes autonomy. The agent autonomously performs hardware troubleshooting, issues hardware replacements, and grants service credits.
The 70% autonomous resolution rate is the number that will get CFOs’ attention. For context, most enterprise voice-AI deployments target 30-40% containment before escalating to a human. Doubling that number while maintaining accuracy on high-stakes decisions (hardware replacements, service credits) is the difference between “voice AI is a nice-to-have” and “voice AI restructures the entire contact center org chart.”
How It Compares to the Competition
Let’s stack up the current frontier voice models head-to-head:
| Capability | Grok Voice Think Fast 1.0 | Gemini 3.1 Flash Live | GPT Realtime 1.5 |
|---|---|---|---|
| τ-voice pass^1 | 67.3% | 43.8% | 35.3% |
| Background reasoning | ✅ Native | ✅ High (with latency cost) | ❌ |
| Languages | 25+ native (100+ supported per prior Grok Voice) | 30+ | 20+ |
| Time to First Audio | ~0.78s | ~0.9s | ~1.1s |
| Approx. pricing | $0.05/min | Tiered | ~$0.10/min |
| Tool calling | Full JSON, MCP, parallel | Full JSON | Full JSON |
| Telephony (SIP) | Twilio, Vonage native | Partner-integrated | Partner-integrated |
| Production at scale | Starlink (live), Tesla (prior gen) | Limited | Various |
The pricing story deserves extra attention. xAI has consistently undercut competitors in 2025-2026 — Grok 4.1 Fast shipped at $0.20/M input and $0.50/M output tokens with a 2M context window (OpenRouter listing), substantially below Gemini 3 Pro and GPT-5 equivalents. Think Fast 1.0’s voice pricing extends that pattern into the voice modality.

What Makes τ-voice Different — And Why It Matters
A quick detour for readers wondering whether τ-voice is a legitimate benchmark or a vendor-selected scorecard.
τ-voice is the voice-specific extension of τ-bench (originally from Sierra), which has become the industry-standard benchmark for agentic tool use in realistic customer-support scenarios. What separates τ-bench from older evaluation suites is its insistence on:
- Pass^k metrics — reliability across repeated attempts, not just best-of-N
- Realistic policy adherence — following corporate policies, not just task completion
- Multi-turn stateful workflows — the kind of work that breaks naive agents
τ-voice extends all of that into the audio modality, where the degradation curve is brutal. Even top-performing text agents routinely lose 15-25 percentage points when the same workflow is evaluated over voice with realistic noise. The fact that Think Fast 1.0 holds 67.3% pass^1 under those conditions is a substantial technical achievement.
You can read the full benchmark methodology in xAI’s τ-voice benchmark details.
Try It Yourself
xAI has made the model available through its console, and developers can start experimenting immediately at console.x.ai/Playground/voice/agent. The company’s official launch post on X (@xai) emphasizes that the model is available via API starting today, with the same xAI SDK patterns that developers already use for Grok 4.1 Fast.
A minimal code snippet — extrapolating from xAI’s existing Agent Tools API patterns — looks like:
pythonCopyimport os
from xai_sdk import Client
client = Client(api_key=os.getenv("XAI_API_KEY"))
voice_agent = client.voice.create(
model="grok-voice-think-fast-1.0",
voice="eve",
tools=[...],
)
The unified developer surface is a real advantage. Teams building across text (Grok 4.1 Fast), speech-to-text, text-to-speech, and voice agents can stay in a single SDK — something developers on fragmented stacks (ElevenLabs for TTS + Deepgram for STT + OpenAI for LLM) will quickly appreciate.
The Bigger Picture: Voice AI’s Inflection Point
Zooming out, Think Fast 1.0 arrives at an inflection point for enterprise voice AI. Three trends are converging:
- Reasoning without latency penalty. Background reasoning pipelines — pioneered in text by o1-style models — are finally arriving in voice. Think Fast 1.0 is the clearest demonstration to date that “smart” and “fast” aren’t mutually exclusive.
- Production deployments at scale. Starlink’s live deployment (20% conversion, 70% autonomous resolution, 28 tools) is the kind of real-world proof point that moves voice AI from pilot-project purgatory to board-level strategy.
- Pricing compression. At approximately $0.05/minute, the economics of replacing Tier-1 support agents are no longer hypothetical. A human contact-center agent costs $15-30/hour fully loaded; Grok Voice costs $3/hour and is available 24/7 across 25+ languages.
The competitive response will be swift. OpenAI’s Realtime API will almost certainly see a GPT Realtime 2.0 update. Google’s Gemini Live team will push thinking-mode latency down. ElevenLabs, Deepgram, Cartesia, and Vapi will differentiate on telephony integration, voice cloning, and vertical specialization.
But as of April 23, 2026, the leader is unambiguous: Grok Voice Think Fast 1.0 is the most capable voice agent publicly available, and the benchmark gap is large enough that catching up will take competitors quarters, not weeks.
Final Thoughts
xAI has had a remarkable eighteen months. From the scrappy underdog behind Grok 1 to benchmark leader in text (Grok 4.1 Fast on τ²-bench Telecom), speech recognition (Grok STT on phone-call entity recognition), and now voice agents (Think Fast 1.0 on τ-voice Bench) — the cadence of frontier releases from the xAI team has been unrelenting.
What’s particularly striking about Think Fast 1.0 is that it’s not a technology demo. It’s a shipping product with a live Fortune 100-scale deployment (Starlink), a third-party-verified benchmark win, and pricing that makes the build-vs-buy calculus a no-brainer for most enterprise voice use cases.
If you’re a developer building voice experiences, a product leader evaluating voice AI vendors, or a CFO thinking about contact-center economics, Think Fast 1.0 deserves serious attention this week. The xAI Playground is open, the API is live, and the benchmark gap speaks for itself.
The voice AI race isn’t over. But as of today, xAI is running it from the front.








Comments 1