
A deep, source-checked breakdown of every benchmark, capability, price point, and caveat in OpenAI’s April 23, 2026 launch of GPT-5.5 and GPT-5.5 Pro.
On April 23, 2026, OpenAI officially unveiled GPT-5.5, roughly seven weeks after the launch of GPT-5.4 in early March. In The Verge’s coverage, OpenAI frames GPT-5.5 as its “smartest and most intuitive to use model yet” — a system “built to understand complex goals, use tools, check its work, and carry more tasks through to completion.” OpenAI’s own headline phrase, echoed across its launch thread on X, is blunter: GPT-5.5 represents “a new class of intelligence for real work and powering agents.”
The launch arrived after a week of speculation. 9to5Mac reported on an “NS41” cryptic post from OpenAI Developers on X that the community quickly decoded as “5.5.” Trending Topics had reported days earlier that the model, internally codenamed “Spud,” was being positioned as OpenAI’s first fully-retrained base model since GPT-4.5 — a bigger deal than the incremental “.1” and “.2” updates of the last year. A Reddit thread pointed to Polymarket odds converging on April 23 as the release date. They were right.
Below is an exhaustive walkthrough of what GPT-5.5 actually is, backed only by OpenAI’s official launch page, its X announcement thread, The Verge, and scores OpenAI explicitly published. Every benchmark number below is quoted verbatim from OpenAI’s evaluation tables — no extrapolations, no invented numbers.
The TL;DR: What Actually Changed
If you only have 60 seconds, here is the essential list:
- Two models launched today: GPT-5.5 and GPT-5.5 Pro.
- Availability: ChatGPT Plus, Pro, Business, Enterprise get GPT-5.5; Pro, Business, Enterprise also get GPT-5.5 Pro. Codex users on Plus, Pro, Business, Enterprise, Edu, and Go get GPT-5.5 with a 400K context window. API access is “coming very soon.”
- Per-token latency in real-world serving matches GPT-5.4, despite being a bigger, smarter model, per OpenAI.
- Token efficiency: Uses significantly fewer tokens than GPT-5.4 for Codex tasks — a claim visible across their Terminal-Bench 2.0 and Expert-SWE charts.
- API pricing (forthcoming): $5 / 1M input tokens and $30 / 1M output tokens for GPT-5.5 with a 1M context window. GPT-5.5 Pro is $30 / 1M input, $180 / 1M output. Batch and Flex are half the standard rate; Priority is 2.5× standard.
- Codex Fast mode generates tokens 1.5× faster for 2.5× the cost.
- Preparedness Framework classification: “High” for both biological/chemical and cybersecurity capabilities — but not Critical.
OpenAI also stressed on its X thread that early testers described GPT-5.5 as an iterative “research partner,” noting it performs especially well when paired with contextual inputs from documents and plugins.
The Benchmark Deep Dive
OpenAI published an unusually complete benchmark table comparing GPT-5.5 and GPT-5.5 Pro against GPT-5.4, GPT-5.4 Pro, Anthropic’s Claude Opus 4.7, and Google’s Gemini 3.1 Pro. I’ll walk through every cluster.
Coding
| Eval | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro (Public) | 58.6% | 57.7% | 64.3%* | 54.2% |
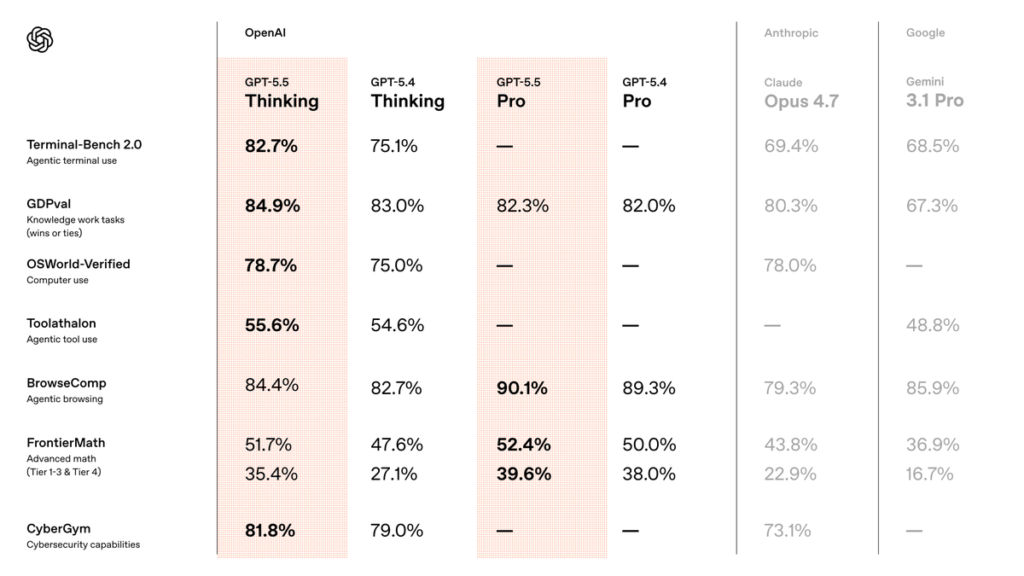
| Terminal-Bench 2.0 | 82.7% | 75.1% | 69.4% | 68.5% |
| Expert-SWE (Internal) | 73.1% | 68.5% | — | — |
On SWE-Bench Pro — Scale AI’s contamination-resistant successor to SWE-bench Verified — GPT-5.5 scores 58.6%, trailing Claude Opus 4.7’s 64.3%. Critically, OpenAI calls out (with an asterisk in its own table) that “Anthropic reported signs of memorization on a subset of problems.” This is an unusually blunt footnote: OpenAI is not conceding the coding crown.
On Terminal-Bench 2.0, which simulates complex command-line workflows requiring planning, iteration, and tool coordination, GPT-5.5 is state-of-the-art at 82.7%, a massive +7.6-point leap over GPT-5.4 and a stunning +13.3 over Claude Opus 4.7. OpenAI’s own chart shows this gain is achieved while using fewer output tokens — GPT-5.4 peaks near 18,000 output tokens; GPT-5.5 tops out lower. That’s the efficiency claim in pictorial form.
On the internal Expert-SWE eval — described by OpenAI as representing long-horizon coding tasks with a “median estimated human completion time of 20 hours” — GPT-5.5 reaches 73.1%, up from 68.5%, again with fewer output tokens.
Computer Use and Vision
| Eval | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 |
|---|---|---|---|
| OSWorld-Verified | 78.7% | 75.0% | 78.0% |
| MMMU Pro (no tools) | 81.2% | 81.2% | — |
| MMMU Pro (with tools) | 83.2% | 82.1% | — |
OSWorld-Verified is the most important number here — it measures whether a model can operate real computer environments on its own. GPT-5.5 narrowly edges Claude Opus 4.7 (78.7% vs 78.0%), with Gemini 3.1 Pro not scored on this benchmark. This is the eval that directly substantiates the “computer use” pillar of OpenAI’s pitch.
Vision (MMMU Pro) is essentially a tie with GPT-5.4 when no tools are used — which is notable, as it implies the core multimodal encoder may be largely inherited rather than retrained. When tools are enabled, GPT-5.5 pulls ahead to 83.2%.
Tool Use
| Eval | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| BrowseComp | 84.4% | 82.7% | 90.1% | 89.3% | 79.3% | 85.9% |
| MCP Atlas | 75.3% | 70.6% | — | — | 79.1% | 78.2% |
| Toolathlon | 55.6% | 54.6% | — | — | — | 48.8% |
| Tau2-bench Telecom (no prompt tuning) | 98.0% | 92.8% | — | — | — | — |
Three items deserve flagging:
- GPT-5.5 Pro dominates BrowseComp at 90.1%, OpenAI’s agentic web-browsing benchmark, with Gemini 3.1 Pro in a distant second.
- MCP Atlas (Scale AI’s Model Context Protocol tool-use benchmark) is the one place where Claude Opus 4.7 (79.1%) and Gemini 3.1 Pro (78.2%) both beat GPT-5.5 (75.3%). OpenAI is transparent about this — an important asterisk for the “OpenAI is best at everything” narrative.
- Tau2-bench Telecom at 98.0% is the headline tool-use win, made more impressive by OpenAI’s footnote that it was run without prompt tuning (with GPT-4.1 as the user model). For context, OpenAI reported GPT-5.2 Thinking at 98.7% on this same benchmark in December 2025 — but with system-prompt assistance. The apples-to-apples comparison is jumps from GPT-5.4’s 92.8% to GPT-5.5’s 98.0%.
Academic and Reasoning
| Eval | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| GPQA Diamond | 93.6% | 92.8% | — | 94.4% | 94.2% | 94.3% |
| Humanity’s Last Exam (no tools) | 41.4% | 39.8% | 43.1% | 42.7% | 46.9% | 44.4% |
| Humanity’s Last Exam (with tools) | 52.2% | 52.1% | 57.2% | 58.7% | 54.7% | 51.4% |
| FrontierMath Tier 1–3 | 51.7% | 47.6% | 52.4% | 50.0% | 43.8% | 36.9% |
| FrontierMath Tier 4 | 35.4% | 27.1% | 39.6% | 38.0% | 22.9% | 16.7% |
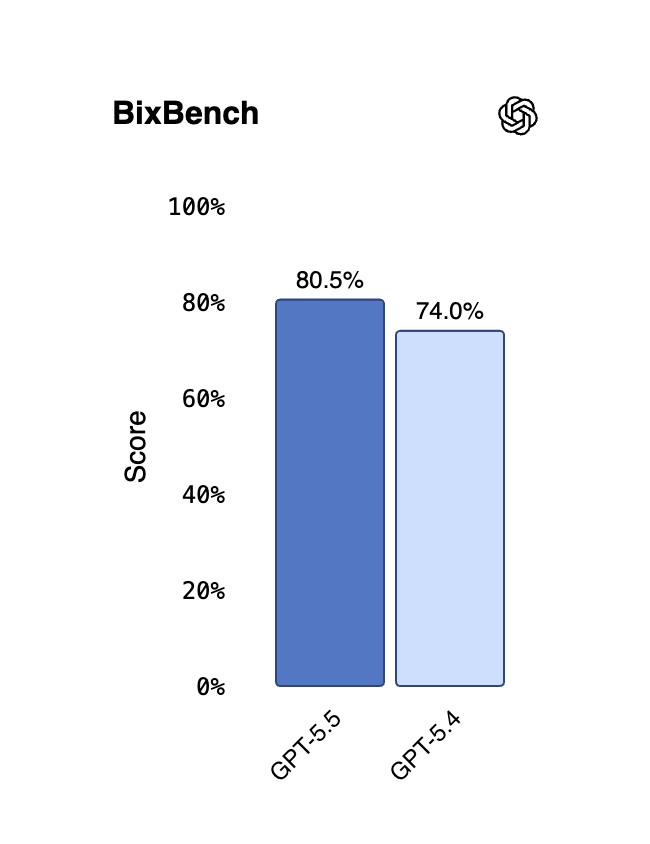
| BixBench | 80.5% | 74.0% | — | — | — | — |
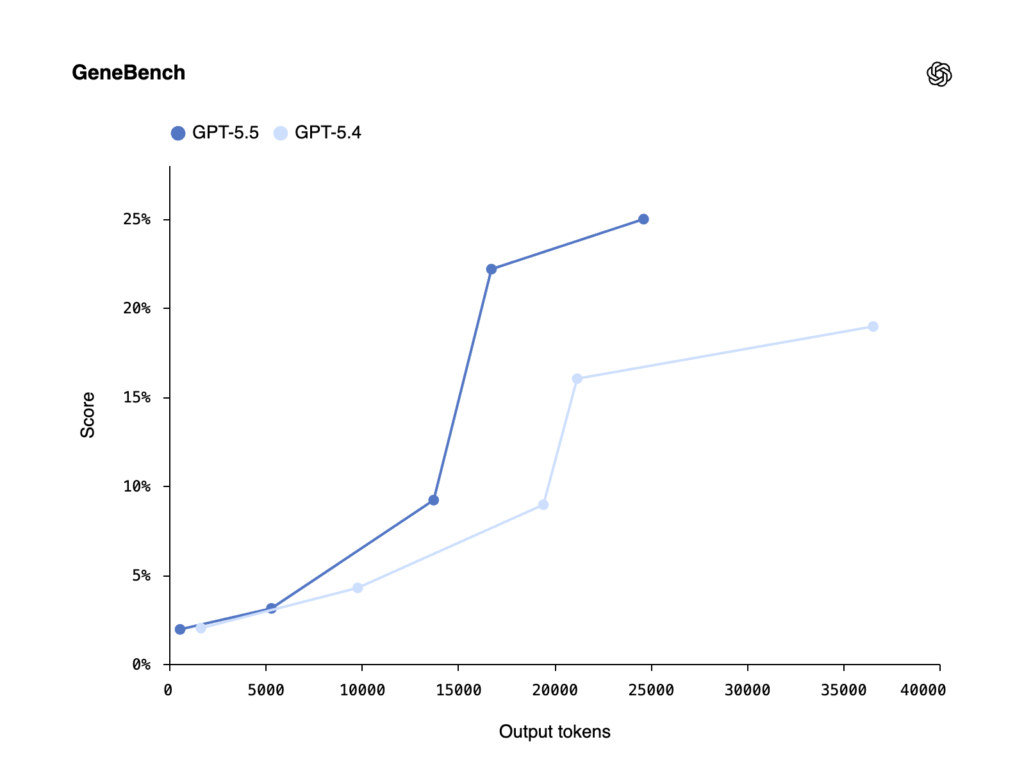
| GeneBench | 25.0% | 19.0% | 33.2% | 25.6% | — | — |
| ARC-AGI-1 (Verified) | 95.0% | 93.7% | — | 94.5% | 93.5% | 98.0% |
| ARC-AGI-2 (Verified) | 85.0% | 73.3% | — | 83.3% | 75.8% | 77.1% |
Several genuinely eye-catching results here:
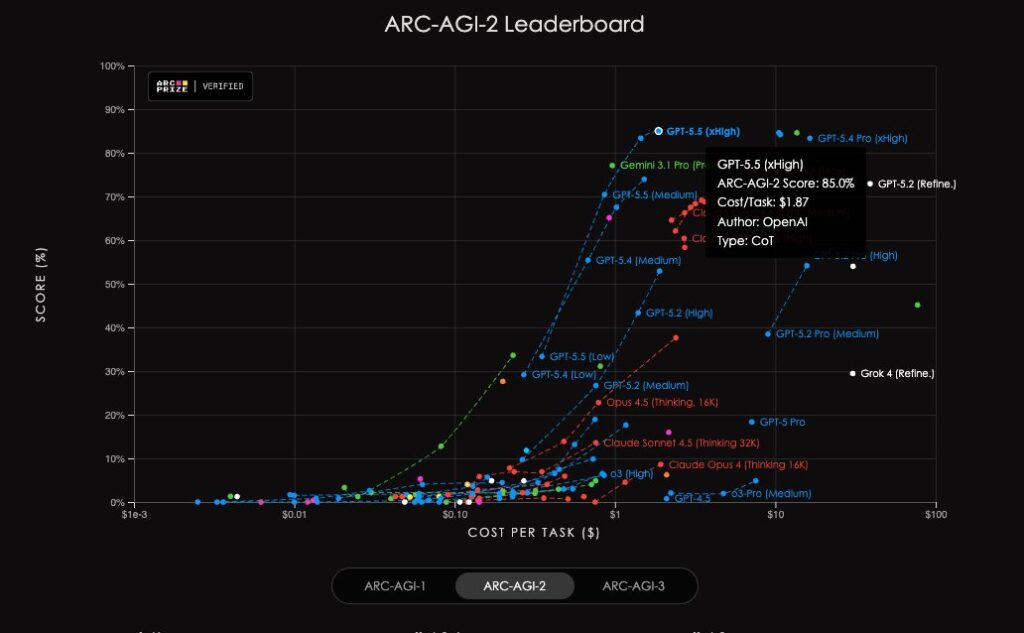
- ARC-AGI-2 at 85.0% is the single most impressive delta in the entire launch: +11.7 points over GPT-5.4 and a comfortable lead over Claude Opus 4.7 (75.8%) and Gemini 3.1 Pro (77.1%). ARC-AGI-2 is François Chollet’s successor to the original ARC benchmark and is designed to be specifically resistant to brute-force memorization.
- FrontierMath Tier 4, the hardest tier of Epoch AI’s FrontierMath benchmark, sees GPT-5.5 Pro jump to 39.6% — +12.5 over GPT-5.4 and more than double Claude Opus 4.7 (22.9%) and Gemini 3.1 Pro (16.7%).
- On GPQA Diamond and Humanity’s Last Exam (no tools), GPT-5.5 is not the leader. Claude Opus 4.7 wins HLE without tools (46.9%), and on GPQA Diamond, Gemini 3.1 Pro (94.3%), Claude Opus 4.7 (94.2%), and GPT-5.4 Pro (94.4%) all exceed GPT-5.5’s 93.6%. This matters for the “raw PhD reasoning” narrative.
- BixBench — a real-world bioinformatics benchmark linked by FutureHouse — sees a +6.5-point jump to 80.5%. GeneBench, a new eval focused on multi-stage genetics and quantitative biology, shows GPT-5.5 Pro at 33.2%. As OpenAI notes, GeneBench tasks often “correspond to multi-day projects for scientific experts.”
Professional Knowledge Work
| Eval | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| GDPval (wins or ties) | 84.9% | 83.0% | 82.3% | 82.0% | 80.3% | 67.3% |
| FinanceAgent v1.1 | 60.0% | 56.0% | — | 61.5% | 64.4% | 59.7% |
| Investment Banking Modeling (Internal) | 88.5% | 87.3% | 88.6% | 83.6% | — | — |
| OfficeQA Pro | 54.1% | 53.2% | — | — | 43.6% | 18.1% |
GDPval, OpenAI’s own eval measuring knowledge work across 44 occupations judged by real industry professionals, now sits at 84.9% for GPT-5.5 and 82.3% for GPT-5.5 Pro. The “wins outright” breakdown is even more revealing: 68.2% for GPT-5.5 vs 46.8% for Gemini 3.1 Pro. GDPval tasks include deliverables like sales decks, tax schedules, and urgent-care schedules — actual professional artifacts.
Interestingly, Claude Opus 4.7 outperforms GPT-5.5 on FinanceAgent v1.1 (64.4% vs 60.0%), another honest concession in OpenAI’s published table. On OfficeQA Pro, though, the gap between GPT-5.5 (54.1%) and Gemini 3.1 Pro (18.1%) is astronomical.
Long Context — The Biggest Quiet Upgrade
The single most under-discussed part of this launch is long-context performance. OpenAI’s table on the OpenAI MRCR v2 8-needle benchmark tells the story:
| Range | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 |
|---|---|---|---|
| 4K–8K | 98.1% | 97.3% | — |
| 128K–256K | 87.5% | 79.3% | 59.2% |
| 256K–512K | 81.5% | 57.5% | — |
| 512K–1M | 74.0% | 36.6% | 32.2% |
The 512K–1M jump from 36.6% to 74.0% is a ~2× absolute gain. On Graphwalks BFS 1mil f1, GPT-5.5 hits 45.4% vs GPT-5.4’s 9.4% and Claude Opus 4.6’s 41.2% — the closest Opus comparison OpenAI published. Combined with the 1M-token API context window OpenAI confirmed, this is a genuine unlock for repo-scale and deep-research workflows.
Cybersecurity
| Eval | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 |
|---|---|---|---|
| Capture-the-Flags (Internal, hardest) | 88.1% | 83.7% | — |
| CyberGym | 81.8% | 79.0% | 73.1% |
OpenAI explicitly classifies GPT-5.5 cybersecurity capabilities as “High” under its Preparedness Framework — not Critical — but acknowledges the gains are non-trivial. To compensate, OpenAI is simultaneously expanding Trusted Access for Cyber, providing cyber-permissive access for verified defenders, including a GPT-5.4-Cyber variant. The Verge specifically flagged GPT-5.4-Cyber as OpenAI’s response to Anthropic’s recent Mythos Preview model.
Architecture, Efficiency, and Infrastructure
The central engineering claim is this: GPT-5.5 matches GPT-5.4 per-token latency in real-world serving, while being substantially more intelligent and using fewer tokens per task. OpenAI’s explanation, per its launch announcement, is that serving at this level required a full-stack rethink.
Key points:
- GPT-5.5 was “co-designed for, trained with, and served on NVIDIA GB200 and GB300 NVL72 systems.”
- Justin Boitano, NVIDIA’s VP of Enterprise AI, says in the launch post: “Built and served on NVIDIA GB200 NVL72 systems, the model enables our teams to ship end-to-end features from natural language prompts, cut debug time from days to hours.”
- OpenAI writes that Codex itself helped optimize the stack. The specific example: prior load balancing split each GPU request into a fixed number of static chunks; Codex analyzed “weeks’ worth of production traffic” and wrote custom heuristic partitioning algorithms. The reported result: token generation speeds increased by over 20%.
This is notable as a public claim of self-bootstrapping — Codex (powered by GPT-5.5) helping to optimize the infrastructure that serves GPT-5.5.
On the Artificial Analysis Coding Agent Index, OpenAI claims GPT-5.5 delivers “state-of-the-art intelligence at half the cost of competitive frontier coding models.” OpenAI’s own chart places GPT-5.5 above Claude Opus 4.7, Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro Preview on the Intelligence Index while using fewer output tokens.
Real-World Testimony: Builders on Record
OpenAI’s launch materials are unusually quote-heavy — the implicit message being that benchmark gains are showing up in deployed systems. The most quoted line comes from Dan Shipper, CEO of Every, who calls GPT-5.5 “the first coding model I’ve used that has serious conceptual clarity.” He describes GPT-5.5 producing the same structural rewrite his best engineer eventually landed on — something GPT-5.4 could not do.
Pietro Schirano, CEO of MagicPath, reports GPT-5.5 merging “a branch with hundreds of frontend and refactor changes into a main branch that had also changed substantially, resolving the work in one shot in about 20 minutes.”
A confessional line: an unnamed NVIDIA engineer told OpenAI that “Losing access to GPT‑5.5 feels like I’ve had a limb amputated.”
Enterprise partner testimonials in the launch include Lovable, Cognition, Windsurf, GitHub, JetBrains, Sonar, Cisco, Abridge, Databricks, Harvey, Box, Lowe’s, Glean, Palo Alto Networks, and Ramp.
Fabian Hedin, CTO of Lovable, captures the builder sentiment most cleanly: “Tasks that used to take multiple attempts like authentication flows, real-time syncing, and multi-file edits started landing right the first time… That’s when building stops feeling like work and starts feeling like magic.”
Scientific Research: A Genuine Co-Scientist?
The scientific-research section of the launch is where OpenAI reaches furthest beyond coding:
- Derya Unutmaz, immunology professor at the Jackson Laboratory for Genomic Medicine, used GPT-5.5 Pro to analyze a gene-expression dataset of 62 samples and ~28,000 genes, producing a detailed research report. He estimates the equivalent analysis would have taken his team months.
- Bartosz Naskręcki, a mathematician at Adam Mickiewicz University, built an algebraic-geometry visualization app from a single prompt in 11 minutes. The app renders two quadratic surfaces and their intersection curve, and computes a Weierstrass model via an effective Riemann-Roch theorem.
- Ramsey number proof: OpenAI says an internal version of GPT-5.5 with a custom harness helped discover “a new proof about Ramsey numbers” — specifically a longstanding asymptotic fact about off-diagonal Ramsey numbers — “later verified in Lean.” The company frames this as “a concrete example of GPT‑5.5 contributing not just code or explanation, but a surprising and useful mathematical argument in a core research area.”
- Brandon White, Co-Founder & CEO at Axiom Bio, on drug discovery: “If OpenAI keeps cooking like this, the foundations of drug discovery will change by the end of the year.”
Combined with the BixBench (80.5%) and GeneBench (GPT-5.5 Pro at 33.2%) results, this paints GPT-5.5 as the first OpenAI model actively pitched as a “co-scientist” rather than a research assistant.
How OpenAI’s Real Teams Use GPT-5.5
Per OpenAI’s launch blog, more than 85% of OpenAI employees now use Codex weekly across software engineering, finance, comms, marketing, data science, and product. Three concrete examples OpenAI published:
- Comms analyzed six months of speaking request data, built a scoring and risk framework, and deployed an automated Slack agent so low-risk requests can be handled automatically.
- Finance reviewed 24,771 K-1 tax forms totaling 71,637 pages through a workflow that excluded personal information — the team finished two weeks earlier than the prior year.
- A Go-to-Market employee automated weekly business reports, saving 5–10 hours a week.
These are specific enough to be credible and small enough to be plausible. They’re also the clearest statement yet of what OpenAI believes the broad-deployment value proposition is: mid-complexity analytical work that blocks human calendars.
Pricing and Availability: The Fine Print
Per OpenAI’s announcement:
- ChatGPT: GPT-5.5 Thinking → Plus, Pro, Business, Enterprise. GPT-5.5 Pro → Pro, Business, Enterprise only.
- Codex: GPT-5.5 → Plus, Pro, Business, Enterprise, Edu, and Go plans, with a 400K context window. Fast mode is 1.5× faster at 2.5× the cost.
- API (coming soon):
- GPT-5.5: $5/M input, $30/M output, 1M context window. Batch and Flex at half price. Priority at 2.5×.
- GPT-5.5 Pro: $30/M input, $180/M output.
- Transition economics: OpenAI concedes “GPT-5.5 is priced higher than GPT-5.4” but argues it’s more token-efficient, so Codex users typically see better results for fewer total tokens.
The 1M API context window is the key number. Combined with the 74% score on the MRCR v2 512K–1M test, this is the first OpenAI model where the full million-token window is demonstrably usable, not just marketed.
The Competitive Picture
Per The Verge, GPT-5.5 drops “in an increasingly heated battle between OpenAI and Anthropic as the companies race to potentially go public later this year.” The article also notes that GPT-5.5’s release comes just days before the high-profile Musk vs. OpenAI trial set to begin in Oakland.
Based on OpenAI’s published numbers, the scoreboard looks like:
- GPT-5.5 clearly leads on: Terminal-Bench 2.0, GDPval, OSWorld-Verified, Toolathlon, OfficeQA Pro, CyberGym, ARC-AGI-2, FrontierMath Tiers 1–4, BixBench, and long-context benchmarks beyond 128K.
- Claude Opus 4.7 clearly leads on: SWE-Bench Pro (though OpenAI notes memorization concerns), MCP Atlas, Humanity’s Last Exam (no tools), FinanceAgent v1.1, and some Graphwalks mid-range tests.
- Gemini 3.1 Pro clearly leads on: ARC-AGI-1, and holds slight wins on GPQA Diamond.
This is a different pattern from the GPT-5.2 launch, where OpenAI effectively swept its comparison tables. GPT-5.5 trades in broader victory for honesty about specific losses, which makes the table more credible overall.
Safety, Safeguards, and Preparedness
OpenAI describes GPT-5.5 as shipping with its “strongest set of safeguards to date.” Concretely:
- GPT-5.5 went through OpenAI’s full safety and governance process including preparedness evaluations, domain-specific testing, and new targeted evaluations for advanced biology and cybersecurity capabilities.
- Feedback was collected from nearly 200 trusted early-access partners before release.
- Both biological/chemical and cybersecurity capabilities are classified “High” (not Critical) under the Preparedness Framework.
- New stricter classifiers for cyber risk have been deployed; OpenAI notes these may feel “annoying initially, as we tune them over time.”
- Trusted Access for Cyber expands cyber-permissive access for verified defenders. Organizations defending critical infrastructure may apply for access to GPT-5.4-Cyber under strict requirements.
- API deployments are still pending because they “require different safeguards.”
OpenAI also published a dedicated GPT-5.5 system card linked from the launch page.
What the Launch Doesn’t Tell Us (Yet)
A few honest gaps worth flagging:
- No architectural details. OpenAI does not disclose whether GPT-5.5 is a fully new base model or a retrained derivative, despite Trending Topics’ prior reporting that “Spud” was a ground-up retraining. Treat that claim as unverified by OpenAI itself.
- No token-count numbers for training. Unlike some prior launches, there is no parameter-count or training-compute disclosure.
- No Pro-tier stats for several benchmarks. GPT-5.5 Pro is not scored on Terminal-Bench 2.0, Expert-SWE, OSWorld-Verified, Toolathlon, CyberGym, Graphwalks, or most long-context tests. This is a meaningful gap for buyers trying to decide whether Pro is worth 6× the output price.
- Humanity’s Last Exam (no tools) gap. Claude Opus 4.7’s 46.9% vs. GPT-5.5’s 41.4% is the clearest “Anthropic still leads on raw frontier reasoning” signal in the whole table.
- API delay. API availability is “very soon” but unspecified — everyone building agentic products on the API is effectively waiting.
The Bigger Strategic Picture
Reading across the launch blog, X thread, and The Verge coverage, three strategic moves are visible:
- OpenAI is doubling down on agentic workflows over raw chat. Nearly every benchmark highlighted — Terminal-Bench 2.0, GDPval, OSWorld-Verified, Tau2-bench — measures tool-use and long-horizon execution, not Q&A. This continues the direction set by GPT-5.2, only more aggressively.
- Codex is the center of gravity. Codex is no longer positioned as a developer tool; it’s pitched as the substrate on which OpenAI itself runs 85%+ of company work. The finance, comms, and GTM vignettes are a blueprint for enterprise adoption.
- Infrastructure is a moat. The explicit GB200/GB300 NVL72 co-design, the 20% token-generation improvement from Codex-authored load balancing, and the “same latency, more intelligence” framing all point to inference-system efficiency as the next competitive battleground.
Should You Use GPT-5.5 Today?
Short answers by use case:
- Complex coding / repo-scale refactors / long-running engineering agents → Yes, based on Terminal-Bench 2.0, Expert-SWE, and the 1M context window. SWE-Bench Pro remains a toss-up vs. Claude Opus 4.7.
- Computer-use agents / browser automation / OS-level tasks → Yes, per OSWorld-Verified and BrowseComp.
- Financial analysis / spreadsheets / deck generation → Mostly yes, but Claude Opus 4.7 still leads on FinanceAgent v1.1.
- Scientific / bioinformatics research → Yes on BixBench, GeneBench, and FrontierMath. GPT-5.5 Pro is the genuinely new tier here.
- High-end academic reasoning → Mixed. Claude Opus 4.7 leads HLE without tools; Gemini leads ARC-AGI-1. GPT-5.5 leads ARC-AGI-2 decisively.
- Cost-sensitive production deployments → Wait for API pricing to settle and for independent efficiency benchmarks beyond OpenAI’s own.
Closing: What This Release Means
GPT-5.5 is not the kind of “everything scores jump by 20 points” launch that reshapes the field overnight. It is something more deliberate: a targeted consolidation of agentic and long-context capabilities, with transparent admission of the places where Anthropic and Google still lead, released on the infrastructure OpenAI will stand on for the next year.
The single most important number in the entire launch is not a benchmark. It’s this line from the OpenAI blog: “GPT-5.5 matches GPT-5.4 per-token latency in real-world serving, while performing better across nearly every evaluation we measured.” If that holds up under independent testing, GPT-5.5 is the first frontier model where “smarter” and “faster” stop being opposing forces — and the economics of agentic AI start to make sense for workflows that were previously too slow or too expensive to automate.
Everything else — the Terminal-Bench crown, the ARC-AGI-2 jump, the 1M context window, the Ramsey proof, the 85% internal adoption — is in service of that claim.
As Dan Shipper put it: it’s the first model with “serious conceptual clarity.” The next twelve months will tell us whether that clarity is an artifact of the benchmark suite, or a real inflection point in how useful AI is at work.
Continue Reading
Compare
- GPT-5.5 Is Here — And It’s Playing a Whole New Game
- GPT-5.5 vs Claude Opus 4.8: The Evidence-Based 2026 Comparison
Related Models
Latest News
- Inside GPT-5.4: The AI That Codes, Thinks, and Controls Your Computer
- OpenAI GPT-4.1: Inside OpenAI’s Evolution and Roadmap
Recent Launches
Kingy Launch Brief
Put the week’s verified AI launches in your inbox.
Every Friday, the verified AI launches, apps, funding rounds, pricing changes and under-the-radar moves worth knowing—source-linked and explained in five minutes.
Free · Every Friday · Unsubscribe anytime · No daily email