
Rio 3.5 Open 397B is a real, large, open-weight Hugging Face release tied to Rio de Janeiro’s municipal technology company. Its specs are impressive. Its benchmark claims are even bigger. The right response is neither hype nor dismissal, but verification.
As of June 14, 2026, this analysis treats the Hugging Face repository and model card as primary sources while distinguishing confirmed repository evidence from first-party benchmark claims that have not yet been independently reproduced.
TL;DR
Rio 3.5 Open 397B is a newly published Hugging Face model under prefeitura-rio/Rio-3.5-Open-397B. The repository is real, large, and downloadable: the Hugging Face API lists 97 safetensor shards, 110 repository files, and safetensor metadata totaling 403,397,928,944 tensor parameters, with an index total size of 806,795,875,168 bytes, or roughly 807 GB decimal / 751 GiB binary. The model card identifies the base model as Qwen/Qwen3.5-397B-A17B, tags the release as MIT-licensed, and says it was developed by IplanRIO, the municipal IT company associated with Rio de Janeiro’s city government. Hugging Face model card, Hugging Face API, raw config, safetensors index
The headline claims are substantial: about 397B total parameters, about 17B active parameters, a sparse Mixture-of-Experts architecture, multimodal input, multilingual coverage, a 1,010,000-token context window, and first-party benchmark results that place Rio close to leading open and proprietary models. The important caveat is that most Rio-specific benchmark claims appear only on the Rio model card at the time of writing. I found repository evidence for the weights, architecture, base-model relationship, modality configuration, and a permissive license tag. I did not find independent Rio benchmark reproductions, a published Rio training report, or repo-local code implementing the claimed SwiReasoning inference path.
That makes Rio 3.5 Open 397B interesting, but not yet settled. Builders should treat it as an auditable open-weight release with aggressive first-party claims, not as an independently proven new frontier champion. For broader context on choosing between closed, open, and local models, see Kingy AI’s guide: Which AI Model Should You Use?
Why This Release Matters
The unusual part is not just the scale. Open-weight MoE releases at hundreds of billions or trillions of total parameters are now part of the competitive landscape. Qwen, DeepSeek, Kimi, MiniMax, Meta, Z.ai/GLM, and others have already made large open or open-weight models central to the AI race.
The unusual part is the name on the repository. The Rio model card says the model was developed by IplanRIO – Empresa Municipal de Informatica e Planejamento S.A., which it describes as the municipal IT company of Rio de Janeiro’s city government. IplanRIO’s official site describes the organization as the municipal company responsible for administering the city’s information and communications technology resources. Rio model card, IplanRIO official site
That is a different release profile from the usual frontier-lab playbook. Frontier systems are normally launched by OpenAI, Anthropic, Google DeepMind, xAI, Alibaba/Qwen, DeepSeek, Moonshot, Meta, Mistral, MiniMax, or Z.ai. A city-government-associated technology company publishing a Qwen-derived, frontier-scale open-weight model is therefore notable even before the benchmark table enters the room.
It also lands at the center of a live strategic question: will the next useful AI stack be controlled mostly through closed APIs, or will open models become good enough for serious agentic software, government, and enterprise work? Kingy has covered that broader sovereignty question here: Open-source AI models, local LLMs, hardware, and AI sovereignty.
What Rio 3.5 Open 397B Is
Rio 3.5 Open 397B appears to be a post-trained derivative of Qwen3.5-397B-A17B. The Rio README front matter lists base_model: Qwen/Qwen3.5-397B-A17B, and the Hugging Face tags include base_model:Qwen/Qwen3.5-397B-A17B. The text configuration is also structurally aligned with Qwen3.5: qwen3_5_moe_text, 60 layers, 512 experts, 10 selected experts per token, 4096 hidden size, 32 attention heads, and 2 key-value heads. Rio README, Rio config, Qwen3.5-397B-A17B card
In plain English, it is not a dense 397B model that activates every parameter for every token. It is a Mixture-of-Experts model. In an MoE model, many expert subnetworks exist, but only a subset is routed for each token. That is why the model card can claim roughly 397B total parameters and roughly 17B active parameters. Total parameters shape storage and memory requirements; active parameters shape part of per-token compute cost. Both matter.

Technical Specs
| Spec | What the source says | Verification status |
|---|---|---|
| Repository | prefeitura-rio/Rio-3.5-Open-397B on Hugging Face |
Confirmed |
| Developer claim | IplanRIO / municipal IT company of Rio de Janeiro | Claimed by model card; IplanRIO role corroborated by official site |
| Base model | Qwen/Qwen3.5-397B-A17B |
Confirmed in README metadata and HF tags |
| Architecture | Qwen3_5MoeForConditionalGeneration; text config qwen3_5_moe_text |
Confirmed in config |
| Total parameters | Model card: about 397B; HF safetensors metadata: 403.397B tensor parameters | Confirmed with counting caveat |
| Active parameters | Model card/base model: about 17B active | Claimed by model card and Qwen base card |
| Text layers | 60 | Confirmed in config |
| Experts | 512 experts, 10 selected experts per token | Confirmed in config |
| Hidden size | 4096 | Confirmed in config |
| Attention heads | 32 query heads, 2 key-value heads | Confirmed in config |
| Context window | README claim: 1,010,000 tokens; config: max_position_embeddings 262,144; examples use 1,048,576 in vLLM/SGLang |
Mixed evidence; long-context serving likely requires overrides/scaling |
| Modalities | Hugging Face pipeline: image-text-to-text; config includes image/video token IDs and vision config | Plausible/confirmed at config level; needs independent task testing |
| Languages | README lists multilingual support and front matter lists pt, en |
Claimed; broad language quality not independently verified here |
| Precision | Safetensors metadata: BF16 parameters plus 8,640 F32 values | Confirmed by HF API |
| Weight footprint | Safetensors index total size: 806,795,875,168 bytes | Confirmed |
| Repository files | 97 .safetensors shards; 110 sibling files via HF API; no repo-local .py implementation files observed |
Confirmed at retrieval time |
| License | README front matter license: mit; HF tags license:mit; no separate LICENSE file observed in the sibling list I retrieved |
MIT-tagged, but package-level license artifacts should be audited before commercial use |
| Inference examples | Transformers, vLLM, and SGLang examples in README | Confirmed |
| Quantizations | Not part of the original repo files reviewed; Hugging Face model search shows derivative quantized listings may appear | Verify each derivative separately |
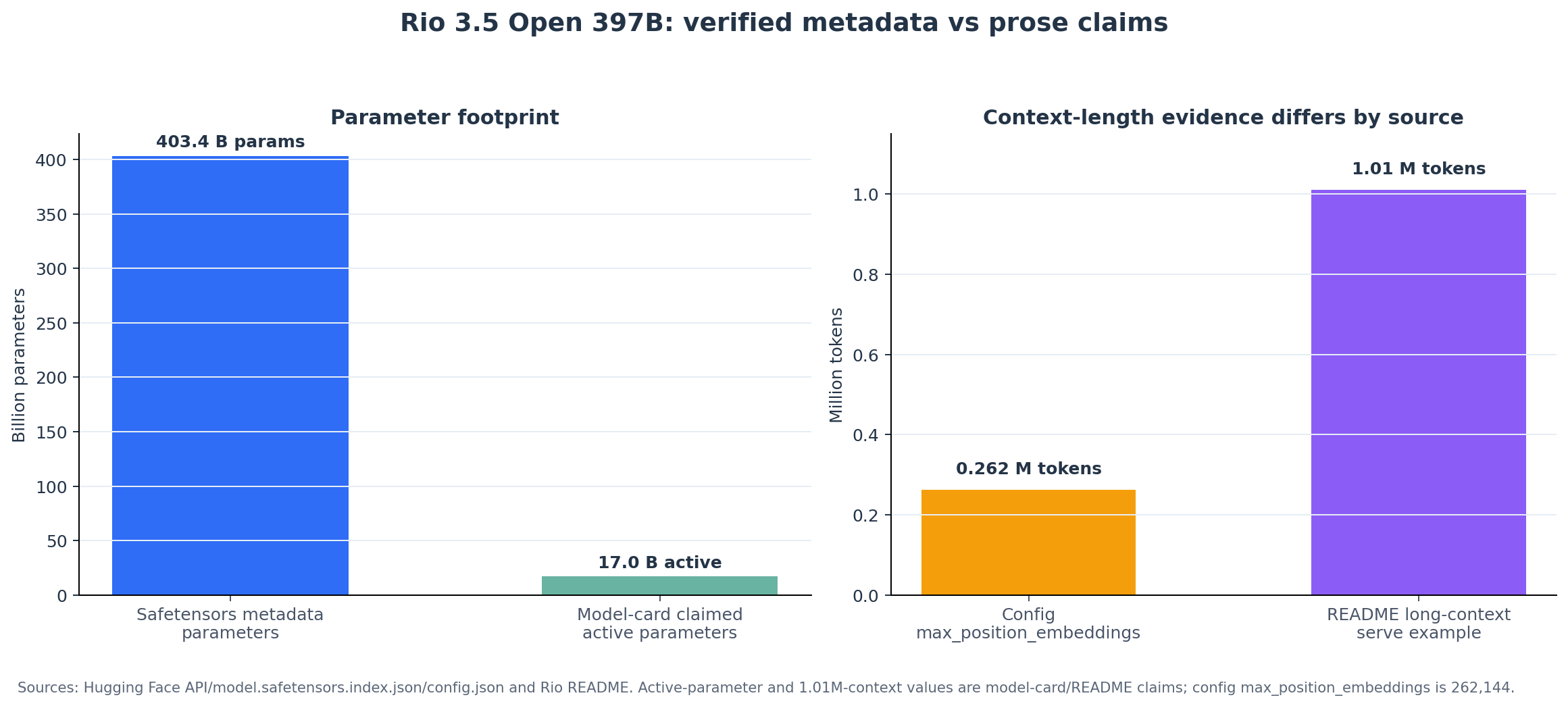
The context-window caveat deserves special attention. Rio’s README lists a 1,010,000-token context window and gives vLLM/SGLang examples using 1,048,576 tokens. But the actual config.json sets max_position_embeddings to 262,144. Qwen’s own Qwen3.5 card says Qwen3.5 “natively supports” up to 262,144 tokens and gives YaRN/RoPE-scaling instructions for reaching 1,010,000 tokens. That makes the safest interpretation: 262K is the native/configured context; roughly 1M is a long-context serving mode that likely depends on scaling overrides and memory budget. Rio README, Rio config, Qwen3.5 card long-context section

Benchmark Claims
The Rio model card includes a large benchmark table covering agentic coding, software engineering, reasoning, math, multilingual, multimodal, instruction following, agents, and an estimated economic-value benchmark. The repository also includes the following benchmark graphic.
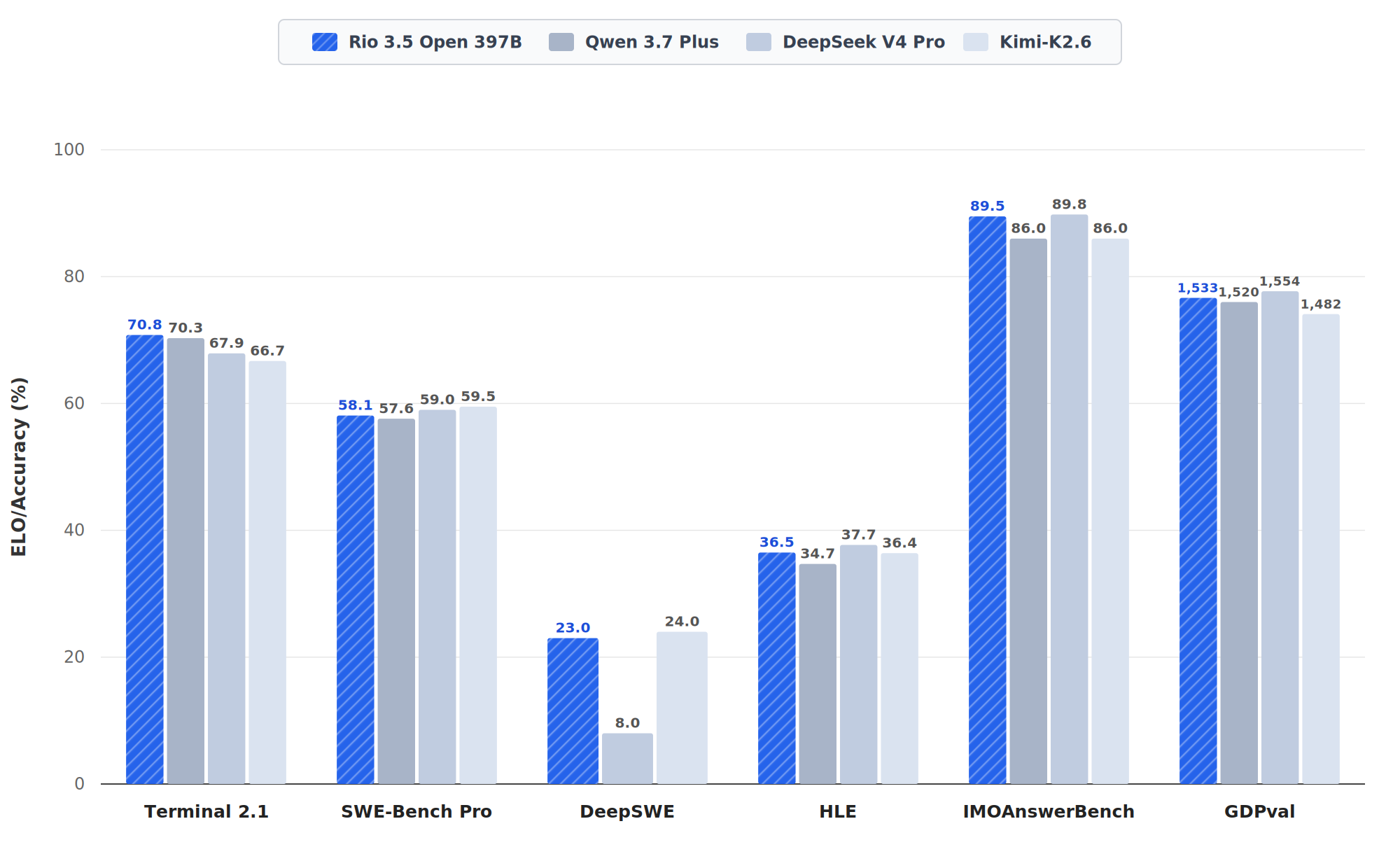
Here is the core issue: benchmark numbers are not all equal. A number can be independently reproduced, benchmark-host reported, vendor reported, model-card-only, or copied from a comparison table with unclear harness settings. Rio’s model-card numbers should currently be treated as first-party/model-card-only unless a benchmark host or third party publishes reproducible Rio runs.
| Category | Benchmark | Rio 3.5 Open 397B | Qwen3.5 base in Rio card | Source status |
|---|---|---|---|---|
| Agentic coding | Terminal-Bench 2.1 | 70.8 | 52.5 | Rio model card only |
| Agentic coding | DeepSWE | 23.0 | 6.0 | Rio model card only |
| Agentic coding | SWE-Bench Pro | 58.1 | 50.9 | Rio model card only |
| Agentic coding | SWE-Bench Verified | 80.2 | 76.2 | Rio model card only |
| Agentic coding | SWE-Bench Multilingual | 77.0 | 69.3 | Rio model card only |
| Knowledge/reasoning | GPQA Diamond | 90.9 | 88.4 | Rio model card only |
| Knowledge/reasoning | Humanity’s Last Exam | 36.5 | 28.7 | Rio model card only |
| Knowledge/reasoning | MMLU-Pro | 88.0 | 87.8 | Rio model card only |
| Knowledge/reasoning | MMLU-Redux | 94.6 | 94.9 | Rio model card only |
| Knowledge/reasoning | SuperGPQA | 72.3 | 70.4 | Rio model card only |
| Knowledge/reasoning | Apex | 29.2 | 9.4 | Rio model card only |
| Math | HMMT 2026 Feb | 93.9 | 87.9 | Rio model card only |
| Math | IMOAnswerBench | 89.5 | 80.9 | Rio model card only |
| Multilingual | MMMLU | 89.8 | 88.5 | Rio model card only |
| Multilingual | MMLU-ProX | 85.6 | 84.7 | Rio model card only |
| Multimodal | MMMU-Pro | 78.4 | 79.0 | Rio model card only |
| Multimodal | MathVision | 89.1 | 88.6 | Rio model card only |
| Multimodal | VideoMMMU | 81.6 | 84.7 | Rio model card only |
| Tool/instruction | MCP-Atlas | 74.2 | 74.2 | Rio model card only |
| Tool/instruction | IFBench | 78.4 | 76.5 | Rio model card only |
| Tool/instruction | IFEval | 93.4 | 92.6 | Rio model card only |
| Economic value | GDPval estimated | 1533 | 1200 | Rio model card only; methodology unclear from card |
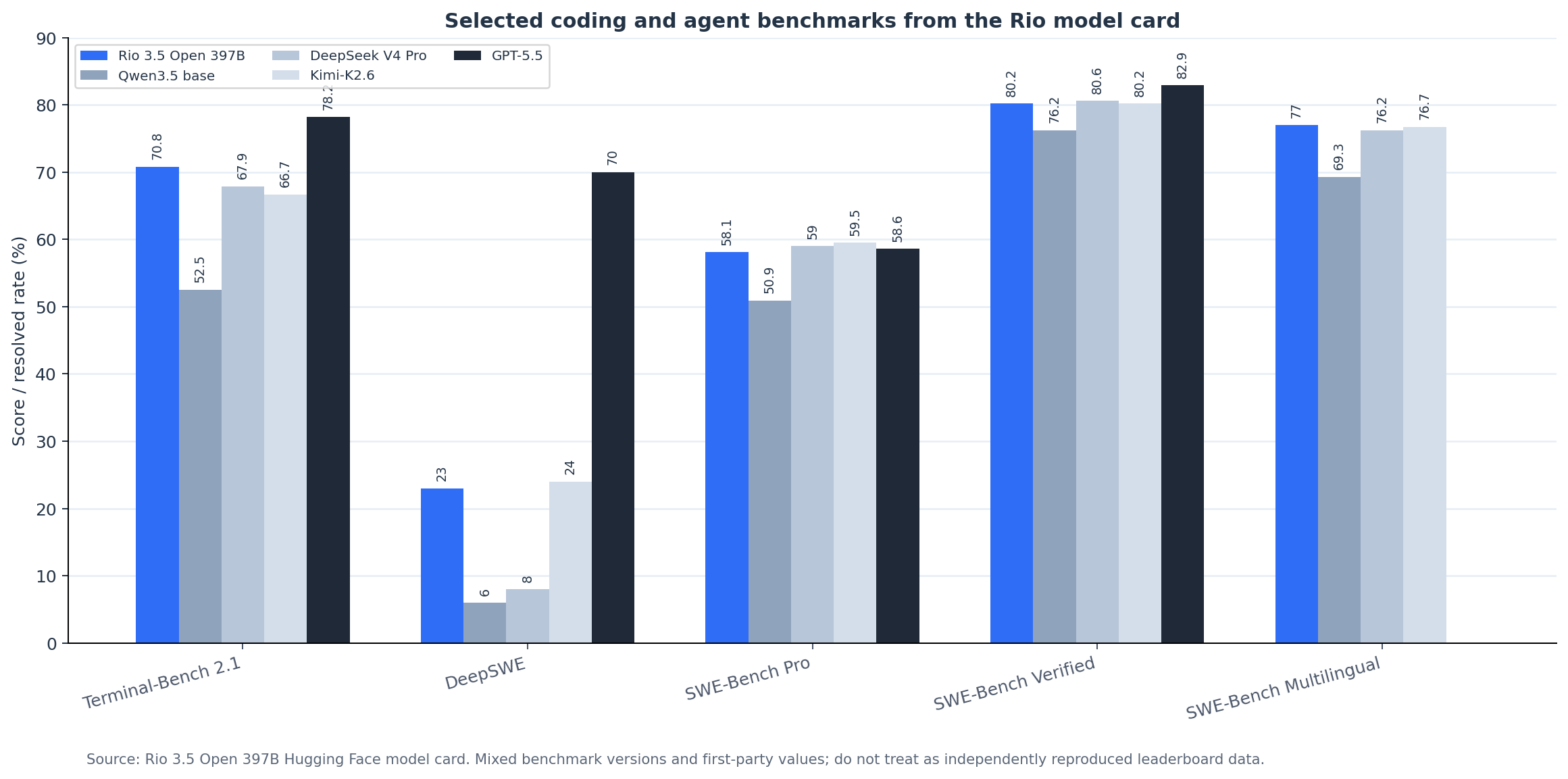
The benchmark families themselves are real. Terminal-Bench evaluates terminal agents in realistic command-line environments; SWE-Bench Verified is a human-validated subset of GitHub issue-resolution tasks; SWE-Bench Pro extends software-engineering evaluation to harder enterprise-style tasks; DeepSWE is a long-horizon software-engineering benchmark; and MCP-Atlas evaluates tool use across real MCP servers. Terminal-Bench, SWE-Bench Verified, SWE-Bench Pro, DeepSWE, MCP-Atlas
But a real benchmark is not the same thing as a verified score. A model-card table does not tell us whether the run used a standard scaffold, whether the same harness was used across models, whether tool access was comparable, whether contamination screens were run, whether the benchmark version was the same, or whether the reported comparison values came from benchmark hosts, vendors, or internal reruns.

Reported Gains Over Qwen3.5 Base
The Rio card’s most meaningful comparison is not Rio versus every frontier model. It is Rio versus its base model. Because the model claims to be post-trained from Qwen3.5-397B-A17B, the base-model delta is the natural place to look first.
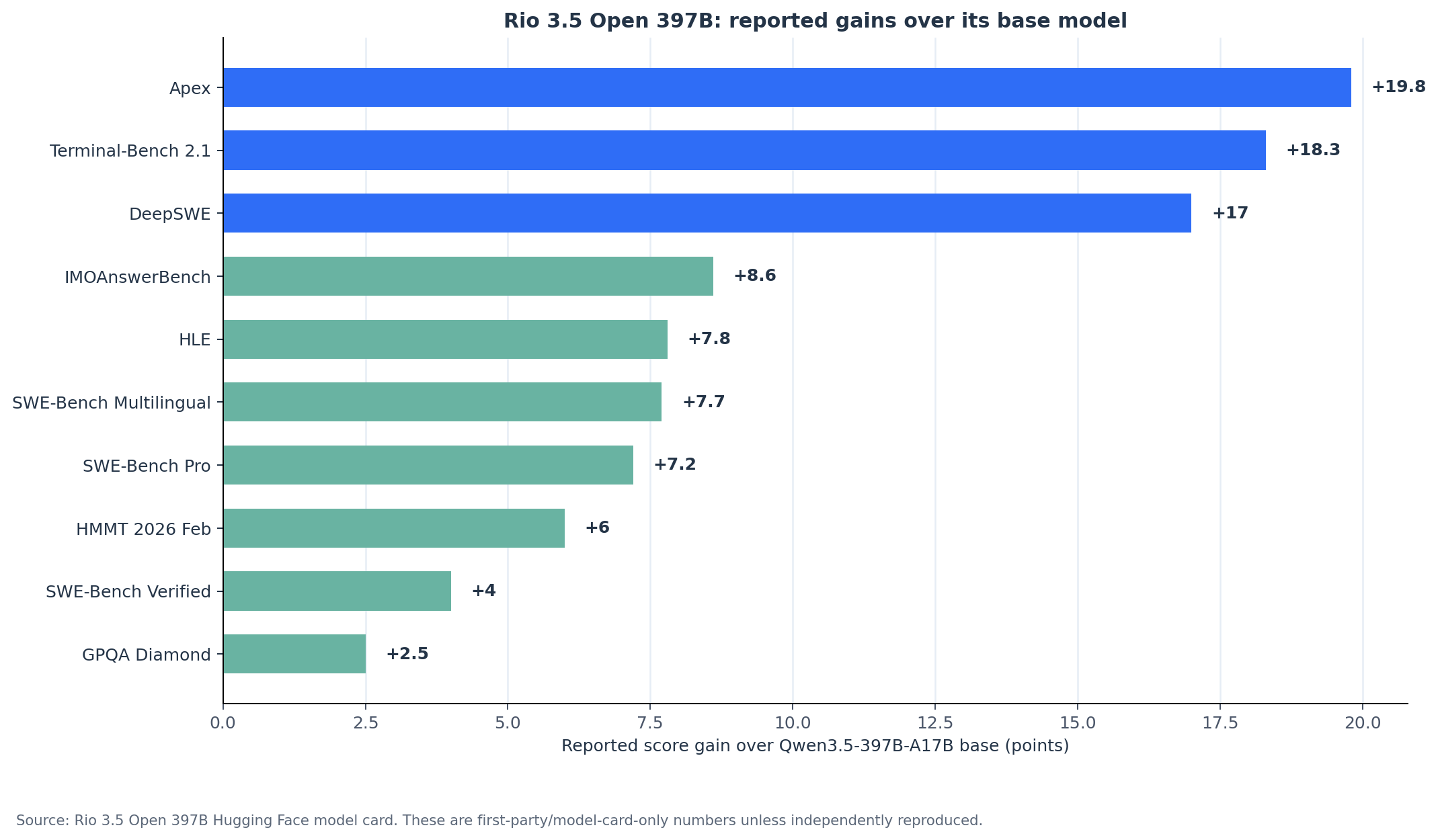
The reported gains are large in some places: +18.3 on Terminal-Bench 2.1, +17.0 on DeepSWE, +19.8 on Apex, +8.6 on IMOAnswerBench, +7.8 on HLE, and +7.7 on SWE-Bench Multilingual. If independently reproduced, that would be a meaningful post-training result. But the word “if” is doing real work.
One Hugging Face discussion adds useful color. A user asked whether the Rio benchmarks were run with SwiReasoning active and whether the model would still improve without latent reasoning. A reply from Sangu1nius answered “With!” and gave an ablation-style mini-table: Qwen base at 80.9 on IMOAnswerBench, 50.9 on SWE-Bench Pro, and 9.4 on Apex; “+ Training” at 84.5, 54.8, and 22.9; and “+ Latent Reasoning” at 89.5, 58.1, and 29.2. That suggests the published Rio headline numbers may depend materially on the latent-reasoning inference path. HF discussion #2
That is important because not every inference stack can implement soft/latent reasoning. The same discussion explicitly notes that engines limited to discrete token generation, such as llama.cpp, cannot currently implement that style of continuous soft-embedding reasoning. HF discussion #2
SwiReasoning: What It Is, And What Is Actually Released
Rio’s model card says the model “features SwiReasoning,” a training-free inference framework from Shi et al. that switches between explicit chain-of-thought reasoning and latent-space reasoning. The arXiv abstract for SwiReasoning describes exactly that: dynamic switching between explicit and latent reasoning guided by entropy trends in next-token distributions, plus a switch-count control mechanism to reduce overthinking. The paper reports average accuracy gains of 1.8%-3.1% and token-efficiency gains of 57%-79% under constrained budgets across mathematics, STEM, coding, and general benchmarks. SwiReasoning arXiv, SwiReasoning GitHub
The idea is straightforward, at least at a high level:
- Explicit reasoning emits intermediate natural-language reasoning tokens. It is inspectable, but token-expensive.
- Latent reasoning keeps some reasoning in continuous hidden space or soft-embedding form. It may be more token-efficient, but it is harder to inspect and harder to support in ordinary inference engines.
- Switching tries to use entropy/confidence signals to decide when to explore in latent space and when to commit in explicit text.

The catch: the Rio repository files I reviewed do not include repo-local Python code implementing SwiReasoning. The Hugging Face API file list includes model weights, configs, tokenizer files, chat_template.jinja, and preprocessors, but no .py files. The README examples show standard Transformers loading plus vLLM and SGLang serving commands. That does not disprove that the model was trained to work well with SwiReasoning, but it does mean the integration is not self-evident from the released repository alone. Rio API, Rio README
For readers who want a fuller primer on reasoning tokens and chain-of-thought tradeoffs, see Kingy AI’s explainer: Chain-of-thought explained.
How It Compares To Frontier Labs
Rio’s first-party numbers suggest a model that may be competitive with leading open-weight systems and within striking distance of some frontier API models on selected rows. But frontier comparison is where benchmark hygiene matters most.
OpenAI’s GPT-5.5 page, Anthropic’s Claude Opus 4.8 page, Google’s Gemini 3.1 Pro model page, and xAI’s Grok 4 materials all publish their own benchmark packages, often with different benchmark versions, scaffolds, tools, and inference settings. OpenAI’s GPT-5.5 page, for example, reports Terminal-Bench 2.0 and SWE-Bench Pro values, while Rio’s card lists Terminal-Bench 2.1. Those are not automatically comparable. OpenAI GPT-5.5, Anthropic Claude Opus 4.8, Google Gemini 3.1 Pro, xAI Grok 4
The real comparison looks like this:
| Dimension | Rio 3.5 Open 397B | Frontier lab models |
|---|---|---|
| Weights | Public Hugging Face weights | Usually closed, API-only |
| License/control | MIT-tagged on HF, but license package should be audited | API terms, no weights |
| Reproducibility | Weights are available; eval harness not published in repo | Evals usually vendor-reported; some third-party leaderboards exist |
| Deployment | Possible self-hosting, but ~807 GB BF16 footprint before KV cache and serving overhead | Hosted APIs hide infra complexity |
| Latency/cost | MoE active-parameter design helps, but full weights still need large distributed memory | API price/latency depends on vendor tier |
| Long context | 262K config; 1M serving claim likely via RoPE/YaRN-style scaling | Many frontier APIs advertise 1M-class contexts, but details vary |
| Multimodal | Config supports image/video tokens and vision tower | Frontier labs generally have mature multimodal products |
| Agentic ecosystem | README points to vLLM/SGLang/Transformers and Qwen Code | Closed labs have integrated agents, connectors, computer use, and managed tools |
Rio’s advantage is control. A user can download the weights, inspect the config, run local or private infrastructure, and fine-tune or adapt subject to license review and hardware budget. Frontier labs’ advantage is operational maturity: hosted reliability, safety/process documentation, product integrations, SDKs, tool ecosystems, and larger public testing footprints.
If you are building agents, that distinction matters. Agentic performance is not only “model IQ”; it is model plus tools, memory, sandboxing, retry logic, browser/terminal harness, context management, and eval discipline. Kingy has a broader implementation-oriented guide here: The state of AI agents in 2026, and an MCP-specific explainer here: What is Model Context Protocol?.
How It Compares To Heavyweight Open Models
Rio enters a crowded heavyweight open-weight field. The relevant peers are not only dense Llama-class models, but sparse MoE systems that try to combine huge total parameter counts with smaller active compute.
| Model | Public source | Parameters / active parameters | Context claim | Modality | License/open status |
|---|---|---|---|---|---|
| Rio 3.5 Open 397B | Hugging Face | Card: ~397B / ~17B active; HF metadata: 403.4B tensor params | Config 262K; README 1.01M / examples 1.048M | Image-text-to-text config | MIT-tagged HF repo; no separate LICENSE file observed in API sibling list |
| Qwen3.5-397B-A17B | Hugging Face/Qwen | 397B / 17B active | Native 262K; hosted Plus says 1M default; YaRN instructions to ~1.01M | Multimodal | Apache-2.0 tag |
| DeepSeek-V4-Pro | Hugging Face | 1.6T / 49B active | 1M | Text-focused MoE card; check repo for modality details | MIT |
| Kimi-K2.6 | Hugging Face/Moonshot | 1T / 32B active | 256K | Image-text-to-text; MoonViT vision encoder | Modified MIT |
| MiniMax-M3 | Hugging Face | ~428B / ~23B active | 1M | Native multimodal text/image/video | MiniMax community license |
| GLM-5 | Hugging Face/Z.ai | 744B / 40B active | Z.ai says long-context with DSA; HF snippet cites 744B/40B | Model family varies by endpoint/card | MIT according to Z.ai blog/HF card |
| Llama 4 Scout / Maverick | Meta | Scout: 17B active, 16 experts; Maverick: 17B active, 128 experts | Scout advertised up to 10M context | Natively multimodal | Open-weight Llama license |
Sources: Rio model card, Qwen3.5-397B-A17B, DeepSeek-V4-Pro, Kimi-K2.6, MiniMax-M3, GLM-5, Meta Llama 4
Against those peers, Rio’s positioning is narrower than the model-card headline might imply:
- Versus Qwen3.5, Rio is best understood as a post-training and inference-strategy claim on top of the same base family. The reported gains over base are the key thing to reproduce.
- Versus DeepSeek-V4-Pro, Rio is smaller in total and active parameters, and its license tag is attractive, but DeepSeek’s own V4 card claims a much larger 1.6T/49B MoE and 1M context.
- Versus Kimi-K2.6, Rio is smaller and appears less obviously agent-productized. Kimi has a stronger public narrative around long-horizon coding and agent orchestration; Rio’s SWE-Bench Pro result is slightly lower than Kimi’s value in Rio’s own comparison table.
- Versus MiniMax-M3, Rio is similar in total-parameter class but lower in claimed active parameters. MiniMax emphasizes native multimodality and sparse attention for 1M context.
- Versus GLM-5, Rio is smaller and less documented, but potentially easier to reason about as a Qwen-derived release if the Qwen ecosystem supports it.
- Versus Llama 4, Rio is in a different open-weight lineage: Qwen MoE rather than Meta’s Llama MoE family. Llama’s ecosystem maturity remains a major counterweight.
Kingy has covered some of these peer families in more detail here: DeepSeek V4 deep dive, Kimi K2.6 analysis, and AI model picker.
Deployment Realities
The “17B active” number can be misleading if read casually. It does not mean Rio is as easy to run as a 17B dense model. Sparse MoE still requires the full expert weights to be present somewhere in the serving system. For Rio, the safetensors index alone reports about 807 GB of model data. Add KV cache, allocator overhead, tensor parallelism, communication overhead, and long-context memory pressure, and this becomes a serious multi-GPU or hosted-inference project.
The README examples use --tensor-parallel-size 8 for vLLM and --tp 8 for SGLang. That does not prove eight GPUs are always sufficient, because GPU type, precision, quantization, context length, batch size, and KV-cache strategy dominate the practical answer. It does, however, signal that the authors expect distributed serving. Rio README
Quantized derivatives may make experimentation easier, and Hugging Face search already exposes derivative quantized listings tied to the Rio base-model metadata. But quantization is not magic. It can reduce memory footprint, but long-context KV cache, expert routing, throughput, and quality degradation still need testing. Hugging Face quantized model search
Claim Audit
| Claim | Rating | Why |
|---|---|---|
| The Hugging Face repo exists and contains large model weights | Confirmed | HF API lists the repo, 97 safetensor shards, and 806.8 GB index total size |
| It is based on Qwen3.5-397B-A17B | Confirmed | README front matter and HF tags list the Qwen base model |
| It uses a Qwen3.5 MoE architecture | Confirmed | Config lists Qwen3_5MoeForConditionalGeneration, 512 experts, 10 experts per token |
| It is roughly 397B total / 17B active | Plausible/mostly confirmed | Model card and Qwen base card say this; HF safetensors metadata counts 403.4B tensor parameters |
| It has a 1,010,000-token context window | Plausible but needs caveat | README claims it; config says 262,144 max positions; Qwen base docs describe 1.01M via RoPE/YaRN scaling |
| It is multimodal | Plausible/config-confirmed | HF pipeline is image-text-to-text and config has vision/video fields; independent multimodal evals not found |
| It is MIT licensed | Partially confirmed | README metadata and HF tags say MIT; no separate LICENSE file observed in retrieved sibling list |
| It includes SwiReasoning | Unclear | Card claims it and a discussion reply says benchmark numbers used it; repo has no local implementation files |
| It beats or matches leading open models | Unverified | Rio-specific scores are currently model-card-only in sources reviewed |
| It competes with frontier labs | Provisional | It may on selected first-party rows, but frontier comparisons mix benchmark versions, tool settings, and vendor-reported values |
| GDPval estimate of 1533 | Weak / unclear | Model card gives the value but not enough methodology to treat it as a reproducible public score |
Bottom Line
Rio 3.5 Open 397B is worth taking seriously because the weights and config are real, the base model is clear, the parameter footprint is large, and the release comes from an unusual institutional source. If the reported post-training and SwiReasoning gains reproduce, it could be an important open-weight model for coding agents, multilingual work, and high-control deployments.
But the responsible headline is not “municipal model beats frontier labs.” The responsible headline is: a Rio-associated team has released a large Qwen3.5-derived open-weight MoE with bold benchmark claims that now need independent reproduction.
For builders, the next steps are obvious:
- Run a small, auditable subset of SWE-Bench Pro, SWE-Bench Verified, Terminal-Bench 2.1, and DeepSWE with a published harness.
- Test Rio with and without SwiReasoning, because the discussion-thread ablation implies latent reasoning may account for a meaningful share of the gains.
- Verify long-context behavior at 262K, 524K, and ~1M with retrieval, reasoning, and degradation tests.
- Audit the license package before commercial deployment.
- Benchmark against Qwen3.5-397B-A17B under identical serving conditions.
Until then, Rio 3.5 Open 397B should sit in the promising-but-unproven bucket: a real open-weight release, a fascinating governance story, and a benchmark table that deserves a hard, careful second pass.
Source List
Primary Rio sources
- Rio 3.5 Open 397B Hugging Face model card
- Rio README
- Rio raw config.json
- Rio safetensors index
- Rio Hugging Face API metadata
- Rio benchmark image in repo
- Rio discussion #2 on SwiReasoning
- IplanRIO official site
{kind=link}
Base model and open-weight peers
- Qwen3.5-397B-A17B
- DeepSeek-V4-Pro
- Kimi-K2.6
- Kimi K2.6 technical blog
- MiniMax-M3
- GLM-5
- Z.ai GLM-5 blog
- Meta Llama 4 announcement
Frontier-lab context
Benchmark and reasoning sources
- Terminal-Bench
- Terminal-Bench 2.1
- SWE-Bench Verified dataset
- SWE-Bench Pro dataset
- DeepSWE
- MCP-Atlas leaderboard
- MCP-Atlas paper
- SwiReasoning paper
- SwiReasoning code
Internal Kingy AI links used
Kingy Launch Brief
Put the week’s verified AI launches in your inbox.
One source-checked edition every Friday, with a clear try, watch or skip verdict. After subscribing, check your inbox and confirm your address.
Free · Fridays · Double opt-in · Unsubscribe anytime