
This is Anthropic’s first broad release of what it calls a Mythos-class model: a new tier above the Opus family, built for long-horizon coding, difficult knowledge work, deep research, advanced vision, tool use, and agentic workflows that can stretch far beyond a single chat response.
The launch is also unusual because Anthropic did not release one model in one form. It released the same underlying model in two access patterns:
Claude Fable 5: the broadly available version for general users, developers, and enterprise customers.
Claude Mythos 5: the more powerful unrestricted version for a smaller group of vetted cybersecurity, infrastructure, and research partners.
The difference is not the base intelligence. According to Anthropic, Fable 5 and Mythos 5 are based on the same underlying model. The difference is safeguards. Fable 5 includes automatic routing and blocking around certain high-risk cybersecurity, biology, chemistry, and model-distillation requests. Mythos 5 removes some of those restrictions for trusted partners working in controlled programs.

That matters because the model is not just better at writing answers. Anthropic is positioning it as a model that can work for much longer, reason across more context, handle more complicated coding projects, interpret visual documents and diagrams, and perform advanced research tasks that previously required expert humans or specialized systems.
The short version: Claude Fable 5 is the general-release version of Anthropic’s most capable model class. Claude Mythos 5 is the restricted-access version for high-trust work in areas where the same capabilities could be misused.
Official announcement: Anthropic — Claude Fable 5 and Claude Mythos 5
What Anthropic Released Today
Anthropic describes Claude Fable 5 as a model whose capabilities “exceed those of any model we’ve previously made generally available.” The company says it reaches state-of-the-art performance on nearly all tested benchmarks, with particular strength in:
- software engineering
- long-running agentic coding
- knowledge work
- scientific research
- vision
- chart and table interpretation
- document reasoning
- tool use
- computer use
- legal and financial workflows
That is the general release.
Then there is Claude Mythos 5, which Anthropic describes as the same underlying model with safeguards lifted in some areas. It is currently restricted to a smaller group of partners, including organizations in Project Glasswing, Anthropic’s cybersecurity initiative.
Anthropic says Mythos 5 has the strongest cybersecurity capabilities of any model in the world, but that is also exactly why the company is limiting access. These are dual-use capabilities. The same model that can help defenders find and patch vulnerabilities could also help attackers discover, exploit, or automate parts of offensive workflows.
That is the core tension of this release.
Anthropic wants to give the public access to a much more capable model, but it does not want to broadly release unrestricted cyber and bio capabilities. So it created Fable 5 as the public-facing version and Mythos 5 as the trusted-access version.
Why the Names Matter: Fable vs. Mythos
Anthropic’s naming is important here.
Mythos appears to be Anthropic’s new label for its highest model class. The company says Mythos-class models sit above Opus-class models. Mythos Preview was previously used inside Project Glasswing, where a limited group of organizations used it to find and patch high-severity software vulnerabilities.
Now Anthropic has released a new version of that model family:
Mythos 5 for trusted users.
Fable 5 for general availability.
Fable is not “small Mythos.” It is not described as a cheaper or weaker derivative. It is the same underlying model with a different safety layer.
That means most normal users should think of Fable 5 as the practical model to test. Mythos 5 is not something most people can simply turn on in the model picker or call from an API key today.
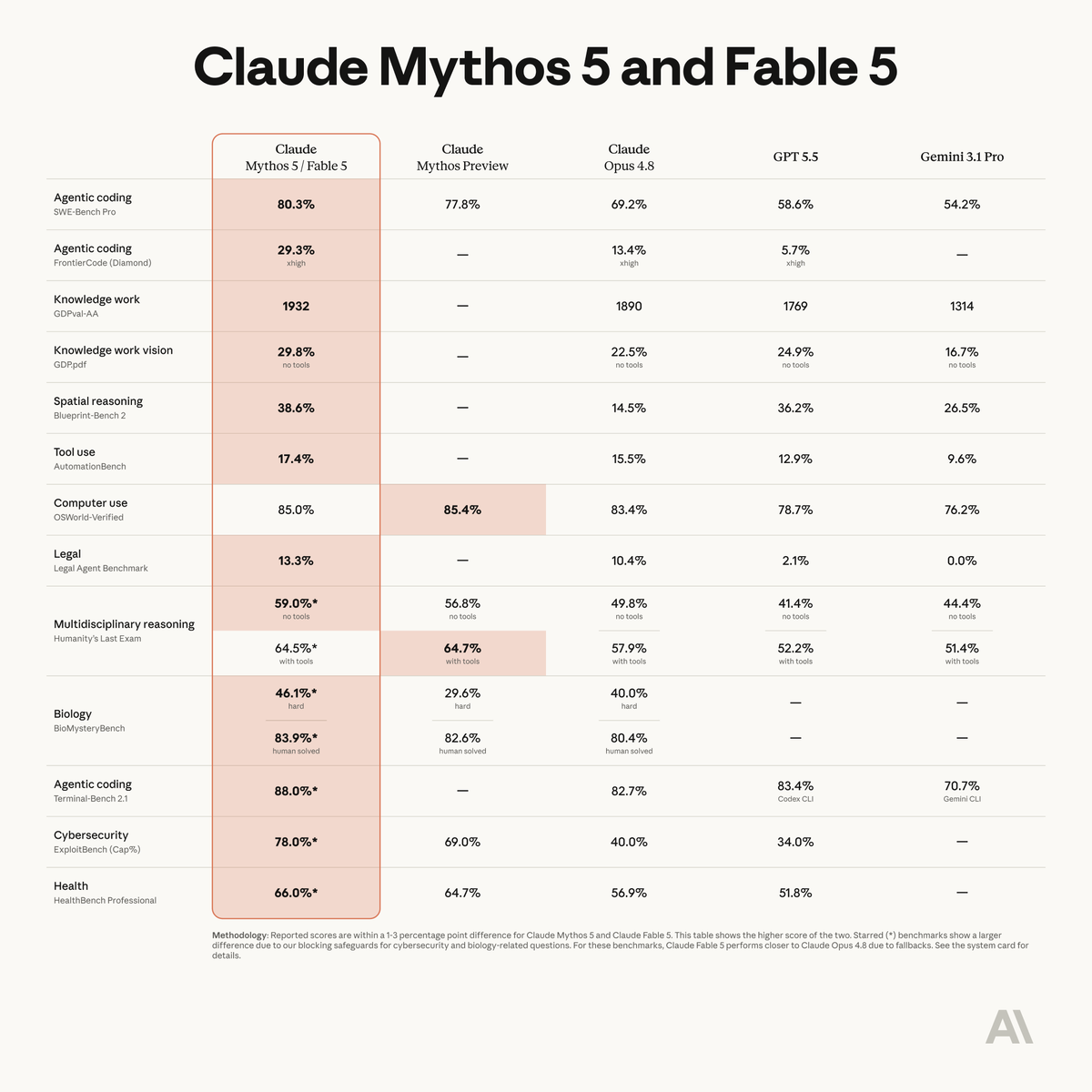
The Big Benchmark Picture
Anthropic published a benchmark table comparing Claude Mythos 5 / Claude Fable 5 against:
- Claude Mythos Preview
- Claude Opus 4.8
- GPT-5.5
- Gemini 3.1 Pro
The important caveat: Anthropic says the table shows the higher score between Fable 5 and Mythos 5. It also says that Fable 5 and Mythos 5 are usually within 1–3 percentage points of each other, but some starred cybersecurity and biology benchmarks show larger differences because Fable 5 falls back to Claude Opus 4.8 for some risky requests.
That means you should not read every Mythos benchmark as “what every public Fable user will get in every situation.” For normal coding, knowledge work, vision, legal, document, and productivity use cases, Fable 5 should be much closer to Mythos 5. For cyber and bio tasks, safeguards may change the effective behavior.
Here are some of the key benchmark results Anthropic published.
- Benchmark Claude Fable 5 / Mythos 5 Claude Opus 4.8 GPT-5.5 Gemini 3.1 Pro
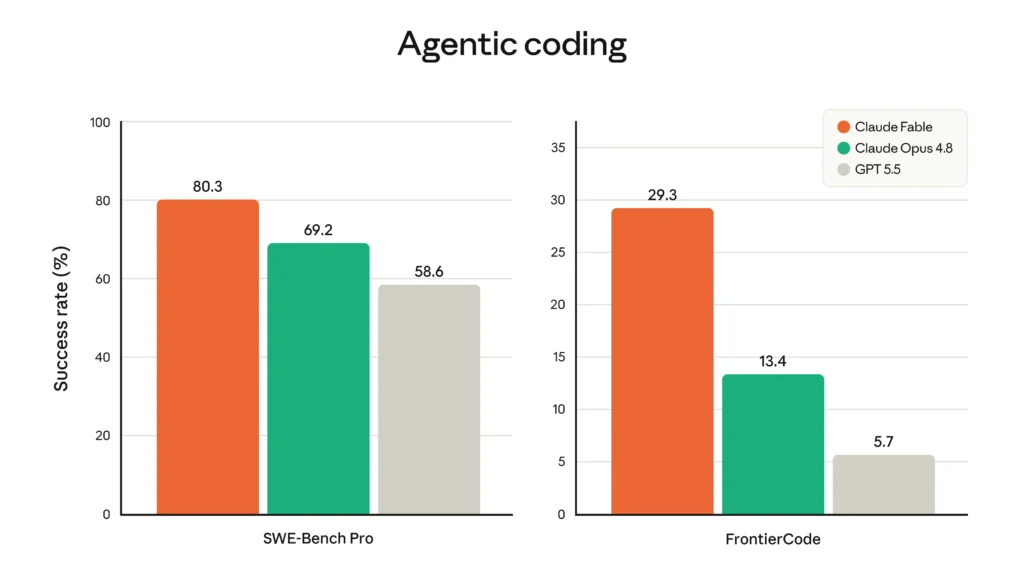
- SWE-Bench Pro 80.3% 69.2% 58.6% 54.2%
- FrontierCode Diamond 29.3% 13.4% 5.7% Not listed
- GDPval-AA 1932 1890 1769 1314
- GDP.pdf 29.8% 22.5% 24.9% 16.7%
- Blueprint-Bench 2 38.6% 14.5% 36.2% 26.5%
- AutomationBench 17.4% 15.5% 12.9% 9.6%
- OSWorld-Verified 85.0% 83.4% 78.7% 76.2%
- Legal Agent Benchmark 13.3% 10.4% 2.1% 0.0%
- Humanity’s Last Exam, no tools 59.0% 49.8% 41.4% 44.4%
- Humanity’s Last Exam, with tools 64.5% 57.9% 52.2% 51.4%
- Terminal-Bench 2.1 88.0% 82.7% 83.4% 70.7%
- ExploitBench Cap% 78.0% 40.0% 34.0% Not listed
- HealthBench Professional 66.0% 56.9% 51.8% Not listed
Source: Anthropic’s official launch post
The headline is clear: in Anthropic’s published benchmark table, Fable 5 / Mythos 5 leads GPT-5.5 on most of the shared benchmarks listed.
But benchmark comparisons need caution. Model companies choose benchmark configurations, tool settings, agent harnesses, effort levels, and evaluation methods. A model that wins a benchmark may not win every real-world task. The right way to read these numbers is not “Claude always beats GPT-5.5.” The better interpretation is:
Claude Fable 5 looks like a very serious frontier model, especially for long-horizon coding, agentic workflows, document-heavy knowledge work, vision-heavy reasoning, and complex professional tasks.
Coding: The Most Obvious Strength
If there is one area where Fable 5 looks immediately important, it is software engineering.
Anthropic says Fable 5 is designed for “ambitious long-running projects.” That language matters. A lot of AI coding tools are good at small tasks:
- write a function
- fix a bug
- explain an error
- generate a component
- refactor a file
- create a script
Fable 5 is being positioned for a harder category:
- large migrations
- complex implementations
- multi-day coding sessions
- test-writing
- debugging across big repositories
- visual QA of front-end outputs
- agentic coding inside tools like Claude Code
Anthropic says Stripe tested Fable 5 on a huge internal migration involving a 50-million-line Ruby codebase. According to the launch post, Fable compressed work that took a team more than two months by hand into a day. That is a company-provided example, not a public independent benchmark, but it gives a clear picture of the type of workload Anthropic is targeting.
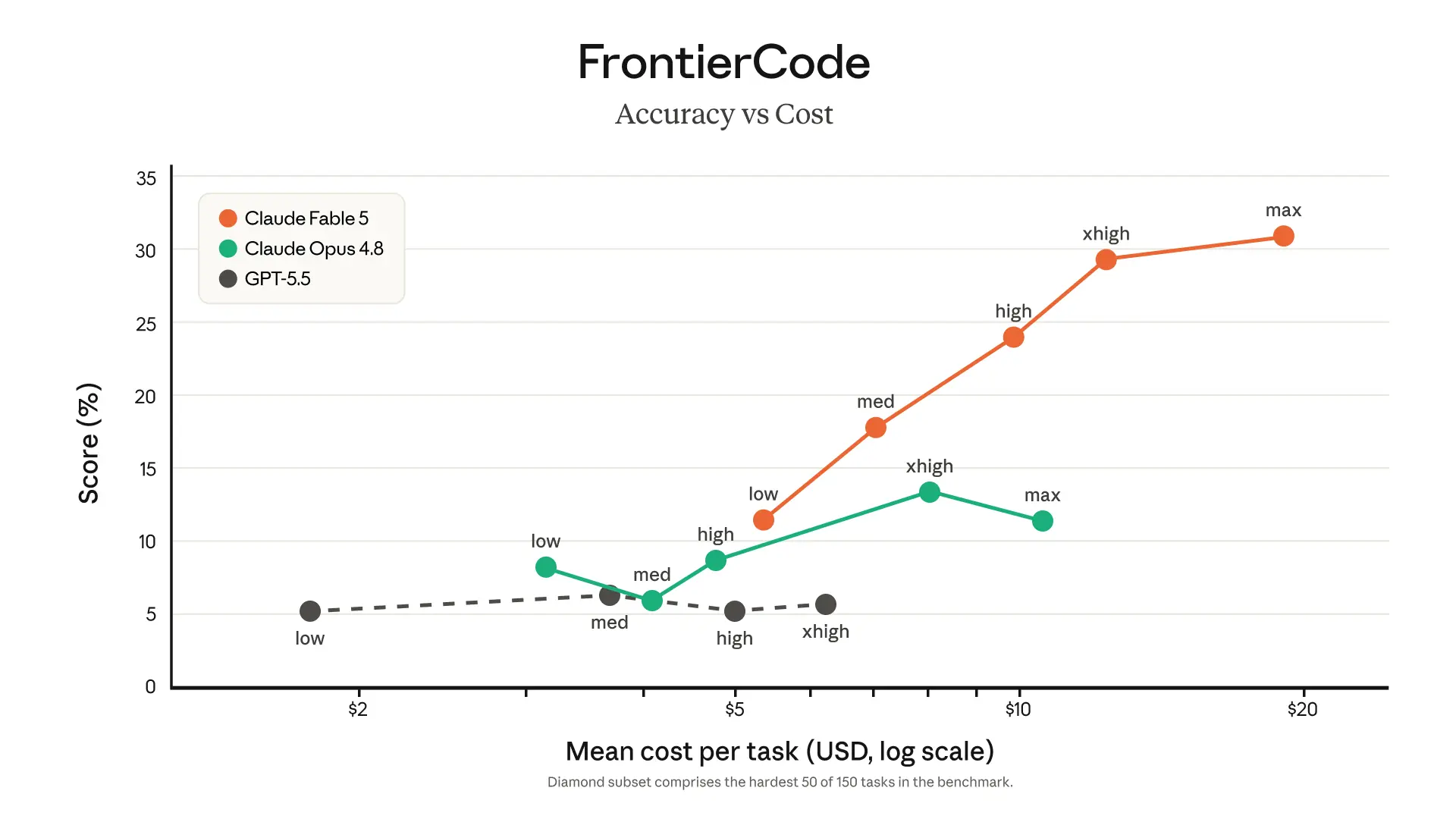
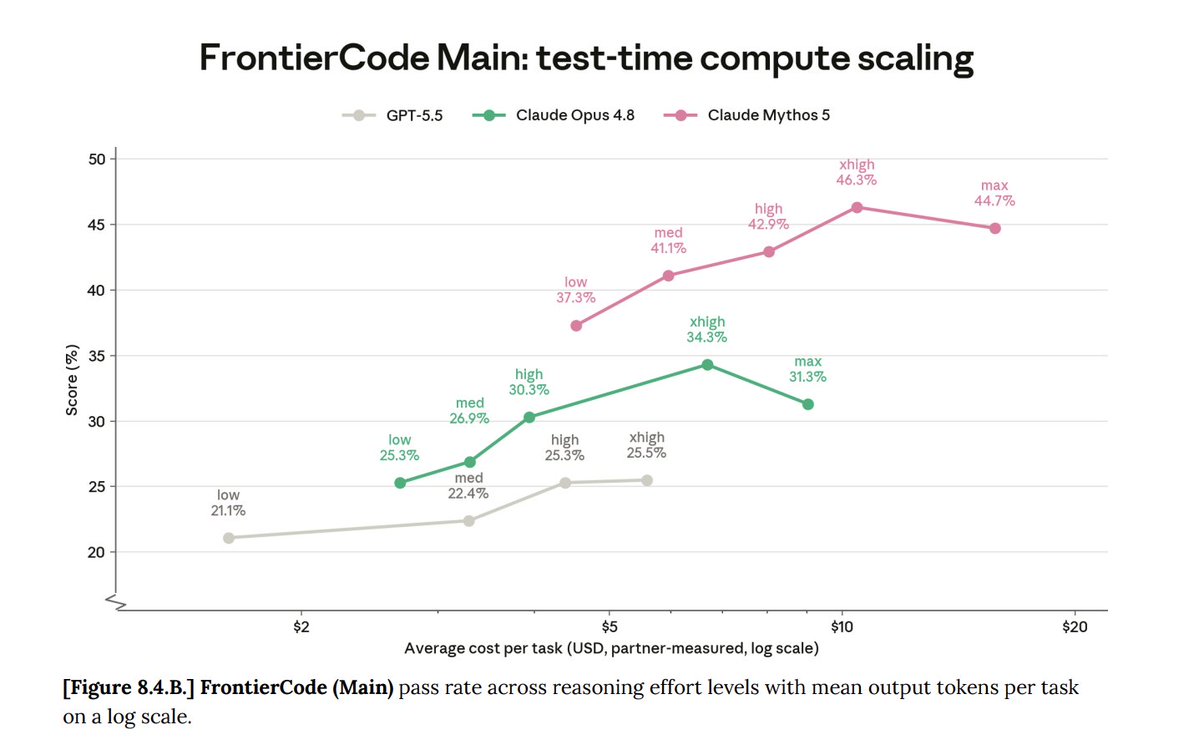
The benchmark table supports the same direction:
SWE-Bench Pro: Fable/Mythos 5 scored 80.3%, compared with 69.2% for Claude Opus 4.8 and 58.6% for GPT-5.5.
FrontierCode Diamond: Fable/Mythos 5 scored 29.3%, compared with 13.4% for Opus 4.8 and 5.7% for GPT-5.5.
Terminal-Bench 2.1: Fable/Mythos 5 scored 88.0%, compared with 82.7% for Opus 4.8 and 83.4% for GPT-5.5 using Codex CLI.
That does not mean you should fire your developers. It means the frontier of AI coding has moved again.
For people using Claude Code, Codex, Cursor, Windsurf, or other agentic development tools, Fable 5 should be tested on the tasks that previous models struggled with:
“Make this change across the whole repo.”
“Find why this backend endpoint fails.”
“Update the UI and verify it visually.”
“Add tests before modifying the behavior.”
“Refactor this legacy code without breaking existing behavior.”
“Read the project, plan the implementation, execute it, then review your own work.”
Those are the prompts where better models matter most.
Knowledge Work, Finance, Legal, and Documents
The second big category is professional knowledge work.
Anthropic claims Fable 5 is exceptional at document reasoning, chart interpretation, table understanding, and complex analysis. That matters because a lot of business work is not simple chat. It is messy, multi-step, and document-heavy.
Think of tasks like:
- analyzing a long contract
- comparing redlines
- reviewing financial tables
- extracting details from PDFs
- building a memo from multiple sources
- reading charts inside a report
- finding inconsistencies across documents
- turning research into a decision brief
In Anthropic’s table, Fable/Mythos 5 leads GPT-5.5 on GDPval-AA and GDP.pdf, two benchmarks related to professional work and document reasoning. It also leads on Anthropic’s listed Legal Agent Benchmark, with 13.3% compared with 10.4% for Opus 4.8 and 2.1% for GPT-5.5.
That legal score still looks low in absolute terms. This is important. A 13.3% score does not mean “AI can replace lawyers.” It means the benchmark is hard, and Fable 5 did materially better than the other listed models in Anthropic’s run.
For real-world legal, finance, and compliance use, the better framing is:
Fable 5 may be a stronger assistant for drafting, comparison, extraction, and first-pass analysis, but human review remains mandatory.
That is especially true in regulated or high-stakes work.
Vision and Spatial Reasoning
Fable 5 also appears meaningfully stronger in vision-heavy tasks.
Anthropic says the model can work with diagrams, charts, tables, files, PDFs, and screenshots. It also says Fable 5 can use vision to evaluate coding outputs, which is increasingly important for front-end development.
That means a workflow might look like this:
- Give Fable 5 a screenshot of the current UI.
- Give it a screenshot or design reference of the target UI.
- Ask it to identify differences.
- Ask it to modify the app.
- Ask it to re-check the output visually.
This is one of the most important areas for AI coding because a model that can write code but cannot see the result is operating half-blind. If Fable 5 is materially better at visual reasoning, it could be better at front-end work, dashboard generation, document interpretation, and design implementation.
On Blueprint-Bench 2, Anthropic reports Fable/Mythos 5 at 38.6%, compared with 36.2% for GPT-5.5, 26.5% for Gemini 3.1 Pro, and 14.5% for Claude Opus 4.8.
On GDP.pdf, Fable/Mythos 5 scored 29.8%, compared with 24.9% for GPT-5.5, 22.5% for Opus 4.8, and 16.7% for Gemini 3.1 Pro.
Again, the right takeaway is not that every vision task is solved. The takeaway is that Anthropic is clearly pushing Claude further into multimodal professional work, not just text chat.
Claude Fable 5 vs GPT-5.5
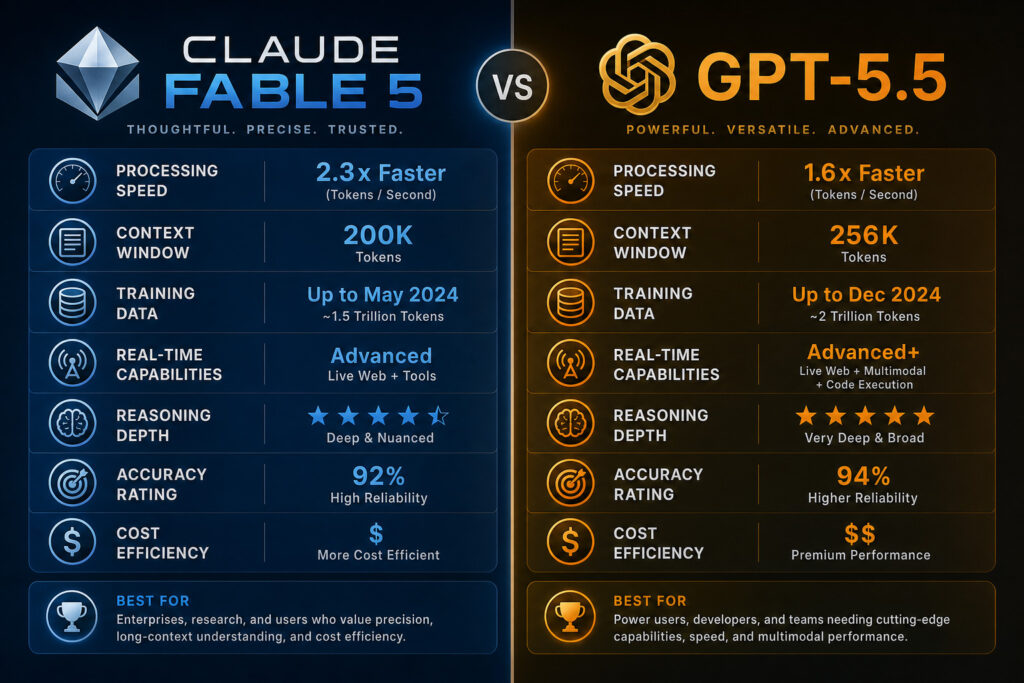
The most obvious comparison is Claude Fable 5 vs GPT-5.5.
OpenAI released GPT-5.5 as a highly capable model for coding, research, data analysis, spreadsheets, tool use, software operation, and complex multi-step work. OpenAI’s official documentation lists GPT-5.5 with a 1,050,000-token context window, 128,000 max output tokens, and API pricing of $5 per million input tokens and $30 per million output tokens. GPT-5.5 Pro is much more expensive at $30 per million input tokens and $180 per million output tokens.
Official GPT-5.5 page: Introducing GPT-5.5
OpenAI model comparison: OpenAI API model comparison
Claude Fable 5 is more expensive than standard GPT-5.5 on list API pricing:
Model Input price Output price
- Claude Fable 5 $10 / million tokens $50 / million tokens
- Claude Mythos 5 $10 / million tokens $50 / million tokens
- GPT-5.5 $5 / million tokens $30 / million tokens
- GPT-5.5 Pro $30 / million tokens $180 / million tokens
So the pricing comparison is mixed.
Standard GPT-5.5 is cheaper than Fable 5.
GPT-5.5 Pro is more expensive than Fable 5.
From a benchmark perspective, Anthropic’s published table shows Fable/Mythos 5 ahead of GPT-5.5 on many listed shared tests, including SWE-Bench Pro, FrontierCode, GDPval-AA, GDP.pdf, AutomationBench, OSWorld-Verified, Legal Agent Benchmark, Humanity’s Last Exam, Terminal-Bench 2.1, ExploitBench, and HealthBench Professional.
From a product perspective, GPT-5.5 has a very clear public API specification around context and max output. Anthropic’s Fable page confirms the model is built for long-running work and says it can stay focused across millions of tokens in long-running tasks, but the official Fable pages I verified do not publish the same clean model-spec table with parameter count, exact public context window, max output, or architecture details.
That is an important distinction.
If you are choosing between Fable 5 and GPT-5.5, the practical test is workload-based:
Use Fable 5 when you need:
- the strongest Claude model available to general users
- long-horizon coding
- large repo work
- agentic development in Claude Code
- difficult document reasoning
- vision-heavy analysis
- legal/finance/professional workflows
- careful self-checking and multi-step deliverables
Use GPT-5.5 when you need:
- lower standard API pricing
- very large published context and output limits
- strong general coding and research
- OpenAI ecosystem integration
- Codex workflows
- lower-cost frontier model access compared with Fable
Use GPT-5.5 Pro when you need OpenAI’s higher-end reasoning mode and the task justifies the much higher cost.
Claude Fable 5 vs Claude Opus 4.8
For Claude users, the more practical comparison may be Fable 5 vs Opus 4.8.
Opus has been Anthropic’s premium model family for hard reasoning, writing, and coding. Fable 5 is positioned above it.
Anthropic’s benchmark table shows Fable/Mythos 5 ahead of Opus 4.8 on most listed benchmarks:
- SWE-Bench Pro: 80.3% vs 69.2%
- FrontierCode Diamond: 29.3% vs 13.4%
- GDPval-AA: 1932 vs 1890
- GDP.pdf: 29.8% vs 22.5%
- Blueprint-Bench 2: 38.6% vs 14.5%
- AutomationBench: 17.4% vs 15.5%
- Legal Agent Benchmark: 13.3% vs 10.4%
- Humanity’s Last Exam, no tools: 59.0% vs 49.8%
- Terminal-Bench 2.1: 88.0% vs 82.7%
- HealthBench Professional: 66.0% vs 56.9%
But Opus 4.8 still matters because Fable 5 sometimes falls back to Opus 4.8 on restricted topics. If a conversation triggers Fable’s cyber, bio, chemistry, or distillation safeguards, the user may receive an Opus 4.8 response instead.
That means Fable 5 is not a complete replacement for Opus in every workflow. It is the stronger general model, but the effective model you get may depend on the topic and safeguard routing.
Claude Fable 5 vs Gemini 3.1 Pro
Google’s Gemini 3.1 Pro Preview is another important comparison.
According to Google’s official Gemini API documentation, Gemini 3.1 Pro Preview supports text, image, video, audio, and PDF input, with text output. Google lists a 1,048,576-token input limit and 65,536-token output limit for the model. Its standard pricing is lower than Fable 5 for many use cases: $2 per million input tokens and $12 per million output tokens up to 200,000 input tokens, and $4 input / $18 output above 200,000 tokens.
Gemini 3.1 Pro Preview docs: Gemini API model docs
Gemini API pricing: Gemini API pricing
Gemini’s strengths are clear:
- lower listed API pricing
- huge context window
- multimodal input support
- Google ecosystem integration
- grounding and tool options
- strong general-purpose capabilities
But in Anthropic’s published benchmark table, Fable/Mythos 5 leads Gemini 3.1 Pro on the shared benchmarks shown:
- SWE-Bench Pro: 80.3% vs 54.2%
- GDPval-AA: 1932 vs 1314
- GDP.pdf: 29.8% vs 16.7%
- Blueprint-Bench 2: 38.6% vs 26.5%
- AutomationBench: 17.4% vs 9.6%
- OSWorld-Verified: 85.0% vs 76.2%
- Legal Agent Benchmark: 13.3% vs 0.0%
- Humanity’s Last Exam, no tools: 59.0% vs 44.4%
- Humanity’s Last Exam, with tools: 64.5% vs 51.4%
- Terminal-Bench 2.1: 88.0% vs 70.7%
So the Fable vs Gemini decision is likely cost-performance.
If you need lower-cost long-context multimodal processing, Gemini 3.1 Pro may be attractive. If you need the strongest performance on the types of coding, reasoning, legal, and agentic tasks Anthropic benchmarked, Fable 5 is the model to test.
Pricing and Access
Claude Fable 5 and Claude Mythos 5 are priced at:
$10 per million input tokens
$50 per million output tokens
Anthropic also says Fable 5 supports a 90% input token discount for prompt caching, and that US-only inference is available at 1.1x pricing.
For developers, the model name is:
claude-fable-5
A minimal Claude API-style request would look like this:
curl https://api.anthropic.com/v1/messages \
-H “x-api-key: $ANTHROPIC_API_KEY” \
-H “anthropic-version: 2023-06-01” \
-H “content-type: application/json” \
-d ‘{
“model”: “claude-fable-5”,
“max_tokens”: 4096,
“messages”: [
{
“role”: “user”,
“content”: “Analyze this repository and propose a safe migration plan.”
}
]
}’
Fable 5 is available through:
- Claude API
- consumption-based Enterprise plans
- Claude Platform
- Anthropic-supported marketplaces
- AWS
- Google Cloud
- Microsoft Foundry
For subscription users, Anthropic says Fable 5 is available at no extra cost on Pro, Max, Team, and seat-based Enterprise plans from launch through June 22. On June 23, Anthropic says it will remove Fable 5 from those included plans, after which it will require usage credits. Anthropic says it may extend availability depending on capacity and hopes to eventually restore Fable as a standard part of paid Claude plans.
Mythos 5 is different. It is not broadly available. It is initially restricted to:
Project Glasswing partners
select biology researchers
trusted access programs
Anthropic says it plans broader trusted access over time, but there is no public “turn on Mythos 5” button for normal users today.
Safeguards: Why Fable 5 May Switch Models
The most unusual part of Fable 5 is the safeguard system.
Anthropic says Fable 5 includes classifiers for:
cybersecurity
biology
chemistry
model distillation
When a request is flagged, Fable 5 may not answer it directly. Instead, Anthropic says the request may be automatically handled by Claude Opus 4.8. Users are informed when that happens.
Anthropic’s support page says these safety checks review not just the latest prompt, but also other material the model reads, including memory, connectors, web content, and files. That means a conversation could trigger fallback because of context loaded into the session, not just because of the last sentence you typed.
Support page: Why Claude switched models in your conversation with Fable 5
Anthropic says automatic switching is enabled by default in:
- Claude web
- Claude mobile
- Claude desktop
- Claude Cowork
- Claude Code
- Claude Design
- Claude for Microsoft 365
- Claude for Teams
- Claude for Slack
API customers have to configure fallback behavior differently. Anthropic’s support documentation says API switching is not simply the same as the consumer app behavior.
For billing, Anthropic says if a request is blocked before Fable runs, the user is charged only for the Opus 4.8 request. If Fable starts generating and is blocked midstream, tokens generated before the block are billed at Fable rates, and the rest is billed at Opus 4.8 rates.
Anthropic also says more than 95% of sessions do not trigger fallback. In those sessions, users should effectively experience Mythos-class performance through Fable 5.
That is the tradeoff: Fable 5 gives broad access to the new model class, but not unrestricted access to every capability.
Data Retention: The 30-Day Rule
There is another important policy detail: Anthropic says prompts and outputs for Mythos-class models are retained for 30 days for trust and safety purposes.
Support page: Data retention practices for Mythos-class models
Anthropic says this applies across the platforms where Mythos-class models are offered. It also says the data is not used to train new Claude models or for non-safety purposes. Human access is limited, logged, and tied to safety investigations or customer requests, according to Anthropic’s support page.
Still, this matters for businesses.
If your organization has strict zero-data-retention requirements, you need to check whether Fable 5 fits your policies before using it. Anthropic specifically says the update affects organizations using zero-data-retention workspaces or cloud deployments with ZDR expectations.
That does not mean Fable 5 is unsafe to use. It means procurement, legal, security, and compliance teams need to understand the retention policy before rolling it into sensitive workflows.
What Anthropic Has Not Disclosed
To avoid overclaiming, it is worth being clear about what Anthropic’s launch pages do not publicly disclose.
Based on the official pages reviewed, Anthropic does not provide a full public technical spec sheet with:
- parameter count
- architecture details
- training data composition
- exact training compute
- exact public Fable context window in the model page
- exact public max output limit in the model page
- a public date for broad Mythos 5 access
- a guarantee that Fable 5 will remain included in paid plans after June 22
Anthropic does say Fable 5 can stay focused across millions of tokens in long-running tasks and is built for days-long complex asynchronous work. But that is not the same as a clean model table saying, “context window equals X and max output equals Y.”
This is one place where OpenAI and Google are currently more explicit in their public API model tables. OpenAI lists GPT-5.5 with a 1,050,000-token context window and 128,000 max output tokens. Google lists Gemini 3.1 Pro Preview with a 1,048,576-token input limit and 65,536-token output limit.
That does not mean those models are better. It means their public spec tables are clearer on those particular fields.
How to Use Fable 5 Well
The worst way to use Fable 5 is to treat it like a normal chatbot and ask one-line prompts.
The model is expensive and designed for hard work. Use it where the extra capability matters.
Good Fable 5 prompts should include:
- a clear goal
- relevant files or context
- constraints
- success criteria
- permission to inspect, plan, execute, and verify
- a request for tests or validation
- a final summary of what changed
For coding, a strong prompt might be:
You are working in this repository. First inspect the app structure, package files, routes, components, and tests. Then create a migration plan before editing. The goal is to replace the current authentication flow with the new provider while preserving existing user roles and admin behavior. Do not remove existing functionality unless necessary. Add or update tests. After implementation, run the relevant checks, fix any failures, and summarize exactly what changed.
For document analysis:
Review these three documents as if you are preparing a decision memo for an executive. Identify contradictions, missing assumptions, financial risks, legal risks, and operational dependencies. Quote or cite the relevant document sections where useful. End with a recommendation, confidence level, and list of questions that need human review.
For visual analysis:
Compare this screenshot with the target design. Identify all visible differences in layout, spacing, typography, colors, alignment, responsiveness, and missing states. Then propose the smallest code changes needed to make the current implementation match the target.
For research:
Create a research brief on this topic. Separate verified facts from assumptions. Use only the provided sources unless asked to browse. Identify which claims are strongly supported, weakly supported, or unsupported. End with a practical recommendation and a list of open questions.
The theme is simple: do not use Fable 5 for tiny tasks. Use it for tasks where planning, context, verification, and multi-step reasoning matter.
Best Use Cases for Claude Fable 5
Fable 5 is most interesting for people who already use AI seriously.
The best use cases include:
1. Large Codebase Work
Fable 5 should be tested on migrations, refactors, complex bug fixes, and repo-wide changes. It is especially relevant for people using Claude Code or other agentic development environments.
2. Agentic Workflows
Anthropic says Fable 5 can work for days, plan work, delegate to subagents, check its work, and produce deliverables. That makes it more relevant for AI agents than for simple chat.
3. Financial and Legal Document Analysis
The model’s document and chart reasoning benchmarks suggest it may be strong for finance, legal, operations, and strategy workflows. Human review is still required.
4. Vision-Heavy Professional Work
Fable 5 looks useful for charts, diagrams, screenshots, PDFs, interface review, architecture diagrams, and visual QA.
5. Research Assistance
Anthropic highlights scientific research capabilities, including internal examples in biology and genomics. Public Fable users should expect safeguards in some bio/chem areas, but the general research capability is still likely to be strong.
6. High-Quality Writing and Editing
Anthropic does not center the launch around writing, but Claude models have historically been strong here. Fable 5 should be tested for long-form drafting, editing, strategy memos, technical explainers, and source-grounded writing.
When Not to Use Fable 5
Fable 5 will not be the right model for everything.
Do not use it when:
- the task is simple
- cost matters more than quality
- you need unrestricted cyber or bio capability
- your organization cannot accept the 30-day retention policy
- you need guaranteed zero-data-retention handling
- you need a public, exact context/output spec before adoption
- you cannot review the output
- a cheaper model can do the job well enough
For high-volume classification, summarization, simple rewriting, metadata generation, or basic customer support, Fable 5 may be overkill.
The best AI stack will likely use Fable 5 selectively: reserve it for the hardest tasks, and use cheaper models for routine work.
The Bigger Story: Frontier Models Are Becoming Operational Systems
Claude Fable 5 is not just another chatbot upgrade.
The direction is clear: frontier models are becoming operational systems. They do not just answer questions. They increasingly:
- inspect codebases
- operate tools
- read documents
- analyze charts
- browse interfaces
- execute multi-step plans
- test their own work
- maintain long-running context
- coordinate work over time
That is why the safety discussion around Fable and Mythos matters. Anthropic is not only releasing a better assistant. It is releasing a model class that appears meaningfully more capable in domains where misuse risk is real.
This is the same reason Project Glasswing matters. Anthropic’s earlier Mythos Preview work was focused on helping defenders find and patch vulnerabilities. The company says partners used Mythos Preview to find more than 10,000 high- and critical-severity vulnerabilities. That is valuable for defense, but the same category of capability is obviously sensitive.
Project Glasswing page: Anthropic Project Glasswing
So the Fable/Mythos split is not just branding. It may be Anthropic’s model for how to release increasingly capable systems:
- broad access where safeguards are strong enough
- restricted access where capabilities are too sensitive
- trusted programs for defenders and researchers
- fallback models for risky categories
- monitoring and retention policies for safety analysis
Whether users like that tradeoff will depend on their priorities.
Some will prefer the openness and explicit specs of other platforms. Some will prefer cheaper models. Some will want unrestricted capability and dislike fallbacks. Others will see Fable 5 as the right compromise: Mythos-level intelligence for ordinary work, with restrictions around areas that could cause major harm.
Verdict: Is Claude Fable 5 a Big Deal?
Yes.
Based on Anthropic’s official launch materials, Fable 5 appears to be one of the most capable broadly available AI models released so far, especially for coding, agentic workflows, document-heavy professional work, vision, and difficult reasoning.
It is not perfect. It is not cheap. It does not come with every spec fully disclosed. And its safeguards mean that some requests will route to Opus 4.8 instead of being answered by Fable directly.
But the benchmark movement is significant.
- For developers, Fable 5 should be tested immediately against real repo tasks.
- For businesses, it should be tested on document-heavy workflows.
- For AI builders, it should be tested inside agent loops.
- For researchers, it should be evaluated carefully with attention to safeguards and retention.
- For everyone else, it may be the new Claude model to use when the task is hard enough to justify the cost.
The most honest conclusion is this:
Claude Fable 5 is not the cheapest model, and Claude Mythos 5 is not broadly available. But Fable 5 gives general users access to Anthropic’s new Mythos-class intelligence for the first time. That makes this one of the most important model launches of 2026 so far.
Kingy Launch Brief
Put the week’s verified AI launches in your inbox.
Get a source-checked briefing on consequential AI launches, with a clear try, watch or skip verdict. Beehiiv will ask you to confirm your address, then you can choose the subjects you want to follow.
Free · Choose your subjects · Double opt-in · Unsubscribe anytime