DeepSeek V4 — Overview
DeepSeek just released the V4 series under MIT license, with two MoE variants:
| Model | Total Params | Activated Params | Context | Precision |
|---|---|---|---|---|
| DeepSeek-V4-Pro | 1.6T | 49B | 1M | FP4 + FP8 Mixed |
| DeepSeek-V4-Flash | 284B | 13B | 1M | FP4 + FP8 Mixed |
Key Architectural Innovations
- Hybrid Attention (CSA + HCA): Combines Compressed Sparse Attention and Heavily Compressed Attention. At 1M context, V4-Pro uses only 27% of the per-token inference FLOPs and 10% of the KV cache vs. V3.2.
- Manifold-Constrained Hyper-Connections (mHC): Improves signal propagation stability across layers.
- Muon Optimizer: Faster convergence and training stability.
- Training data: 32T+ tokens, followed by a two-stage post-training pipeline (domain-expert SFT + GRPO-based RL, then unified on-policy distillation).
- Three reasoning modes: Non-think, Think High, and Think Max (flagship “Max” mode, requires ≥384K context window).
Benchmarks — Base Models (V3.2 vs V4-Flash vs V4-Pro)
| Benchmark | V3.2-Base | V4-Flash-Base | V4-Pro-Base |
|---|---|---|---|
| MMLU (5-shot) | 87.8 | 88.7 | 90.1 |
| MMLU-Pro | 65.5 | 68.3 | 73.5 |
| AGIEval | 80.1 | 82.6 | 83.1 |
| SimpleQA Verified | 28.3 | 30.1 | 55.2 |
| FACTS Parametric | 27.1 | 33.9 | 62.6 |
| SuperGPQA | 45.0 | 46.5 | 53.9 |
| HumanEval (Pass@1) | 62.8 | 69.5 | 76.8 |
| GSM8K | 91.1 | 90.8 | 92.6 |
| MATH | 60.5 | 57.4 | 64.5 |
| LongBench-V2 | 40.2 | 44.7 | 51.5 |
The jump in SimpleQA Verified (28 → 55) and FACTS Parametric (27 → 63) is the most significant — a huge reduction in hallucination on factual recall.
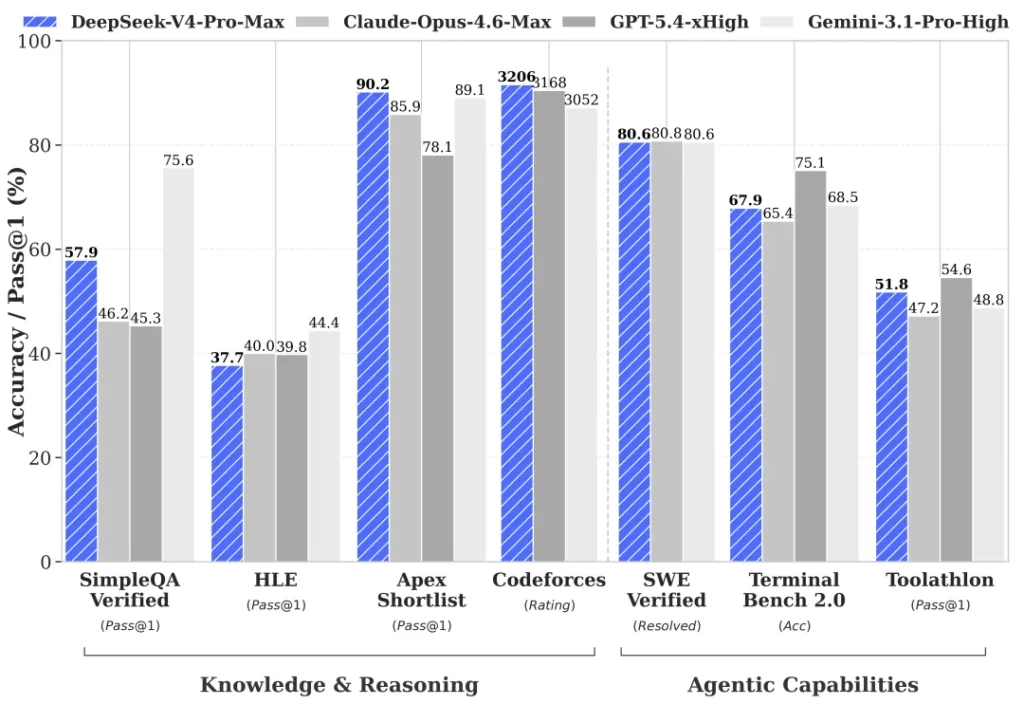
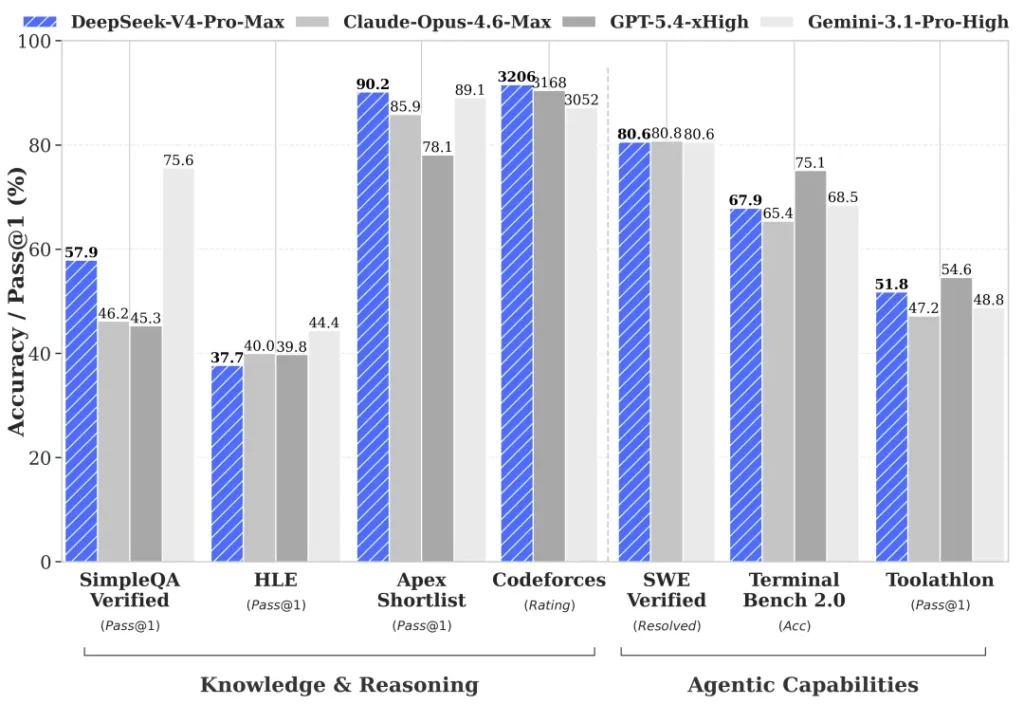
Frontier Model Comparison — DeepSeek-V4-Pro-Max vs Closed Models
⚠️ Note: the official model card benchmarks against Opus 4.6 Max, GPT-5.4 xHigh, and Gemini 3.1 Pro High — not Opus 4.7 or GPT-5.5. Here’s the real head-to-head:
| Benchmark | Opus-4.6 Max | GPT-5.4 xHigh | Gemini-3.1-Pro High | DS-V4-Pro Max |
|---|---|---|---|---|
| MMLU-Pro | 89.1 | 87.5 | 91.0 | 87.5 |
| SimpleQA-Verified | 46.2 | 45.3 | 75.6 | 57.9 |
| Chinese-SimpleQA | 76.4 | 76.8 | 85.9 | 84.4 |
| GPQA Diamond | 91.3 | 93.0 | 94.3 | 90.1 |
| HLE | 40.0 | 39.8 | 44.4 | 37.7 |
| LiveCodeBench | 88.8 | — | 91.7 | 93.5 🏆 |
| Codeforces (Rating) | — | 3168 | 3052 | 3206 🏆 |
| HMMT 2026 Feb | 96.2 | 97.7 | 94.7 | 95.2 |
| IMOAnswerBench | 75.3 | 91.4 | 81.0 | 89.8 |
| Apex | 34.5 | 54.1 | 60.9 | 38.3 |
| Apex Shortlist | 85.9 | 78.1 | 89.1 | 90.2 🏆 |
| MRCR 1M | 92.9 | — | 76.3 | 83.5 |
| CorpusQA 1M | 71.7 | — | 53.8 | 62.0 |
| Terminal Bench 2.0 | 65.4 | 75.1 | 68.5 | 67.9 |
| SWE Verified | 80.8 | — | 80.6 | 80.6 |
| SWE Pro | 57.3 | 57.7 | 54.2 | 55.4 (K2.6 leads at 58.6) |
| SWE Multilingual | 77.5 | — | — | 76.2 |
| BrowseComp | 83.7 | 82.7 | 85.9 | 83.4 |
| GDPval-AA (Elo) | 1619 | 1674 | 1314 | 1554 |
| MCPAtlas Public | 73.8 | 67.2 | 69.2 | 73.6 |
| Toolathlon | 47.2 | 54.6 | 48.8 | 51.8 |
Where V4-Pro Wins, Loses, and Ties
- 🏆 Wins outright: LiveCodeBench (93.5 — #1), Codeforces (3206 Elo — #1), Apex Shortlist (90.2 — #1). V4 is the world’s strongest coding model on competitive/live coding.
- 🤝 Matches frontier: SWE-bench Verified (80.6%, essentially tied with Opus 4.6’s 80.8 and Gemini 3.1 Pro’s 80.6). Strong on GPQA Diamond, HMMT, IMO.
- 📉 Loses: Gemini 3.1 Pro dominates knowledge (MMLU-Pro, SimpleQA, GPQA, HLE). GPT-5.4 wins agentic (Terminal Bench, Toolathlon, GDPval). Opus 4.6 wins long-context retrieval (MRCR, CorpusQA) and multilingual SWE.
Against Other Open-Source Models
Compared to the other open-weight flagships (K2.6 Thinking and GLM-5.1 Thinking):
- V4-Pro-Max beats K2.6 Thinking on almost every benchmark except SWE Pro (K2.6: 58.6 vs V4: 55.4) and HLE-with-tools.
- V4-Pro-Max clearly beats GLM-5.1 Thinking across the board.
- The claim in the model card is accurate: it is “the best open-source model available today” — particularly the first open-weight model to credibly match closed frontier models on coding/reasoning while being MIT-licensed.
Flash vs Pro (Internal Scaling)
V4-Flash-Max (13B active) hits remarkable numbers: LiveCodeBench 91.6, HMMT 94.8, SWE Verified 79.0 — essentially frontier-tier performance from a 284B MoE. This is the more deployable model for most teams.
Efficiency Story
The architectural headline isn’t just benchmarks — it’s the 1M-context cost profile: 27% of V3.2’s per-token FLOPs and 10% of its KV cache. Combined with FP4 MoE weights, V4-Pro is the most inference-cheap frontier-tier model ever released.
Bottom Line
DeepSeek V4 is not the “1T param, Engram memory” model rumored earlier — it’s a 1.6T MoE with hybrid sparse attention that:
- Sets the SOTA on competitive coding (LiveCodeBench, Codeforces).
- Ties Opus 4.6 / Gemini 3.1 Pro on SWE-bench Verified.
- Trails Gemini 3.1 Pro on pure knowledge and GPT-5.4 on agentic tool use.
- Decisively ends the open-vs-closed gap on coding/math while remaining behind on agentic workflows.
Kingy Launch Brief
Put the week’s verified AI launches in your inbox.
One source-checked edition every Friday, with a clear try, watch or skip verdict. After subscribing, check your inbox and confirm your address.
Free · Fridays · Double opt-in · Unsubscribe anytime