
Reviewed July 28, 2026. This explainer is grounded in the authors’ arXiv paper and distinguishes their image-model experiments from broader claims about every AI system.
Verdict: “Self-Consuming Generative Models Go MAD” is durable because it identifies a concrete failure mode: repeatedly training on model-generated data can reduce quality or diversity unless enough fresh real data enters the loop. It does not prove that any use of synthetic data ruins a model, nor does it directly establish the same rate of decline for modern language models.
The Paper in One Minute
Sina Alemohammad, Josue Casco-Rodriguez, Lorenzo Luzi and five co-authors submitted the paper in July 2023. They study “autophagous” training loops: a new model generates samples, those samples enter the next training set, and the process repeats across generations.
The central result is conditional but serious. Without enough fresh real data in each generation, the authors observe progressive loss of precision (sample quality), recall (coverage or diversity), or both. They call this Model Autophagy Disorder, or MAD.
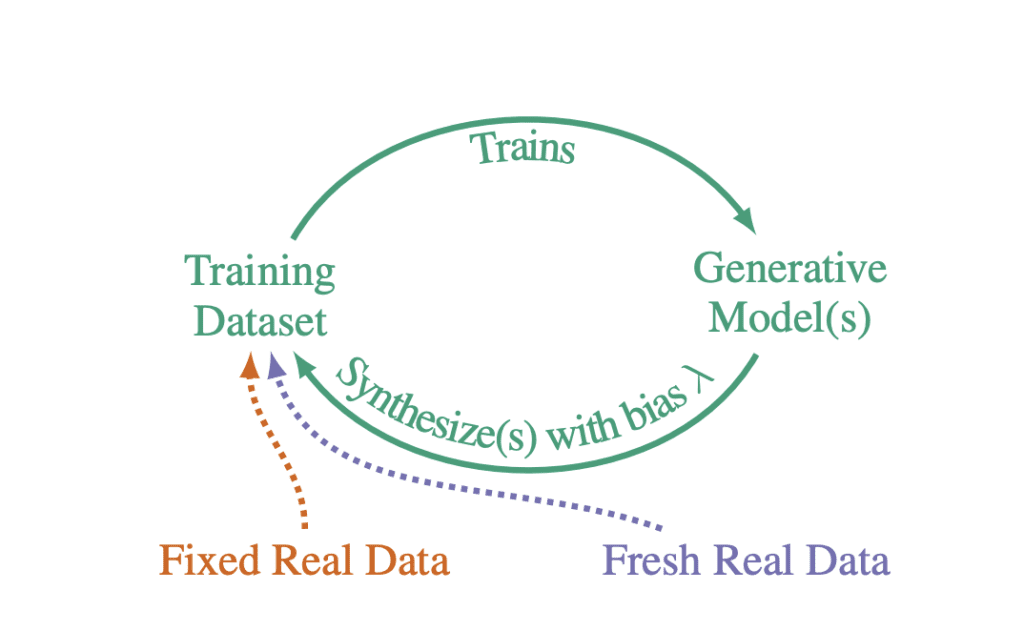
Three Training Loops, Three Different Risks
| Loop | Training data over generations | Why it matters |
|---|---|---|
| Fully synthetic | Each generation depends on synthetic samples from earlier models. | Errors and missing modes have no fresh real distribution to correct them. |
| Synthetic augmentation | A fixed real dataset remains, with more synthetic data added. | The real anchor helps, but the synthetic share and sampling bias still matter. |
| Fresh-data loop | New real examples enter at each generation. | Sufficient fresh data can counter the compounding loss demonstrated in the other loops. |
What “Quality or Diversity” Means
A model can fail in more than one way. Biased sampling may keep the most attractive or high-scoring outputs, improving apparent sharpness while narrowing the range of outcomes. Less selective sampling can preserve more variety while allowing visible artifacts to accumulate. The paper’s precision-and-recall framing is valuable because a small set of polished outputs can hide a collapsed distribution.

What the Paper Does Not Establish
- It does not show that synthetic data is always harmful; controlled synthetic data can still be useful.
- It does not quantify a universal “internet collapse” date.
- Its principal experiments use generative image models, so extending the exact behavior to language, audio or multimodal systems is an inference.
- Filtering synthetic content is not automatically safe: selecting only preferred samples can trade diversity for quality.
Practical Implications for Dataset Builders
The paper supports a conservative data policy: track provenance, preserve access to original real data, measure diversity as well as average quality, and test repeated-generation effects rather than evaluating one training run. Watermarks and detectors may help with provenance, but neither should be treated as perfect.
For related context, read Kingy’s guide to Karpathy’s autoresearch loop and its analysis of AI data-exhaustion claims. The useful lesson is not “never use synthetic data.” It is “do not let a recursive pipeline hide where its training distribution came from.”
Primary Source
Read the paper abstract, author list and full text on arXiv.
Kingy Launch Brief
Put the week’s verified AI launches in your inbox.
The public Friday pilot has not sent its first issue yet. Join for a source-checked launch briefing with a clear try, watch or skip verdict, then check your inbox and confirm your address.
Free · Friday pilot · Double opt-in · Unsubscribe anytime