

Large language models are powerful, but they are not agents by themselves.
That distinction sounds subtle, but it explains a lot of the confusion around modern AI products. People look at tools like Claude Code, Codex, Cursor, Windsurf, Manus, Devin-like systems, and other “AI agents” and assume the magic lives entirely inside the model. If the agent succeeds, the model must be brilliant. If it fails, the model must be weak.
That is only partly true.
A model is the reasoning and generation engine. It predicts, writes, summarizes, classifies, plans, and proposes actions. But an agent that can inspect files, call tools, run tests, use a browser, remember progress, recover from errors, and ask for approval before doing something dangerous needs more than a model.
It needs a harness.
In the simplest terms, an agentic harness is the software layer around a model that turns it from a text generator into a working agent. LangChain puts the idea bluntly: “Agent = Model + Harness” in its article The Anatomy of an Agent Harness. The model contains intelligence; the harness makes that intelligence useful.
A useful analogy is this:
The model is the engine.
The harness is the car.
An engine alone can produce power. But without steering, brakes, fuel lines, a dashboard, transmission, safety systems, wheels, and a road interface, it does not get you anywhere useful. Likewise, an LLM alone can produce text. But without context management, tool execution, memory, permissions, runtime environments, and feedback loops, it cannot reliably do complex work in the real world.
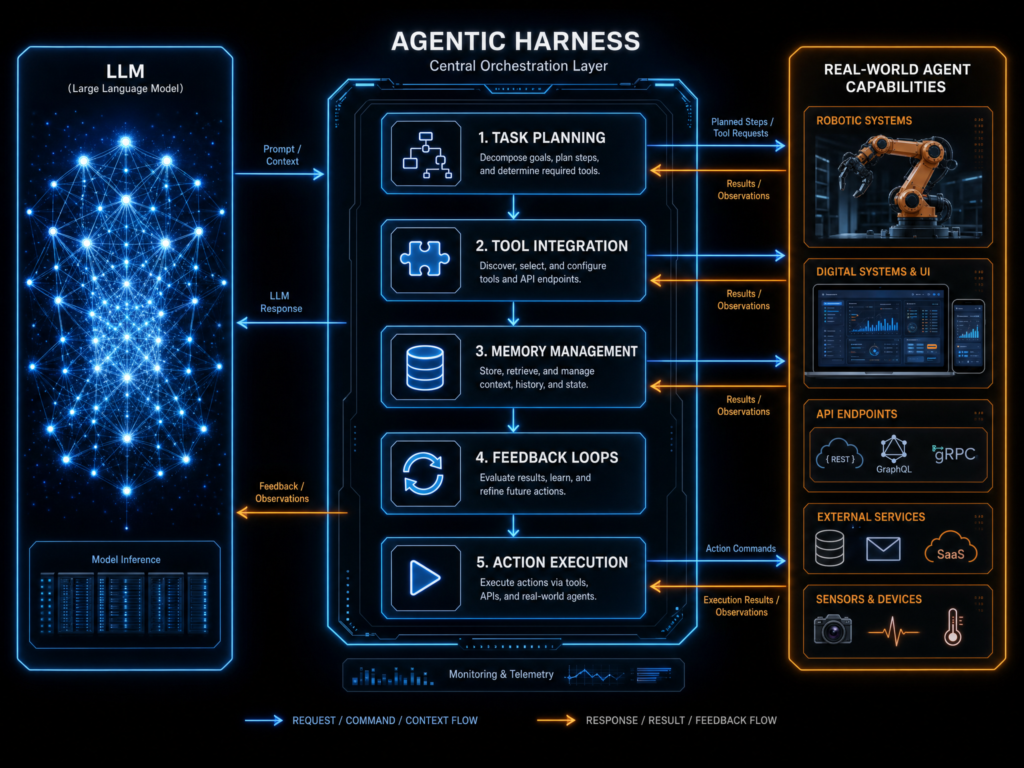
That missing layer — the harness — is becoming one of the most important concepts in AI.
The model is not the product
For most of the LLM era, the public conversation focused on models. GPT versus Claude. Gemini versus Llama. Bigger context windows. Better reasoning benchmarks. Faster inference. Lower cost per token.
Those things matter. But they are not the whole system.
A raw LLM generally receives input and produces output. It can reason over what is in its context window, but it does not automatically have durable memory, permissioned access to your filesystem, safe code execution, browser control, test runners, observability, or an understanding of when it should stop and ask a human for approval.
LangChain’s article describes a harness as the code, configuration, and execution logic that is not the model itself: system prompts, tools, skills, MCPs, filesystems, sandboxes, orchestration logic, hooks, compaction, continuation, lint checks, and more (LangChain).
Parallel gives a similar definition in its explainer, describing an agent harness as infrastructure that wraps around an LLM and handles what the model itself does not: tools, memory, workflows, and interaction with complex environments (Parallel).
That means when you use an AI coding agent, you are not just using a model. You are using a model embedded inside an engineered environment.
That environment decides:
- what the model sees,
- what tools it can call,
- what files it can read or edit,
- what commands it can run,
- what state gets persisted,
- what gets summarized or compacted,
- what actions require approval,
- what tests or checks are run,
- how errors are handled,
- when the task is considered complete.
That is the harness.
From chatbot to agent
A chatbot is usually reactive. You ask a question; it answers. You provide context; it reasons over that context. You ask for a draft; it produces one.
An agent is different. An agent does not merely answer. It acts.
For example, a coding chatbot might say:
“The bug is probably in the authentication middleware. You should check whether the token expiry logic handles null values.”
A coding agent might instead:
“I inspected the authentication middleware, found a failing null-token path, edited the file, added a regression test, ran the test suite, found a linter issue, fixed it, and produced a reviewable diff.”
The second behavior requires a loop:
- Observe the environment.
- Reason about what to do next.
- Take an action.
- Observe the result.
- Adjust the plan.
- Verify the outcome.
- Continue or stop.
That loop is not just “the model.” It is the model operating inside a system that lets it observe and act.
LangChain describes common agent execution as a ReAct-style pattern: the model reasons, takes an action through a tool call, observes the result, and repeats (LangChain). But the model cannot execute the tool call by itself. The harness must expose the tool, validate the request, run it, capture the result, and feed the result back into the model.
The harness is what gives the model hands, eyes, memory, and constraints.
Why the term “harness” is showing up now
The term is becoming popular because AI systems are moving from short, one-shot interactions to long-running work.
A one-shot model interaction can be simple:
“Summarize this article.”
But a long-running agent task might be:
“Refactor this backend service, preserve the API contract, update tests, validate the build, and open a pull request.”
That second task is much harder. It requires the system to maintain state over time, understand a project, inspect files, make edits, run commands, recover from errors, and avoid damaging unrelated work.
Anthropic’s engineering post Effective harnesses for long-running agents explains the challenge clearly: long-running agents often work across multiple context windows, and each new session can begin with no memory of what came before. Anthropic compares this to software engineers working in shifts, where every new engineer arrives with no memory of the previous shift.
That is a devastating problem for autonomous work.
If an agent loses track of what has already been done, it may duplicate work, break half-finished features, declare success too early, or spend most of its time reconstructing the project state. Anthropic’s solution involved a more structured harness: an initializer agent to set up the environment and a coding agent that makes incremental progress while leaving clear artifacts for the next session (Anthropic).
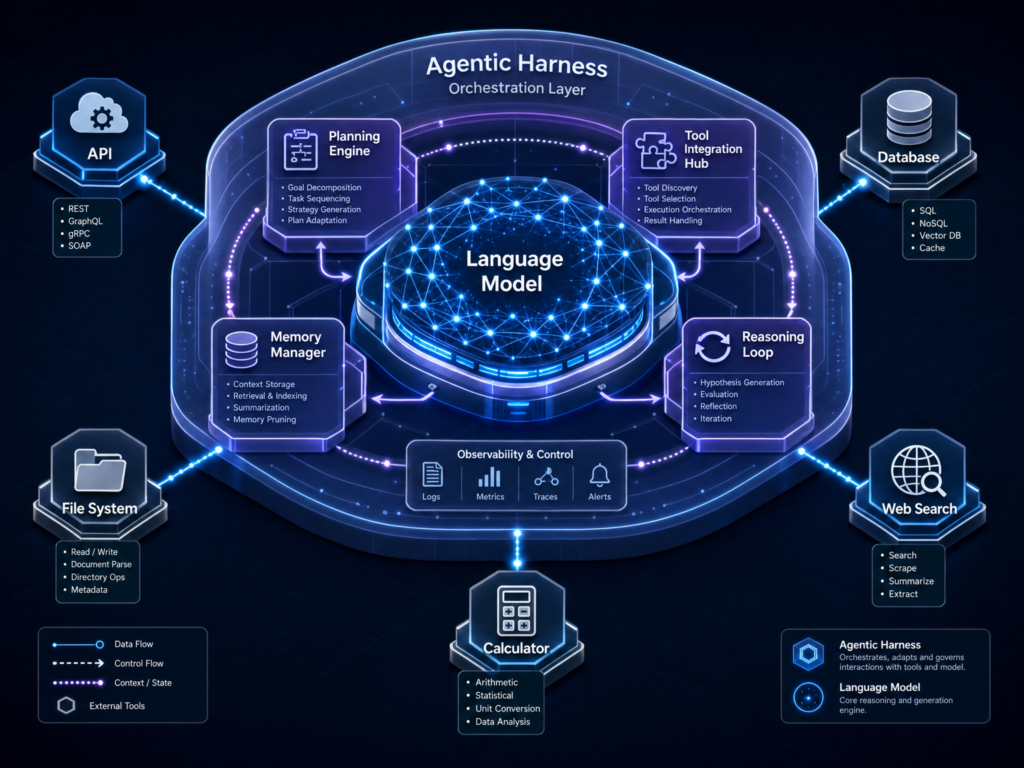
This is the essence of harness thinking.
The question is not merely:
“How smart is the model?”
The better question is:
“What system surrounds the model so it can keep making reliable progress?”
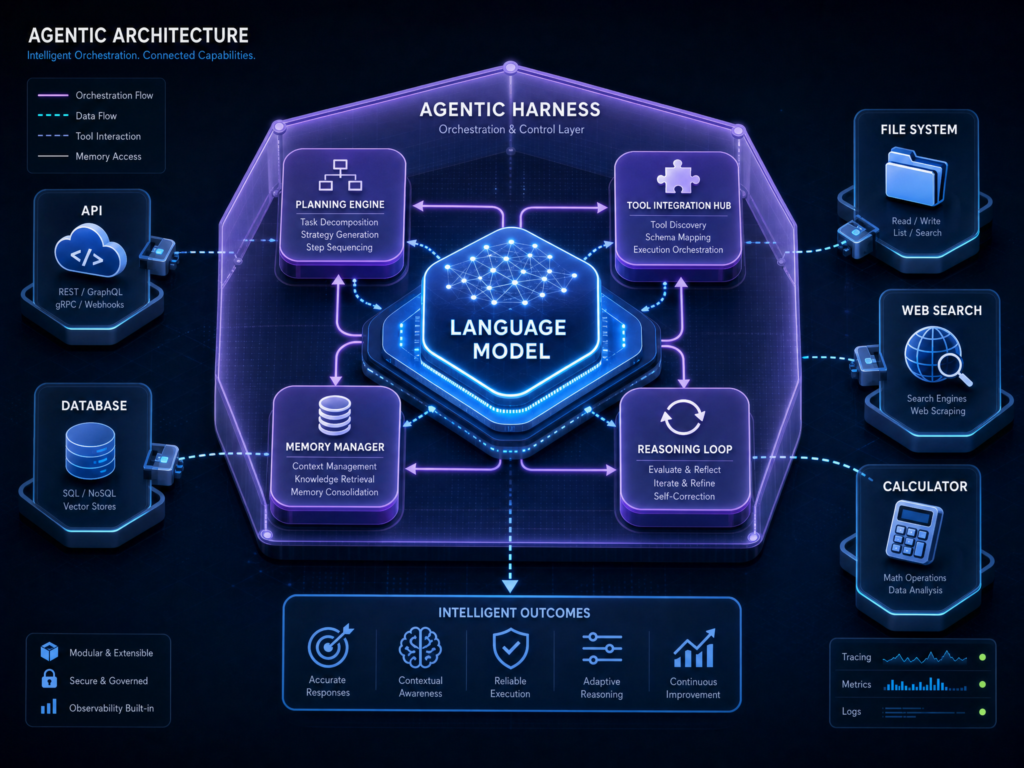
The anatomy of an agentic harness
A mature harness usually has several layers.
The first is context management. The model cannot reason over everything in the world. It can only reason over what is placed into its context window. The harness decides what information to include: user instructions, relevant files, tool results, summaries, project rules, documentation, prior decisions, and current task state.
This is why “context engineering” has become such an important discipline. It is not enough to give the model more tokens. The system needs to give it the right information at the right time.
The second layer is tool access. Agents need tools. A coding agent may need file read/write, grep, terminal access, package managers, test runners, browser automation, Git, GitHub CLI, or deployment commands. A research agent may need search, extraction, document parsing, citation checking, spreadsheet tools, and web navigation.
But exposing tools is not enough. The harness must also govern how those tools are used. It needs schemas, permissions, retries, error handling, and logging. A good harness does not simply say, “Here are 50 tools, good luck.” It shapes tool access so the agent can make effective choices without spiraling.
The third layer is state and memory. If an agent is working on a long task, it needs to know what happened earlier. That memory can live in many places: session logs, summaries, files, databases, vector stores, Git history, progress documents, or task trackers.
LangChain emphasizes the filesystem as a foundational harness primitive because it gives agents durable storage, a workspace, and a collaboration surface. Agents can store intermediate outputs, write plans, update progress, and coordinate with humans or other agents through files (LangChain).
The fourth layer is execution environment. If the agent can run code, where does that code run? Locally? In a container? In a sandbox? In a cloud workspace? With network access or without it? With access to secrets or not?
This is a harness-level decision. It affects safety, reproducibility, cost, and capability.
The fifth layer is verification. Agents are probabilistic. They can claim something is fixed when it is not. A harness can reduce that risk by running tests, linting code, checking schemas, validating citations, comparing screenshots, inspecting logs, or requiring human approval.
Anthropic found that Claude could mark features as complete prematurely without proper testing. Their harness pattern pushed the agent to self-verify features and only mark them passing after careful testing (Anthropic).
The sixth layer is permissions and governance. Agents that can act need boundaries. A harness can require approval before deleting data, sending emails, charging cards, modifying production systems, or accessing sensitive resources. This is where safety becomes infrastructure rather than just a line in a prompt.
The seventh layer is observability. If an agent fails, you need to know why. What did it see? What tool did it call? What model was used? What command failed? What context was included? What policy blocked an action?
A harness that cannot be observed cannot be trusted.
Prompt engineering, context engineering, and harness engineering
It helps to separate three related ideas.
Prompt engineering is about the instructions you give the model. It asks: what words should we use to get the desired response?
Context engineering is about what information the model sees. It asks: what should be included, retrieved, summarized, excluded, or compressed for this specific step?
Harness engineering is broader. It asks: what entire system should surround the model so it can complete work reliably?
Martin Fowler’s site describes harness engineering for coding agents as a way to increase confidence in agent outputs through guides and sensors. Guides steer the agent before it acts; sensors observe after it acts and help it self-correct. Examples include AGENTS.md, skills, linters, type checkers, structural tests, code review agents, and feedback loops (Martin Fowler).
That framing is important because it shows that a harness is not just a technical wrapper. It is a control system.
A prompt can say:
“Follow our architecture.”
A harness can enforce architecture with structural tests.
A prompt can say:
“Run the test suite.”
A harness can run the test suite and block progress if it fails.
A prompt can say:
“Do not edit generated files.”
A harness can restrict file access or detect prohibited changes.
A prompt is advice. A harness can be enforcement.
Why coding agents made harnesses visible
Coding agents made the harness concept easier to see because software development exposes the full loop.
When an AI coding agent works, you can often watch it:
- inspect files,
- search the repository,
- form a plan,
- edit code,
- run commands,
- read errors,
- revise the implementation,
- update tests,
- produce a diff.
This makes the hidden architecture visible. The user sees not just a generated answer, but an operational system.
That is why products like Claude Code, Codex, Cursor, and Windsurf are not merely “models for coding.” They are different kinds of harnesses around models.
A terminal agent emphasizes command-line execution, repository access, Git workflows, and local or cloud runtime control. An IDE agent emphasizes editor context, inline diffs, autocomplete, multi-file edits, and developer ergonomics. A general-purpose cloud agent emphasizes broader workflows: browsing, research, file generation, task execution, and multi-step delivery.
The underlying model matters, but the harness determines what kind of work the model can actually perform.
OpenAI’s post Harness engineering: leveraging Codex in an agent-first world shows this in practice. OpenAI describes building an internal software product with Codex writing the code, while humans focused on designing environments, specifying intent, and building feedback loops. The post emphasizes that the engineering role shifted from writing code manually to creating the scaffolding that allowed agents to do reliable work.
One of the most revealing lines from the OpenAI piece is:
“Humans steer. Agents execute.”
That is a harness worldview. The human’s job becomes defining goals, constraints, feedback loops, and operating environments. The agent’s job becomes executing within those boundaries.
The harness as infrastructure
A recent Medium article, Agentic Harnesses: The New Infrastructure Layer for AI Systems?, frames the harness as the infrastructure layer beneath modern agentic systems. It argues that the harness binds together models, tools, memory, permissions, orchestration logic, execution environments, and user-facing surfaces into one operational system.
That framing is useful because it separates the harness from the interface.
The interface is what the user sees: a terminal, IDE, web app, chat window, Slack bot, or API. The harness is what governs the work underneath.
This distinction matters. The same harness pattern could theoretically power multiple interfaces. One user might interact through a terminal. Another through an IDE. Another through a cloud dashboard. Another through an API. If the harness is well-designed, the interface becomes just one surface on top of a deeper execution system.
That is why harness design may become a competitive moat.
Models can be swapped. Interfaces can be copied. But reliable execution systems are hard to build. They require deep iteration on failure modes, state management, context strategy, permissions, evaluation, and recovery.
What makes a good harness?
A good harness does not maximize autonomy blindly. It maximizes useful, bounded autonomy.
There is a difference.
An agent that can do anything can also break anything. A strong harness gives the agent enough freedom to make progress, while limiting the ways it can cause damage.
A good harness is usually:
Legible. The agent can understand the environment. Documentation, file structure, logs, tests, and errors are available in formats the model can use. OpenAI’s Codex post emphasizes making the application UI, logs, metrics, traces, and repository knowledge legible to agents (OpenAI).
Incremental. The agent works in small steps rather than attempting to solve a huge task in one shot. Anthropic found that incremental progress was critical for long-running coding tasks (Anthropic).
Verifiable. The agent’s claims are checked against reality. Tests run. Schemas validate. Browser actions confirm behavior. Logs are inspected.
Permissioned. Dangerous actions require approval. The agent should not have unrestricted access to production systems, secrets, billing actions, or destructive commands.
Observable. Humans can inspect what happened. Tool calls, model outputs, command results, state transitions, and errors should be logged.
Recoverable. The system can resume after interruption, revert bad changes, retry bounded steps, or escalate to a human.
Context-efficient. The harness does not dump everything into the prompt. It uses progressive disclosure: show the model what matters now, and let it retrieve deeper information when needed.
Adaptable. When the agent repeatedly fails, the harness can be improved. Add a linter. Add a test. Add a checklist. Add a permission boundary. Add a better progress file. Add a more reliable tool.
This is why harness engineering is not a one-time setup. It is an ongoing practice.
The role of humans changes
Agentic harnesses do not remove humans. They change where humans sit in the loop.
In a traditional workflow, humans do most of the execution. They read the code, make the change, run the test, interpret the failure, fix it, and prepare the pull request.
In an agentic workflow, humans increasingly define intent, constraints, review criteria, and escalation points. The harness then lets the agent execute within those boundaries.
Martin Fowler’s article argues that the human’s job is to steer the agent by iterating on the harness. When an issue happens repeatedly, improve the feedforward and feedback controls so that issue becomes less likely in the future (Martin Fowler).
That is a major shift.
Instead of repeatedly correcting the same agent mistake manually, you encode the correction into the environment. You turn human judgment into durable scaffolding.
If the agent keeps violating naming conventions, add a rule or linter.
If it keeps forgetting to update documentation, add a checklist or CI check.
If it keeps marking work done too early, add explicit acceptance tests.
If it keeps choosing the wrong files, improve repo maps or architecture docs.
If it keeps running unsafe commands, tighten permissions.
This is how harnesses compound.
Why better models do not eliminate harnesses
It is tempting to think that better models will make harnesses unnecessary. If models become smarter, maybe they will not need all this scaffolding.
Some harness features may become less necessary as models improve. Better models may plan more effectively, use tools more accurately, and maintain coherence over longer tasks. But the need for a harness does not disappear.
Why?
Because real-world work requires interaction with systems outside the model. Even a brilliant model still needs:
- current data,
- tools,
- file access,
- APIs,
- execution environments,
- authentication,
- permissions,
- logging,
- rollback,
- observability,
- compliance,
- cost controls,
- human approval.
Those are not just intelligence problems. They are systems problems.
A model can suggest deleting a database. The harness decides whether that action is allowed. A model can write code. The harness runs tests. A model can cite a source. The harness can verify the link. A model can propose a plan. The harness tracks state and progress.
The smarter the model, the more valuable the harness may become, because smarter models can attempt more powerful actions. More capability creates more need for control.
The product landscape: Codex, Claude Code, Cursor, Windsurf, Manus
So where do the familiar tools fit?
Think of each product as a different combination of model, harness, interface, and workflow.
Codex is OpenAI’s coding-agent system. OpenAI’s harness engineering article describes Codex being used in an agent-first workflow where agents write code and humans focus on intent, environment design, feedback loops, and review (OpenAI).
Claude Code is Anthropic’s coding-agent product. Anthropic’s long-running agent article specifically discusses the Claude Agent SDK as a general-purpose agent harness with context management and tool use, and the broader Claude coding ecosystem reflects the same harness principles: tool use, progress tracking, compaction, environment setup, and verification (Anthropic).
Cursor and Windsurf are agentic IDE-style products. Their harnesses are embedded inside the editor experience: file context, inline edits, diffs, multi-file changes, command execution, and developer workflow integration. The interface is the IDE, but the harness is the system that lets the model act inside the project.
Manus and similar general-purpose agents are broader agentic workspaces. They are not only about code. They typically aim to handle research, browsing, task execution, artifact generation, and multi-step workflows. The same harness concept applies, but the toolset and environment are broader than a software repository.
The key point is that these products are not all the same thing. Some are terminal-first. Some are IDE-first. Some are cloud-first. Some are coding-specific. Some are general-purpose. But they all depend on the same core pattern:
model + context + tools + state + permissions + execution + verification + interface.
That combination is the agentic harness.
The real lesson: agents are systems, not prompts
The rise of agentic harnesses marks a maturation point in AI.
Early LLM applications were often prompt-centric. If the output was bad, people tried a better prompt. Then they tried better retrieval. Then longer context. Then a different model.
Those improvements still matter. But for agents, the reliability frontier is increasingly about systems.
Can the agent see the right information?
Can it act safely?
Can it verify its work?
Can it remember progress?
Can it recover from interruption?
Can it ask for help when needed?
Can humans inspect what happened?
Can the workflow improve over time?
Those are harness questions.
A weak harness turns a powerful model into an unreliable demo. A strong harness can make the same model dramatically more useful.
This is why “agentic harness” is such an important phrase. It gives a name to the layer that many people were sensing but not clearly describing. It explains why some AI products feel dramatically more capable than others even when they use similar models. It explains why coding agents are not just autocomplete with a bigger context window. It explains why AI product quality increasingly depends on orchestration, permissions, memory, tools, feedback loops, and environment design.
The model is still essential. But the model is no longer the whole story.
The future of AI agents will not be determined only by who has the smartest model. It will also be determined by who builds the best harness around that model.
Because an LLM can generate text.
But a harness turns that text into action.







