For more than a decade, the data-center conversation has been pulled almost entirely toward the GPU. Training, inference, MLPerf charts, FP8 throughput, HBM stack heights — accelerators have eaten the headlines, and for good reason. But the dirty secret of running modern AI at scale is that the GPU is almost never the only bottleneck. Agents wait on CPUs. Sandboxes wait on CPUs. Reinforcement learning loops wait on CPUs. Tokenizers, retrievers, schedulers, KV-cache managers, ETL jobs, compilation steps, code interpreters — all of it runs on the host.
Which is exactly the gap NVIDIA is trying to fill with Vera, its second-generation Arm server CPU, announced at GTC 2026 and now in full production with partner systems shipping in the second half of 2026.
This guide walks through what Vera actually is, what NVIDIA has and hasn’t disclosed, how it compares to AMD and Intel, what the early third-party benchmarks suggest, and — crucially — what’s still missing from the public record. The goal is to help you decide where Vera fits in your stack without pretending the data is more complete than it actually is.

Why Vera matters now
NVIDIA’s own framing is unusually direct. The official Vera CPU product page describes the chip as “purpose-built for agentic AI,” with a stated focus on reinforcement learning, sandboxed tool execution, and the orchestration work that keeps GPUs fed. The NVIDIA technical blog goes further, invoking Amdahl’s law by name: as GPUs get faster every generation, the serial CPU-bound parts of an AI pipeline become a larger share of total wall-clock time.
That framing matches what’s actually happening in production. A modern agentic AI system doesn’t just call a model — it plans, retrieves, calls tools, executes generated code in a sandbox, evaluates results, and iterates. Each cycle includes a meaningful slice of work that lives on the CPU. When you’re running tens of thousands of these loops concurrently, the host platform stops being a procurement afterthought and starts being a first-order design problem.
Vera is NVIDIA’s attempt to make the host CPU a first-class part of the AI factory, rather than a generic x86 box bought from someone else.
What NVIDIA actually launched
It’s worth being careful about terminology here, because three things were announced under overlapping branding:
- Vera CPU — the 88-core Arm v9.2 processor itself, available in standard single-socket and dual-socket configurations.
- Vera CPU Rack — an MGX-based, liquid-cooled rack with up to 256 Vera CPUs, sold as a CPU-only system for sandbox, ETL, and analytics density.
- Vera Rubin platform — the full rack-scale AI supercomputer combining Vera CPUs with Rubin GPUs (and, in extended configurations, Groq 3 LPX inference accelerators), described in detail in the Vera Rubin platform press release and NVIDIA’s “Inside the Rubin Platform” technical blog.
This guide focuses on the CPU. But it’s important to keep the levels straight, because many of NVIDIA’s most aggressive performance claims — “10× higher inference throughput per watt,” “one-tenth the cost per token versus Blackwell” — are platform-level claims for Vera Rubin, not Vera-only claims.
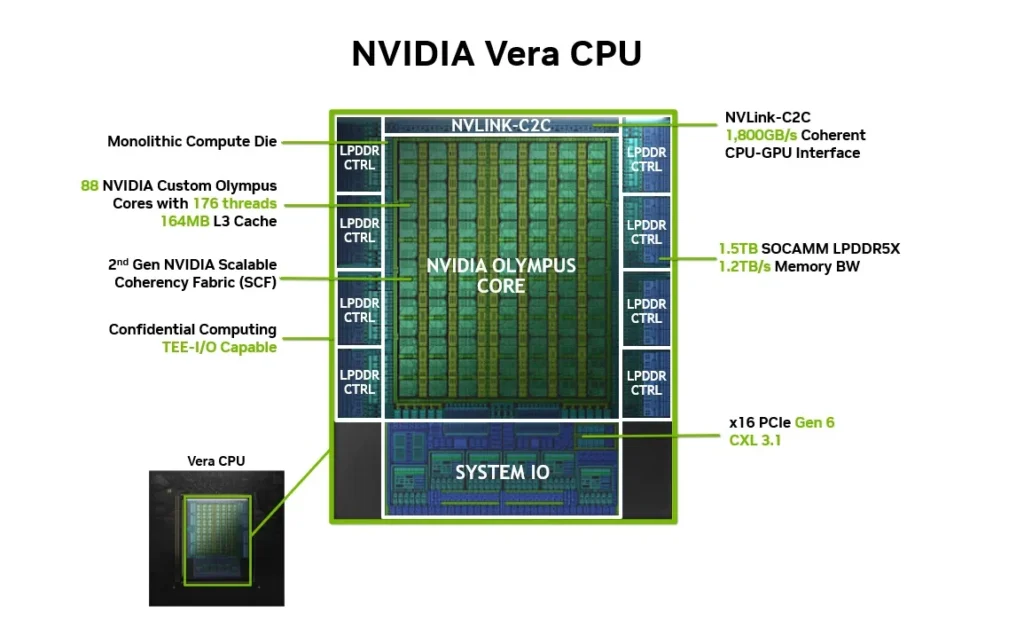
The headline Vera specifications, drawn from the official launch press release and product page:
- 88 custom Olympus cores, fully Arm v9.2 compatible
- 176 threads via NVIDIA Spatial Multithreading
- 2 MB L2 per core (176 MB total), plus 164 MB shared L3
- Up to 1.5 TB of LPDDR5X per socket, delivered through SOCAMM modules
- Up to 1.2 TB/s of memory bandwidth, with NVIDIA claiming sustained over 90% of peak under load
- 3.4 TB/s SCF on-chip bisection bandwidth
- 1.8 TB/s NVLink-C2C for both CPU-to-CPU and CPU-to-GPU links
- PCIe Gen6 and CXL 3.1 for external I/O
- First CPU to support FP8 precision (via 6 × 128-bit SVE2 engines)
- Full confidential computing across CPU and connected GPUs
And, just as importantly, the things NVIDIA has not disclosed in any official material reviewed for this guide:
- Process node
- Clock frequencies
- TDP
- Public list pricing
- L1 cache sizes
- Independent SPEC, STREAM, or MLPerf CPU results
That last category matters. The current evidence base is rich on architecture and thin on independent benchmarks. Anyone telling you Vera “beats” or “loses to” current-generation x86 CPUs on the basis of public data alone is overstating the certainty available.
From Grace to Vera
Vera is the second generation of NVIDIA’s Arm server CPU line, following Grace. The headline jump, as summarized by Tom’s Hardware and Knowledge Hub Media at launch, is a claimed 1.5× improvement in instructions per cycle, achieved by replacing Grace’s off-the-shelf Arm Neoverse V2 cores with NVIDIA’s own custom Olympus cores.
But the bigger story is structural. Grace was designed primarily as a companion to the GPU — most production deployments paired it inside a Grace Hopper or Grace Blackwell Superchip. Vera is being positioned, openly, as a standalone competitor in the data-center CPU market. BigGo’s launch coverage summarizes the shift cleanly: “While Grace was designed primarily as a high-performance companion to NVIDIA’s GPUs, Vera is positioned as a general-purpose data center CPU with a laser focus on AI-adjacent tasks.” Meta’s announced plan to deploy multiple generations of NVIDIA CPU-only systems — including standalone Grace and then standalone Vera — is the clearest signal that this isn’t just marketing language.
Compared to Grace, Vera bumps core count from 72 to 88, more than doubles memory bandwidth (from roughly 546 GB/s to 1.2 TB/s), roughly triples memory capacity (to 1.5 TB), doubles NVLink-C2C bandwidth to 1.8 TB/s, and introduces FP8 vector support and Spatial Multithreading. The platform also adds confidential computing across the CPU-GPU domain, PCIe Gen6 and CXL 3.1, and SOCAMM-based detachable LPDDR5X memory modules.
The Olympus core
The Olympus core is NVIDIA’s first fully custom data-center CPU core. Per the NVIDIA technical blog, it features a 10-wide instruction fetch and decode front end, a neural branch predictor capable of evaluating two taken branches per cycle, and six 128-bit SVE2 vector engines with FP8 support.
A few things deserve attention here.
First, NVIDIA is explicitly framing this as a single-thread performance play. Agentic loops are not embarrassingly parallel in the way a transformer matrix multiplication is — most sandbox environments use a small number of threads, and overall throughput is the sum of many independent short tasks. Faster cores translate directly to lower per-environment wall-clock time, which translates to more RL training iterations and faster agent response times. PC Gamer’s coverage notes that NVIDIA has been unusually emphatic about “extremely high” single-core performance, though it has not put Olympus into any consumer roadmap.
Second, the FP8 vector path is genuinely interesting but should be read carefully. Vera is the first general-purpose CPU to support FP8 in the ISA, which is useful for the kind of host-side AI work that touches model weights — quantized embeddings, small reranker models, lightweight classifiers used as policy filters. It is not a substitute for a tensor accelerator. There is no separate on-CPU NPU or AMX-equivalent matrix unit disclosed; the FP8 capability lives inside the general-purpose SVE2 pipeline. That makes Vera flexible for mixed control/data workloads but means dense matrix math still belongs on the GPU.
Third, the neural branch predictor is more practically meaningful than it sounds. Agentic workloads are unusually branch-heavy compared to classic HPC code: interpreters, garbage collectors, JIT compilers, schedulers, and tool-calling logic all live or die by branch prediction accuracy. NVIDIA’s decision to invest there suggests the team profiled real RL and agent traces rather than just optimizing for SPEC.
Spatial Multithreading
This is one of Vera’s more genuinely novel features and deserves a careful read.
Traditional simultaneous multithreading (SMT) — the way Intel Hyper-Threading and AMD’s SMT work — time-shares per-core execution resources between two threads. When both threads are active, they fight over the same caches, schedulers, and execution ports. Average throughput goes up; tail latency and predictability go down. For multi-tenant cloud environments, this is a well-known headache.
NVIDIA’s Spatial Multithreading takes a different approach. According to the NVIDIA technical blog, each Olympus core physically partitions its resources between two threads rather than time-slicing them. Users can choose at runtime whether to optimize for single-thread performance (88 threads, full resources per thread) or for density (176 threads, partitioned resources). NVIDIA explicitly markets this as delivering “stable performance, stronger isolation, and predictable tail latency under heavy load.”
The catch — and this is a useful real-world example of new hardware running ahead of mature software — is that the Linux kernel’s scheduler didn’t initially know how to handle this asymmetric capacity model. Phoronix reported on an upstream patch series from NVIDIA engineers showing that without SMT-aware scheduler fixes, certain CPU-intensive workloads could see up to roughly 2× lower performance on Vera Rubin systems. The patches are landing; the work is normal for a new platform. But it’s a useful reminder that early adopters should budget for kernel and userspace tuning during the first generation of deployments.
Why the memory system is the real story
Headline core counts are misleading on Vera. AMD’s EPYC 9965 ships with 192 cores; Intel’s Xeon 6980P ships with 128. Vera’s 88 cores trail both. If your workload is purely about stuffing the maximum number of independent threads into a socket and you don’t care about per-core feed rate, Vera is not the obvious winner.
The competitive picture changes when you look at memory bandwidth per active core.
- Vera: ~1.2 TB/s ÷ 88 cores ≈ 13.6 GB/s per core (NVIDIA rounds this to “up to 14 GB/s per core”)
- EPYC 9755 / 9965: 614 GB/s ÷ 128 or 192 cores ≈ 3.2–4.8 GB/s per core with DDR5-6400
- Xeon 6980P: ~614 GB/s with DDR5-6400 across 12 channels, or ~845 GB/s with MRDIMM-8800, giving roughly 4.8–6.6 GB/s per core
That’s a 2× to 4× per-core bandwidth advantage for Vera, depending on what you’re comparing against. As ServeTheHome’s hands-on coverage noted, the chip uses a 1,024-bit LPDDR5X interface across eight SOCAMM modules to hit that bandwidth — substantially wider than what current DDR5 server platforms can offer.
This matters because the workloads NVIDIA is targeting — agentic sandboxes, ETL, real-time analytics, KV-cache movement, vector database queries — tend to be more memory-bound than compute-bound at the CPU level. They benefit much more from bandwidth per active thread than from raw thread count.
SOCAMM itself is also worth noting. It’s NVIDIA’s term for “Small Outline Compression-Attached Memory Modules” — LPDDR5X packaged into a detachable, serviceable form factor rather than soldered to the board. That brings the power efficiency of mobile-class memory into the data center without sacrificing the field-replaceable serviceability that operators expect. NVIDIA says SOCAMM delivers Vera’s full bandwidth at less than half the memory power of comparable DDR-based configurations, though it does not publish the precise wattage.
Single die versus many chiplets
The other major architectural decision in Vera is that the 88 cores live on a single monolithic compute die. Adjacent dielets handle the memory controllers and I/O, but the compute fabric itself is uniform — every core is the same practical distance from every cache, memory controller, and I/O path.
This is a deliberate departure from AMD’s chiplet philosophy, which exposes a NUMA topology with multiple core complex dies arranged around a central I/O die. AMD’s approach has real advantages — better yield, easier scaling to very high core counts, lower production cost — but it also creates NUMA tuning work and uneven cross-die latency that has to be managed by the application or the scheduler.
NVIDIA’s argument, made directly in the Rubin platform technical blog, is that agentic and analytics workloads are too irregular to tune that way. The second-generation Scalable Coherency Fabric (SCF) connects all 88 cores to the unified L3 with 3.4 TB/s of bisection bandwidth and, NVIDIA says, sustains over 90% of peak memory bandwidth under load. That’s the kind of number that, if it holds up under independent measurement, would be a meaningful differentiator for the workloads where tail latency matters more than peak throughput.
Whether the monolithic die is the right long-term call is genuinely debatable — chiplets exist for good economic reasons — but the design thesis is internally consistent.
What the early benchmarks actually say
There are essentially three tiers of public performance evidence for Vera right now.
NVIDIA’s own claims. The most-cited numbers come from the NVIDIA technical blog and the Vera launch press release: up to 50% faster agentic sandbox performance compared to “competitive x86 platforms,” more than 22,500 concurrent sandboxes per Vera CPU Rack, and 2× better performance per watt at the rack level. These are useful directionally but, like all vendor numbers, should be read as best-case marketing comparisons rather than independently audited results.
Redpanda’s early benchmark. Redpanda published a detailed performance writeup on Kafka-compatible streaming workloads using early-access Vera hardware against AMD EPYC Turin and Intel Xeon 6 Granite Rapids systems. Their headline results: about 5.6× lower streaming latency than Turin and 2.7× lower than Granite Rapids on a triple-replicated 24-core cluster case; about 73% higher ring-shuffle SQL throughput at 64 cores than Turin; and Vera latency that actually decreased as the system scaled across more cores, the opposite of what they observed on the comparison platforms. These are real numbers on a real workload, but they are also partner-published numbers on vendor-provided hardware. Treat them as informative, not definitive.
The general benchmark vacuum. As of publication, there is no public SPEC CPU 2017, no public STREAM, no public MLPerf CPU inference submission, and no third-party reviewer with sustained, normalized access to Vera silicon. The independent record is essentially Redpanda plus ServeTheHome’s hands-on architectural walkthrough, and that’s it.
That’s not a criticism — it’s normal for a part that ships to partners in H2 2026. But it does mean the broad “Vera vs. EPYC vs. Xeon” conclusion you’ll see in some social-media takes is, today, premature.
Where Vera helps inference
The cleanest mental model is to ask: what part of your inference pipeline is currently CPU-bound?
For high-batch dense decode — the classic benchmark where a Llama-class model is serving thousands of concurrent requests — most of the work has already moved onto the GPU. Vera will not materially change the per-token throughput on those workloads, because the bottleneck isn’t on the host. The accelerator is the bottleneck, and you should compare H100s, H200s, B200s, and Rubin parts.
For low-batch or interactive serving, agentic toolchains, retrieval-augmented generation, vector-database lookups, multi-tenant routing, KV-cache spill management, and pre/post-processing, the picture changes. These workloads are dominated by short-lived CPU-bound tasks where queueing, scheduling, and IPC latency are directly visible to the end user. NVIDIA’s design choices — high per-core memory bandwidth, deterministic tail latency, Spatial Multithreading, coherent CPU-GPU memory via NVLink-C2C — line up well with this profile.
The same logic applies to model families. Transformers benefit indirectly: the math still runs on the GPU, but agentic transformer systems with extensive tool-calling, retrieval, and orchestration see meaningful host-side improvements. CNNs see less benefit because they’re more purely accelerator-bound. Streaming and database-adjacent workloads — Kafka-style pipelines, real-time analytics, embedding-store joins — sit closer to Vera’s sweet spot.
Where Vera helps training
For training, the headline use case is post-training, not pretraining.
Dense pretraining is overwhelmingly GPU-bound. The CPU’s job is to feed the dataloader and stay out of the way. A faster CPU buys you marginal improvements at best.
Post-training — RLHF, RLAIF, code-execution RL, reward model evaluation, agent-tuning sandboxes — is a different animal. As NVIDIA’s own technical blog points out, each RL step requires CPU-side code generation, compilation, execution in a sandbox, evaluation of results, and a feedback signal that closes the loop. If those CPU steps run too slowly, evaluations miss the gradient window and the GPU sits idle. The broader industry has been moving in this direction for at least a year — see, for example, how Poolside trains Laguna models in their RL “virtual gym”, where the model spends extensive cycles solving real software engineering problems in sandboxed environments before considering training complete.
A simple serial-fraction calculation, using NVIDIA’s “up to 1.5×” sandbox claim as illustrative input: if your post-training pipeline is 20% CPU-bound, a 1.5× CPU speedup yields about a 7% end-to-end throughput gain. At 30% CPU-bound, ~11%. At 40% CPU-bound, ~15%. These are not vendor numbers — they’re back-of-envelope Amdahl’s law math — but they’re a more honest framing than “1.5× faster!” implies on its own.
The real-world effect can be larger, because faster CPU work also raises GPU utilization and reduces tail-latency stalls. It can also be smaller if your bottleneck is somewhere else entirely (network, storage, etc.).
Comparison with x86 server CPUs
Treating this as a single ranking is a mistake. It’s better to compare on three axes.
On raw core count, AMD’s EPYC 9965 (192 cores) leads, with Intel’s Xeon 6980P (128 cores) and Vera (88 cores) trailing in that order.
On per-core memory bandwidth, Vera leads substantially — about 2.8× a standard-DDR EPYC 9755 or Xeon 6980P, and still a clear lead even against Xeon 6 configurations using MRDIMM-8800.
On disclosed CPU-side AI throughput, Intel is currently the most explicit, with AMX delivering up to 2,048 INT8 ops/cycle/core and 1,024 BF16/FP16 ops/cycle/core as documented in Intel’s Xeon 6980P specifications. AMD emphasizes full-width AVX-512 on Zen 5 with similar tensor-style instructions. NVIDIA emphasizes FP8-capable SVE2 but has not published direct ops/cycle figures.
That’s a competitive landscape, not a knockout. Vera’s edge sits in workloads where per-active-core feed rate, latency determinism, coherent CPU-GPU memory, and FP8-flavored vector work matter more than raw thread count or matrix throughput.
Comparison with GPUs and AI accelerators
This comparison is essentially category-confused on purpose. Vera is not meant to compete with H100, H200, B200, Gaudi 3, Graphcore Bow, or Cerebras WSE-3. Those parts are accelerators, and on dense tensor math they will dominate any CPU by orders of magnitude — NVIDIA’s H100 page lists 3,958 FP8 TFLOPS dense per SXM module, which no CPU on the market approaches.
Vera’s role is to make those accelerators spend less time idle. If you read it as “the CPU half of a coherent CPU-GPU node,” the comparison stops being apples-to-oranges and starts being useful. In a Vera Rubin NVL72 system, every Rubin GPU is paired with a Vera CPU that can present coherent shared memory and 1.8 TB/s of NVLink-C2C bandwidth — closer to a unified heterogeneous node than the classic PCIe-attached-host model.
For a broader picture of how NVIDIA’s full stack of hardware fits together — including how the Vera CPU pairs with Rubin GPUs in the broader Blackwell-to-Rubin transition — it’s worth thinking about the data center, not the chip, as the unit of compute. That’s the framing NVIDIA itself increasingly uses.
Security, virtualization, and multitenancy
NVIDIA’s product page lists “full confidential computing” across the CPU and connected GPUs as a first-class Vera feature, with hardware-enforced isolation that allows encrypted operation across the CPU-GPU domain. For regulated industries — financial services, healthcare, defense — that’s a meaningful step beyond what’s currently available on most x86 platforms.
Canonical’s announced Ubuntu 26.04 support for Rubin-class systems includes nested virtualization and MPAM (Memory Partitioning and Monitoring), which allows cache and memory-bandwidth partitioning between tenants. Combined with BlueField-4 SmartNICs, which offload management and security work to dedicated Grace-based control cores, the multitenant story looks unusually serious for a first-generation platform.
This is worth flagging because confidential computing has historically been an x86 story (Intel SGX, TDX; AMD SEV-SNP). NVIDIA arriving with a coherent CPU-GPU confidential-compute model from day one changes the procurement conversation for buyers who care about regulated workloads.
Software ecosystem and migration
Here’s the good news, and it’s genuinely good: there is no new CPU programming model to learn.
The NVIDIA technical blog and the Grace-era ecosystem documentation are consistent that the workflow is standard Linux on Arm: GCC, LLVM, standard package managers, normal Linux distributions, and the usual containerized application stacks. Major Linux distros (RHEL, Ubuntu, SUSE), major AI frameworks, and major orchestration platforms run unmodified on Arm v9.2 systems.
For GPU work, the path stays familiar. TensorRT and TensorRT-LLM remain GPU inference technologies. Moving from an x86+GPU server to a Vera+GPU server is mostly a host migration, not a rewrite of your inference stack. If your production system already runs on CUDA, TensorRT-LLM, Triton, or NIM microservices, the work is in validating Arm container images, host dependencies, and control-plane binaries — not porting kernels off the GPU.
Profiling support is reasonable for a first-generation platform. Nsight Systems supports Arm-SBSA servers, and the broader Arm performance ecosystem (Arm Performance Libraries, Arm Forge, PAPI, perf) is mature.
The friction points are predictable:
- x86-only binaries. Closed-source agents, vendor plugins, or operational tooling that assumes x86 will need Arm builds or vendor cooperation.
- Custom CPU optimizations. AVX-512-tuned hot paths need SVE2 equivalents. Most well-maintained libraries already have them.
- Early platform maturity. The Phoronix kernel scheduler patch series is exactly the kind of thing first-wave adopters should expect to encounter — and budget time to absorb.
If your production stack is already container-portable and CUDA-based, you’re in the lowest-friction category. If you depend on x86-only ISVs or custom kernel modules, the migration is real work.
What’s still missing from public disclosure
It’s worth ending on an honest accounting of what we don’t know:
- Process node is not publicly confirmed.
- Clock frequencies, TDP, and public pricing are not disclosed in any official material reviewed here.
- L1 cache sizes and detailed per-precision execution-unit throughput are not published.
- Independent SPEC, STREAM, and MLPerf CPU benchmarks for Vera don’t yet exist publicly.
- Sustained third-party reviews of production silicon at scale are months away.
These gaps are normal for a platform announced months before general availability. They are also the things that will most strongly shape the eventual Vera-vs-x86 conversation. The honest move is to treat current commentary — including this guide — as provisional until the post-shipment evidence comes in.
The practical bottom line
Vera is a serious, internally consistent, and unusually focused CPU design. It is not trying to be the highest-core-count part on the market, and it does not try to compete with accelerators on tensor throughput. What it does try to do — make the CPU side of an AI factory fast, predictable, bandwidth-rich, and coherent with the GPU — is a real problem worth solving, and NVIDIA’s design choices are tightly aligned with that goal.
The early evidence supports the thesis. Redpanda’s streaming benchmark is meaningful, NVIDIA’s architectural disclosures are technically credible, and the platform-level integration with Rubin is a structural advantage no third-party CPU vendor can replicate.
The evidence is not yet complete. Until SPEC, STREAM, and MLPerf CPU numbers exist for Vera — and until independent reviewers spend a few quarters with production silicon — the strongest defensible claim is the one NVIDIA itself makes: this is a CPU designed for the parts of modern AI that aren’t tensor math, and the early signals suggest it does that job well.
For most readers, the practical question is simpler than the benchmark debate. If your workload is dominated by dense GPU compute, Vera doesn’t change your accelerator choice. If your workload spends real time on CPU-side orchestration, agentic loops, RL sandboxes, ETL, or analytics — and especially if you also want coherent CPU-GPU memory and confidential computing in the same node — Vera is worth taking seriously and worth piloting when partner systems arrive in the second half of 2026.