The For You Page isn’t magic. It’s math that refuses to be told what to do.
Introduction: The Algorithm That Feels Like Magic
There is a very specific moment that almost every TikTok user remembers. You’ve been on the app for maybe forty-five minutes. You haven’t followed anyone. You haven’t liked anything. You’ve just been swiping. And then — mid-scroll — a video appears that feels as if it was made for you. Not for your demographic. Not for people your age. For you.
That moment is the reason a brand-new account, posting its very first video, can rack up a million views in twenty-four hours — a feat that is nearly impossible on YouTube, Instagram, or Facebook. As one practitioner put it in an extensive Reddit discussion on r/MachineLearning, “TikTok seems to be the most consistent at scaling audience incredibly fast.”
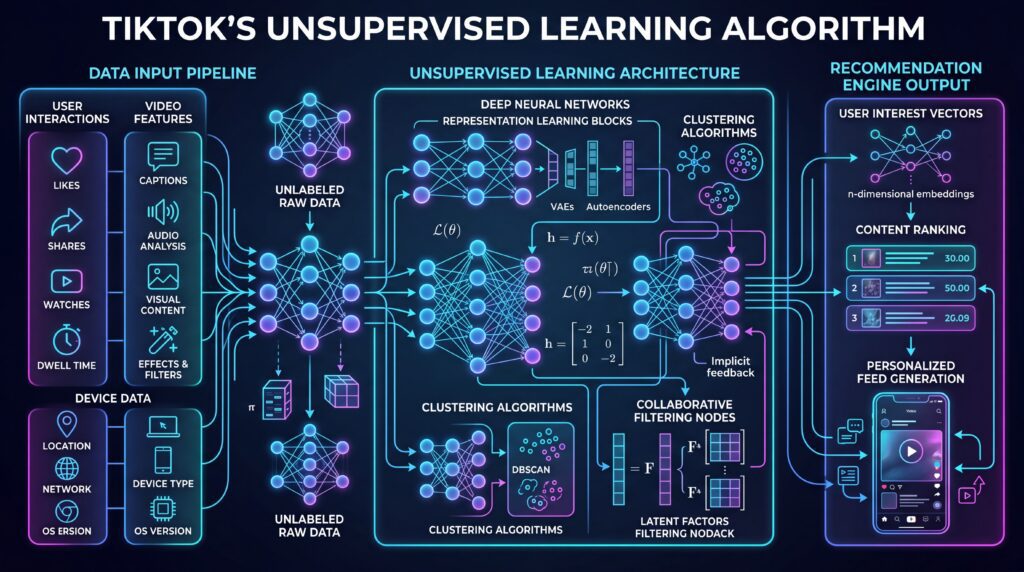
The uncomfortable truth about how TikTok pulls this off is that no one on the team can fully explain any single recommendation. The system that powers the For You Page (FYP) does not work by having engineers define categories like “cooking video” or “dance tutorial” and then matching users to those categories. It works by letting the data organize itself — by clustering videos that behave alike, clustering users who swipe alike, and drawing connections between the two without ever being told what those connections mean.
That paradigm has a name: unsupervised learning. And while TikTok’s public communications focus on the glossy output — the personalized feed, the viral trends — the engine underneath is one of the most aggressive, most successful deployments of unsupervised and self-supervised machine learning in consumer technology today.
This article is a tour of that engine. We’ll start with the basics — how videos get sorted into invisible buckets and pushed into different feeds — and climb all the way up to the foundation models, contrastive embeddings, and real-time collisionless hash tables that ByteDance has openly published. Along the way we’ll look at a case study of a brand-new user’s first fifty swipes, a sidebar on the Monolith paper that ByteDance released in 2022, and the uncomfortable questions about what happens when a system gets this good at reading minds.
Pull quote: “The app wants to keep you there as long as possible.” — The New York Times, reporting on a leaked TikTok internal document (NYT, December 2021)
Part I: Supervised vs. Unsupervised — A Quick Primer for Context
Before we go anywhere, it helps to draw a clean line between the two dominant paradigms of machine learning.
Supervised learning is the familiar one. You hand a model millions of examples, each paired with a correct answer. “This image is a cat. This image is a dog. This email is spam. This email is not.” The model learns to predict the label. It is powerful, it is well-understood, and it has one crippling limitation: somebody has to produce those labels.
Unsupervised learning removes that constraint entirely. You hand the model a pile of raw data — no labels, no answers — and ask it to find structure on its own. It might discover that certain videos tend to be watched by the same kinds of people. It might notice that a cluster of videos all share visual motion patterns even though no human ever tagged them as “fast-paced.” It might detect that a new pocket of content is forming that doesn’t fit any existing category.
There’s a third paradigm worth naming: self-supervised learning, in which the model generates its own labels from the structure of the data itself. “Given the first nine seconds of this video, predict the tenth.” “Given this caption with a word masked out, predict the word.” Self-supervised learning is technically a subset of unsupervised learning, but in modern practice it’s the workhorse that has replaced both.
Why does TikTok lean so heavily on the unsupervised family?
- Scale. Millions of new videos are uploaded every day. The idea that humans could review and label each one in time for it to be useful is laughable.
- Speed. Trends emerge in hours. By the time a human labeler agreed on a new tag (“goblin-mode” or “girl-dinner”), the trend would be dead.
- Diversity. TikTok’s niches are famously strange — #CleanTok, #BookTok, #CoconutGirl. These weren’t invented by TikTok’s engineers. They emerged from user behavior and then the platform’s algorithm surfaced them. That discovery process is only possible when the system is not bound by pre-defined categories.
Supervised learning is still present at TikTok — heavily, in areas like content moderation, copyright detection, and ad policy enforcement — but the core of the FYP is unsupervised all the way down.
Part II: Clustering Videos — The Foundation of the For You Page
Let’s start at the ground floor. When a new video is uploaded to TikTok, the system has seconds — not hours — to understand it well enough to show it to a few people and see what happens.
There is no human in this loop. Instead, three pipelines extract raw signal from the video in parallel, as Mage AI’s breakdown of TikTok’s machine learning stack describes:
- Computer vision reads the frames. Faces, objects, scenes, motion patterns, dominant colors. This is a deep-learning step that, at its base, can itself be self-supervised.
- Natural language processing reads the audio — via transcription — and the on-screen text and captions.
- Metadata is pulled from the creator’s side: hashtags, selected sound, applied effects, and the creator’s own historical fingerprint.
All three pipelines output numerical representations. None of them output a human-readable label. The pipelines produce feature vectors — long lists of numbers that describe the video in a form only another algorithm can use.
Now comes the first unsupervised step: clustering. The system needs to answer a question that has nothing to do with “what is this video about” and everything to do with “what is this video near?”
Several classical unsupervised techniques could do this work, and TikTok almost certainly uses variants of all of them:
- K-means carves the space of all videos into a fixed number of coarse buckets — perhaps a few thousand.
- Hierarchical clustering builds nested niches — dance → hip-hop → choreography tutorial → beginner choreography tutorial.
- DBSCAN detects density — a cluster is a region where videos are packed tightly together, which is exactly how a trend looks when it emerges.
- Gaussian Mixture Models assign soft memberships. A cooking-ASMR video with a cat walking through the frame is 60% #CookTok, 30% #CatTok, 10% ASMR. Nothing is forced into a single bucket.
Here’s the critical insight that is easy to miss: these clusters are not given names. Cluster 4,281 is not called “cozy fall cooking.” It’s just cluster 4,281. TikTok doesn’t need to know what a cluster means in English. It only needs to know which users historically engaged with cluster 4,281, which clusters tend to appear adjacent to it, and how it’s currently trending.
This is the first of many places where TikTok’s system is profoundly unhuman. A content moderator or a marketing team would look at cluster 4,281 and try to name it. The algorithm never bothers. It just treats the cluster as a coordinate.
Let’s look at what the pipeline looks like from raw upload to first impression:
Figure 1: The ingestion pipeline. A raw upload becomes a numerical feature vector in seconds, then gets assigned to a cluster. No human labels are involved.
Once a video has a cluster coordinate, it’s ready for the second half of the system: the users.
Part III: Clustering Users — Turning Behavior Into a Taste Fingerprint
If videos are coordinates, users are also coordinates. And the signals that define a user’s position in taste space are almost entirely implicit.
Slate’s breakdown of the TikTok algorithm enumerates the signals TikTok publicly acknowledges: likes, comments, shares, video completions, re-watches, favorites, followed accounts, and created content. But the loudest signals are the ones users don’t think of as signals at all — how long you paused, whether you scrolled away in the first second, whether you hit mute, whether you swiped back to watch again.
Why are implicit signals so much more powerful than likes? Because they are cheap and ubiquitous. You’ll like maybe 1% of the videos you watch. But every video you see produces a watch-time datapoint. That means the implicit signal stream is two orders of magnitude denser — and machine-learning models love density.
Each user becomes a vector built from millions of these micro-signals. And exactly as with videos, users can then be clustered. “Taste tribes” emerge — groups of users whose behavior patterns rhyme.
The cold-start problem is famously hard in recommendation systems (“we don’t know anything about this new user; what do we show them?”), but TikTok cheats its way out of it. A new user’s very first feed is seeded from device type, language, country setting, IP geography, and the categories they optionally select at sign-up. That’s enough to drop them into a rough cluster. Every swipe from there sharpens the estimate.
And here, quietly, is the optimization target. Again from the leaked internal document cited in the New York Times investigation:
Pull quote: “It has chosen to optimize for two closely related metrics in the stream of videos it serves: ‘retention’ — that is, whether a user comes back — and ‘time spent.'”
Clustering videos and clustering users are the raw ingredients. Retention and time-spent are the reward function. Everything else in this article is engineering to make those three things fit together as tightly as possible.
Part IV: From Clusters to Embeddings — The Representation Revolution
Hard clustering has a fatal weakness: a video is in exactly one bucket. A user is in exactly one tribe. Real taste doesn’t work that way.
The modern answer is embeddings — dense numerical vectors, typically anywhere from 16 to 1,024 dimensions, that capture a video’s or user’s identity as a point in continuous space. Two videos that are “similar” are close together in this space; two videos that are unrelated are far apart. Similarity becomes a matter of geometry rather than category membership.
Critically, these embeddings are learned in an unsupervised (or self-supervised) way. Nobody labels them. They are trained by one of three dominant techniques:
- Autoencoders. A neural network is asked to compress a video into a small vector and then reconstruct the original from that vector. The only way to succeed at this task is to discover compact representations of what matters. Everything unimportant gets discarded.
- Contrastive learning. The model is shown pairs. A user watched video A, then video B. The model is told: pull A and B close together in embedding space. Then it is shown a random unrelated video C and told: push C far away. Repeat a trillion times. The resulting geometry encodes real behavioral similarity, without anyone ever writing down what any of it means.
- Two-tower models. One neural network generates user embeddings; a second generates video embeddings. They’re trained jointly, so that a user’s vector lands close to the videos that user engaged with. At serving time, you look up the user’s current vector and do a nearest-neighbor search in video space.
This is the representation layer that every downstream component speaks. Ranking, search, ads, TikTok Shop — all of them operate on top of these unsupervised embeddings. If you understand this one layer, you understand 70% of how modern TikTok works.
Figure 2: A simplified two-dimensional projection of the embedding space. Real embeddings have hundreds of dimensions. Videos cluster; users sit in taste space at a specific coordinate; nearest-neighbor search pulls candidate videos.
Sidebar: Monolith — ByteDance’s Open Secret
In September 2022, a team of eleven ByteDance engineers uploaded a paper to arXiv titled “Monolith: Real Time Recommendation System With Collisionless Embedding Table”. It is the closest thing to an official description of TikTok-family recommendation infrastructure that exists in public.
Monolith solves a problem that sounds mundane but is actually the crux of why TikTok feels faster than competitors: how do you update a recommendation model in real time, at the scale of a billion users, without the model’s memory exploding?
Standard deep-learning frameworks like TensorFlow and PyTorch were built for batch training — train for hours on a fixed dataset, then deploy. Monolith, per the paper’s abstract, was built differently:
- Collisionless embedding tables. Traditional recommenders hash user IDs and item IDs into fixed-size tables, which forces unrelated IDs to share embeddings when hashes collide. Monolith uses a Cuckoo HashMap that guarantees each ID has its own slot — at the cost of more complex memory management.
- Online training. A Parameter Server updates the model’s weights from a live stream of user events. The inference servers sync with the training server on a short cadence, which means a user’s behavior in the last few minutes can measurably move their next recommendation.
- Expirable embeddings and frequency filtering. Users or items that go dormant have their embeddings retired, keeping the table size under control even as billions of new IDs pour in.
The paper reports that, on their production workloads, real-time training with 30-minute sync cycles outperformed batch training across every metric they measured. That closes-the-loop effect — where your behavior feeds back into the model that serves you, in near-real-time — is the engineering moat under the algorithm’s “uncanny” feel.
The Monolith codebase is open-source on GitHub, though ByteDance archived the repository in October 2025.
Part V: Collaborative Filtering — The Unsupervised Social Graph
If embeddings give you geometry, collaborative filtering gives you graph. And the two compose beautifully.
The classical formulation, as Swidia’s deep dive on TikTok’s algorithm lays out, has two flavors:
- User–user CF: Find users who behave like you. Recommend what they watched that you haven’t.
- Item–item CF: Find videos that tend to be watched by the same people. Recommend the neighbors of what you just watched.
Both are unsupervised in the pure sense. No labels. No categories. Just a gigantic sparse matrix of “did user i engage with video j?” and a set of mathematical techniques — notably matrix factorization and, more recently, graph neural networks — for decomposing that matrix into latent factors.
The latent factors are themselves unsupervised constructs. Factor 17 might end up corresponding to something vaguely recognizable like “videos that appeal to people who find ASMR relaxing,” but nobody told the model that. The factor just emerged from the pattern of co-engagement.
TikTok’s specific advantage in CF is structural. Because videos are short (seconds to a minute) and the feed is a firehose, a single user generates 10–100x more engagement events per session than they would on YouTube or Netflix. That density is devastating to competitors. It means the co-engagement matrix gets filled in faster, latent factors become crisper, and the inferred taste tribes are more reliable.
Part VI: Self-Supervised Learning — The Quiet Heavyweight
So far we’ve discussed unsupervised techniques that are, loosely speaking, pre-2020 in spirit. The real modern weapon — the one that quietly powers everything from GPT to Sora to, yes, TikTok’s FYP — is self-supervised learning.
The core move is deceptively simple: take a piece of data, hide part of it, and train the model to predict the hidden part from the visible part. Because the hidden part is known ground truth, you get supervision “for free.” No humans involved.
In TikTok’s stack, this shows up in at least three places:
1. Video representation. A model is shown nine seconds of a video and asked to predict the tenth. Or it’s shown a frame with patches masked out and asked to reconstruct them. Or it’s shown the video with no audio and asked to pick the correct audio from a set. Whatever the specific task, the upshot is that the model learns a representation that encodes everything that makes that video what it is — without a single human label.
2. Language on the platform. TikTok analyzes billions of captions and comments. A peer-reviewed 2026 study in Frontiers in Sports and Active Living that analyzed 412 Wushu short videos and 236,627 TikTok comments used BERT-based models — a foundational self-supervised architecture — for both topic clustering and sentiment analysis. That same family of models, at industrial scale, is what TikTok uses to cluster comments, detect sentiment, and extract semantic signal from captions.
3. Behavior sequences. This is the most interesting and least discussed use. If you treat a user’s watch history as a sequence — video 1, video 2, video 3, … — you can train a model to predict video N+1 given videos 1 through N. This is exactly the training objective that powers large language models. The model is never told what any video is “about.” It simply learns the statistical structure of watch sequences, which turns out to capture taste, mood, time-of-day, mid-session drift, and topic momentum with terrifying fidelity.
Pull quote: “Its strategic use of ML has no doubt played a role in their success. TikTok’s use of ML demonstrates the power that good data and a great algorithm can have in connecting users to the content they want to consume.” — John Patrick Hinek, Mage AI blog
Self-supervised learning is the technique that lets one foundation model, trained once on oceans of unlabeled data, power dozens of downstream tasks. Search. Ads. Shop. Trend detection. Creator recommendations. If you’re wondering how TikTok ships so many new features so fast, a big part of the answer is: they’re all standing on the same pre-trained representation.
Part VII: How It All Assembles — The Two-Stage Architecture
Embeddings and clusters are the ingredients. But the actual For You Page is cooked in a classic two-stage pipeline: Candidate Generation followed by Ranking.
Figure 3: The two-stage architecture. Stage 1 narrows billions of videos down to a few thousand candidates using unsupervised techniques. Stage 2 uses supervised models to predict which ones you’ll actually engage with.
Stage 1: Candidate Generation. The system needs to go from “billions of possible videos” to “a few thousand that are plausibly relevant to this specific user right now.” This is where unsupervised work does the heavy lifting. Given the user’s embedding, the system does approximate nearest-neighbor search in video embedding space. It also pulls from item-item collaborative filtering (“users who watched the last video you liked also watched…”), from cluster lookups (“videos in the same cluster as videos this user has historically engaged with”), and from a trending pool.
Stage 2: Ranking. Now supervised learning enters. A large multi-task deep model takes each of the few thousand candidates and predicts several things at once: probability of a like, probability of completing the video, probability of sharing, probability of commenting, predicted watch-time. These predictions are combined into a single score, which sorts the list. A final layer of diversity and safety filters strips out duplicates, injects some exploratory content, and applies content policy.
The exploration layer matters. Not every video you see is predicted to match your taste. TikTok deliberately injects content outside your usual lanes, as the platform itself has publicly acknowledged:
Pull quote: “Bringing a diversity of videos into your For You feed gives you additional opportunities to stumble upon new content categories, discover new creators, and experience new perspectives.” — TikTok Newsroom
That exploration serves a dual purpose. It prevents filter bubbles, yes. But it also feeds the unsupervised layer back upstairs: by showing users videos outside their current cluster, the system discovers new taste connections that the current map doesn’t capture. It’s an unsupervised feedback loop that keeps the map of taste updated in perpetuity.
Part VIII: A Case Study — The First Fifty Swipes
Let’s make this concrete. Imagine a brand-new user — call her Mira — who just installed TikTok. She set her language to English, her country to Canada, and selected “Comedy,” “Cooking,” and “Books” as interests at sign-up. She has never liked, followed, or commented on anything. What happens?
Swipes 1–5. Mira is dropped into the coarsest possible cluster: English-speaking Canadian women 18–34 with comedy/cooking/books as opt-ins. The first five videos are drawn broadly from the trending pool within this demographic. The system is barely recommending; it’s observing. It watches how long Mira lingers on each. The first video is a comedy skit about dating — she swipes away in 2.1 seconds. The second is a cooking video with fast cuts — she watches the full 23 seconds and re-watches.
Swipes 6–15. The scroll-away signal from video 1 and the full-watch + rewatch on video 2 are vastly more informative than anything Mira’s sign-up form said. Her embedding has already shifted — away from relationship comedy, toward food content. The candidate generator starts pulling from the cooking-adjacent embedding neighborhood. By swipe 10, 4 of the 10 videos shown are food-related.
Swipes 16–30. A specific pattern emerges: Mira engages most with cooking videos that have a calm, voice-over style. She skips aggressive, high-volume cooking content. The two are in the same coarse cluster but far apart in fine-grained embedding space. The ranking model picks this up from watch-time differentials. By swipe 20, the fast-cut loud cooking videos have been suppressed.
Swipes 31–40. The exploration layer injects something unexpected — a BookTok video about a novel set in a bakery. Mira watches the whole thing and shares it. A tiny connection has just been made in the embedding space between calm cooking videos and a specific corner of BookTok. This connection wasn’t there before Mira made it.
Swipes 41–50. Mira’s feed has effectively become: calm cooking content, a particular aesthetic of BookTok, and a growing sliver of food-related travel. She has not followed a single account, has liked only two videos, and has commented on none. Her watch-time fingerprint alone has moved her to a specific, reproducible coordinate in taste space. And per the Monolith paper’s design, the model is updating in near-real-time — her behavior in swipe 42 is measurably shaping what she sees in swipe 48.
No human engineer has looked at Mira. No category has been assigned to her. The system has simply done what unsupervised learning does: let structure emerge from behavior.
Part IX: Advanced and Emerging Frontiers
The architecture above is, roughly, the 2022 state of the art. The more recent frontier is wilder.
Multimodal contrastive pre-training. Techniques inspired by OpenAI’s CLIP jointly embed images and text into the same space. For TikTok, the natural extension is to jointly embed video, audio, captions, and comments. When a sound goes viral, the multimodal embedding propagates its signal across every video that uses it — instantly — regardless of topic. This is part of why trending sounds spread across unrelated niches so fast.
Anomaly detection for viral prediction. Viral videos are, statistically, outliers. Unsupervised anomaly-detection techniques can flag videos whose early engagement patterns deviate sharply from their cluster’s norm. If a video in a normally-quiet cluster is suddenly getting 10x the watch-completion rate, that’s a viral signal before it becomes viral in raw view counts. The system can lean in, giving it more distribution, in some cases hours before a human would notice.
Online and dynamic clustering. Clusters are no longer static. They shift hour-by-hour as behavior evolves. A cluster that was “summer vacation content” in July becomes something subtly different in August. Systems like Monolith’s real-time training are what make this continuous re-shaping feasible.
Cross-lingual, cross-cultural embeddings. A K-pop dance cover performed in Seoul and a cover of the same choreography performed in São Paulo end up near each other in embedding space even though they share no captions or hashtags in common. This is the power of visual and audio features, learned self-supervised, transcending text.
Creator-side applications. The same embedding infrastructure powers creator tools: style-matching for brand partnerships, collaboration recommendations, and — more controversially — distribution-prediction APIs that help creators understand their own cluster assignment.
Pull quote: “What sets TikTok’s recommendation algorithm apart is its commitment to continuous improvement. The algorithm is designed to evolve dynamically, learning from both mistakes and successes.” — Swidia, “A Deep Dive into TikTok’s Algorithm”
Part X: The Cost of a Mind-Reading Feed
A system this good at reading behavior is also this good at exploiting it. That sentence is not hyperbole — it’s a direct consequence of the architecture.
Rabbit holes. When the optimization target is watch-time, and the embedding space captures fine-grained emotional response, the system will identify and lean into content patterns that produce engagement regardless of whether that content is healthy. Eating-disorder content, self-harm content, radicalization content — every investigation into every major platform has shown the same dynamic, and TikTok is not exempt. The Wall Street Journal’s 2021 investigation found that accounts set up to simulate minors were served increasingly extreme content within hours.
Opacity. When no cluster has a name and no embedding dimension is interpretable, nobody — not the safety team, not the legal team, not even the ML team — can answer “why did this user see this video?” in a way that is technically precise. The honest answer is: “because their vector was close to that video’s vector in a 256-dimensional space.” That is not a defensible answer in a regulatory hearing.
Manipulation. Bad actors reverse-engineer the cluster map. Coordinated inauthentic behavior — bot networks that watch, like, and share in specific patterns — can poison the embedding space, pulling content into clusters where it wouldn’t naturally belong.
Regulatory pressure. The EU’s Digital Services Act now requires large platforms to offer a non-personalized feed option and to be auditable with respect to systemic risks. Ongoing legislative debate in the United States over TikTok’s ownership has focused, in part, on the fact that the recommendation system is so opaque that even auditing it is a research project in itself. The unsupervised core — the very thing that makes TikTok’s feed feel magical — is also the thing regulators find most alarming.
The unsupervised paradigm, in other words, is a Faustian bargain. It scales beautifully. It handles novelty. It generalizes. And it is nearly impossible to govern.
Conclusion: Unsupervised Learning as the Real Moat
The marketing story of TikTok is about trends, creators, and virality. The engineering story is something quieter and stranger: an infrastructure built on the insistence that data should organize itself.
Every headline feature — the For You Page, search, trends, TikTok Shop, creator tools, ad targeting — sits on top of unsupervised and self-supervised representations. The clustering of videos is unsupervised. The clustering of users is unsupervised. The embedding spaces that replaced those clusters are learned self-supervised. The collaborative filtering signal is unsupervised. The foundation models that power multimodal understanding are self-supervised. The real-time infrastructure that keeps all of this fresh — ByteDance’s Monolith — is an engineering achievement in service of that same unsupervised paradigm.
The competitive moat isn’t any single algorithm. It’s the pipeline: raw data → embeddings → clusters → candidate generation → ranking → served feed → new data → updated embeddings, on a loop that now measures in minutes rather than days.
Looking forward, the convergence is obvious. The same self-supervised objectives that trained GPT and Claude — predict the next token, reconstruct the masked region, align modalities — are converging with the training objectives used in TikTok’s stack. It is not a stretch to imagine a near future in which TikTok’s recommender is, architecturally, indistinguishable from a large language model, with video embeddings in place of word tokens and user sessions in place of sentences.
Every other social platform has noticed. Instagram Reels, YouTube Shorts, X’s For You feed — all have reoriented around copies of the two-stage architecture described above. The unsupervised paradigm has already won. The only question left is whether we, as users and as a society, have figured out how to live with an intelligence that knows what we want before we do.