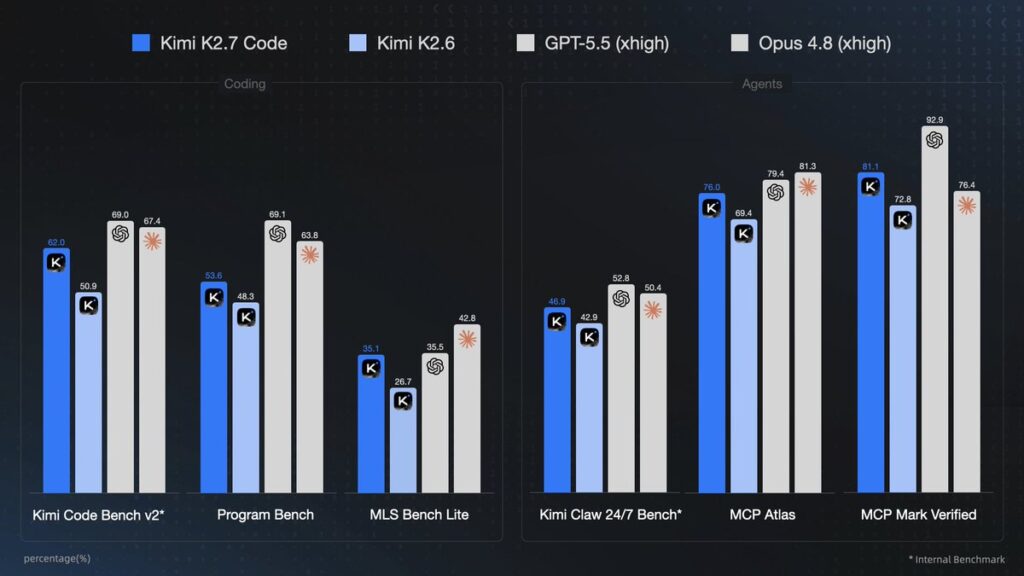
Disclosure: Moonshot AI’s Kimi K2.7 Code benchmark table is first-party. I use it because it is the only detailed release-day table available from a primary source, but I label it as company-reported and avoid treating it as an independent leaderboard.
Image note: AI-generated featured image created for Kingy AI.
TL;DR
- Kimi K2.7 Code is real and newly released: Moonshot lists it on the Kimi K2.7 Code Hugging Face model card, the Kimi API quickstart, and the Kimi model list. The original social announcement is here: Kimi_Moonshot on X.
- It is a coding-focused agent model: Moonshot describes it as built on Kimi K2.6, with better long-horizon coding task completion and about 30% lower thinking-token usage versus K2.6.
- Specs: 1T total parameters, 32B activated parameters, 384 experts, 8 selected experts per token, 256K context, native multimodality, MoonViT vision encoder, and native INT4 quantization according to the model card.
- Benchmark story: company-reported results show K2.7 Code beating K2.6 on all six published coding and agentic evals, including +21.8% on Kimi Code Bench v2 and +31.5% on MLS Bench Lite.
- Frontier comparison: in Moonshot’s own table, K2.7 Code does not beat GPT-5.5 on any of the six listed benchmarks; it beats Claude Opus 4.8 on MCP Mark Verified and is close to GPT-5.5 on MLS Bench Lite.
- API price: the official pricing page lists $0.19 per 1M cached input tokens, $0.95 per 1M cache-miss input tokens, and $4.00 per 1M output tokens.
What Moonshot Released
Kimi K2.7 Code is Moonshot AI’s latest coding-specialized Kimi model. The release is not just an API alias: the model weights are available on Hugging Face under a Modified MIT license, and Moonshot says the model can be deployed with vLLM, SGLang, and KTransformers. The Kimi API docs list the API model string as kimi-k2.7-code and describe it as Kimi’s most capable coding model to date.
The important positioning detail is that K2.7 Code is not pitched as a general replacement for every Kimi workload. It is a coding-focused agentic model. Moonshot says it follows instructions more reliably in long contexts, completes coding tasks with higher success rates, supports tool invocation, and does not support non-thinking mode. For readers tracking open-weight releases and coding agents, this sits naturally beside Kingy AI’s open-weight model coverage, AI coding tools coverage, and AI agents coverage.
Specifications
| Spec | Kimi K2.7 Code | Source |
|---|---|---|
| Architecture | Mixture-of-Experts | Hugging Face model card |
| Total parameters | 1T | Hugging Face model card |
| Activated parameters | 32B | Hugging Face model card |
| Layers | 61, including 1 dense layer | Hugging Face model card |
| Experts | 384 experts; 8 selected per token; 1 shared expert | Hugging Face model card |
| Context length | 256K / 262,144 tokens | Kimi API docs |
| Attention / activation | MLA attention, SwiGLU activation | Hugging Face model card |
| Vision | MoonViT vision encoder, 400M vision encoder parameters | Hugging Face model card |
| Inputs | Text, image, and video input in official API; URL-formatted images are not supported in the Kimi docs reviewed | Kimi API docs |
| Thinking mode | Required; disabling thinking causes an API error | Kimi API docs |
| Default max output | 32K tokens / 32,768 | Kimi API docs |
| Sampling constraints | temperature fixed at 1.0, top_p fixed at 0.95, n fixed at 1, penalties fixed at 0.0 | Kimi API docs |
| Deployment | vLLM, SGLang, KTransformers; transformers >=4.57.1 and <5.0.0 | Hugging Face model card |
| License | Modified MIT | Hugging Face model card |
The hardware implication is obvious: this is not a casual laptop model. It activates only 32B parameters per token, but the weight package is enormous. The Hugging Face file listing shows a repository size of roughly 595 GB, which is why K2.7 Code is better thought of as an open-weight frontier-style deployment target or hosted API model, not a small local coding assistant.
Official Benchmarks
Moonshot published six benchmark rows: three coding evals and three agentic/tool-use evals. The table below reproduces the company-reported numbers and links the benchmark names where Moonshot linked public benchmark pages.
| Benchmark | Kimi K2.6 | Kimi K2.7 Code | GPT-5.5 | Claude Opus 4.8 | K2.7 vs K2.6 |
|---|---|---|---|---|---|
| Kimi Code Bench v2 | 50.9 | 62.0 | 69.0 | 67.4 | +21.8% |
| Program Bench | 48.3 | 53.6 | 69.1 | 63.8 | +11.0% |
| MLS Bench Lite | 26.7 | 35.1 | 35.5 | 42.8 | +31.5% |
| Kimi Claw 24/7 Bench | 42.9 | 46.9 | 52.8 | 50.4 | +9.3% |
| MCP Atlas | 69.4 | 76.0 | 79.4 | 81.3 | +9.5% |
| MCP Mark Verified | 72.8 | 81.1 | 92.9 | 76.4 | +11.4% |
Kimi K2.7 Code improvement over K2.6, company-reported
How to Read the Evals
The K2.7 story is strongest when the comparison is against K2.6. It improves across every published row, and the biggest jumps are in coding-specific tests. That supports Moonshot’s claim that the model is a focused coding upgrade rather than a broad rename.
The frontier comparison is more complicated. GPT-5.5 remains ahead of K2.7 Code on all six rows in Moonshot’s own table. Claude Opus 4.8 leads K2.7 Code on five of the six rows, but K2.7 Code beats Opus 4.8 on MCP Mark Verified, 81.1 versus 76.4. On MLS Bench Lite, K2.7 Code is close to GPT-5.5, 35.1 versus 35.5, but still behind Opus 4.8’s 42.8.
Moonshot’s footnotes matter. Kimi K2.7 Code and K2.6 were tested with thinking mode enabled through Kimi Code CLI at temperature 1.0, top_p 0.95, and 262,144-token context. GPT-5.5 was tested in Codex with xhigh mode, and Claude Opus 4.8 in Claude Code with xhigh mode. Those are reasonable agentic tool environments, but they are not the same model host, same UI, or same vendor stack.
Chart: K2.7 vs Frontier Models
Selected benchmark scores: K2.7 Code, GPT-5.5, and Claude Opus 4.8
K2.7 62.0
GPT-5.5 69.0
Opus 4.8 67.4
K2.7 35.1
GPT-5.5 35.5
Opus 4.8 42.8
K2.7 81.1
GPT-5.5 92.9
Opus 4.8 76.4
Pricing and API Details
Kimi K2.7 Code is inexpensive relative to frontier proprietary coding models. The official pricing page lists:
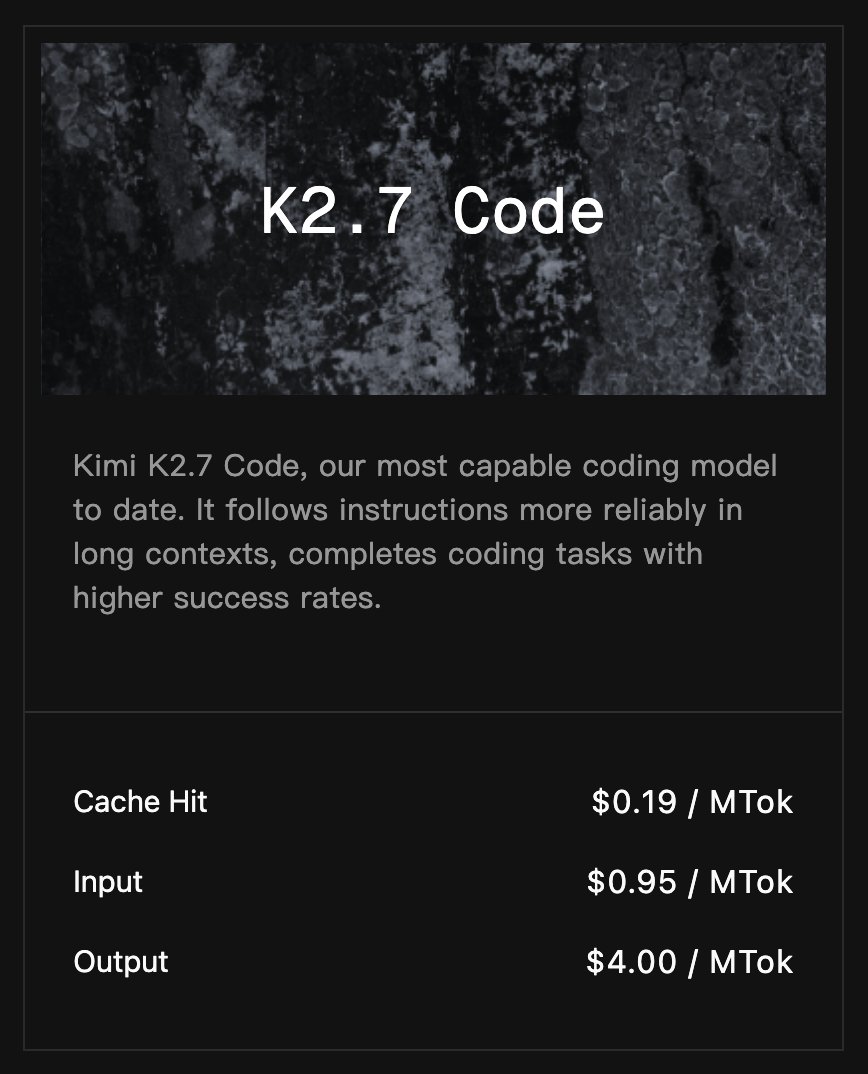
- Cached input: $0.19 per 1M tokens.
- Cache-miss input: $0.95 per 1M tokens.
- Output: $4.00 per 1M tokens.
- Context window: 262,144 tokens.
For comparison, OpenAI’s GPT-5.5 and Anthropic’s Claude Opus 4.8 pricing were not part of Moonshot’s table, so this article does not invent a dollar-for-dollar claim. The safer point is narrower: K2.7 Code looks priced for high-volume coding-agent runs, especially if automatic context caching hits. As with any agent model, real cost depends on retries, tool-loop length, reasoning-token volume, cache behavior, and whether the output actually passes tests.
Comparison With Popular Open-Weight Models
| Model | Openness / license posture | Specs in public docs | Where K2.7 looks stronger or weaker |
|---|---|---|---|
| Kimi K2.7 Code | Weights and code on Hugging Face; Modified MIT | 1T total, 32B active, 256K context, native multimodal coding model | Best direct story is K2.6-to-K2.7 coding-agent improvement. Less independently benchmarked on release day. |
| Kimi K2.6 | Open-weight Kimi predecessor | Kimi docs list 256K context and native multimodal support for K2.6 | K2.7 beats K2.6 on every listed coding and agentic benchmark, but K2.6 remains the broader general Kimi model in the docs reviewed. |
| Qwen3-Coder-480B-A35B | Open model family from Qwen; see the Qwen3-Coder announcement | 480B total, 35B active, 256K native context and up to 1M with extrapolation methods | Qwen3-Coder is a major open coding baseline, but Moonshot’s K2.7 table does not include it, so a direct K2.7-vs-Qwen claim needs a shared benchmark run. |
| Llama 4 Maverick | Open-weight Meta model under the Llama license; see Meta’s Llama 4 announcement | Meta describes Maverick as MoE with 17B active and 400B total parameters | Llama 4 Maverick is more general-purpose and older; it is not in Moonshot’s K2.7 coding-agent table, so avoid direct benchmark claims here. |
| DeepSeek V3.2 family | Popular open-weight reasoning and agent model family; see DeepSeek’s V3.2-Exp announcement | DeepSeek highlights sparse attention and long-context efficiency for V3.2-Exp | DeepSeek remains a major production comparison point, but no release-day K2.7 shared benchmark row was found in the sources reviewed. |
The honest conclusion: among open-weight coding models, K2.7 Code is now one of the models developers should test first. But “test first” is not the same as “declare winner.” Qwen3-Coder, DeepSeek, Llama, and Kimi K2.6 all have different context behavior, licensing terms, deployment ergonomics, quantization paths, and hosting economics. For practical model selection, pair this article with Kingy AI’s AI Coding Foundations for Beginners and the course on MCP, agents.md, and context engineering.
Comparison With Proprietary Frontier Models
Moonshot chose GPT-5.5 and Claude Opus 4.8 as the proprietary frontier comparison set. That is a useful signal: K2.7 Code is being positioned against elite coding-agent systems, not merely against small open models.
Still, the published numbers are not a clean upset. GPT-5.5 is ahead on Kimi Code Bench v2, Program Bench, MLS Bench Lite, Kimi Claw 24/7 Bench, MCP Atlas, and MCP Mark Verified. Claude Opus 4.8 is ahead on five rows and behind K2.7 on MCP Mark Verified. The more defensible headline is: Kimi K2.7 Code narrows the open-weight coding-agent gap, beats its predecessor convincingly, and reaches frontier-adjacent results on several agentic coding evals at a much lower listed API price.
That matters for teams that can tolerate a little more integration work. Proprietary frontier tools still win on polish, enterprise controls, and mature IDE or agent products. Kimi K2.7 Code wins attention because it offers inspectable weights, low API pricing, OpenAI/Anthropic-compatible API access, and deployment flexibility through common inference engines.
Developer Caveats
- Thinking mode is mandatory. The Kimi docs say K2.7 Code throws an error if thinking is disabled.
- Preserve reasoning content in tool loops. Moonshot says multi-step tool calling requires keeping assistant reasoning content from the current turn in context.
- Sampling controls are constrained. K2.7 Code fixes temperature, top_p, n, presence penalty, and frequency penalty to specific values.
- Video support has limits. The Hugging Face model card says video content with third-party vLLM or SGLang APIs is experimental and only supported in the official API for now.
- Benchmarks are early. Independent K2.7 Code leaderboard coverage was not available in the sources reviewed at publication time.
Who Should Try Kimi K2.7 Code?
Try it if you are building coding agents, repo-scale refactor tools, benchmark harnesses, code-review workflows, DevOps assistants, or long-context developer copilots. It is especially interesting if you care about open weights, cost control, and running your own model infrastructure.
Wait or test cautiously if you need a polished general-purpose assistant, strict procurement guarantees, mature enterprise integrations, or independent benchmark confirmation before adopting a new model. The model card is strong, but release-day data is still mostly first-party.
Final Verdict
Kimi K2.7 Code is a serious open-weight coding-agent release. The headline is not that it crushes GPT-5.5 or Claude Opus 4.8; Moonshot’s own benchmark table does not show that. The headline is that K2.7 Code meaningfully improves Kimi’s coding-agent performance over K2.6, cuts thinking-token usage by about 30%, keeps a large 256K context window, ships with open weights, and is priced aggressively for agent workloads.
For builders, the right next move is straightforward: run K2.7 Code against your own private coding tasks, compare it with your current GPT, Claude, Qwen, DeepSeek, or Llama stack, and judge by passed tests per dollar, not benchmark aura. Kimi K2.7 Code has earned a spot in that bake-off.
Sources
- Moonshot AI Kimi K2.7 Code model card on Hugging Face
- Kimi API docs: Kimi K2.7 Code quickstart
- Kimi API docs: Kimi K2.7 Code pricing
- Kimi API docs: model list
- Kimi Code
- Kimi Moonshot announcement on X
- Qwen3-Coder official announcement
- Meta Llama 4 official announcement
- DeepSeek V3.2-Exp announcement
- Program Bench, MLS-Bench, MCP Atlas, and MCPMark
Kingy Launch Brief
Put the week’s verified AI launches in your inbox.
A concise, source-checked briefing on the launches, pricing changes and product moves that matter. Join the pilot list while the first canonical edition is prepared.
Free · Pilot cadence · Unsubscribe anytime · No daily email