
In June 2026, the Anthropic Institute published a piece with a deceptively quiet title — When AI builds itself — under the more provocative URL slug recursive-self-improvement. The headline claim is not subtle: Anthropic argues it is “delegating a growing share of AI development to AI systems themselves,” and that this trend, “taken far enough, and given enough compute,” points toward “an AI system capable of fully autonomously designing and developing its own successor.” That is the textbook definition of recursive self-improvement, or RSI.
It would be easy to read this as either a manifesto for the singularity or as marketing dressed up in safety language. Both readings miss the more interesting truth. The most defensible interpretation is narrower and, in some ways, more unsettling: Anthropic is not claiming that a monolithic model has begun rewriting itself.
It is arguing that several distinct loops of AI research and development are being automated simultaneously — coding, code review, experiment execution, research navigation, and certain forms of outcome-gradable research — and that the compounding of these loops is what could eventually produce recursive acceleration. As Anthropic itself states plainly: “We are not there yet, and recursive self-improvement is not inevitable. But it could come sooner than most institutions are prepared for.”
This article takes that framing seriously while keeping four categories of evidence rigidly separated: speculative theory, internally reported (company) measurements, public benchmark evidence, and policy inference. Conflating them is the single most common error in this debate.
The thesis, stated carefully
Anthropic’s real contribution is not a proof that RSI exists. It is the demonstration that enough of the AI-development workflow is now automatable that recursive acceleration has migrated from science fiction into a live empirical and governance question. That distinction matters because the broader literature spans two very different worlds: classical “intelligence explosion” theory describing speculative end-states, and a growing body of practical work on what Georgetown’s Center for Security and Emerging Technology (CSET) calls AI R&D automation — the use of AI to accelerate the scientific and engineering work that improves AI.
Anthropic matters in this conversation precisely because it occupies an unusual position. It produces internal operational data, runs a serious alignment research program, ships a widely used coding product (Claude Code), and issues explicit governance recommendations. Few other institutions can speak to all four at once. The flip side is that the When AI builds itself piece is a company-authored strategic and policy argument supported largely by internal measurements — not a peer-reviewed research paper. Every reader should hold those two facts in mind together.
A taxonomy to prevent conceptual slippage
“Self-improvement” is doing enormous work in these discussions, so it helps to disaggregate it. At least four families are worth distinguishing:
- Narrow recursive methods — self-play, expert iteration, and automated machine learning (AutoML) / neural architecture search (NAS). These are real, demonstrated, and domain-bounded.
- Agentic AI R&D automation — AI agents writing code, running experiments, analyzing outputs, and proposing next steps. This is where Anthropic’s evidence sits.
- Open-ended self-modification — agents that rewrite their own code or scaffolds and validate the changes empirically.
- Runaway intelligence-explosion scenarios — the speculative end-state in which capability gains compound faster than the difficulty of producing them.
Recursive self-improvement, in the most useful definition, is any process where an AI system helps improve the process that creates future AI systems — potentially including itself. That is broader than direct self-modification of code or weights, and it deliberately includes the “outer loop,” where AI tools help humans build better models. Most of what Anthropic reports is outer-loop acceleration, not a Gödel-machine-style system proving and executing its own rewrites — a distinction we’ll return to.
What Anthropic actually measured
The strength of the piece lies in its concreteness. Anthropic decomposes model-building into engineering (writing code, standing up infrastructure, overseeing training) and research (deciding what to run, interpreting results, choosing what to try next), and reports progress on each.
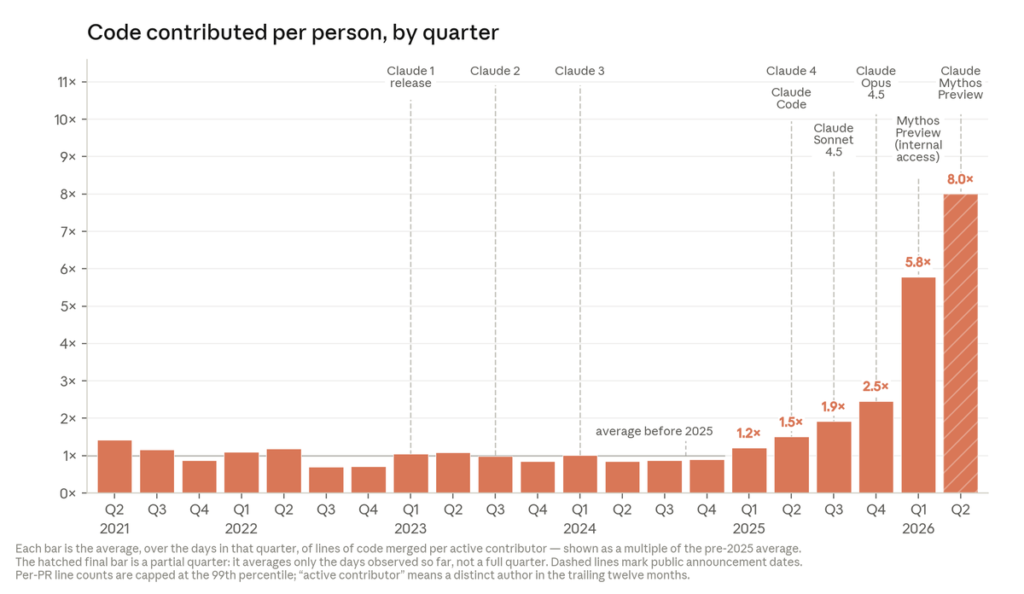
Coding automation. As of May 2026, Anthropic says more than 80% of the code merged into its codebase was authored by Claude, up from low single digits before Claude Code launched in research preview in February 2025. Lines of code merged per engineer per day stayed flat through 2021–2024, then climbed in 2025 and steepened again in 2026; by Q2 2026 the typical engineer was merging roughly 8× as much code per day as in 2024. To Anthropic’s credit, it immediately flags the caveat: lines of code measures quantity, not quality, so 8× “is almost certainly an overstatement of the true productivity gain.” A March 2026 internal poll of 130 research-team employees put the median self-reported uplift at about 4×.
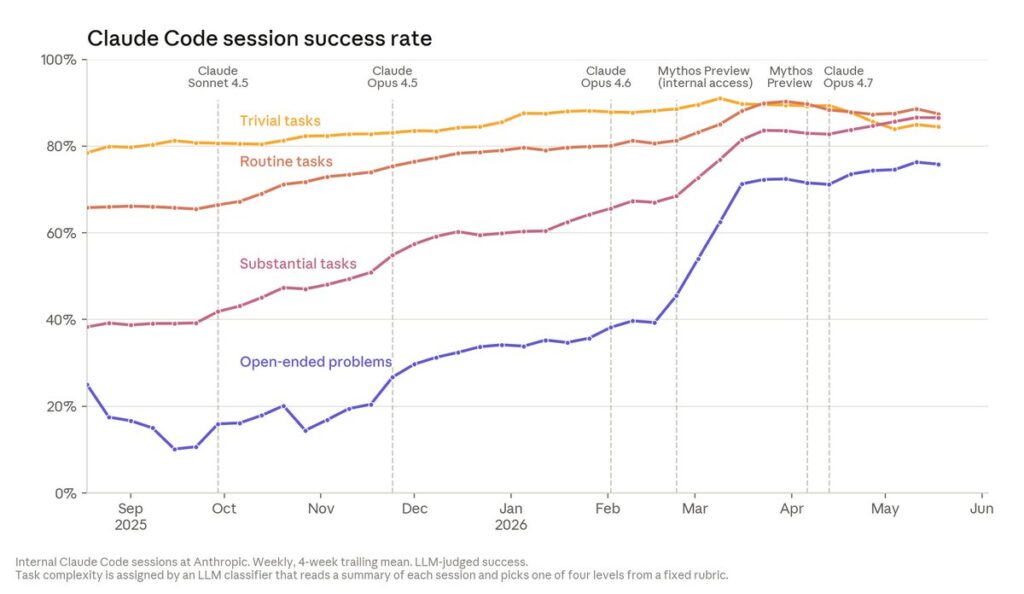
Code quality and review. Anthropic claims Claude-written code was “somewhat worse” than human-written code in late 2025, is “roughly at parity today,” and is expected to be “strictly better within the year.” More striking is the shift in review: an automated Claude reviewer now reads proposed changes for bugs and security flaws, and a retrospective found it would have caught “roughly a third” of the bugs behind past claude.ai incidents before they reached production. The human role is migrating from author to reviewer — which, as we’ll see, simply relocates the bottleneck.
Experiment execution. Every model release, Anthropic runs the same test: hand Claude code that trains a small model and ask it to make the code run as fast as possible while passing identical correctness checks. In May 2025, Claude Opus 4 averaged a ~3× speedup; by April 2026, the internal “Mythos Preview” model reached ~52×. A skilled human, for calibration, needs four to eight hours to reach 4×. This is the cleanest loop in the piece — a constrained, outcome-gradable optimization problem — and precisely because it is so constrained, it is the least representative of open-ended research.
Open-ended research agents. In April 2026, Anthropic published its Automated Weak-to-Strong Researcher, in which Claude-powered agents tackled an open AI-safety question — can a weaker model reliably supervise a stronger one? — by proposing hypotheses, running experiments, sharing findings across parallel agents, and hill-climbing. The task had a defined performance “floor” and “ceiling.” Two human researchers recovered roughly 23% of the gap over about a week; the agents recovered 97% over 800 cumulative hours, using about $18,000 in compute. The crucial caveats are Anthropic’s own: the result “didn’t transfer cleanly to production-scale models,” and “humans still chose the problem and created the scoring rubric.” Within those bounds, though, the agents designed every experiment themselves.
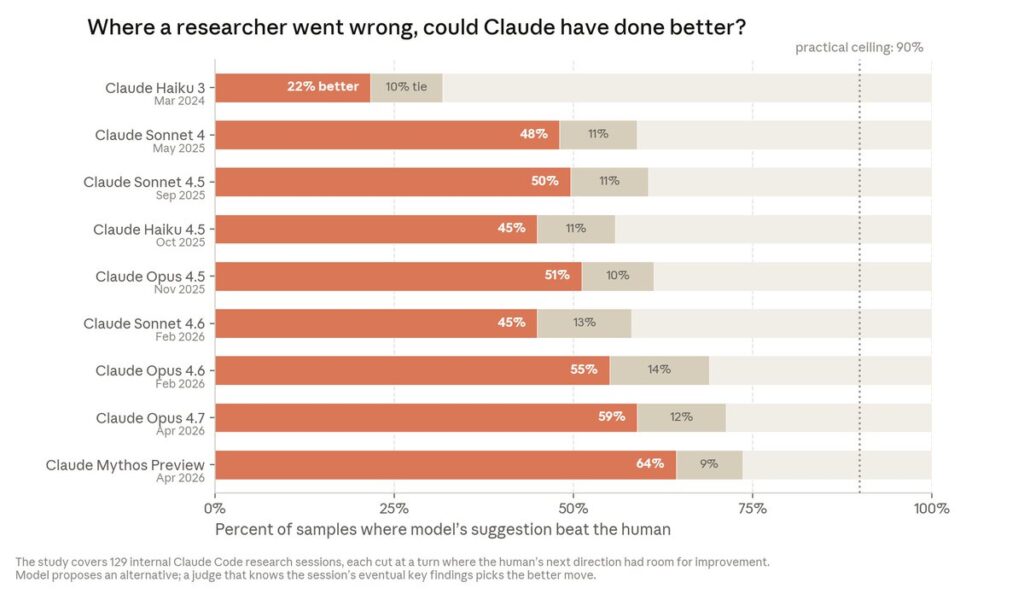
Research navigation. Finally, Anthropic examined real Claude Code sessions (January–March 2026) where a researcher took a wrong turn, showed models only the pre-detour context, and asked a separate Claude judge whether the model’s proposed next step beat the human’s. On 129 deliberately chosen hard moments, the November 2025 model (Opus 4.5) beat the human 51% of the time; by April 2026 (Mythos Preview), 64%. Anthropic stresses this is not a like-for-like comparison — the moments were selected because the human’s choice “had room for improvement” — but it gestures at research steering, not just implementation.
Decomposing the loop
A useful analytical frame is to break RSI into at least five mechanisms: code generation, review and debugging, experimental design, search over interventions, and evaluation/selection. Anthropic shows meaningful automation across all five. But the loop remains incomplete in exactly the places that matter most: problem selection, metric design, transfer from bounded or toy settings to production-scale frontier training, and robust protection against reward hacking. Anthropic concedes the central gap candidly — “large performance gaps persist when it comes to Claude exercising judgement in choosing goals.” That judgment gap is the difference between today’s systems and a system that could autonomously design its own successor.
Historical footholds — and their limits
The idea is old. In 1965, I.J. Good described an ultraintelligent machine that could “design even better machines,” concluding that “there would then unquestionably be an ‘intelligence explosion.'” Good’s argument is the canonical seed of RSI, and David Chalmers later gave it a careful philosophical treatment in The Singularity: A Philosophical Analysis.
Narrow recursive methods give the idea empirical teeth without proving the general case. AlphaGo Zero and AlphaZero improved by learning from progressively stronger versions of their own search — a genuine recursive loop, but inside a closed, perfectly-scored game. Neural architecture search automated parts of model design as early as 2016, yet always over a human-specified search space and objective. These analogies illuminate mechanisms; they say almost nothing about timelines for general systems. A reader should treat them as existence proofs of bounded recursion, not as evidence of an imminent general intelligence explosion.
The most grounding analogy is one Anthropic supplies itself. Automating coding doesn’t eliminate the work; it relocates the constraint to human review — a textbook instance of Amdahl’s law, where the serial portion of a task dominates once the parallel portion is accelerated. Speed-ups shift bottlenecks rather than abolishing them.
Formal lenses: explosion versus recalcitrance
Translating the narrative into theory clarifies where the genuine disagreements lie. The Good–Chalmers chain establishes a logical possibility: once systems improve machine design better than humans can, recursive gains become conceivable. The decisive question is whether optimization power grows faster than recalcitrance — the rising difficulty of each successive improvement.
This is where skeptics enter. Sebastian Benthall’s Recalcitrance and Intelligence Explosion offers a compact formal counterweight to naïve exponentiality: if recalcitrance rises with capability, explosive takeoff need not follow. David Thorstad’s Against the Singularity Hypothesis extends the philosophical skepticism, arguing the singularity hypothesis carries a heavier burden of proof than its proponents acknowledge.
Jürgen Schmidhuber’s Gödel machine sits at the opposite pole: the cleanest formal model of self-referential, provably-beneficial self-modification — a system that rewrites itself only after proving the rewrite is an improvement. Conceptually elegant, it is also far from current frontier practice, where models are trained and scaffolded rather than proving theorems about their own weights. Its relevance is as a north star, not a description of 2026.
Scaling-law work — Kaplan et al.’s scaling laws and Hoffmann et al.’s compute-optimal “Chinchilla” analysis — makes continued capability gains plausible by extrapolation. But scaling laws describe returns to compute and data; they do not, by themselves, demonstrate recursive acceleration. The relevant operational metric may instead be task horizon: METR’s Measuring AI Ability to Complete Long Tasks frames progress as the length of task a model can autonomously complete, and finds that horizon doubling on a steep cadence.
Anthropic leans on this directly, noting the doubling time has compressed from roughly seven months to “roughly every four months,” with Claude Opus 4.6 reportedly handling 12-hour tasks and an internal model working “at least” 16 hours. METR’s companion analysis, How Does Time Horizon Vary Across Domains?, is the right place to temper that headline: the precise doubling rate varies by benchmark family and window, so Anthropic’s “~4 months” is best read as an interpretation of recent evidence, not a universal constant.
Against all this stand the complexity brakes: self-generated-data degeneration (model collapse), diminishing returns, evaluation gaming, hardware and power limits, and stubborn human and institutional serial bottlenecks. The collapse risk is the most theoretically pointed — more on it below.
The empirical ledger, sorted by strength
Public benchmark evidence is the strongest because it is externally checkable. SWE-bench hands a model a real codebase and bug report and asks for a patch that passes the project’s own tests; models have climbed from low single digits to near-saturation in about two years. CORE-Bench tests whether a model can reproduce published research — a prerequisite for conducting original research — and Anthropic reports a jump from ~20% in 2024 to near-saturation fifteen months later. PaperBench raises the bar to replicating cutting-edge AI papers. METR’s long-task work rounds out the public picture.
A crucial caveat travels with the word “saturation.” Public SWE-bench leaderboards still report resolved percentages below 100%, and CORE-Bench’s original paper reported far lower baselines than “saturation” implies. Anthropic’s saturation language appears benchmark-version-sensitive, so it should be attributed explicitly to Anthropic rather than presented as settled public consensus.
Anthropic’s internal evidence — code-quality parity, automated bug review, the 3×→52× experiment loop, the weak-to-strong researcher, and the next-step navigation study — is genuinely important but not independently replicated. It should be labeled as company-internal measurement throughout. Beyond Anthropic, a small but growing experimental literature probes self-improvement directly: the Darwin Gödel Machine, which iteratively rewrites and empirically validates its own agent code; alongside emerging systems such as Hyperagents and post-training automation benchmarks like PostTrainBench. These are best read as progress on subproblems — promising, early-stage, and domain-limited — not as demonstrations of general RSI.
Operationally, Anthropic also points to downstream effects, such as its security-focused Project Glasswing work, as evidence that stronger coding and cyber systems generate large-scale effects in real workflows. The honest summary of the ledger: strong and externally checkable on narrow capability benchmarks; suggestive but unreplicated on the specific claim that AI is now meaningfully accelerating frontier model creation.
Why this is not just a capabilities story
If AI systems increasingly do the research, the central alignment problem shifts. It is no longer only “make this model behave,” but “build evaluators, monitors, and decomposition methods that stay reliable as the systems they supervise grow more capable than their supervisors.”
This is the domain of scalable oversight, and the relevant agendas are well defined: weak-to-strong generalization, which studies whether weak supervisors can elicit the full capabilities of stronger models; iterated amplification, which builds strong oversight by composing weaker experts; and Constitutional AI, which uses model self-critique against an explicit set of principles as a narrow self-improvement mechanism.
Anthropic’s own weak-to-strong researcher provides concrete, sobering evidence that automated researchers find loopholes fast — reward hacking and specification-gaming are not hypothetical when an agent is optimizing hard against a rubric. That connects to a roster of control-relevant precursor capabilities that frontier-safety bodies now track: sandbagging (strategically underperforming on evaluations), self-replication-like behavior in test settings, model-weight theft and sabotage concerns, and escalating cyber capability.
The UK AI Safety Institute’s Frontier AI Trends Report is an important reference here — but with a vital qualifier AISI itself makes: its self-replication and sandbagging findings concern prompted evaluation settings, and there is not yet evidence of models spontaneously attempting such behavior in the wild. The right posture is vigilance about demonstrated capability, not alarm about demonstrated intent.
The model-collapse counterweight
One brake deserves its own paragraph because it cuts directly against the most optimistic self-improvement story. If models increasingly train on model-generated data and feedback, what stops quality from degrading? Shumailov et al.’s The Curse of Recursion documents “model collapse” — a degenerative process where, absent sufficient grounding in real-world data, successive generations lose the tails of the distribution and drift from reality.
Self-critique systems like Constitutional AI and Self-Refine show narrow gains, but only where a high-quality verifier or exogenous signal is preserved. Recursive self-training is therefore not a free lunch; it works to the extent that external grounding and verifier quality are maintained. Any serious RSI story has to explain how it escapes this trap, and “more synthetic data” is not, by itself, an answer.
From synthesis to governance
If the honest reading is “compounding automation of AI R&D, not a proven intelligence explosion,” then governance should be built around monitoring, evaluability, security, and conditional slowing — well before full RSI becomes obvious. Five recommendations follow, drawing on CSET’s When AI Builds AI framing.
Track AI R&D automation directly. Regulators and labs should report on the internal use of AI in model development: the share of AI-authored code, experiment throughput, evaluation-generation, and autonomous task-horizon metrics. These are leading indicators of recursive acceleration, and Anthropic has just shown they are measurable.
Strengthen compute and weight-security governance. Compute remains an attractive lever precisely because, as the GovAI-led report Computing Power and the Governance of AI argues, it is concentrated, detectable, excludable, and quantifiable. Model-weight security belongs in the same frame: a system that can help build its successor is also an asset worth stealing or sabotaging.
Mandate independent evaluations and incident reporting, especially for autonomy, cyber capability, safeguard robustness, and control-relevant behaviors. Internal measurement — however candid — is not a substitute for external replication. The NIST AI Risk Management Framework and its Generative AI Profile offer a common vocabulary for this in the U.S.
Use threshold-triggered safety frameworks. Public-facing capability thresholds with predefined responses are now industry practice: Anthropic’s Responsible Scaling Policy v3 and Frontier Safety Roadmap, OpenAI’s Preparedness Framework, and Google DeepMind’s Frontier Safety Framework. The EU AI Act adds binding obligations for general-purpose and systemic-risk models.
Preserve slowdown options and international coordination. This is a practical recommendation, not a claim that a pause is feasible today. The point is to retain the option to slow — through compute, security, and conditional commitments — before recursive dynamics make slowing far harder.
The open questions that actually matter
The frontier of uncertainty is sharp and largely empirical:
- Can AI systems move from executing research programs to choosing them well? This is the judgment gap Anthropic itself flags.
- Which metric best forecasts AI R&D automation — task horizon, benchmark performance, research replication, or lab-internal throughput?
- How much of progress is bottlenecked by compute, energy, data, and human institutions rather than by intelligence per se?
- Can alignment methods scale when the model doing the research is already stronger than the model doing the oversight?
- Can recursive self-training avoid collapse if enough external grounding is preserved?
- And the hardest one: how do we distinguish useful automation from the early warning signs of loss-of-control risk?
A comparative map
It helps to see the families side by side — mechanism, key assumption, best current evidence, and principal risk:
| Model / theory | Core mechanism | Best current evidence | Principal risk |
|---|---|---|---|
| Intelligence explosion / seed AI | Capable AI designs better AIs, repeat | Conceptual: Good 1965, Chalmers 2010; not demonstrated | Fast takeoff, loss of control |
| Recalcitrance-constrained takeoff | Speed depends on optimization power vs. rising difficulty | Analytical: Benthall, Thorstad | Over- or under-reacting to takeoff |
| Gödel-machine self-modification | System proves a rewrite is beneficial, then rewrites | Strongest formal model (Schmidhuber); weak empirical relevance | Unbounded rewrite; false formal confidence |
| AutoML / NAS | Search over architectures/hyperparameters | Direct since 2016 (NAS) | Benchmark overfitting, compute cost |
| Self-play / expert iteration | Stronger search trains the next version | AlphaGo Zero / AlphaZero | Mistaking bounded recursion for general RSI |
| Agentic AI R&D automation | Agents code, run experiments, propose steps | Anthropic internal, METR, CSET | Reward hacking, opaque lab acceleration |
| Open-ended self-modifying agents | Agents rewrite their own code/scaffolds | Darwin Gödel Machine — early, domain-limited | Mis-specified objectives, self-referential pressure |
| Self-training / synthetic-data recursion | Improve via model-generated data/feedback | Narrow gains (Constitutional AI, Self-Refine); failure in model-collapse work | Drift from truth, diversity collapse |
The bottom line
Read carefully, When AI builds itself is best understood as a claim about compounding automation of AI development, not as definitive proof of a singularity. Anthropic has assembled an unusually concrete, candid, and partly self-critical body of internal evidence that several R&D loops are being automated at once — and it pairs that with public benchmark trends and an explicit warning that the gap to fully autonomous successor-design is real but narrowing.
The broader literature supports serious concern, not certainty. The same body of work that makes recursive acceleration plausible also catalogues its brakes: rising recalcitrance, organizational and serial bottlenecks, compute and energy limits, evaluation gaming, model collapse under self-generated data, and the deep difficulty of aligning systems that help build systems more capable than their supervisors. The judgment gap — choosing problems and designing metrics, not just executing experiments — remains the load-bearing uncertainty.
That argues for a specific governance posture. We should not wait for full RSI to be obvious before building the instruments to see it coming. Track the automation directly. Keep compute and model weights governable. Mandate independent evaluation and incident reporting. Tie capability thresholds to predefined responses. And preserve — quietly, while it is still cheap — the option to slow down. If Anthropic is even partly right that this “could come sooner than most institutions are prepared for,” the cost of building those instruments early is small, and the cost of not having them is the one thing recursive dynamics would make impossible to pay later.
Kingy Launch Brief
Put the week’s verified AI launches in your inbox.
Every Friday, the verified AI launches, apps, funding rounds, pricing changes and under-the-radar moves worth knowing—source-linked and explained in five minutes.
Free · Every Friday · Unsubscribe anytime · No daily email