
A deep dive into OpenAI’s latest frontier model — what it does, how it performs, and why it might genuinely change the way we work on computers.
When OpenAI unveiled GPT-5.5 today, they framed it as more than just another incremental model release. In their announcement on X, the company called it “a new class of intelligence for real work and powering agents,” and after combing through the launch materials, benchmark data, and early-tester feedback, that framing actually holds up. GPT-5.5 is not simply a smarter GPT-5.4. It is a model built from the ground up to understand complex goals, use tools, check its own work, and actually carry tasks through to completion — the kind of behavior that transforms an LLM from a clever text generator into something that can meaningfully get computer work done on your behalf.
This article unpacks everything OpenAI shared about GPT-5.5 and its bigger sibling GPT-5.5 Pro: the capabilities, the benchmarks, the real-world use cases from early testers, the new inference efficiency breakthroughs, the cybersecurity safeguards, and what the availability and pricing look like for developers and ChatGPT subscribers alike.
A New Way of Getting Computer Work Done
The central thesis of GPT-5.5, as stated on the official OpenAI announcement page, is deceptively simple: instead of carefully managing every step of a task, you can hand GPT-5.5 a messy, multi-part goal and trust it to plan, use tools, check its work, navigate through ambiguity, and keep going until the task is finished.
That’s a big claim, but OpenAI’s framing is specific. GPT-5.5 excels at:
- Writing and debugging code
- Researching online
- Analyzing data
- Creating documents and spreadsheets
- Operating software
- Moving across tools until a task is finished
As OpenAI posted on X, the gains are especially clear in four domains — agentic coding, computer use, knowledge work, and early scientific research — areas where progress depends on reasoning across context and taking action over time, not just answering a one-shot question.
This is a meaningful shift. Most model releases over the past two years have been judged primarily on one-turn benchmark performance. GPT-5.5’s story is about sustained performance: holding context across large systems, reasoning through ambiguous failures, and carrying changes through the surrounding codebase or workflow.
Intelligence Without the Speed Penalty
One of the most surprising engineering achievements of GPT-5.5 is that it delivers a meaningful step up in intelligence without compromising on speed. Larger, more capable models are usually slower to serve — that’s the well-known tradeoff that has shaped LLM deployment for years.
GPT-5.5 breaks that pattern. According to OpenAI’s release post, it matches GPT-5.4’s per-token latency in real-world serving while performing better across nearly every evaluation OpenAI measured. Just as importantly, it uses significantly fewer tokens to complete the same Codex tasks — making it both more capable and more efficient.
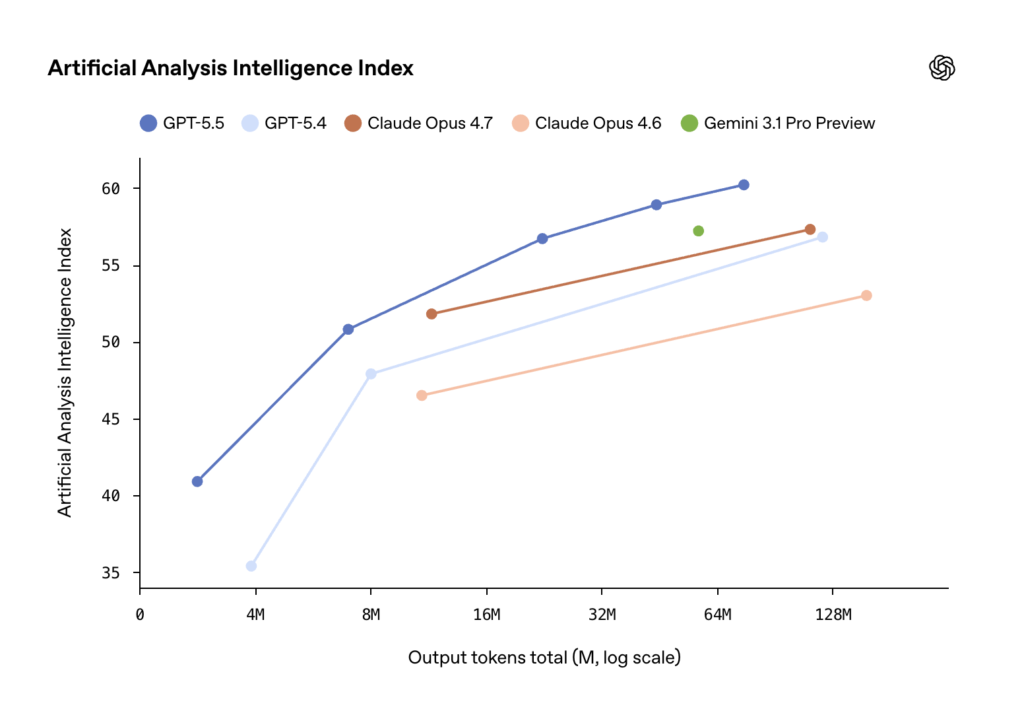
On the economic side, OpenAI highlights that on Artificial Analysis’s Coding Agent Index, GPT-5.5 delivers state-of-the-art intelligence at roughly half the cost of competitive frontier coding models. For teams running large agentic workloads, that kind of cost-efficiency can be the difference between a pilot project and production deployment.
In ChatGPT specifically, full-stack inference improvements enable a more capable model at faster speed. OpenAI says this efficiency is a “game-changer” for GPT-5.5 Pro — a model that was previously impractical for many demanding tasks because of its latency profile, but is now genuinely usable day-to-day.
Agentic Coding: The Strongest Coding Model OpenAI Has Ever Shipped
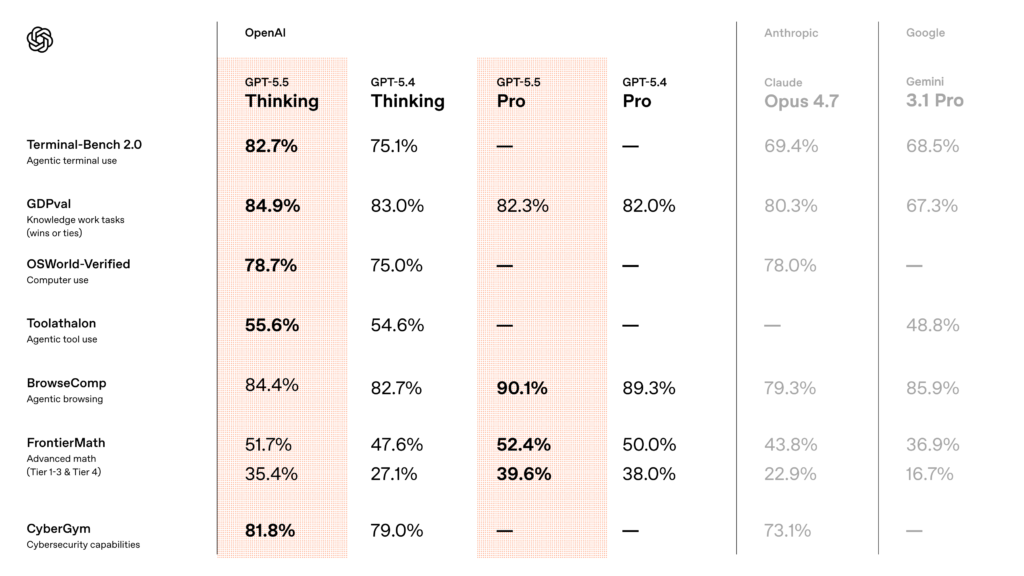
If there’s one domain where GPT-5.5’s improvements are most dramatic, it’s agentic coding. The benchmark numbers speak loudly:
- Terminal-Bench 2.0: 82.7% (up from GPT-5.4’s 75.1%; Claude Opus 4.7 scores 69.4%, Gemini 3.1 Pro scores 68.5%)
- Expert-SWE (Internal): 73.1% (up from 68.5%) — this is OpenAI’s internal frontier eval for long-horizon coding tasks with a median estimated human completion time of 20 hours
- SWE-Bench Pro (Public): 58.6% (up from 57.7%)
Across all three evals, GPT-5.5 improves on GPT-5.4’s scores while using fewer tokens — a double win that translates directly into lower costs and faster turnaround times.
But benchmarks only tell part of the story. What early testers described was qualitatively different: a model that understands the shape of a system — why something is failing, where the fix needs to land, and what else in the codebase would be affected.
Dan Shipper, Founder and CEO of Every, called GPT-5.5 “the first coding model I’ve used that has serious conceptual clarity.” He shared a striking anecdote: after launching an app, he spent days debugging a post-launch issue before bringing in one of his best engineers to rewrite part of the system. To test GPT-5.5, he effectively rewound the clock — could the model look at the broken state and produce the same kind of rewrite the engineer eventually decided on? GPT-5.4 could not. GPT-5.5 could.
Pietro Schirano, CEO of MagicPath, observed a similar step change when GPT-5.5 merged a branch with hundreds of frontend and refactor changes into a main branch that had also changed substantially — resolving the work in one shot in about 20 minutes. “It genuinely feels like I’m working with a higher intelligence, and there’s almost a sense of respect,” he said.
Senior engineers who tested the model said GPT-5.5 was noticeably stronger than both GPT-5.4 and Claude Opus 4.7 at reasoning and autonomy, catching issues in advance and predicting testing and review needs without explicit prompting. In one case, an engineer asked it to re-architect a comment system in a collaborative markdown editor and returned to a 12-diff stack that was nearly complete. Others said they needed surprisingly little implementation correction and felt more confident in GPT-5.5’s plans compared with GPT-5.4.
Perhaps the most memorable quote came from an engineer at NVIDIA who had early access to the model: “Losing access to GPT-5.5 feels like I’ve had a limb amputated.”
Partners including Lovable, Cognition, Windsurf, GitHub, JetBrains, and Sonar have all integrated or tested GPT-5.5. Fabian Hedin, CTO & Co-Founder at Lovable, put the experience simply: “Builders want better outcomes, not endless iteration. With GPT-5.5, the tasks that used to take multiple attempts like authentication flows, real-time syncing, and multi-file edits started landing right the first time. Harder requests were resolved more cleanly, in fewer turns, with less back-and-forth. That’s when building stops feeling like work and starts feeling like magic.”
Knowledge Work: Beyond Coding, Into Everything Else
The same strengths that make GPT-5.5 great at coding translate surprisingly well to knowledge work. Because the model is better at understanding intent, it moves more naturally through the full loop of professional work: finding information, understanding what matters, using tools, checking the output, and turning raw material into something useful.
In Codex, GPT-5.5 outperforms GPT-5.4 at generating documents, spreadsheets, and slide presentations. Alpha testers said it was especially strong on operational research, spreadsheet modeling, and turning messy business inputs into plans. When combined with Codex’s computer use skills, GPT-5.5 brings us closer to the feeling that the model can actually use the computer with you — seeing what’s on screen, clicking, typing, navigating interfaces, and moving across tools with precision.
OpenAI itself is one of the largest internal users. According to the announcement, more than 85% of the company uses Codex every week across functions including software engineering, finance, communications, marketing, data science, and product management. A few concrete internal examples:
- The Communications team used GPT-5.5 in Codex to analyze six months of speaking request data, build a scoring and risk framework, and validate an automated Slack agent so low-risk requests could be handled automatically while higher-risk ones still route to human review.
- The Finance team used Codex to review 24,771 K-1 tax forms totaling 71,637 pages, using a workflow that excluded personal information and accelerated the task by two weeks compared to the prior year.
- On the Go-to-Market team, an employee automated generating weekly business reports, saving 5–10 hours a week.
In ChatGPT, GPT-5.5 Thinking unlocks faster help for harder problems, with smarter and more concise answers. GPT-5.5 Pro takes this further, and early testers reported a significant step up in both the difficulty and quality of work ChatGPT can take on. Compared to GPT-5.4 Pro, testers found GPT-5.5 Pro’s responses significantly more comprehensive, well-structured, accurate, relevant, and useful — with especially strong performance in business, legal, education, and data science.
Knowledge Work Benchmarks
The numbers back up the qualitative feedback:
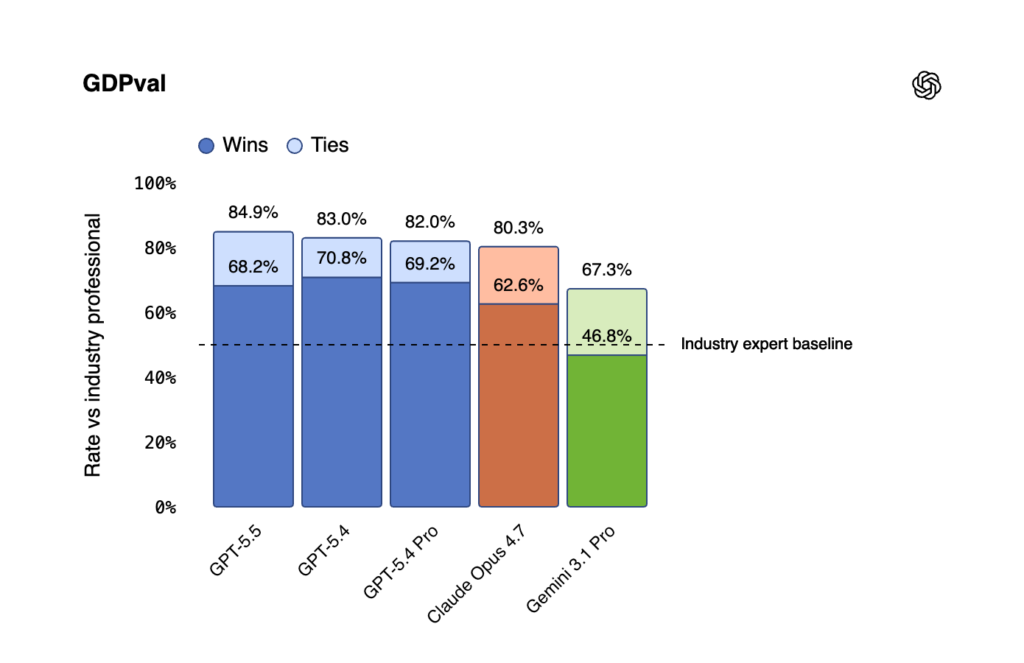
- GDPval (wins or ties): 84.9% — state-of-the-art, beating Claude Opus 4.7 (80.3%) and Gemini 3.1 Pro (67.3%). This benchmark tests agents’ abilities to produce well-specified knowledge work across 44 occupations.
- OSWorld-Verified: 78.7% — measures whether a model can operate real computer environments on its own.
- Tau2-bench Telecom: 98.0% without prompt tuning — a massive jump from GPT-5.4’s 92.8%.
- FinanceAgent v1.1: 60.0%
- Internal investment-banking modeling tasks: 88.5%
- OfficeQA Pro: 54.1%
Justin Boitano, VP of Enterprise AI at NVIDIA, summarized the enterprise view: “GPT-5.5 delivers the sustained performance required for execution-heavy work. Built and served on NVIDIA GB200 NVL72 systems, the model enables our teams to ship end-to-end features from natural language prompts, cut debug time from days to hours, and turn weeks of experimentation into overnight progress in complex codebases. It’s more than faster coding — it’s a new way of working that helps people operate at a fundamentally different speed.”
Other partners testing and deploying GPT-5.5 across enterprise workflows include Cisco, Abridge, Databricks, Harvey, Box, Lowe’s, Glean, Palo Alto Networks, and Ramp.
Scientific Research: A Bona Fide Co-Scientist
One of the most exciting — and most underrated — sections of OpenAI’s launch is on scientific research. GPT-5.5 shows clear gains on scientific and technical workflows, which require more than answering a hard question: researchers need to explore an idea, gather evidence, test assumptions, interpret results, and decide what to try next. GPT-5.5 is notably better at persisting across that loop.
GeneBench and BixBench
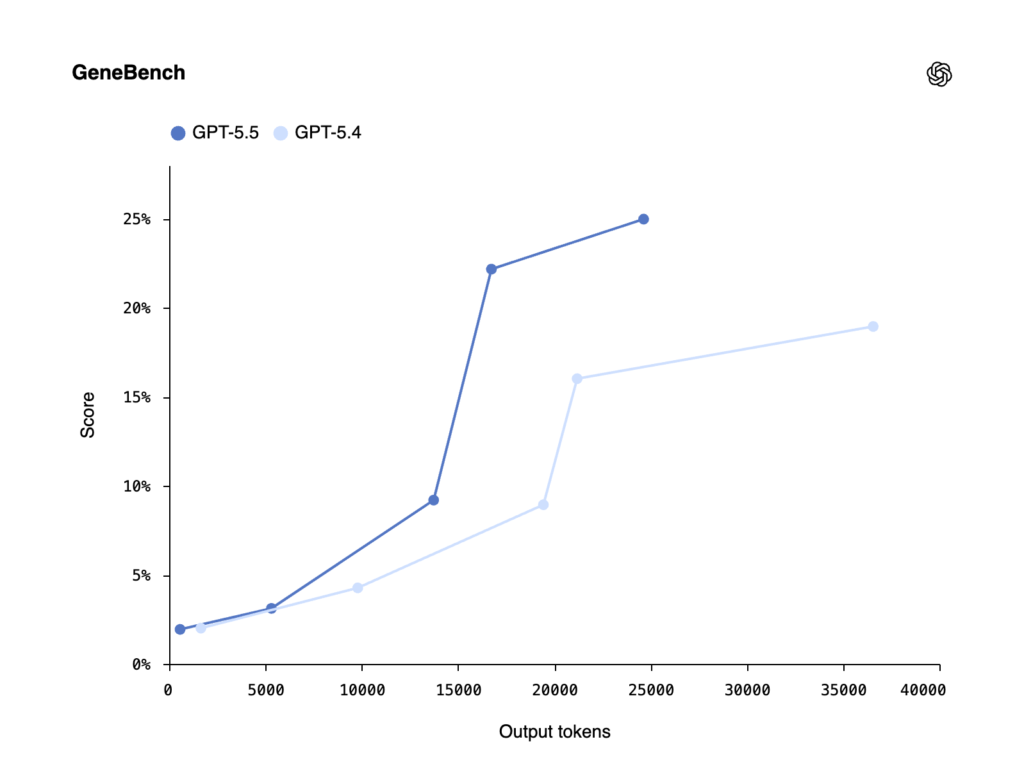
On GeneBench — a new eval focused on multi-stage scientific data analysis in genetics and quantitative biology — GPT-5.5 scored 25.0% vs. GPT-5.4’s 19.0%. GPT-5.5 Pro reaches 33.2%. These tasks often correspond to multi-day projects for scientific experts, requiring models to reason about ambiguous or errorful data with minimal supervisory guidance, address hidden confounders, handle QC failures, and correctly implement modern statistical methods.
On BixBench, a benchmark built around real-world bioinformatics and data analysis, GPT-5.5 hit 80.5% (up from GPT-5.4’s 74.0%) — leading performance among models with published scores.
A New Proof About Ramsey Numbers
Perhaps the most remarkable scientific anecdote: an internal version of GPT-5.5 with a custom harness helped discover a new proof about Ramsey numbers, one of the central objects in combinatorics. Ramsey numbers ask, roughly, how large a network has to be before some kind of order is guaranteed to appear. Results in this area are rare and often technically difficult. GPT-5.5 found a proof of a longstanding asymptotic fact about off-diagonal Ramsey numbers — later verified in Lean. That’s a concrete example of GPT-5.5 contributing not just code or explanation, but a surprising and useful mathematical argument in a core research area.
Real Researchers, Real Workflows
- Derya Unutmaz, an immunology professor and researcher at the Jackson Laboratory for Genomic Medicine, used GPT-5.5 Pro to analyze a gene-expression dataset with 62 samples and nearly 28,000 genes, producing a detailed research report that summarized findings and surfaced key questions — work he said would have taken his team months.
- Bartosz Naskręcki, assistant professor of mathematics at Adam Mickiewicz University in Poznań, Poland, used GPT-5.5 in Codex to build an algebraic-geometry app from a single prompt in 11 minutes, visualizing the intersection of quadratic surfaces and converting the resulting curve into a Weierstrass model. He later extended the app with more stable singularity visualization and exact coefficients reusable in further work.
Brandon White, Co-Founder & CEO at Axiom Bio, put the drug-discovery implications plainly: “It’s incredibly energizing to use OpenAI’s new GPT-5.5 model in our harness, have it reason over massive biochemical datasets to predict human drug outcomes, and then see it deliver significant accuracy gains on our hardest drug discovery evals. If OpenAI keeps cooking like this, the foundations of drug discovery will change by the end of the year.”
Mathematical Benchmarks
Beyond the Ramsey result, GPT-5.5 posts strong mathematical benchmark numbers:
- FrontierMath Tier 1–3: 51.7% (GPT-5.5 Pro: 52.4%)
- FrontierMath Tier 4: 35.4% (GPT-5.5 Pro: 39.6%) — vs. Claude Opus 4.7’s 22.9% and Gemini 3.1 Pro’s 16.7%
- GPQA Diamond: 93.6%
- Humanity’s Last Exam (with tools): 52.2% (GPT-5.5 Pro: 57.2%)
- ARC-AGI-2 (Verified): 85.0% — a substantial jump from GPT-5.4’s 73.3%
Next-Generation Inference Efficiency
One of the more technically fascinating parts of the announcement is how OpenAI actually served GPT-5.5 at GPT-5.4 latency. This required rethinking inference as an integrated system rather than a set of isolated optimizations.
GPT-5.5 was co-designed for, trained with, and served on NVIDIA GB200 and GB300 NVL72 systems. And here’s the fun meta-part: Codex and GPT-5.5 themselves were instrumental in helping OpenAI hit its performance targets. Codex helped the team move faster from idea to benchmarkable implementation — sketching approaches, wiring experiments, and identifying which optimizations were worth deeper investment. GPT-5.5 helped find and implement key improvements in the serving stack. In short: the model helped improve the infrastructure that serves it.
One concrete example: load balancing and partitioning heuristics. Before GPT-5.5, OpenAI split requests on an accelerator into a fixed number of chunks to balance work across computing cores. A pre-determined number of static chunks isn’t optimal for all traffic shapes. Codex analyzed weeks’ worth of production traffic patterns and wrote custom heuristic algorithms to optimally partition and balance work. The result: token generation speeds increased by over 20%.
Long Context: A Clear Win
One quiet but important area where GPT-5.5 shines is long context. On Graphwalks BFS 1M f1, GPT-5.5 scores 45.4% vs. GPT-5.4’s 9.4% — a massive leap. On OpenAI MRCR v2 8-needle at 512K-1M, GPT-5.5 hits 74.0% vs. GPT-5.4’s 36.6% and Claude Opus 4.7’s 32.2%.
For anyone running document-heavy workflows, multi-repo codebases, or long-horizon research tasks, these long-context improvements are arguably as important as the headline benchmark numbers.
Cybersecurity: Capability, Safeguards, and Democratized Defense
Every frontier model release now comes with a cybersecurity story, and GPT-5.5 is no exception. OpenAI is treating GPT-5.5’s biological/chemical and cybersecurity capabilities as “High” under their Preparedness Framework. While GPT-5.5 didn’t reach Critical cybersecurity capability level, evaluations and testing showed a meaningful step up compared to GPT-5.4.
Benchmark numbers:
- CyberGym: 81.8% (vs. GPT-5.4’s 79.0% and Claude Opus 4.7’s 73.1%)
- Internal Capture-the-Flags: 88.1% (vs. 83.7%)
OpenAI’s approach here is notable. Rather than simply gating access, they’re trying to democratize defensive use:
- Industry-leading safeguards: Tighter controls around higher-risk activity, sensitive cyber requests, and protections against repeated misuse. External experts worked for months to test and iterate on the robustness of these safeguards.
- Expanded access through Trusted Access for Cyber: Organizations responsible for defending critical infrastructure can apply for access to cyber-permissive models (including GPT-5.4-Cyber) with fewer restrictions, provided they meet strict security requirements. Verified users can apply at chatgpt.com/cyber to reduce unnecessary refusals for legitimate defensive work.
- Government partnerships: OpenAI is working with government partners to explore how advanced AI can support defensive work — from digital systems that secure taxpayer data to local power grids and water supplies.
OpenAI’s framing is worth quoting directly: “We want powerful AI to be available to the people using it to defend systems, institutions, and the public. The viable path is trusted access, robust safeguards that scale with capability, and the operational capacity to detect and respond to serious misuse.”
Users may find the stricter classifiers around cyber-risk activities “annoying initially,” OpenAI acknowledges — but they’ll be tuned over time. The full safety and governance process for GPT-5.5 included preparedness evaluations, domain-specific testing, new targeted evaluations for advanced biology and cybersecurity, and robust testing with external red-teamers — with roughly 200 trusted early-access partners giving feedback before release.
Availability and Pricing
So who gets GPT-5.5, and what does it cost?
ChatGPT
- GPT-5.5 Thinking: Available to Plus, Pro, Business, and Enterprise users
- GPT-5.5 Pro: Available to Pro, Business, and Enterprise users (designed for harder questions and higher-accuracy work)
Codex
- GPT-5.5: Available for Plus, Pro, Business, Enterprise, Edu, and Go plans
- Context window: 400K
- Fast mode: Available, generating tokens 1.5x faster for 2.5x the cost
API (coming very soon)
- gpt-5.5: $5 per 1M input tokens / $30 per 1M output tokens, with a 1M context window
- gpt-5.5-pro: $30 per 1M input tokens / $180 per 1M output tokens
- Batch and Flex pricing: Half the standard API rate
- Priority processing: 2.5x the standard rate
Availability in the API will roll out after OpenAI finalizes safety and security requirements for serving at scale, working closely with partners and customers.
While GPT-5.5 is priced higher than GPT-5.4, OpenAI emphasizes it is both more intelligent and much more token-efficient. In Codex specifically, the experience has been tuned so GPT-5.5 delivers better results with fewer tokens than GPT-5.4 for most users.
The Full Benchmark Picture
Here’s a consolidated look at how GPT-5.5 stacks up across the evaluations OpenAI published:
| Category | Benchmark | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| Coding | Terminal-Bench 2.0 | 82.7% | 75.1% | 69.4% | 68.5% |
| Coding | SWE-Bench Pro | 58.6% | 57.7% | 64.3%* | 54.2% |
| Coding | Expert-SWE (Internal) | 73.1% | 68.5% | — | — |
| Professional | GDPval (wins or ties) | 84.9% | 83.0% | 80.3% | 67.3% |
| Professional | OfficeQA Pro | 54.1% | 53.2% | 43.6% | 18.1% |
| Computer Use | OSWorld-Verified | 78.7% | 75.0% | 78.0% | — |
| Tool Use | BrowseComp | 84.4% | 82.7% | 79.3% | 85.9% |
| Tool Use | Toolathlon | 55.6% | 54.6% | — | 48.8% |
| Tool Use | Tau2-bench Telecom | 98.0% | 92.8% | — | — |
| Academic | FrontierMath Tier 4 | 35.4% | 27.1% | 22.9% | 16.7% |
| Academic | BixBench | 80.5% | 74.0% | — | — |
| Academic | ARC-AGI-2 | 85.0% | 73.3% | 75.8% | 77.1% |
| Cyber | CyberGym | 81.8% | 79.0% | 73.1% | — |
| Long Context | Graphwalks BFS 1M f1 | 45.4% | 9.4% | 41.2% (Opus 4.6) | — |
*Anthropic reported signs of memorization on a subset of SWE-Bench Pro problems.
What This All Actually Means
Stepping back from the individual benchmarks and testimonials, a few things stand out about GPT-5.5:
1. The “agent” framing is finally grounded in reality. For the past year, “agentic AI” has mostly been a marketing term attached to models that were still fundamentally one-shot responders with tool-use bolted on. GPT-5.5’s combination of long-horizon planning, tool use, self-checking, and genuine persistence — backed by benchmarks like Expert-SWE with 20-hour median human task durations — feels like the first time the capability actually matches the rhetoric.
2. Efficiency is becoming a first-class feature. Matching GPT-5.4’s latency while being substantially smarter, and using fewer tokens on the same tasks, is a meaningful economic shift. The Artificial Analysis comparison — state-of-the-art intelligence at half the cost of competitive frontier coding models — suggests that frontier LLM economics are starting to bend in customers’ favor rather than against them.
3. Scientific research is a frontier worth watching. The Ramsey number proof, the GeneBench gains, BixBench leadership, and the Axiom Bio quote about drug discovery all point to GPT-5.5 as more than a productivity tool. If Brandon White’s prediction holds — that “the foundations of drug discovery will change by the end of the year” — we may look back on this release as one of the inflection points.
4. Cybersecurity access is becoming structured. OpenAI’s Trusted Access for Cyber program, combined with “High” capability classification under the Preparedness Framework, is a template for how the industry will likely handle dual-use capabilities going forward: democratize for defense, restrict for offense, verify identity, and monitor use.
5. The model helping build the model. The fact that Codex and GPT-5.5 helped identify and implement the inference optimizations that make GPT-5.5 fast is a concrete, shipped example of recursive self-improvement in the practical, non-scary sense. It’s also a strong signal that future models will be developed on compressed timelines as the tooling improves.
Final Thoughts
GPT-5.5 is not the kind of release where a single headline capability grabs attention. There’s no dazzling new modality, no Ghibli-style viral moment. What there is, instead, is a model that is measurably better at the full loop of real work: understanding intent, planning, using tools, checking itself, and finishing.
For individual ChatGPT subscribers on Plus, Pro, Business, or Enterprise plans, GPT-5.5 is available today. For developers, the API is coming very soon at $5/$30 per million tokens with a 1M context window. For enterprises running Codex workflows, the efficiency gains alone may justify the upgrade.
And for the broader AI ecosystem, GPT-5.5 is a signal that the frontier is still moving — not in dramatic, paradigm-shifting leaps, but in the steady, compounding way that eventually adds up to a genuinely different working relationship between humans and computers.
If you want to read OpenAI’s announcement in full, check out the introduction blog post and the launch thread on X (post 1, post 2, post 3, post 4).
The era of treating LLMs as chatbots is winding down. The era of treating them as collaborators — real research partners, real engineering teammates, real co-scientists — has quietly arrived. GPT-5.5 is a big part of why.
Kingy Launch Brief
Put the week’s verified AI launches in your inbox.
Every Friday, the verified AI launches, apps, funding rounds, pricing changes and under-the-radar moves worth knowing—source-linked and explained in five minutes.
Free · Every Friday · Unsubscribe anytime · No daily email