Published April 16, 2026 — the day AI’s most rigorous workhorse got a serious upgrade
Anthropic has been on an relentless release schedule in 2026 — roughly a major update every two weeks since January. But today’s launch is different. Claude Opus 4.7 isn’t just an incremental patch. It’s the first version of the Opus line that Anthropic feels confident enough to hand your hardest work, with less supervision. That’s the company’s own language, and it’s a claim worth unpacking.
This is a model that catches its own mistakes before reporting back. It follows instructions with near-literal precision. It can see images at more than three times the resolution of its predecessor. It remembers what happened in previous work sessions. And it ships today on claude.ai, the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry — at the same price as before.
Here’s the full breakdown.
The Context: Where Does Opus 4.7 Sit?
Before diving into capabilities, it helps to understand Anthropic’s current model landscape. The company is running what Dataconomy describes as a “dual-track strategy”: frequent commercial Opus updates for the broad public, while Claude Mythos Preview — its most powerful model, the one with advanced cybersecurity capabilities — stays under tightly controlled access through Project Glasswing.
As CNBC reported today, Opus 4.7 is explicitly described as “less broadly capable” than Mythos Preview. Anthropic isn’t hiding that. What they are saying is that Opus 4.7 is the strongest generally available model they’ve shipped — and in many practical categories, it’s a meaningful leap over Opus 4.6.
The new model also serves a specific safety purpose: it’s the first model where Anthropic has experimentally trained to reduce cyber capabilities, then deployed new safeguards to detect and block high-risk cybersecurity requests. The company says what it learns from Opus 4.7’s real-world deployment will inform how it eventually releases Mythos-class capabilities more broadly.
What’s Actually Better in Opus 4.7?
1. Instruction Following — Finally, Literally
This is the headline capability, and it comes with an important migration warning.
Opus 4.7 is substantially better at following instructions — and by “better,” Anthropic means more literal. Where previous Claude models might loosely interpret a prompt or quietly skip a sub-instruction that seemed inconvenient, Opus 4.7 reads and executes your instructions exactly as written.
That’s great news for structured workflows. It’s a potential headache for anyone who built prompts around Opus 4.6’s more flexible interpretation style. Anthropic explicitly flags this in their notes:
“Prompts written for earlier models can sometimes now produce unexpected results: where previous models interpreted instructions loosely or skipped parts entirely, Opus 4.7 takes the instructions literally.”
The recommendation is clear: re-tune your prompts and harnesses. If your existing setup relied on the model “filling in the gaps” with reasonable assumptions, Opus 4.7 will take those gaps literally — which may or may not be what you want.
For developers building production pipelines, this is welcome clarity. Predictability and precision are exactly what agentic software engineering demands.
2. Vision — 3x the Resolution, Real Multimodal Utility
The multimodal improvement is significant and practical. Opus 4.7 now accepts images up to 2,576 pixels on the long edge — roughly 3.75 megapixels — more than three times the pixel count that prior Claude models could process.
This isn’t a minor quality-of-life update. It unlocks a category of use cases that were previously either unavailable or frustrating:
- Computer-use agents that need to read dense, multi-element screenshots
- Data extraction from complex charts, technical diagrams, or scientific figures
- Professional output like interfaces, slides, and documents that benefit from pixel-perfect visual reference
- Life sciences workflows — Sanj Ahilan, Chief Research Officer at Solve Intelligence, specifically called out improvements in reading chemical structures and interpreting complex technical diagrams
Notably, this is a model-level change, not an API parameter. Images you send will automatically be processed at higher fidelity. The tradeoff: higher-resolution images consume more tokens, so users who don’t need the extra detail should consider downsampling before sending.
One early tester, Aj Orbach (Co-Founder and CEO), was blunt about the visual output quality: “Claude Opus 4.7 is the best model in the world for building dashboards and data-rich interfaces. The design taste is genuinely surprising — it makes choices I’d actually ship.”
The vision upgrade is also why news of Opus 4.7’s development reportedly sent stocks of Adobe and Figma down over 2% before the launch. A model that can design professional interfaces and presentations with high visual fidelity is a direct competitive threat to design tooling incumbents.
3. Real-World Work — Agentic Reliability at Scale
Perhaps the most frequently cited improvement from early testers is Opus 4.7’s behavior in long-running, multi-step work. It doesn’t give up mid-task. It pushes through tool failures that would have stopped Opus 4.6. It verifies its own outputs before reporting back.
Across finance, legal, engineering, and enterprise document workflows, the pattern is consistent:
- Finance: Anthropic’s internal testing showed Opus 4.7 producing more rigorous analyses, more professional presentations, and tighter integration across tasks. It also achieved state-of-the-art on GDPval-AA, a third-party evaluation of economically valuable knowledge work across finance, legal, and other domains.
- Coding: On CursorBench, Opus 4.7 cleared 70% of tasks versus 58% for Opus 4.6. On one internal benchmark, it resolved 3x more production tasks than Opus 4.6, with double-digit gains in code and test quality.
- Document reasoning: Databricks reported 21% fewer errors than Opus 4.6 when working with source information on document analysis tasks.
- Agentic tool use: Notion AI observed 14% improvement over Opus 4.6 at fewer tokens and a third of the tool errors — and called it “the first model to pass our implicit-need tests.”
The cumulative picture is a model that can handle the kind of work that previously needed constant check-ins: running autonomously, handling setbacks, and returning results you can trust.
4. Memory — Multi-Session Context That Actually Works
Opus 4.7 is better at using file system-based memory. This means it can remember important notes across long, multi-session work and apply that context to new tasks without requiring you to re-establish background every time.
In practice, this is the difference between an AI that feels like a capable temporary contractor (who forgets everything between calls) and one that functions more like a persistent team member who carries institutional knowledge forward. The model uses memory to:
- Skip re-establishing context at the start of new sessions
- Move on to subsequent tasks with less up-front setup
- Build on prior work coherently over extended project timelines
This capability is especially relevant for long-horizon agentic use cases — running research pipelines, building software over multiple sessions, or managing ongoing client deliverables.
New Platform Features Launching Alongside Opus 4.7
xhigh Effort Level
Until today, the API offered effort levels ranging from low to high to max. Opus 4.7 introduces a new xhigh level, sitting between high and max. This gives developers finer-grained control over the tradeoff between reasoning depth and latency on hard problems.
In Claude Code specifically, the default effort level has been raised to xhigh for all plans. Anthropic’s recommendation for coding and agentic use cases: start at high or xhigh and tune from there.
Task Budgets (Public Beta)
A new API feature launching today in public beta. Task budgets let developers guide Claude’s token spend across longer runs — essentially giving the model instructions about how to allocate effort and manage costs as it works through extended multi-step tasks. This is a practical necessity for production agentic pipelines where runaway token usage can be a real operational concern.
/ultrareview in Claude Code
Claude Code users get a new slash command: /ultrareview. It launches a dedicated review session that reads through your recent changes and surfaces the kinds of issues a careful human reviewer would flag — bugs, design problems, subtle logic errors.
Pro and Max Claude Code users get three free ultrareviews to test it out. It’s positioned as the AI equivalent of a senior code reviewer sitting down and doing a proper read-through, rather than a linting pass.
Auto Mode for Max Users
Auto mode — which lets Claude make operational decisions on your behalf, enabling longer tasks to run with fewer interruptions — is now extended to Max users. Previously, this was available to a more limited set. The feature is designed to reduce the friction of running long autonomous tasks while maintaining appropriate guardrails, since Claude still evaluates decisions rather than blindly skipping all permissions.
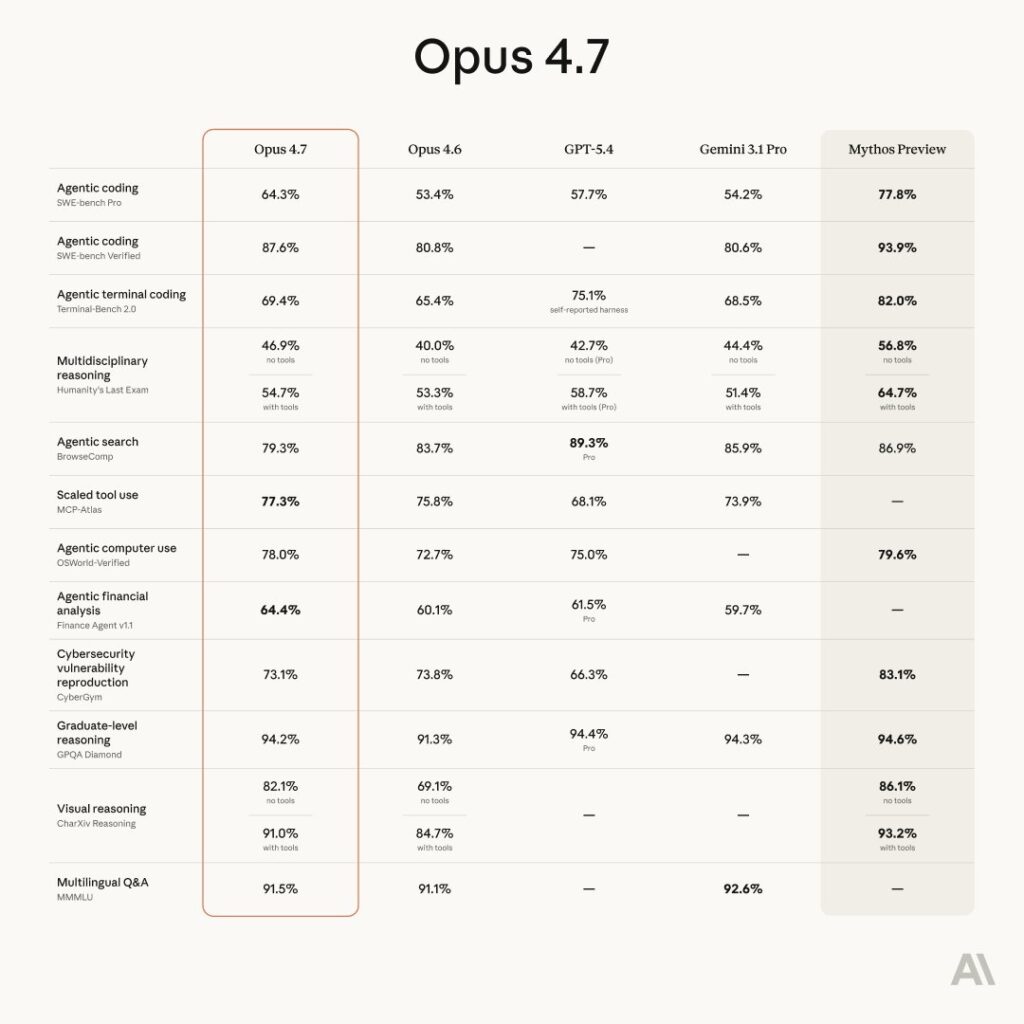
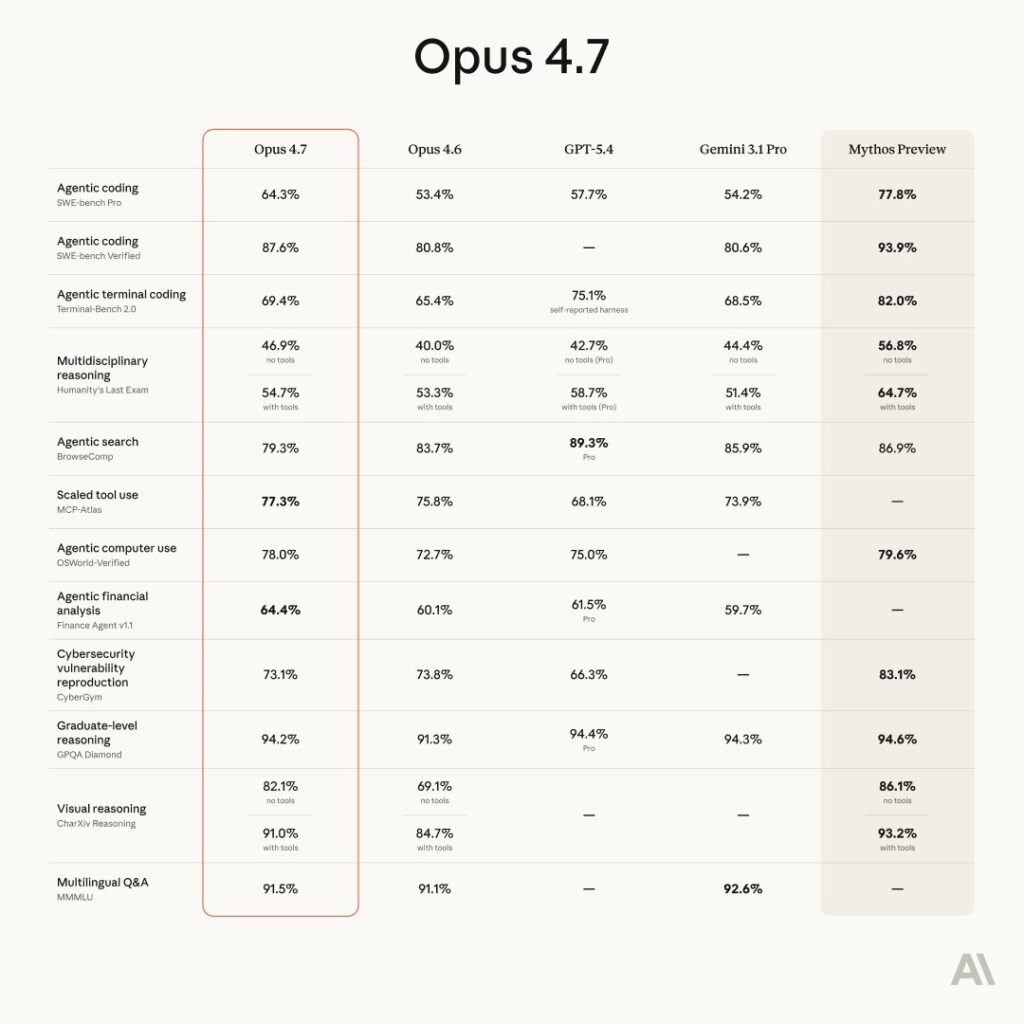
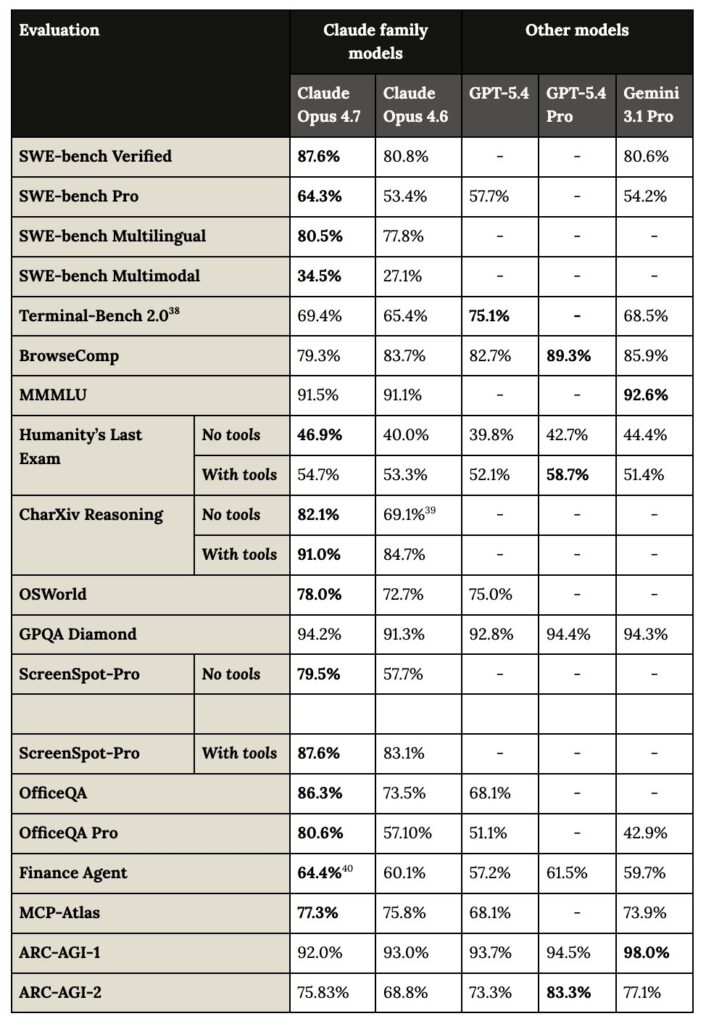
Benchmarks: The Numbers
For those who want to compare directly, here’s a sampling of what Anthropic and third-party testers have reported:
| Domain | Result |
|---|---|
| GDPval-AA (finance, legal, knowledge work) | State-of-the-art |
| Finance Agent evaluation | State-of-the-art |
| CursorBench | 70% vs 58% for Opus 4.6 |
| Databricks OfficeQA Pro | 21% fewer errors than Opus 4.6 |
| Notion Agent multi-step | +14% over Opus 4.6, 1/3 fewer tool errors |
| XBOW visual-acuity benchmark | 98.5% vs 54.5% for Opus 4.6 |
| Rakuten-SWE-Bench | 3x more production tasks resolved |
| Internal agentic coding evaluation | Improved score-per-token at all effort levels |
GitHub Copilot’s changelog notes “stronger multi-step task performance and more reliable agentic execution” in their early testing, and confirmed the model will replace Opus 4.5 and 4.6 in the Copilot Pro+ model picker over the coming weeks.
Safety, Alignment, and the Mythos Relationship
Anthropic is notably transparent about where Opus 4.7 sits on the safety spectrum.
The model shows a similar safety profile to Opus 4.6 overall. On some measures — honesty, resistance to prompt injection attacks — it is an improvement. On others, like a tendency to give overly detailed harm-reduction advice on controlled substances, it is “modestly weaker.”
Anthropic’s own alignment assessment: “largely well-aligned and trustworthy, though not fully ideal in its behavior.”
Importantly, Mythos Preview remains the best-aligned model Anthropic has trained, showing the lowest rates of misaligned behavior across their automated behavioral audit. Opus 4.7 is a modest improvement on Opus 4.6 and Sonnet 4.6 on that same audit, but it doesn’t reach Mythos’s level.
On cybersecurity specifically, Anthropic notes that Opus 4.7’s cyber capabilities were intentionally reduced during training relative to what Mythos can do, and that the model ships with automatic safeguards that detect and block prohibited or high-risk cybersecurity requests. Security professionals doing legitimate work — vulnerability research, penetration testing, red-teaming — can apply to the new Cyber Verification Program to access the model for those purposes.
Migrating from Opus 4.6: Two Things to Plan For
If you’re running Opus 4.6 in production, the upgrade is generally favorable — but Anthropic flags two changes that require deliberate planning:
1. Updated tokenizer. The same input text may map to roughly 1.0–1.35× more tokens than before, depending on content type. Budget accordingly.
2. More thinking at higher effort levels. Especially in agentic settings and on later turns, Opus 4.7 produces more output tokens because it reasons more. This is the source of the reliability improvements — but it has a cost implication.
The net result in Anthropic’s own internal coding evaluation was favorable: improved scores at all effort levels with controlled token usage. But Anthropic’s guidance is to measure the difference on your own real traffic rather than assuming the same economics as before.
Pricing remains $5 per million input tokens and $25 per million output tokens — identical to Opus 4.6. The model is accessible via the identifier claude-opus-4-7 on the API.
Market Context: Why This Release Matters Beyond Benchmarks
The announcement of Opus 4.7 — even before launch — sent ripples through public markets. India Today reported that Adobe, Figma, Wix, and GoDaddy all saw share price declines following pre-launch reporting by The Information. Investors are reading the tea leaves correctly: a model that can produce professional-quality interfaces, slides, docs, and web design from natural language prompts — at higher visual resolution — is a direct competitive threat to the SaaS design stack.
This follows a pattern Anthropic has established in 2026. The Claude Cowork tool earlier this year triggered what some called a “SaaSPocalypse” scare, hitting stocks of enterprise software vendors globally. Each Anthropic release seems to be probing a new vertical.
The design-tool ambitions are real and concrete. Anthropic has partnerships with Figma to convert AI-generated code into editable design files, and Claude is now integrated into Microsoft Word and PowerPoint. Opus 4.7’s higher resolution vision and improved output quality for interfaces and slides makes those integrations substantially more capable.
Real Voices: What Early Testers Are Saying
Beyond benchmark tables, the testimonials from early-access users tell a consistent story. Scott Wu, CEO of Devin, summed it up: “Claude Opus 4.7 takes long-horizon autonomy to a new level. It works coherently for hours, pushes through hard problems rather than giving up, and unlocks a class of deep investigation work we couldn’t reliably run before.”
Michele Catasta, President of Replit, framed it in terms of the human relationship: “Personally, I love how it pushes back during technical discussions to help me make better decisions. It really feels like a better coworker.”
And perhaps most striking: Sean Ward, CEO of a company that builds AI developer tools, reported that Opus 4.7 “autonomously built a complete Rust text-to-speech engine from scratch — neural model, SIMD kernels, browser demo — then fed its own output through a speech recognizer to verify it matched the Python reference. Months of senior engineering, delivered autonomously.”
That’s the headline story, really. Not the benchmark numbers or the tokenizer changes. A model that can do months of senior engineering, check its own work, and hand it back to you.
The Bottom Line
Claude Opus 4.7 is available today. It is Anthropic’s best publicly available model. It follows instructions precisely, sees images at triple the resolution, works reliably across long multi-step tasks, and remembers context across sessions. It ships with new tooling — xhigh effort, task budgets, /ultrareview, expanded auto mode — that makes the agentic use cases it excels at easier to build and manage.
The migration has two gotchas (tokenizer changes, more output tokens at high effort), both manageable with testing. The price is unchanged.
If you’re building with Claude, the upgrade decision is largely straightforward. If you’re a product in the design, legal, finance, or software engineering space — Opus 4.7 is another data point in the trend that’s been spooking software stocks all year. The AI is coming for the hardest parts of knowledge work. And based on today’s launch, it’s getting good at them.
Claude Opus Releases
- Claude Opus 4.7 coding, safety, and honesty update
- Claude Opus 4.8 release analysis
- Claude Opus 4.1 launch tracker
- Claude Opus 4.8 launch tracker
Claude Opus Comparisons
- Claude Opus 4.7 coding upgrade analysis
- Claude Opus 4.8 frontier-model comparison
- Claude Opus 4.6 downgrade analysis
Claude Coding Updates
The Kingy Brief
Get The Kingy Brief.
Every week: what launched, what changed price, and what scored well — built on KALI.
Weekly · Double opt-in · Unsubscribe anytime