MiniCPM5-1B is a compact open-weight language model from OpenBMB, released as the first checkpoint in the MiniCPM5 series. In plain English: it is a small text-generation model designed to run locally, including in resource-constrained environments, while still supporting modern workflows such as long-context prompting, coding assistance, tool use, and optional “thinking” mode.
The official Hugging Face model card describes MiniCPM5-1B as a dense 1B-class causal language model built on the standard LlamaForCausalLM architecture. It has 1,080,632,832 total parameters, 679,552,512 non-embedding parameters, 24 layers, grouped-query attention with 16 query heads and 2 key-value heads, and a context length of 131,072 tokens. It is released under the Apache 2.0 license. (huggingface.co)
That combination is the point. MiniCPM5-1B is not trying to be a frontier cloud model. It is trying to be useful where a very large model is too heavy, too expensive, too slow, too private-cloud-dependent, or simply unnecessary.
The Short Version
MiniCPM5-1B is best understood as a local-first assistant model for developers and builders who care about small footprint, long context, tool calling, and practical deployment.
| Area | What OpenBMB says |
|---|---|
| Model type | Causal language model |
| Architecture | Standard LlamaForCausalLM |
| Parameters | 1,080,632,832 total |
| Non-embedding parameters | 679,552,512 |
| Layers | 24 |
| Context length | 131,072 tokens |
| Modality | Text input, text output |
| License | Apache 2.0 |
| Formats | BF16, GGUF, MLX/4-bit, base, SFT |
Why It Matters
For the last few years, small language models have been awkwardly positioned. They are attractive because they can run closer to the user, but many of them are limited in reasoning, coding, instruction following, long-context handling, or tool use. A 1B model can be easy to run but not necessarily easy to rely on.
MiniCPM5-1B is interesting because OpenBMB is explicitly aiming at that practical gap. The model card says it is designed for “local assistants, coding agents, tool-use workflows, and reasoning scenarios where a compact model is preferred.” It also supports both Think and No Think chat modes from the same checkpoint via the chat template. (huggingface.co)
That last detail matters. Many teams do not always need a model to reason slowly. Sometimes they need fast classification, routing, short answers, JSON-like tool arguments, or a local assistant that can sit inside a workflow without becoming the workflow. Other times, they want a model to spend more tokens on a harder reasoning task. MiniCPM5-1B exposes that tradeoff through enable_thinking.
In the official quickstart, OpenBMB shows enable_thinking=False in the Transformers chat template example and gives separate recommended sampling settings for Think and No Think modes. Think mode is recommended with temperature=0.9, top_p=0.95; No Think mode with temperature=0.7, top_p=0.95. (github.com)
What It Is Not
MiniCPM5-1B is not a multimodal model. It does not natively take images, audio, or video as input. Artificial Analysis explicitly notes that MiniCPM5-1B is text input and text output only, unlike some MiniCPM-V models.
It is also not a guarantee of correctness. OpenBMB’s own limitations section says the model can produce inaccurate, biased, or unsafe outputs, and that generated content should be reviewed before use in high-stakes settings.
That is worth saying clearly because small models can create a false sense of safety. A model that runs locally is not automatically more accurate. It may be more private, cheaper, faster, or easier to customize, but its outputs still need evaluation.
How Good Is It?
The official OpenBMB evaluation table compares MiniCPM5-1B against other small open models, including Qwen3-0.6B Thinking, Qwen3.5-0.8B Thinking, and LFM2.5-1.2B Thinking. OpenBMB reports an average score of 42.57 for MiniCPM5-1B Thinking across its selected benchmark set, compared with 26.77 for Qwen3-0.6B Thinking, 25.14 for Qwen3.5-0.8B Thinking, and 35.61 for LFM2.5-1.2B Thinking. (huggingface.co)
Independent coverage from Artificial Analysis is also positive. On May 26, 2026, Artificial Analysis reported that MiniCPM5-1B Non-reasoning scored 17.9 on its Intelligence Index, ahead of other open-weight models in the sub-2B category at the time of publication. It also reported a 128K context window, BF16 precision, Apache 2.0 licensing, and text-only modality.
One especially practical note from Artificial Analysis: MiniCPM5-1B scored well on AA-Omniscience partly because it abstained instead of guessing on many questions. (artificialanalysis.ai) That is not the same as “the model knows more.” It suggests a behavior pattern that may be useful: the model may be more willing than some peers to decline uncertain answers. For real products, that is valuable only if it holds up in your own domain tests.
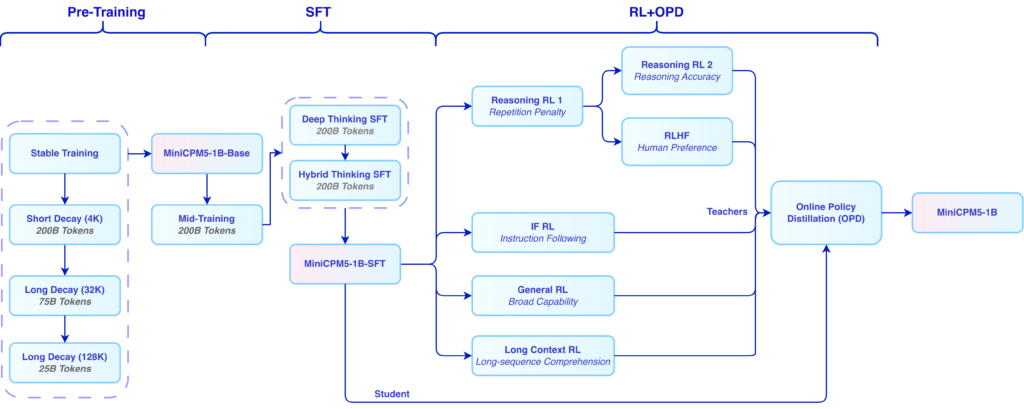
Training Approach
OpenBMB says MiniCPM5-1B was trained through base training, mid-training, and post-training. The model card describes the training as connected to UltraData tiered data management and says the released training corpus includes Ultra-FineWeb, Ultra-FineWeb-L3, and UltraData-Math. (huggingface.co)
For post-training, OpenBMB describes three stages: supervised fine-tuning, reinforcement learning, and On-Policy Distillation. The model card says OpenBMB used 200B tokens of deep-thinking SFT and 200B tokens of hybrid-thinking SFT, then trained specialized RL teachers for math, code, closed-book QA, writing, and related domains before distilling those teachers into the release model. (huggingface.co)
The claimed result of RL plus OPD is also specific: OpenBMB says it raised the average score by 16 points on math, code, and instruction-following tasks while reducing responses that hit the max-token budget by 29 percentage points. (huggingface.co)
That is a meaningful claim, but it should be treated as a model-card result until reproduced independently. The important product takeaway is simpler: MiniCPM5-1B was not only pretrained and instruction-tuned; OpenBMB put visible effort into post-training for reasoning, tool use, and response control.
Deployment Options
MiniCPM5-1B is unusually approachable on the deployment side. Because it uses the standard LlamaForCausalLM architecture, OpenBMB says mainstream inference engines can load it without custom model code or a model-code fork.
The official materials list support for:
| Runtime | Use case |
|---|---|
| Transformers | Local Python inference on CPU or GPU |
| vLLM | OpenAI-compatible server |
| SGLang | OpenAI-compatible server, recommended by OpenBMB for tool calling |
| llama.cpp | GGUF local inference on CPU/GPU |
| Ollama | GGUF local on-device runtime |
| LM Studio | Desktop local inference and local server |
| MLX | Apple Silicon local inference |
| FlagOS | Multi-chip deployment |
For example, the BF16 model can be served with vLLM:
pip install "vllm>=0.21" vllm serve openbmb/MiniCPM5-1B --port 8000
The GGUF version can be run through llama.cpp:
llama-server -hf openbmb/MiniCPM5-1B-GGUF:Q4_K_M
That makes the model accessible to different audiences. Researchers can use Transformers. Backend teams can serve it behind an OpenAI-compatible API. Mac users can try MLX or LM Studio. Local-model users can use GGUF routes.
Tool Calling
Tool calling is one of the more interesting parts of MiniCPM5-1B’s positioning. OpenBMB says MiniCPM5-1B emits XML-style tool calls, and that SGLang’s built-in minicpm5 parser can convert those into OpenAI-compatible tool_calls. (github.com)
That does not mean it will be a perfect agent out of the box. Tool use has to be tested against real schemas, bad inputs, conflicting instructions, and failure cases. But a compact local model that can route tools reliably is useful even if it is not your main “brain.” It can sit in front of larger models, classify tasks, extract structured arguments, decide whether a retrieval call is needed, or handle simple local automations.
In many systems, that is exactly where a 1B model makes sense. You do not always need a huge model to decide which tool to call next. You need a small model that is fast, predictable enough, cheap to run, and easy to replace if it fails evaluation.
Practical Use Cases
MiniCPM5-1B is most compelling where the constraints are real.
A local coding assistant is one example. The model is small enough to experiment with on local hardware, has long-context support, and is explicitly evaluated by OpenBMB across code-related tasks. It will not replace a top-tier coding model for difficult software engineering work, but it may be useful for local codebase navigation, boilerplate generation, simple refactors, command explanation, or routing tasks inside a coding-agent stack.
A document assistant is another plausible use. The 131K context window makes it attractive for long documents, policies, logs, and notes. Long context alone does not guarantee good retrieval or reasoning, but it gives developers room to pass more context directly when that is acceptable.
A privacy-sensitive assistant is also a natural fit. Local inference can reduce reliance on remote APIs. That does not remove the need for security review, but it changes the architecture. Sensitive content can remain on device if the full application stack is designed that way.
Finally, MiniCPM5-1B may be useful as an edge or fallback model. If a cloud model is unavailable, too expensive, or unnecessary, a compact local model can handle lower-risk tasks. This is less glamorous than replacing large models, but more realistic.
Where to Be Careful
The biggest risk is over-reading the benchmarks. MiniCPM5-1B looks strong for its size, but “strong for 1B” is not the same as “strong enough for every job.” You should test it on your actual prompts, languages, documents, tool schemas, latency targets, and hardware.
The second risk is long-context optimism. A 131K token window is valuable, but long-context performance varies by task. Passing a giant prompt is not the same as retrieving the right evidence, following instructions across the whole prompt, or preserving details near the middle.
The third risk is assuming local equals safe. Local models can still hallucinate, follow malicious instructions, leak sensitive context through logs, or produce unsafe outputs. OpenBMB’s model card is direct about the need to review and verify outputs. (huggingface.co)
Bottom Line
MiniCPM5-1B is a serious small-model release: a 1B-class, text-only, open-weight language model with long context, Think/No Think modes, practical deployment paths, and explicit support for local assistant and tool-use workflows.
Its appeal is not that it magically makes small models equivalent to giant ones. It does not. The appeal is that it gives builders a capable, permissively licensed, locally deployable model in a size class where every improvement matters.
For teams building local assistants, coding workflows, tool routers, document helpers, or edge AI features, MiniCPM5-1B is worth testing. The right posture is practical: run your own evaluation, compare it against your current small-model baseline, and decide where its size, context length, and deployment flexibility actually create value.
The Kingy Brief
Get The Kingy Brief.
Every week: what launched, what changed price, and what scored well — built on KALI.
Weekly · Double opt-in · Unsubscribe anytime