Table of Contents
- Introduction
- Foundations of Supervised Learning
- Real-World Examples of Supervised Learning
- Foundations of Unsupervised Learning
- Real-World Examples of Unsupervised Learning
- Key Differences Between Supervised and Unsupervised Learning
- When to Use Supervised vs. Unsupervised Learning
- The Incredible Potential for Future Discoveries
- Conclusion
- Sources
1. Introduction
The ever-evolving realm of machine learning has reshaped numerous aspects of our daily lives—ranging from how we filter spam out of our inboxes, to how we discover music recommendations, to the near-human ability of sophisticated AI systems to decipher complex imagery. Two primary paradigms underscore much of this progress: supervised learning and unsupervised learning. Both approaches reflect different ways of extracting patterns and insights from data, and each has unique advantages, challenges, and domains of application. Yet, despite their distinctiveness, these two methods can often complement one another within large machine learning pipelines.
Machine learning itself is part of the broader field of artificial intelligence, in which algorithms learn representations, rules, and patterns directly from data rather than relying on explicitly programmed instructions. This shift to data-driven reasoning enables the creation of intelligent systems capable of feats once considered the domain of science fiction. From medical diagnoses supported by sophisticated classifiers to algorithms clustering astronomical data to discover exoplanets, the potential applications seem boundless. What makes machine learning so versatile is its ability to adapt to new situations, learn from mistakes, and improve over time—a virtuous cycle of refinement that can be harnessed for incredible breakthroughs.
While the terms “supervised learning” and “unsupervised learning” might sound somewhat abstract, the difference boils down to a core question: Are we telling the algorithm exactly what the desired output is during training, or are we simply letting it explore the data to discover hidden structures? This question transforms into two markedly different learning procedures. In supervised learning, labeled data is key. Labels—such as “spam” or “not spam,” or “dog” vs. “cat”—guide the algorithm to map inputs to outputs. Conversely, in unsupervised learning, no explicit labels exist; the algorithm must unearth latent structures, groupings, or patterns on its own.
In what follows, we will embark on a thorough examination of these two approaches. We will cover everything from the theoretical underpinnings of supervised and unsupervised learning, to their practical real-world use cases, to a direct comparison of their strengths and weaknesses. Finally, we will explore how and when practitioners might choose one approach over the other, as well as the transformative potential that these techniques hold for future discoveries in domains like bioinformatics, astrophysics, autonomous systems, natural language understanding, and more. By the time you reach the end of this article, you will have a robust, in-depth understanding of supervised and unsupervised learning, and how each can be harnessed for projects that shape the next generation of intelligent technologies.

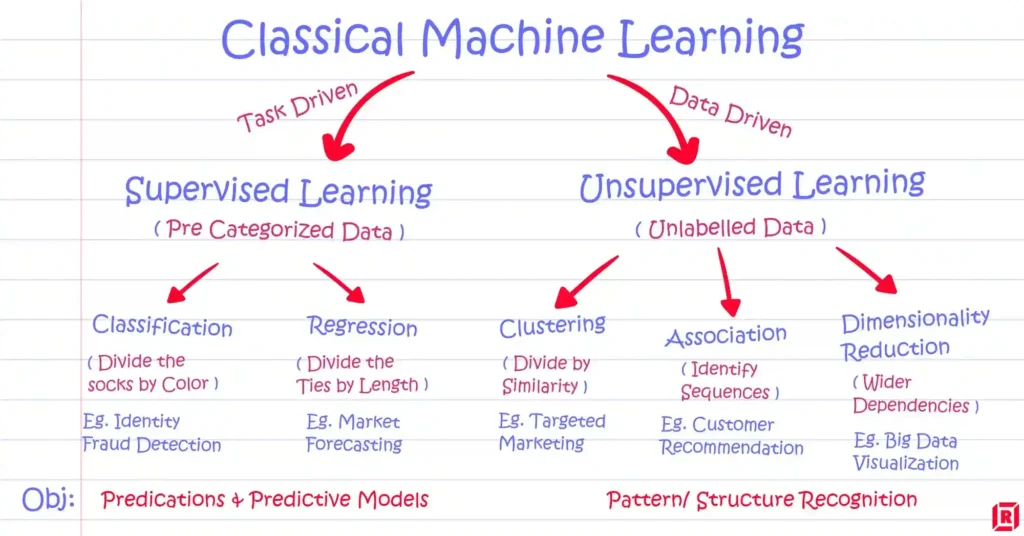
2. Foundations of Supervised Learning
Supervised learning is often described as learning with a “teacher.” This teacher is the labeled dataset itself. For every input, there is a known desired output—be it a class label (in classification tasks) or a numerical value (in regression tasks). The presence of these labels allows the model to learn a mapping from the input to the output. Formally, given a training set of NNN examples {(xi,yi)}i=1N\{(x_i, y_i)\}_{i=1}^N{(xi,yi)}i=1N, where xix_ixi is a feature vector representing the iii-th example and yiy_iyi is the associated label, supervised learning seeks a function fff such that f(xi)≈yif(x_i) \approx y_if(xi)≈yi for all iii.
In simpler terms, if you have a dataset of images of cats and dogs, each labeled accordingly, a supervised learning algorithm (e.g., a convolutional neural network) will learn to predict whether a new image is a cat or a dog. Under the hood, the algorithm processes each training image, makes a prediction, compares that prediction to the ground truth (i.e., the label), and adjusts its internal parameters (weights) to reduce the discrepancy between the prediction and the actual label. Over many iterations, the model gradually refines its predictions.
- Types of Supervised Learning Tasks
- Classification: Predicting a discrete category label, e.g., whether an email is spam or not spam.
- Regression: Predicting a continuous value, e.g., forecasting future stock prices or estimating house prices based on features like location, size, and number of bedrooms.
- Key Algorithms
- Linear Regression: Perhaps the most fundamental method for regression, aiming to fit a linear relationship between variables.
- Logistic Regression: Used for classification tasks, especially in cases where outcomes are binary (e.g., 0 or 1).
- Decision Trees: Provide an intuitive, rule-based classification or regression that splits data based on certain thresholds.
- Random Forests: An ensemble of decision trees that often provides robust performance by averaging multiple trees’ predictions.
- Support Vector Machines (SVM): Effective in high-dimensional spaces, capable of constructing linear or nonlinear decision boundaries.
- Neural Networks: Inspired by the structure of the human brain, especially powerful for image recognition, language processing, and increasingly for time-series data.
- Evaluation and Validation
In supervised learning, model quality is often judged by metrics like accuracy, precision, recall, F1-score (for classification), or mean squared error, mean absolute error, and R2R^2R2 (for regression). Cross-validation, particularly k-fold cross-validation, is a standard method to ensure that models generalize well to unseen data.
Because of the reliance on labeled data, one of the main challenges in supervised learning is acquiring high-quality, sufficiently large labeled datasets. Data annotation can be time-consuming and costly, especially for tasks that require domain expertise (e.g., annotating medical imagery for cancer detection). However, if labels are abundant and of good quality, supervised learning can deliver remarkably accurate and interpretable results, making it the go-to choice for a vast array of real-world applications.
3. Real-World Examples of Supervised Learning
- Image Classification in Healthcare
A notable example of supervised learning in healthcare is in dermatology: deep learning models, such as those built using convolutional neural networks (CNNs) with frameworks like PyTorch or TensorFlow, are trained on labeled images of skin lesions. These models learn to distinguish benign moles from malignant melanomas. Each training image is annotated by expert dermatologists. The final system can assist medical professionals by flagging suspicious lesions for further examination.- Impact: Reduces diagnostic error rates, expedites patient care decisions, and can be scaled to remote or underserved regions through telemedicine platforms.
- Impact: Reduces diagnostic error rates, expedites patient care decisions, and can be scaled to remote or underserved regions through telemedicine platforms.
- Natural Language Processing (NLP): Email Spam Detection
A classical, yet endlessly relevant, application of supervised learning is spam detection. Email providers collect large volumes of labeled emails—marked either as spam or not spam. A supervised algorithm (often using logistic regression, Naive Bayes, or neural networks) learns the patterns indicative of unsolicited content. Whether it is suspicious phrases, blacklisted domains, or unusual frequency of hyperlinks, the model refines its classification rules.- Impact: Protects users from scams, phishing attempts, and general spam overload.
- Impact: Protects users from scams, phishing attempts, and general spam overload.
- Financial Forecasting
In finance, supervised regression models or ensemble methods (like gradient boosting machines) are used to predict stock movements, forecast exchange rates, or estimate credit risk. When labeling data, historical records serve as the ground truth—e.g., a stock’s future closing price.- Impact: Aids investment decisions, risk management, and automated trading strategies.
- Impact: Aids investment decisions, risk management, and automated trading strategies.
- Facial Recognition for Security
Systems like facial recognition in airports or secure facilities are trained in a supervised fashion. A dataset of faces labeled with identities is fed to a deep CNN, and the network learns to associate specific facial features with individuals.- Impact: Enhances security protocols, though it also prompts debates on privacy and ethical usage.
- Impact: Enhances security protocols, though it also prompts debates on privacy and ethical usage.
- Sentiment Analysis on Social Media
Social media monitoring tools frequently rely on supervised NLP techniques to classify the sentiment of user posts or tweets. With labeled examples of positive, neutral, or negative sentiments, the supervised classifier can evaluate public opinion about brands, products, or events in real time.- Impact: Real-time customer feedback enables companies to adapt marketing strategies, detect PR crises early, and gauge consumer happiness.
These examples highlight how supervised learning has entrenched itself in nearly every domain, from medical diagnostics to everyday tasks like spam filtering. Whenever the desired outcome is well-defined and labeled data is available, supervised learning can excel, often with impressively high accuracy.
4. Foundations of Unsupervised Learning
Unlike supervised learning, unsupervised learning operates without labeled datasets. The data provided to the algorithm does not carry explicit “answers.” Instead, the learning process seeks to uncover hidden structures or groupings inherent in the data. This idea of discovering latent patterns can be highly beneficial in scenarios where labeling is expensive, impractical, or impossible.
Formally, consider a dataset of unlabeled instances {x1,x2,…,xn}\{x_1, x_2, \dots, x_n\}{x1,x2,…,xn}. The goal of unsupervised learning is to learn some structure in the data. That might be by clustering similar examples together, reducing the dimensionality for data visualization, or learning probability distributions that define how data might be generated. While there is no single “correct” answer for each data point, success in unsupervised learning typically revolves around coherence, interpretability, and the utility of the discovered structure for downstream tasks.
- Types of Unsupervised Learning Tasks
- Clustering: Grouping similar data points together, e.g., k-means or hierarchical clustering.
- Dimensionality Reduction: Techniques like Principal Component Analysis (PCA) or t-SNE that project high-dimensional data onto lower dimensions for visualization or further modeling.
- Density Estimation: Estimating the underlying probability distribution of data, e.g., using Gaussian Mixture Models.
- Association Rule Mining: Discovering interesting relationships or frequent patterns within large datasets, often used in market basket analysis.
- Key Algorithms
- k-Means: A widely used clustering algorithm that partitions data into kkk clusters by minimizing within-cluster variance.
- Hierarchical Clustering: Builds a tree (dendrogram) structure to show how clusters merge or subdivide at different similarity thresholds.
- DBSCAN: Density-Based Spatial Clustering of Applications with Noise identifies clusters as areas of high density separated by areas of low density, robust to outliers.
- Principal Component Analysis (PCA): A linear approach to dimensionality reduction that finds orthogonal directions of maximum variance in high-dimensional data.
- t-SNE (t-distributed Stochastic Neighbor Embedding): A non-linear method excellent for visualizing high-dimensional data in 2D or 3D space, often used for revealing clusters or separable groups.
- Evaluation in Unsupervised Learning
Because there are typically no labels to compare against, evaluating unsupervised learning can be challenging. Methods like the Silhouette Score, the Davies-Bouldin Index, or visual inspection are sometimes employed to measure how well the algorithm has grouped or separated data. Additionally, domain experts often interpret clusters or reduced dimensions to judge if they make intuitive sense.
Unsupervised learning’s strength lies in its ability to glean structure from raw data without guidance. This capability becomes indispensable in exploratory data analysis, pattern discovery in large unlabeled datasets, or anytime domain expertise is available but explicit labeling is prohibitive. The insights gained from unsupervised approaches can inform subsequent analyses—possibly leading to refined supervised tasks if and when labeling resources become available.

5. Real-World Examples of Unsupervised Learning
- Customer Segmentation in Marketing
Retail and e-commerce companies often have vast amounts of customer transaction data without explicit “labels.” Clustering techniques (like k-means) can segregate shoppers into distinct segments based on purchasing habits, frequency of purchases, and preferred product categories.- Impact: Highly targeted marketing campaigns and personalized recommendations, leading to improved customer satisfaction and higher sales conversions.
- Impact: Highly targeted marketing campaigns and personalized recommendations, leading to improved customer satisfaction and higher sales conversions.
- Anomaly Detection in Cybersecurity
In cybersecurity operations, organizations collect massive logs of network behavior. Unsupervised learning approaches, such as density-based clustering (DBSCAN) or autoencoders used in an anomaly detection context, can flag activity that deviates markedly from the “normal” network behavior.- Impact: Identification of suspicious network intrusions or unusual login patterns before they escalate into full-scale breaches.
- Impact: Identification of suspicious network intrusions or unusual login patterns before they escalate into full-scale breaches.
- Topic Modeling in Document Analysis
Clustering and topic modeling algorithms like Latent Dirichlet Allocation (LDA) help discover hidden thematic structures in large text corpora. For instance, news organizations or research institutions can feed thousands of unlabeled documents into LDA, which then groups the documents by latent topics.- Impact: Rapid organization of unstructured text data, enabling search, summary, and content recommendations.
- Impact: Rapid organization of unstructured text data, enabling search, summary, and content recommendations.
- Gene Expression Analysis in Bioinformatics
Researchers dealing with genomic data often have no predefined labels. Clustering techniques can group samples that exhibit similar gene expression profiles, potentially highlighting unknown disease subtypes or biomarker relationships.- Impact: Deepens understanding of complex diseases, facilitates drug discovery, and personalizes medicine.
- Impact: Deepens understanding of complex diseases, facilitates drug discovery, and personalizes medicine.
- Recommender Systems (Collaborative Filtering)
Although some recommender systems use supervised techniques, a large number leverage unsupervised or semi-supervised methods to discover latent factors in user-item interactions. For instance, matrix factorization or autoencoders identify hidden patterns in user preferences without explicit “labels.”- Impact: Netflix or YouTube suggests content you might like, even if the system has minimal direct feedback, by mapping your activity into a latent feature space.
Unsupervised learning methods often serve as the bedrock for subsequent, more specialized analytics. Clusters discovered in raw data might later be used to define classes for a supervised classifier, or the underlying structure might inform how resources and efforts are allocated in product development or policy-making contexts.
6. Key Differences Between Supervised and Unsupervised Learning
- Data Labeling
- Supervised: Requires labeled data, which can be expensive or time-consuming to obtain.
- Unsupervised: Works with unlabeled data, making it more flexible but less direct in how “accuracy” is measured.
- Objective
- Supervised: Learn a mapping from inputs to a known target output (e.g., predict or classify).
- Unsupervised: Discover hidden structure or groupings without a predefined notion of correctness.
- Evaluation Metrics
- Supervised: Metrics like accuracy, precision, recall, R2R^2R2 provide clear quantitative measures.
- Unsupervised: Relies more on internal metrics (Silhouette Score, Davies-Bouldin Index) or qualitative/visual assessments.
- Complexity of Implementation
- Supervised: Straightforward to understand conceptually if good labels exist, with clear training objectives (minimize error).
- Unsupervised: Often more complex to evaluate; success can depend heavily on domain insights and the nature of data.
- Scalability and Data Requirements
- Supervised: Performance can degrade if labeled data is insufficient, leading to underfitting or poor generalization.
- Unsupervised: Can be applied to massive datasets, though large data volume can also introduce complexity in cluster interpretability.
- Common Use Cases
- Supervised: Image classification, sentiment analysis, spam detection, regression-based forecasting.
- Unsupervised: Customer segmentation, anomaly detection, dimensionality reduction, exploratory data analysis.
In short, supervised learning is typically chosen when specific, measurable outcomes are needed and sufficient labeled data is available. Unsupervised learning is apt when the goal is exploration, discovering patterns, or performing tasks like clustering or anomaly detection without the need (or the feasibility) for explicit labels.
7. When to Use Supervised vs. Unsupervised Learning
Deciding whether to use supervised or unsupervised methods often hinges on the availability and quality of labeled data, the exact objective of the project, and the level of interpretability required. Below is a high-level framework for making this decision:
- Nature of the Problem
- If you have clearly defined outcomes (e.g., “Is this image a cat or dog?” “What is the next day’s temperature?”) and a labeled dataset: Use supervised learning.
- If you want to explore data to see if natural groupings exist (e.g., “What are the hidden segments in my customer base?” “Are there any outliers in network traffic?”): Use unsupervised learning.
- Availability of Labels
- Sufficient, high-quality labels: Supervised learning is often more accurate, direct, and interpretably aligned with business or research goals.
- No labels or labeling is prohibitively expensive: Unsupervised learning allows you to glean insights without manual annotation.
- Goal Clarity
- Well-defined predictive goal: If the end objective is a metric-based prediction or classification, supervised methods excel.
- Exploratory analysis: If you need to discover unknown patterns or anomalies, unsupervised approaches are more suitable.
- Data Dimensionality
- Dimensionality is high, but you aim for interpretability: Consider unsupervised dimensionality reduction to compress your feature space before a supervised task.
- Dimensionality is moderate: Can apply either supervised or unsupervised methods directly.
- Ethical and Regulatory Constraints
- Regulations might require interpretability: Methods like decision trees (supervised) or certain interpretable clustering (unsupervised) might be preferred for explainability.
- Privacy concerns: Labeled data containing personal information might be restricted, pushing you to use unsupervised techniques or synthetic data approaches.
In many real-world pipelines, practitioners combine both methods. For instance, you might use unsupervised clustering to discover potential classes in the data, then assign labels to those clusters (through expert review), and finally refine a supervised model trained on this newly labeled dataset. This synergy underscores that supervised and unsupervised learning are not mutually exclusive. Instead, they are complementary tools in the machine learning toolkit.
8. The Incredible Potential for Future Discoveries
Machine learning, particularly in its supervised and unsupervised guises, has already taken us far beyond what was possible only a decade ago. Yet the frontier remains expansive, with myriad opportunities for groundbreaking innovations:
- Advances in Semi-Supervised and Weakly Supervised Learning
When data labeling is only partial or noisy, hybrid approaches such as semi-supervised learning (where a small amount of labeled data is combined with large amounts of unlabeled data) can produce robust models. This field has already advanced significantly, especially in NLP tasks where labeled data might be scarce. As these methods mature, we can expect even more powerful models trained at a fraction of the labeling cost. - Self-Supervised Learning
Self-supervised learning, a burgeoning subfield, leverages massive unlabeled datasets by formulating pretext tasks (e.g., predicting missing words, next frames in video, or masked areas in an image). Once the model gains these representations, it can be fine-tuned on smaller labeled datasets. This approach underpins many of the largest language models (e.g., GPT-like architectures). As research continues, self-supervised learning might bridge the gap between supervised and unsupervised paradigms, making the boundaries ever blurrier. - Reinforcement Learning with Unlabeled Data
Reinforcement learning (RL) traditionally relies on reward signals, but some emerging methods integrate unsupervised or self-supervised objectives. Future research will likely involve RL agents that can explore environments without direct feedback, discovering structured representations of the world that accelerate learning when rewards do become available. - Automated Labeling and Active Learning
By leveraging unsupervised clustering or anomaly detection, some tasks can reduce the labeling burden: data points that are most “representative” or “interesting” (as identified by an unsupervised algorithm) can be prioritized for manual labeling. This approach, known as active learning, targets labeling resources more efficiently. The interplay between supervised and unsupervised learning stands to become more organic and iterative. - Explainable and Ethical AI
The opacity of black-box models—particularly deep neural networks—has sparked pressing conversations about ethics, bias, and transparency. Future research will likely yield new ways to interpret not only the final model decisions but also the latent representations gleaned by unsupervised methods. The synergy between interpretable clustering and classification might help produce fairer and more accountable AI systems. - Federated Learning and Privacy Preservation
As privacy regulations tighten, the machine learning community is exploring federated learning—models that train across multiple decentralized devices or servers holding local data. Unsupervised or semi-supervised techniques in federated contexts can help with data that cannot be easily labeled or shared. Innovations in differential privacy might also ensure that unsupervised models do not inadvertently expose personal details, thus addressing ethical and legal concerns in data processing. - Cross-Domain Applications
Astronomy, climate science, and quantum physics are examples of domains inundated with massive amounts of unlabeled data. Novel unsupervised methods could expedite breakthroughs by clustering novel phenomena or reducing the dimensionality of complex data sets (e.g., large-scale simulations of climate models). Meanwhile, supervised methods refined on newly labeled subsets can confirm or expand upon these discoveries.
Overall, the synergy between supervised and unsupervised learning is poised to revolutionize how we tackle scientific, commercial, and social challenges. Whether it is discovering new particles in physics or unveiling hidden subpopulations in healthcare data, these methodologies serve as vital instruments in humanity’s quest to decode complexity.
9. Conclusion
In this extensive discussion, we have traversed the essential terrain of supervised vs. unsupervised learning, two cornerstone methodologies in modern machine learning. Supervised learning thrives on labeled data, providing highly accurate and targeted predictions across tasks like classification and regression. Unsupervised learning, by contrast, delves into uncharted territory where labels do not exist, unveiling hidden structures and patterns within vast datasets through clustering, dimensionality reduction, and density estimation.
We explored real-world examples—from spam detection and dermatological image classification in supervised domains, to anomaly detection and customer segmentation in unsupervised settings. The differences between these paradigms are profound: the presence (or absence) of labels, distinct evaluation metrics, unique algorithmic objectives, and challenges in interpretability. Yet these methods frequently intersect, often in hybrid approaches such as semi-supervised learning or active learning, illustrating their complementary nature.
Deciding when to use supervised or unsupervised learning depends on the availability of data labels, the clarity of the problem statement, cost and time constraints, and the need for interpretability. However, as we look to the future, exciting developments in self-supervised learning, reinforcement learning, federated privacy-preserving techniques, and more, indicate that these boundaries may blur further. The synergy between labeled and unlabeled data, combined with advanced computational capabilities, heralds a new era in machine learning: one in which discoverability, interpretability, and adaptability will expand exponentially.
Our capacity to harness these techniques responsibly and ethically will shape both industry and society. From life-saving medical breakthroughs to optimizing global resource distribution, the potential is vast. Experts, practitioners, and policy-makers alike must collaborate to ensure that innovations in supervised and unsupervised learning serve the broader good—ushering in solutions that are fair, transparent, and beneficial across myriad domains.
10. Sources
Below are sources and resources where you can learn more and stay updated:
- Scikit-learn Documentation:
https://scikit-learn.org/stable/
A comprehensive guide to popular supervised and unsupervised algorithms in Python. - PyTorch:
https://pytorch.org/
An open-source machine learning framework widely used for building neural networks in supervised and unsupervised contexts. - TensorFlow:
https://www.tensorflow.org/
Another major framework for deep learning, offering various APIs for supervised, unsupervised, and reinforcement learning. - Google AI Blog:
https://ai.googleblog.com/
Regularly updated with cutting-edge research and practical breakthroughs in both supervised and unsupervised methods. - Kaggle:
https://www.kaggle.com/
A platform offering datasets, competitions, and community discussions on machine learning projects, including supervised and unsupervised challenges. - OpenAI Blog:
https://openai.com/blog/
Delve into ongoing research in large language models, self-supervised learning, and general advancements in AI. - UCI Machine Learning Repository:
https://archive.ics.uci.edu/ml/index.php
A trove of datasets for both supervised and unsupervised tasks, widely used in academic and experimental settings.
By immersing yourself in these resources, you can continue to explore the rich tapestry of ideas, applications, and innovations that shape the landscape of supervised and unsupervised learning. As the frontiers of machine learning expand, practitioners will continue to blend these paradigms, forming ever more powerful and insightful pipelines capable of tackling the world’s most challenging problems.
Continue Reading
- Supervised vs Unsupervised Learning: Foundations, Practical Examples, and Key Differences
- How TikTok’s Algorithm Really Works: A Deep Dive Into the Unsupervised Learning Engine Behind the For You Page
Related Guides
- Comprehensive AI Glossary: Key Terms in Machine Learning, Deep Learning, and Artificial Intelligence
Compare
- Data Science vs Machine Learning: What’s the Difference? [Complete 2025 Guide]
- Reinforcement Learning Revolution: How DeepSeek R1 Is Reshaping AI Reasoning
Recent Launches
The Kingy Brief
Get The Kingy Brief.
Every week: what launched, what changed price, and what scored well — built on KALI.
Weekly · Double opt-in · Unsubscribe anytime