
On the evening of May 31, 2026 (Eastern time), Shanghai-based AI startup MiniMax pushed its most ambitious model yet into the world. By Monday morning, June 1, the launch had a name everyone in the AI community was repeating: MiniMax M3.
The pitch is unusually bold for an open-weight release — MiniMax claims M3 is the first open model to fuse three capabilities that, until now, only the closed frontier labs could offer simultaneously: frontier-level coding and agentic performance, a one-million-token context window, and native multimodality, complete with the ability to operate a desktop computer.

That framing comes straight from the company’s own launch blog post, which opens with a deceptively simple line: “MiniMax M3 is officially released today.” What follows is a dense technical argument that the gap between open and closed models has narrowed to a sliver — and, on a handful of benchmarks, may have closed entirely. This article walks through what M3 actually is, the specifications and benchmark numbers published so far, how it stacks up against both open-source rivals and the proprietary frontier, and the significant caveats that independent observers have already raised.
Two important sources anchor everything below: the official MiniMax M3 model page and the MiniMax research blog. Everything else — VentureBeat, The Decoder, the South China Morning Post, Tech Times, OpenRouter — either corroborates or contextualizes those primary claims.
What M3 actually is
At its core, M3 is a sparse Mixture-of-Experts foundation model that accepts text, image, and video as inputs and produces text as output. According to its OpenRouter listing, the model offers a 1,048,576-token (1M) context window with a maximum output of 512,000 tokens, and it was released to the API on May 31, 2026. MiniMax positions it squarely at the workloads that punish models with short or expensive context: long-horizon agent tasks, whole-repository coding, and long-video understanding.
The South China Morning Post framed the launch in business terms, noting that M3 is MiniMax’s first major product release since the firm began preparing for an IPO on Shanghai’s STAR Market — a listing that would complement its existing Hong Kong presence. The SCMP also flagged a telling omission: MiniMax declined to disclose the model’s parameter count or the compute infrastructure used to train it. For a model billed as “open-weight,” that silence is conspicuous, and it’s a thread several critics have pulled at.
What MiniMax did disclose is that M3 represents a generational break from its M2 line. As the developer-focused Lushbinary guide observes, the M2 series had actually removed sparse attention in favor of full attention; M3 brings sparsity back in a brand-new form, and that single architectural decision is what unlocks the 1M context window at a usable price.
MSA: the architecture doing the heavy lifting
The headline technical feature is MiniMax Sparse Attention (MSA). The problem it solves is old and well understood: standard transformer attention is quadratic. Every token attends to every other token, so doubling the context roughly quadruples the attention compute. That’s why long context windows have historically been slow and ruinously expensive.
MSA attacks this with a two-stage mechanism. As MiniMax describes it in the blog, and as Tech Times summarizes, a lightweight index branch first scans incoming tokens and partitions the key-value (KV) cache into blocks, selecting only those blocks relevant to a given query. The expensive full-attention computation then runs only on the selected blocks. MiniMax argues this partitions the KV “more precisely” than competing approaches like DeepSeek’s DSA or the MoBA method, achieving higher effective context coverage.
There’s a second, lower-level optimization that matters just as much. Rather than loading the matching KV blocks for each individual query — which causes the same block to be fetched from memory repeatedly — MSA flips the loop. It uses a “KV outer gather Q” approach: KV blocks become the outer loop, and all the queries that hit a given block are batched together. Each block is read from memory exactly once, in a contiguous access pattern instead of scattered jumps. MiniMax claims this implementation runs more than 4× faster than open-source alternatives like Flash-Sparse-Attention and flash-moba.
The aggregate numbers are striking. At a maxed-out 1M-token context, MiniMax says M3’s per-token compute drops to 1/20th of the previous generation, translating to a 9× speedup in prefill and 15× in decoding. The aimadetools complete guide cites slightly more precise figures — 9.7× faster prefill and 15.6× faster decoding versus the M2 generation at million-token contexts — and emphasizes a crucial distinction from DeepSeek’s Multi-head Latent Attention: MSA operates on uncompressed key-values, so there’s no precision loss at long context. Independent researcher Elie Bakouch, quoted by Tech Times, characterized the approach as “block level selection like in CSA but attention is done on the real KV, not in the compressed dimension.”
One important honesty note from MiniMax’s own materials: across multiple ablations, MSA “matched full attention on the vast majority of capabilities” — vast majority, not all. That hedge is the kind of detail worth remembering once independent evaluations begin.
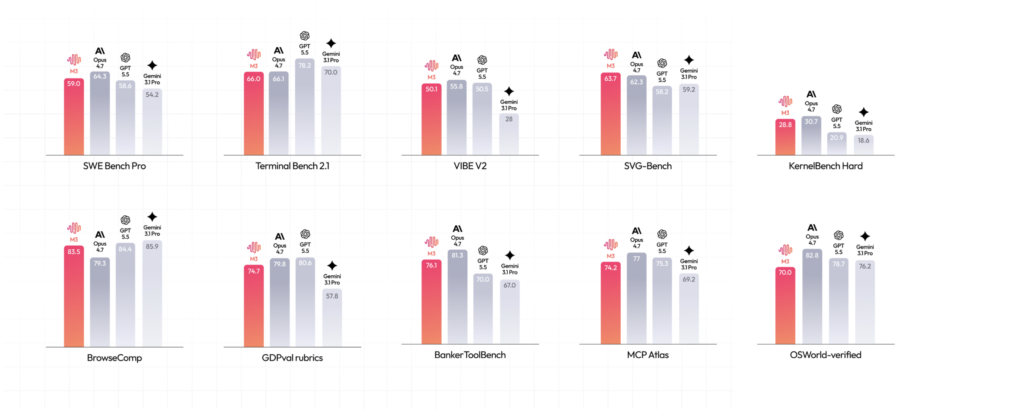
The benchmark numbers
Coding and agentic capability are where MiniMax planted its flag. Here are the headline scores published at launch, drawn directly from the official blog:
- SWE-Bench Pro: 59.0% — long-horizon, real-world software engineering tasks
- Terminal-Bench 2.1: 66.0% — agentic terminal and CLI execution
- SWE-fficiency: 34.8% — efficient resolution of engineering tasks
- KernelBench Hard: 28.8% — GPU kernel optimization
- MCP Atlas: 74.2% — multi-step tool use via the Model Context Protocol
- BrowseComp: 83.5 — autonomous browsing and information retrieval
- SVG-Bench: 63.7% — programmatic SVG/visual code generation
- OSWorld-Verified: 70.0% — desktop GUI computer use
The most repeated claim is SWE-Bench Pro. MiniMax says M3’s 59.0% surpasses GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%) and approaches Claude Opus 4.7. SWE-Bench Pro is a deliberately harder benchmark than the now-saturated SWE-Bench Verified, built around roughly 1,865 real pull requests from 41 actively maintained open-source repositories, as Tech Times notes. Beating two of the three U.S. frontier flagships on it — if the numbers hold — is a genuinely notable result for an open-weight model.
On the multimodal side, MiniMax reports that M3 scores above Gemini 3.1 Pro on OmniDocBench (document understanding) and achieves the highest score on Claw-Eval, an end-to-end autonomous-agent framework. On SVG-Bench, the company says M3 surpasses Opus 4.7, and on BrowseComp, its 83.5 edges past the Opus 4.7 baseline of 79.3 — a result echoed across The Decoder and VentureBeat.
It’s worth being precise about methodology here, because MiniMax was unusually transparent about it. The company’s evaluation appendix states that SWE-Bench Pro and several other tests were run on internal infrastructure using Claude Code as the scaffolding, with results averaged over multiple runs. Some external baselines (Terminal-Bench 2.1 figures for GPT-5.5, Gemini 3.1 Pro, and Opus 4.7) were lifted from official leaderboards; others were re-tested via API on the same hardware. That’s both more disclosure than many launches provide and, simultaneously, a reminder that these are vendor-run comparisons.
The long-horizon autonomy demonstrations
Benchmarks are single snapshots; what MiniMax seemed most proud of were three sustained-autonomy demonstrations that read more like research anecdotes than leaderboard entries. The Decoder and VentureBeat both gave them prominent coverage.
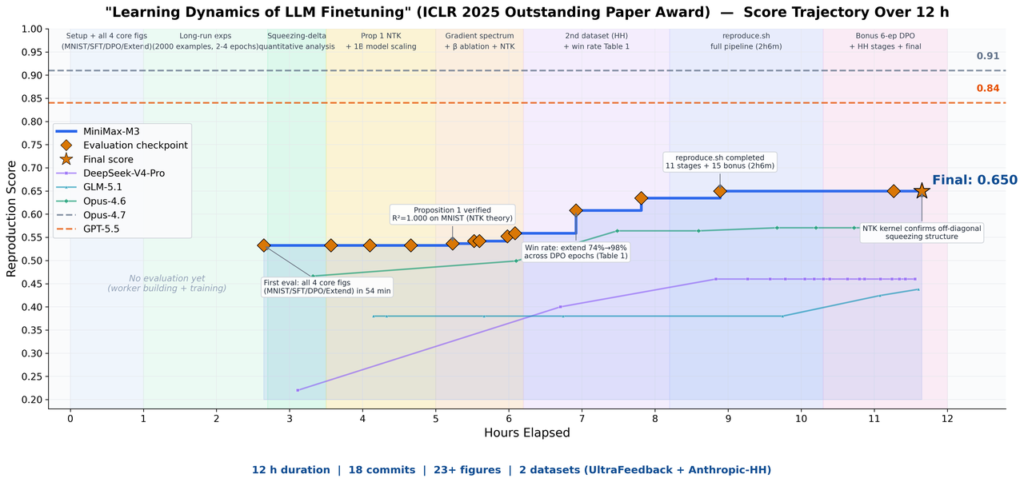
The 12-hour paper reproduction. MiniMax handed M3 an ICLR 2025 Outstanding Paper Award winner — Learning Dynamics of LLM Finetuning — and asked it to reproduce the work independently. M3 ran continuously for nearly 12 hours, producing 18 commits and 23 experimental figures with no human intervention. According to the company, it matched the predicted probability trends in the SFT stage, observed the “squeezing effect” central to the DPO experiments, and validated the “Extend” mitigation method from the original paper. This is the demo that best showcases all three capabilities working together: multimodality to parse the paper’s charts and formulas, long context to hold paper + code + logs in a single window, and coding/agentic skill to drive the execution.
The 24-hour CUDA kernel optimization. MiniMax asked M3 to optimize an FP8 GEMM (matrix multiplication) kernel on NVIDIA Hopper GPUs — one of the most compute-intensive and notoriously difficult operations in LLM inference. Starting with only a task description, a benchmark script, and a non-runnable Triton skeleton (no reference solution to copy), M3 ran for about 24 hours, completed 147 benchmark submissions and 1,959 tool calls, and pushed hardware peak utilization from 7.6% to 71.3% — a 9.4× speedup. MiniMax notes that most other tested models gave up within the first 30 submissions; M3’s best solution didn’t appear until submission 145, after pushing through several performance plateaus. The Decoder’s reporting adds a sober counterpoint: Opus 4.7 reached comparable results in far fewer runs.
PostTrainBench — M3 training models. In the most open-ended test, MiniMax gave M3 four pretrain-only base models and asked it to autonomously run the full pipeline — data synthesis, training, evaluation, iteration — within 12 hours, with no human input. M3 scored 0.37 (37.1), ranking third overall behind only Opus 4.7 (0.42) and GPT-5.5 (0.39), but clearly ahead of every other model tested.
These are, as Tech Times rightly underlines, “demonstrations of long-horizon autonomous execution, not controlled benchmark evaluations.” Impressive as anecdotes, they aren’t reproducible leaderboard results.
How M3 compares to the proprietary frontier
This is where the launch-day euphoria meets a harder reality, and VentureBeat deserves credit for surfacing it. MiniMax’s comparison baseline throughout its materials is Claude Opus 4.7 — but Anthropic shipped Opus 4.8 on May 25, 2026, a week before M3’s launch. When VentureBeat lined M3 up against the current ceiling, a consistent gap emerged:
| Benchmark | MiniMax M3 | Claude Opus 4.8 |
|---|---|---|
| SWE-Bench Pro | 59.0% | 69.2% |
| Terminal-Bench 2.1 | 66.0% | 74.6% |
| OSWorld-Verified | 70.0% | 83.4% |
On all three directly comparable agent evaluations, M3 trails Opus 4.8 by roughly 10–13 points. M3’s Terminal-Bench result of 66.0% is essentially tied with the previous-generation Opus 4.7 baseline of 66.1%. In other words, M3’s “approaches the frontier” claim is accurate against the frontier as it stood when the evaluations were designed — but the frontier moved.
Against GPT-5.5 and Gemini 3.1 Pro, the picture is genuinely competitive. M3’s 59.0% on SWE-Bench Pro beats GPT-5.5’s 58.6% and Gemini 3.1 Pro’s 54.2%. But on Terminal-Bench 2.1, the aimadetools comparison shows GPT-5.5 (72.1%) and Gemini 3.1 Pro (70.0%) both ahead of M3’s 66.0%. The fair summary, echoed across sources, is this: M3 is frontier-adjacent. It wins on specific tests — SWE-Bench Pro, BrowseComp, SVG-Bench — and loses on others, but it does so while undercutting those rivals on price by an order of magnitude.
How M3 compares to other open-source models
The more interesting fight may be inside the open-weight camp, where Chinese labs have been trading blows all year. VentureBeat’s pricing snapshot situates M3 among a crowded field of DeepSeek, Xiaomi MiMo, Moonshot’s Kimi, Z.ai’s GLM, and Alibaba’s Qwen models.
The most direct rival is DeepSeek-V4 Pro Max, a fellow open-weight model with a reported 1.6-trillion total parameter footprint. VentureBeat’s head-to-head shows the two trading narrow wins:
| Benchmark | MiniMax M3 | DeepSeek-V4 Pro Max |
|---|---|---|
| SWE-Bench Pro | 59.0% | 55.4% |
| Terminal-Bench 2.1 | 66.0% | 67.9% |
| BrowseComp | 83.5% | 83.4% |
| MCP Atlas | 74.2% | 73.6% |
M3 edges ahead on code synthesis and tool use; DeepSeek pulls slightly ahead in command-line execution; on browsing they’re at statistical parity. The notable subtext, as VentureBeat puts it, is that M3 achieves this “without requiring extensive parameter activation scaling” — MiniMax’s block-filtered sparse attention is doing competitively against DeepSeek’s much larger, high-effort reasoning configuration. The aimadetools guide adds an honest caveat in the other direction: DeepSeek V4-Pro reportedly scores higher (80.6%) on the easier SWE-Bench Verified, so the open-weight ranking depends heavily on which benchmark you privilege.
The broader open field includes Kimi-K2.6 (Moonshot), GLM-5 and GLM-5.1 (Z.ai), Qwen3.7-Max (Alibaba), and MiMo-V2.5 (Xiaomi). MiniMax’s own NL2Repo methodology notes pull competitor scores for DeepSeek-V4-pro, Kimi-k2.6, and GLM-5.1 from Qwen’s published blog — a reminder of how incestuous and self-referential the current benchmark ecosystem has become. What separates M3 from this pack, per the aimadetools breakdown, isn’t raw coding score but the combination: native multimodality, computer use, and MSA’s long-context speed advantage, none of which most of these text-only rivals offer in one package.

Pricing: the real disruption
If the benchmarks are contested, the pricing is not. This is where M3 lands its hardest punch.
At launch, M3’s standard API rate is $0.60 per million input tokens and $2.40 per million output tokens, with a temporary 50% launch discount for the first week bringing it to $0.30 / $1.20. The aimadetools guide adds further granularity: cache reads at $0.12/M, and a 2× long-context multiplier ($1.20 / $4.80) for inputs in the 512K–1M range. Crucially, calls at or below 512K input tokens — “the vast majority of conversation and coding scenarios,” per the blog — bill at the standard rate.
VentureBeat’s pricing table makes the gap visceral. Against Claude Opus 4.8 ($5 / $25) and GPT-5.5 ($5 / $30), M3 at full price is roughly 8–20% of the cost, and at promo pricing closer to 5–10%. Lushbinary’s worked example drives it home: a coding task consuming 500K input and 100K output tokens costs about $0.27 on M3 promo, $0.54 at standard, and $5.00 on Opus — the same task at roughly a tenth to a twentieth of the price.
For developers who prefer subscriptions, MiniMax updated its Token Plan across three tiers, all sharing a single multimodal usage pool across text, image, speech, and music:
- Plus — $20/month: ~1.7B tokens of M3 usage
- Max — $50/month: ~5.1B tokens (plus daily Hailuo 2.3 video clips)
- Ultra — $120/month: ~9.8B tokens
VentureBeat reports the Max and Ultra tiers also bundle concurrent-agent capacity (4–5 and 6–7 agents respectively) for use with MiniMax Code, the company’s dedicated coding agent. That product — built on the open-source OpenCode and Pi harnesses, and itself slated to be open-sourced — runs an “Agent Team” with a Producer + Verifier adversarial loop designed to operate autonomously for days.
The caveats that matter
For all the excitement, the most responsible coverage came wrapped in warnings, and any honest article has to repeat them.
The benchmarks are vendor-run. As Tech Times bluntly puts it, every figure in MiniMax’s launch materials “was produced by MiniMax on its own internal infrastructure, using evaluation environments MiniMax configured, with baselines MiniMax selected.” Reviewer Thomas Wiegold, quoted in the same piece, was careful to clarify this isn’t an accusation of cheating — “it’s just how launch-day benchmarks work.” As of launch, independent scores from Artificial Analysis and LMArena, the two most-cited third-party evaluators, were still pending. Until those land, treat M3’s rankings as a preliminary signal, not a settled result.
The weights haven’t shipped. Despite the “open-weight” branding, neither the model weights nor the technical report were available at launch. MiniMax committed to publishing both on Hugging Face and GitHub “within 10 days” — targeting roughly June 11, 2026. Until then, as Tech Times notes, outside engineers cannot inspect the architecture, verify the MSA speed claims, assess safety behavior, or confirm the license terms. MiniMax has used a modified-MIT license for prior models, which is closer to open-weight than to fully open source. The “open” designation is, for now, a company commitment rather than a verifiable fact.
Jurisdictional and legal risk. Tech Times devotes substantial space to a concern the more breathless coverage skips: MiniMax is headquartered in Shanghai and is subject to China’s 2017 National Intelligence Law, which obligates Chinese firms to “support, assist, and cooperate” with state intelligence work. For agentic coding workloads involving proprietary source code or sensitive data routed through MiniMax’s API, that’s a structural consideration regardless of server location. The same report notes a U.S. congressional investigation announced April 29, 2026, naming MiniMax alongside other Chinese labs; Anthropic’s February 2026 allegations of industrial-scale distillation against Claude; and an active copyright suit from Disney, Universal, and Warner Bros. Discovery over the separate Hailuo product, which a federal judge allowed to proceed on May 26, 2026. None of these implicate M3’s technical merits, but they shape the deployment calculus for regulated or enterprise users.
Long context is not memory. As Lushbinary cautions, a 1M window helps, but stuffing everything into context is no substitute for a real memory system on long-running agents. And the promo pricing is temporary — teams should model unit economics against the standard $0.60 / $2.40 rate.
The bottom line
MiniMax M3 is the most technically ambitious release in the company’s history, and arguably a milestone for open-weight AI generally. The MSA architecture is a genuinely novel contribution to the long-context problem, the pricing is aggressive enough to reshape the economics of agentic workloads, and the benchmark scores — even discounted for vendor bias — place M3 in frontier-adjacent territory while beating GPT-5.5 and Gemini 3.1 Pro on at least one serious coding test.
But the honest verdict, the one threaded through The Decoder, VentureBeat, and especially Tech Times, is that M3 trails the current frontier — Claude Opus 4.8 — by a meaningful 10-plus points on the directly comparable agent benchmarks, its scores are not yet independently verified, and the open weights that would let anyone check the claims are still ten days out. The cost advantage is real and large. It is, as Tech Times concludes, “a factor — not the only factor.”
The right move for anyone considering M3 in production is the one every credible source recommends: wait for the weights and the technical report around June 11, watch for independent scores from Artificial Analysis and LMArena, and run your own evaluations on representative tasks before committing. The promise is enormous. The verification has just begun.
The Kingy Brief
Get The Kingy Brief.
Every week: what launched, what changed price, and what scored well — built on KALI.
Weekly · Double opt-in · Unsubscribe anytime