On May 28, 2026, Anthropic released Claude Opus 4.8, the latest iteration of its flagship Opus line and—at least for the moment—the most capable model the company is willing to put into general circulation. Arriving just 41 days after Opus 4.7, the release continues an aggressive cadence that has come to define the 2026 frontier-model race. Yet the headline here is not a single dramatic leap. Instead, Opus 4.8 is best understood as a practical upgrade: modestly better benchmark numbers wrapped around a genuinely interesting set of platform and behavioral changes, all delivered at exactly the same price as its predecessor.
Anthropic itself frames the model plainly. “We’re upgrading Claude Opus to a new version: Claude Opus 4.8,” the company wrote in its launch announcement. “It builds on Opus 4.7 with improvements across benchmarks, and is a more effective collaborator. It’s available today for the same price.” That “same price” framing is the commercial heart of the release—and the lens through which most of the technical story should be read.
Specifications at a glance
Opus 4.8 is, on paper, a point-release that preserves the core architecture and surface area of Opus 4.7. The key specifications, drawn from Anthropic’s announcement and the LLM Stats technical breakdown, are:
- Model ID:
claude-opus-4-8on the Claude API - Context window: 1 million input tokens
- Maximum output: 128K tokens
- Modalities: Text and vision input; text output
- Effort levels: Defaults to high, with extra (
xhighin Claude Code) and max available for harder problems - Standard pricing: $5 per million input tokens, $25 per million output tokens
- Fast mode pricing: $10 per million input tokens, $50 per million output tokens, at roughly 2.5× output speed
- Release status: Generally available
The 1M-token context window carries over unchanged from Opus 4.7, as does the $5/$25 rate card. In other words, anyone already building on the Opus rate structure can swap in the new model ID without recalculating their cost model. Anthropic clearly designed the release to remove friction: it is a drop-in replacement at the API level, with the same tools, platform features, and pricing as before.
Benchmarks: real gains, with honest caveats
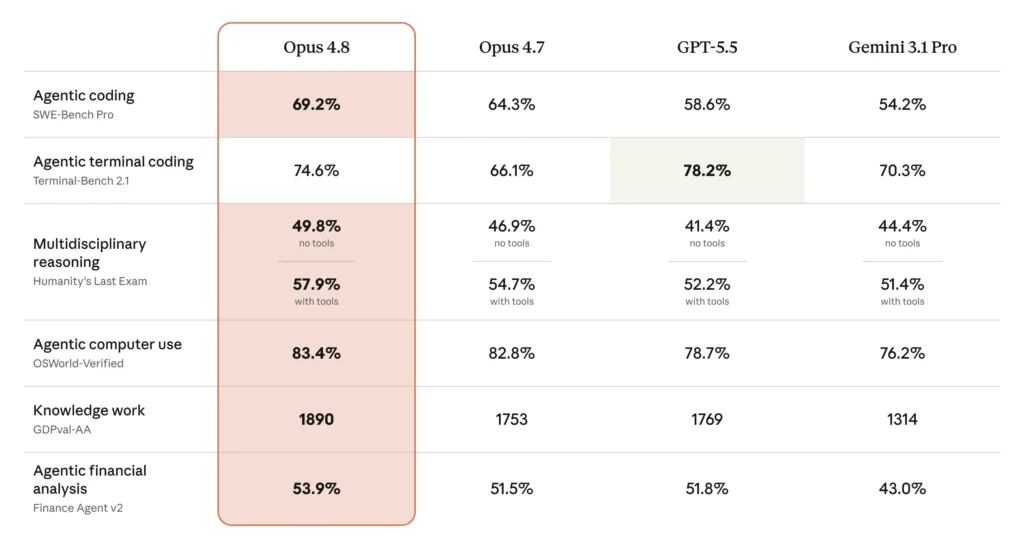
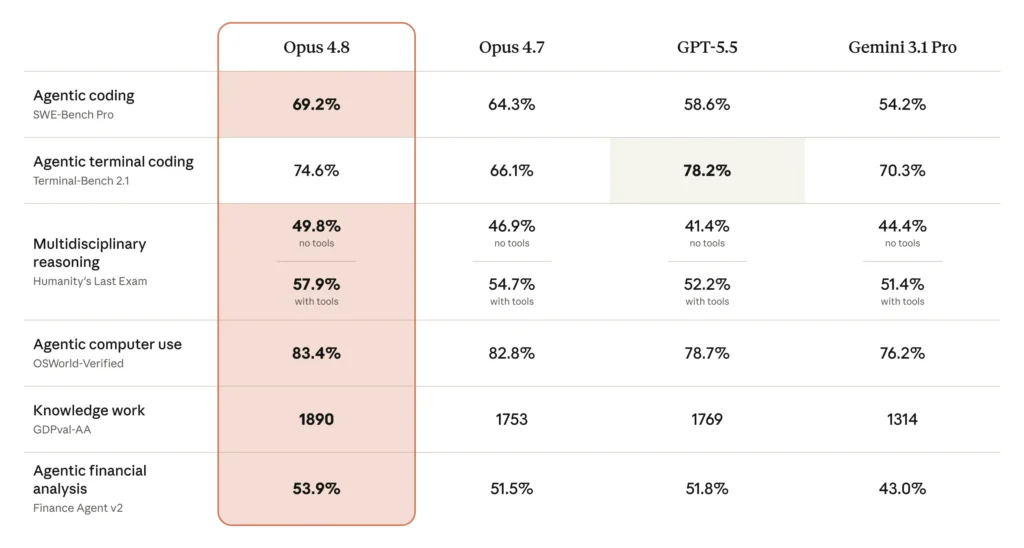
Anthropic published a comparison of Opus 4.8 against Opus 4.7, GPT-5.5, and Gemini 3.1 Pro across coding, agentic, reasoning, and knowledge-work benchmarks. The standard configuration uses adaptive thinking at max effort, averaged over five trials. The results are genuinely improved—but the deltas range from substantial to flat, and a couple even tick slightly downward.
On the coding front, the marquee numbers are:
- SWE-bench Verified: 88.6% (up from 87.6% on Opus 4.7)
- SWE-bench Pro: 69.2% (up from 64.3%)
- SWE-bench Multilingual: 84.4% (up from 80.5%)
- Terminal-Bench 2.1: 74.6%
The +1.0 point on SWE-bench Verified looks unimpressive until you remember that this benchmark is approaching saturation—almost everyone at the frontier is clustered near the ceiling. The more meaningful signal is the +4.9 point jump on SWE-bench Pro, the harder and less-saturated set, where real headroom still exists. By comparison, Codersera reports that GPT-5.5 scores 58.6% and Gemini 3.1 Pro 54.2% on SWE-bench Pro, giving Opus 4.8 a clear lead on agentic coding.
Terminal-Bench is one place where Opus 4.8 does not win. Run through the Terminus-2 public harness, Opus 4.8 scores 74.6% versus GPT-5.5’s 78.2%. Anthropic notes in a footnote that GPT-5.5’s own Codex CLI harness pushes its score to 83.4%. The honest read: for single-agent, terminal-only shell loops, GPT-5.5 remains competitive or ahead.
On reasoning and knowledge, the picture is mixed:
- GPQA Diamond: 93.6% (down slightly from 94.2%)
- Humanity’s Last Exam (with tools): 57.9% (up from 54.7%)
- Humanity’s Last Exam (no tools): 49.8% (up from 46.9%)
- USAMO 2026: 96.7% (up from 69.3%)
- GDPval-AA: 1890 Elo
The GPQA Diamond regression is within trial variance on a near-saturated benchmark—Gemini 3.1 Pro also sits at roughly 94.3% there, so nobody is meaningfully pulling ahead. The genuinely eye-catching number is USAMO 2026 at 96.7%, a 27.4-point single-cycle jump over Opus 4.7’s 69.3%, per Digital Applied’s analysis. A gain of that magnitude on competition-grade math proofs suggests a qualitative shift in mathematical reasoning depth, not mere incremental tuning.
The GDPval-AA score of 1890 Elo—Artificial Analysis’s knowledge-work evaluation—is arguably the most commercially relevant headline. Anthropic’s chart implies roughly a 67% head-to-head win rate against GPT-5.5 (1769 Elo) on broad knowledge-work tasks, the first non-marginal lead of this kind in the Opus 4.x line. The caveat, flagged by Codersera, is that Opus 4.8 uses about 30% more turns than GPT-5.5 to complete the same task, so the quality lead carries a real inference-cost overhead.
Agentic browsing and tool use are where the model moves most consistently:
- BrowseComp (single-agent): 84.3% (up from 79.3%); 88.5% with a multi-agent orchestrator
- MCP-Atlas: 82.2% (up from 77.3%)
- OSWorld-Verified (computer use): 83.4%
- Online-Mind2Web: 84% (per partner testing)
One important methodological note: Anthropic changed how it runs OSWorld-Verified—adding a zoom-tool fix and a 128K max-token-per-turn budget—and restated Opus 4.7’s score to 82.3%. So part of the OSWorld gain reflects harness changes rather than a clean model-to-model delta. It’s a good reminder to treat self-reported benchmarks with appropriate skepticism; as Mashable bluntly noted in its coverage, these numbers have not been independently verified.
On long context, the model behaves predictably. GraphWalks BFS scores 85.9% on the 256K subset but drops to 68.1% on the full 1M-token subset—a marked improvement over Opus 4.7’s 40.3% at 1M, but still a reminder to treat the advertised 1M window as a ceiling rather than a comfortable working budget.
The honesty story
If there is a single theme Anthropic wants to own with this release, it is honesty. The company has long trained its models to avoid making claims they can’t support, but a persistent failure mode across all AI systems is the tendency to jump to conclusions—confidently declaring progress when the evidence is thin. Opus 4.8 is positioned as a meaningful step toward fixing that.
According to Anthropic, Opus 4.8 is “around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked.” The system card numbers, as relayed by Digital Applied, go further: the model fails to raise important events to the user only 3.7% of the time, scores 0% on uncritically reporting flawed results (a first for a Claude model), and shows more than a ten-fold reduction in overconfidence versus Opus 4.7. LLM Stats reports it produces dishonest summaries of agentic coding work roughly seventeen times less often than Claude Sonnet 4.6.
This matters because the rest of the release pushes the model toward running longer and with less human supervision. Honesty about its own work is precisely the property you want when an agent is grinding through a multi-hour task unattended.
Anthropic’s alignment team also reported that Opus 4.8 “reaches new highs on our measures of prosocial traits like supporting user autonomy and acting in the user’s best interest,” with rates of misaligned behavior substantially lower than Opus 4.7—”effectively tied” with Claude Mythos Preview, the company’s best-aligned model. The model ships under the same ASL-3 protections as Opus 4.7.
There is one caveat worth flagging for anyone running agents on untrusted input: the system card notes that Opus 4.8 is somewhat less robust to agentic prompt injection than Opus 4.7, with Gray Swan red-teaming showing a ~9.6% attack-success-rate versus 6.0% for 4.7. Teams running agentic pipelines that ingest untrusted content should revisit their sandboxing.
Fast mode, effort control, and dynamic workflows
Three companion launches landed alongside the model, and they may matter more to day-to-day work than any benchmark.
Fast mode is a high-speed configuration of Opus 4.8 that delivers roughly 2.5× faster output token speeds while preserving full Opus-level intelligence. It costs double the standard per-token rate ($10/$50 per million)—but the notable detail is that it is three times cheaper than fast mode was on previous Claude models. According to the fast mode page, it is available now in research preview on Claude Code for all developers with extra usage enabled, and in a limited research preview on the Claude Platform (API), accessible via an account manager or a waitlist form. That cheaper fast tier makes interactive, latency-sensitive use of a frontier Opus model far more practical than it was a generation ago.
Effort control is now exposed directly in claude.ai and Cowork, sitting beside the model selector and available on all plans. Higher effort settings prompt the model to think more frequently and deeply for better answers; lower settings respond faster and consume rate limits more slowly. Opus 4.8 defaults to high effort, which Anthropic judges to be the best balance of quality and experience. On coding tasks, that default spends roughly the same number of tokens as Opus 4.7’s default but performs better. Users wanting more can select “extra” (xhigh) or “max”—Anthropic recommends “extra” for difficult tasks and long-running asynchronous workflows, and has raised Claude Code rate limits to accommodate the heavier token use.
Dynamic workflows is the marquee new capability, available in research preview in Claude Code. It lets Claude plan a large task, fan out hundreds of parallel subagents that each plan, execute, and verify a slice of the work, then merge and verify the results through an orchestrator before reporting back. Anthropic’s flagship example is codebase-scale migrations across hundreds of thousands of lines of code—kickoff to merge, with the existing test suite as the success bar—turning work normally scoped in quarters into something that can finish in days. It is available on Max, Team, and Enterprise plans (with admin enablement) and consumes substantially more tokens, so Claude Code shows a confirmation prompt before triggering one.
A quieter but consequential developer change rounds out the release: the Messages API now accepts system entries inside the messages array, not just the top-level system parameter. This lets harnesses update Claude’s instructions mid-task—adjusting permissions, token budgets, or environment context as an agent runs—without breaking the prompt cache or routing the update through a user turn. For long agentic runs, that means steering the model mid-flight while still paying cached-input rates on everything that came before.
Availability: not API-only
A common question about frontier releases is whether they launch behind the API exclusively. For Opus 4.8, the answer is clearly no—it is broadly available from day one. Anthropic states the model “is available everywhere today.”
Concretely, that means:
- Claude.ai — the consumer and Pro/Max/Team/Enterprise web app
- Claude Code — Anthropic’s agentic coding environment
- Claude API — via the model ID
claude-opus-4-8 - Amazon Bedrock
- Google Cloud Vertex AI
- Microsoft Foundry
- GitHub Copilot — selectable on day one, per Codersera
One deployment nuance: Codersera reports the full 1M-token context is available on the Claude API, Bedrock, and Vertex AI, while Microsoft Foundry launched at a 200K context. LLM Stats also cautions that Vertex AI may lag a short window before the publisher model resolves, so teams routing through Vertex should confirm claude-opus-4-8 is live there before cutting traffic over, keeping the direct Anthropic route as primary in the meantime. Fast mode, as noted, remains gated to a research preview rather than general availability.
So while the standard model is genuinely available everywhere, the newest capabilities—fast mode and dynamic workflows—are still in staged research-preview rollouts.
Pricing in the wider frontier
At $5/$25 per million tokens, Opus 4.8 is now among the most expensive frontier models on the market. Codersera’s rate-card comparison puts GPT-5.5 at roughly $3/$15 (estimated), Gemini 3.1 Pro at $2–$4 input / $12–$18 output, and budget challengers like DeepSeek V4-Pro at a fraction of the cost—roughly 12× cheaper on input and 29× cheaper on output. The emerging 2026 consensus pattern is a tiered architecture: Opus 4.8 as the high-judgment planner, with cheaper models executing the bulk work.
Cost can be softened considerably. Prompt caching cuts cache reads to about $0.50 per million (a 90% saving), the Batch API offers 50% off both sides for asynchronous work, and the minimum cacheable prompt length dropped to 1,024 tokens—useful for short-system-prompt agentic loops. Stacked, a cached batch read can fall to roughly 5% of the standard rate.
What’s next, and how it landed
Anthropic was candid that Opus 4.8 is “a modest but tangible improvement on its predecessor.” The company is working on cheaper models with Opus-level capability, and—more notably—on a higher-intelligence Mythos-class model. Under Project Glasswing, a small number of organizations already use Claude Mythos Preview for cybersecurity work, but its capability level demands stronger cyber safeguards before general release. Anthropic expects to bring Mythos-class models to all customers “in the coming weeks,” a timeline echoed in parallel reporting from Axios and the New York Times—the latter noting Anthropic’s recent $65 billion raise at a roughly $900B+ valuation.
Reception has been measured rather than euphoric. Mashable noted skepticism on Reddit, where users worried about losing access to older favorites and grumbled that “nobody trusts the benchmark charts.” That skepticism is fair—the deltas are small, two scores dipped, and the numbers are self-reported. But the more honest framing is that the benchmark race is saturating, and the real story has shifted to the operational layer: parallel-subagent workflows for codebase-scale work, prompt-cache-safe mid-task steering, a meaningfully cheaper fast mode, and an alignment assessment that finally puts hard numbers on honesty.
For teams already on the Opus rate card, the calculus is simple: same price, same context, same API surface, demonstrably better agentic coding and knowledge work, and a model that is markedly less likely to lie to you about what it just did. Opus 4.8 won’t reset the leaderboards, but for unattended, long-horizon agentic work, its mix of incremental capability and behavioral reliability is exactly the direction that counts—at least until Mythos arrives.
Claude Opus Comparisons
Claude Opus Coverage
- Claude Opus 4.8 launch coverage
- Claude Opus 4.7 coding upgrade
- Claude Opus 4.7 safety and honesty coverage
- Claude Opus 4.8 dynamic workflows and coding assistants
Claude Opus Launch Tracker
The Kingy Brief
Get The Kingy Brief.
Every week: what launched, what changed price, and what scored well — built on KALI.
Weekly · Double opt-in · Unsubscribe anytime