
A practical briefing on what launched, how it performs, what it costs, and how to actually use it.
DeepSeek’s new V4 family is the most consequential open-weight model drop of this generation, and not just because the benchmarks are strong. It is the first open-weight system that makes routine 1-million-token context feel economically realistic, with list prices that undercut GPT-5.5 and Claude Opus 4.7 by an order of magnitude or more. According to DeepSeek’s official model card on Hugging Face, V4 is a preview release built around a hybrid long-context attention architecture, a new residual-stream scheme, the Muon optimizer, and a post-training pipeline that trains domain specialists and consolidates them through on-policy distillation.
This is not a bigger V3.2. It is a different system with a different cost curve.
1. What Actually Launched
DeepSeek V4 is a family, not a single model. The DeepSeek-V4-Pro and DeepSeek-V4-Flash Hugging Face cards list four open-weight checkpoints under an MIT license:
| Model | Total params | Active params | Context | Precision |
|---|---|---|---|---|
| DeepSeek-V4-Flash-Base | 284B | 13B | 1M | FP8 Mixed |
| DeepSeek-V4-Flash | 284B | 13B | 1M | FP4 + FP8 Mixed |
| DeepSeek-V4-Pro-Base | 1.6T | 49B | 1M | FP8 Mixed |
| DeepSeek-V4-Pro | 1.6T | 49B | 1M | FP4 + FP8 Mixed |
The instruct models use mixed FP4/FP8 precision — MoE expert weights in FP4, most other weights in FP8 — while the base models are FP8 mixed. The model card calls V4-Pro-Max, the maximum-reasoning-effort mode of V4-Pro, the new state of the art among open-source models and says it significantly narrows the gap with leading closed-source systems on reasoning and agentic tasks. Both models were pre-trained on more than 32T tokens.
The more interesting number is efficiency. In the 1M-token setting, the Hugging Face card reports that V4-Pro requires only 27% of single-token inference FLOPs and 10% of the KV cache of DeepSeek-V3.2. V4-Flash pushes that further. This is the “killer feature” — it is not just that the model can accept 1M tokens, it is that it can do so without the serving economics collapsing.
Reuters previously reported in early April that DeepSeek V4 was imminent and optimized for Huawei’s Ascend chips, which explains some of the infrastructure-engineering focus in the technical report.
2. The Technical Story: Why V4 Matters
DeepSeek kept the high-level recipe — Transformer backbone, Mixture-of-Experts feed-forward layers, Multi-Token Prediction — but rewrote three major pieces.
Hybrid long-context attention
The main bottleneck V4 attacks is the quadratic cost of attention over very long sequences. The Hugging Face card describes a hybrid that combines:
- Compressed Sparse Attention (CSA): compresses the KV cache along the sequence dimension, then applies sparse selection so each query attends to a chosen subset of compressed KV entries. In V4-Flash, CSA uses compression rate 4 and top-k 512; in V4-Pro, top-k is 1024.
- Heavily Compressed Attention (HCA): uses a much larger compression rate (128 in the official configuration) and keeps attention dense over the heavily compressed entries — a cheap global memory path.
The two are interleaved through the stack. CSA preserves targeted retrieval capacity; HCA provides low-cost global coverage. The net effect is that million-token windows stop blowing up the KV cache.
Manifold-Constrained Hyper-Connections (mHC)
V4 replaces ordinary residual connections with Manifold-Constrained Hyper-Connections. The idea is to widen the residual stream and constrain the residual mapping to a stable manifold — specifically doubly stochastic matrices — to improve signal propagation and training stability. In the official config, V4 uses an mHC expansion factor of 4 with 20 Sinkhorn-Knopp iterations. This is one of the more interesting choices in the release, because it is a capacity/stability change rather than a serving optimization.
Muon optimizer and infrastructure work
The model card notes V4 uses the Muon optimizer for most modules, retaining AdamW for embeddings, prediction heads, some mHC parameters, and RMSNorm weights, and attributes faster convergence and improved stability to Muon. The accompanying engineering work is also substantial: fused MoE kernels, TileLang kernel development, FP4 quantization-aware training for routed expert weights, batch-invariant deterministic kernels, two-stage contextual parallelism for long-context attention, and a heterogeneous KV-cache system with on-disk storage.
V4 is designed as a production long-context system, not just a benchmark model.
3. Post-training: Why There Are “Modes”
V4 has Non-think, Think High, and Think Max reasoning modes, documented explicitly on the model card. Thinking is enabled by default, with reasoning_effort set to high by default; complex agentic requests may route to max. The official DeepSeek API pricing page confirms both deepseek-v4-flash and deepseek-v4-pro support both thinking and non-thinking modes, and notes that the legacy deepseek-chat and deepseek-reasoner names are deprecated aliases mapped into V4-Flash modes.
Post-training used a two-stage paradigm: independent cultivation of domain specialists (through SFT and RL with GRPO) across math, coding, agents, and instruction following, followed by unified consolidation via on-policy distillation. The practical implication: “V4-Pro-Max” is V4-Pro with a higher reasoning budget and different inference behavior. On hard tasks, Max is materially better.
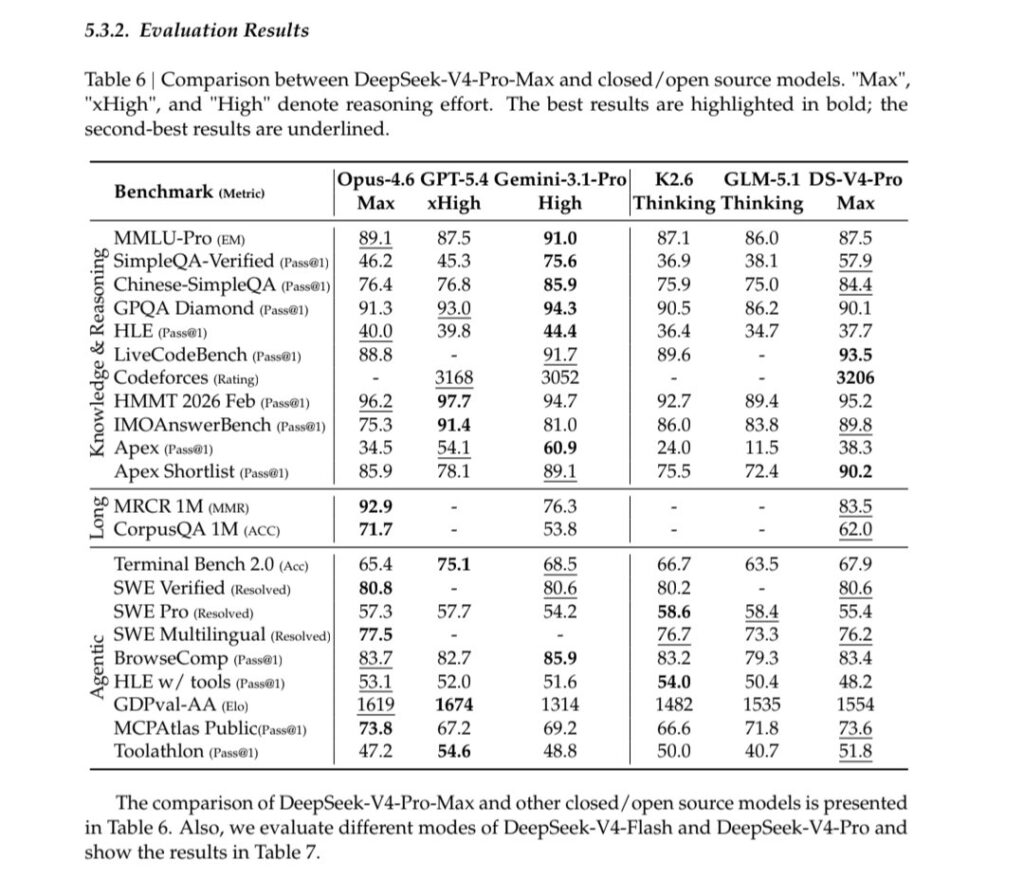
4. Headline Benchmarks
DeepSeek’s own instruct table on the Hugging Face card positions V4-Pro-Max against Claude Opus 4.6 Max, GPT-5.4 xHigh, Gemini 3.1 Pro High, Kimi K2.6 Thinking, and GLM-5.1 Thinking. Selected numbers:
| Benchmark | V4-Pro-Max | GPT-5.4 xHigh | Opus 4.6 Max | Gemini 3.1 Pro | Kimi K2.6 | GLM-5.1 |
|---|---|---|---|---|---|---|
| SimpleQA-Verified | 57.9 | 45.3 | 46.2 | 75.6 | 36.9 | 38.1 |
| GPQA Diamond | 90.1 | 93.0 | 91.3 | 94.3 | 90.5 | 86.2 |
| HLE | 37.7 | 39.8 | 40.0 | 44.4 | 36.4 | 34.7 |
| LiveCodeBench | 93.5 | — | 88.8 | 91.7 | 89.6 | — |
| Codeforces (rating) | 3206 | 3168 | — | 3052 | — | — |
| Apex Shortlist | 90.2 | 78.1 | 85.9 | 89.1 | 75.5 | 72.4 |
| MRCR 1M | 83.5 | — | 92.9 | 76.3 | — | — |
| Terminal Bench 2.0 | 67.9 | 75.1 | 65.4 | 68.5 | 66.7 | 63.5 |
| SWE Verified | 80.6 | — | 80.8 | 80.6 | 80.2 | — |
| BrowseComp | 83.4 | 82.7 | 83.7 | 85.9 | 83.2 | 79.3 |
The pattern is clear: V4-Pro-Max leads on LiveCodeBench, Codeforces, and Apex Shortlist, stays within striking distance of frontier closed models on GPQA/HLE, and trails Claude Opus 4.6 on MRCR 1M long-context recall and Gemini 3.1 Pro on broad factual benchmarks.
5. How It Compares to GPT-5.5 and Claude Opus 4.7
DeepSeek’s official table compares against GPT-5.4 and Opus 4.6, not the current frontier. OpenAI describes GPT-5.5 as its smartest model, especially strong on coding, research, and data analysis. Anthropic lists Claude Opus 4.7 as its most capable generally available model for complex reasoning and agentic coding, with a 1M context window, 128K max output, adaptive thinking, and pricing of $5/M input and $25/M output.
Comparing across reported numbers (different harnesses, caveat emptor):
| Benchmark | V4-Pro-Max | GPT-5.5 | Opus 4.7 |
|---|---|---|---|
| Terminal-Bench 2.0 | 67.9 | 82.7 | 69.4 |
| SWE-Bench Pro | 55.4 | 58.6 | 64.3 |
| GPQA Diamond | 90.1 | 93.6 | 94.2 |
| HLE (no tools) | 37.7 | 41.4 | 46.9 |
| BrowseComp | 83.4 | 84.4 | 79.3 |
The honest read: GPT-5.5 and Opus 4.7 remain ahead in several hard agentic and knowledge-heavy settings — GPT-5.5 notably on Terminal-Bench, Opus 4.7 on SWE-Bench Pro and HLE. But V4’s value proposition is different. It is open-weight, dramatically cheaper, and built for efficient 1M context. On coding competitions and several math benchmarks, V4-Pro-Max is already extremely competitive with the previous frontier tier.
Independent rankings like Artificial Analysis are still catching up; at the time of writing, their DeepSeek page still emphasized V3.2 rather than a full V4 evaluation.
6. Long Context: The Real Story
V4’s 1M-token pitch has two sides: efficiency and performance.
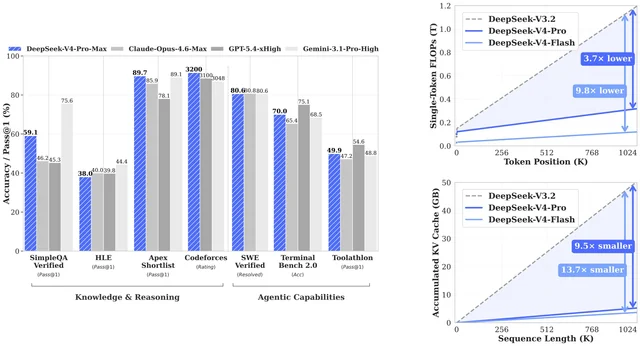
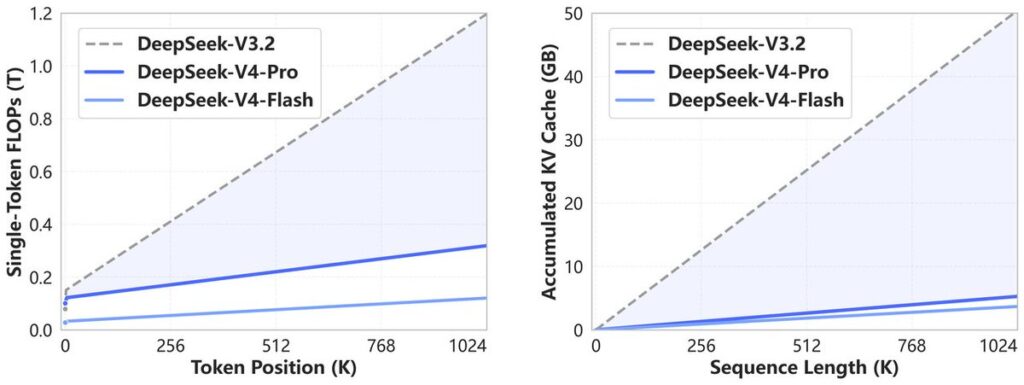
On efficiency, V4 is the most interesting release in a while. The Hugging Face card reports that at 1M context, V4-Pro uses roughly 3.7× lower single-token FLOPs and ~9.5× smaller KV cache than V3.2; V4-Flash pushes that to about 9.8× lower FLOPs and 13.7× smaller KV cache. For anyone running long-document pipelines, these are the numbers that matter more than any single benchmark score.
On performance, V4-Pro-Max scores 83.5 on MRCR 1M and 62.0 on CorpusQA 1M in the official table. That is ahead of Gemini 3.1 Pro on both, but still behind Claude Opus 4.6 (92.9 MRCR, 71.7 CorpusQA). The model’s retrieval stays strong through about 128K, then degrades gradually through the far end of the window.
Practical takeaway: V4 is very likely one of the best choices for cheap, high-volume million-token document processing, especially when you can exploit context caching. For the very hardest long-context retrieval, Anthropic’s top models may still edge it out.
7. Coding, Math, and Agents
Coding
V4-Pro-Max is excellent at competitive programming — Codeforces rating 3206, ahead of GPT-5.4 xHigh (3168) and Gemini 3.1 Pro High (3052) in DeepSeek’s own table. On software-engineering agent tasks the picture is more mixed. V4-Pro-Max ties the leaders on SWE Verified (80.6) but trails Kimi K2.6 and GLM-5.1 on SWE Pro (55.4). For pure agentic coding at the frontier, GPT-5.5 and Opus 4.7 still look stronger.
Math
V4 is extremely strong on math-heavy benchmarks — 95.2 on HMMT 2026 Feb, 89.8 on IMOAnswerBench, 90.2 on Apex Shortlist. The formal-math section of the technical report is striking, with V4-Flash-Max reported at 81.0 on a practical Putnam-200 setting, far above the comparable baseline in DeepSeek’s figures.
Agents and tool use
V4-Pro-Max performs well on multi-tool benchmarks: MCPAtlas 73.6, Toolathlon 51.8, BrowseComp 83.4, and HLE-with-tools 48.2. DeepSeek also describes its production sandbox infrastructure, DeepSeek Elastic Compute, built from Rust components, function-call execution, containers, microVMs, and fullVMs, managing hundreds of thousands of concurrent sandbox instances. That matters because agent quality is increasingly constrained by the execution stack, not just the model.
8. Real-World Writing and Search
The technical report includes internal real-world evaluations. On Chinese functional writing, V4-Pro reportedly beats Gemini 3.1 Pro with a 62.7% win rate vs 34.1%, with similar margins on creative writing. On the hardest Chinese writing prompts, however, Claude Opus 4.5 still leads V4-Pro (52.0% vs 45.9%).
On search, DeepSeek distinguishes retrieval-augmented search in non-thinking mode from agentic search in thinking mode. In an internal comparison, agentic search wins 61.7% of 869 tasks, RAG wins 18.3%, and ties sit at 20.0%. The cost tradeoff is real: agentic search averages 16.2 tool calls, 13,649 prefill tokens, and 1,526 output tokens per task, versus 10,453 prefill and 1,308 output tokens for RAG. That is exactly the long-context, repeated-prefix, many-tool workload V4 was engineered for.
9. Pricing
Here the story is almost embarrassingly simple. From the official DeepSeek API pricing page:
| Model | Input (cache miss) | Input (cache hit) | Output | Context | Max output |
|---|---|---|---|---|---|
deepseek-v4-flash | $0.14/M | $0.028/M | $0.28/M | 1M | 384K |
deepseek-v4-pro | $1.74/M | $0.145/M | $3.48/M | 1M | 384K |
| GPT-5.5 | $5.00/M | $0.50/M | $30.00/M | 1M | — |
| GPT-5.5 Pro | $30.00/M | — | $180.00/M | — | — |
| Claude Opus 4.7 | $5.00/M | up to 90% caching discount | $25.00/M | 1M | 128K |
The pricing docs also explicitly note that deepseek-chat and deepseek-reasoner are deprecated aliases corresponding to the non-thinking and thinking modes of deepseek-v4-flash.
Cost examples
For 1M input tokens + 50K output tokens, cache-miss:
| Model | Approx cost |
|---|---|
| DeepSeek V4 Flash | $0.154 |
| DeepSeek V4 Pro | $1.914 |
| Claude Opus 4.7 | $6.25 |
| GPT-5.5 | $6.50 |
| GPT-5.5 Pro | $39.00 |
For 128K input + 8K output, cache-miss:
| Model | Approx cost |
|---|---|
| DeepSeek V4 Flash | $0.020 |
| DeepSeek V4 Pro | $0.251 |
| Claude Opus 4.7 | $0.840 |
| GPT-5.5 | $0.880 |
| GPT-5.5 Pro | $5.280 |
Rough summary: V4-Pro is about 3× cheaper than GPT-5.5 on uncached input and ~8.6× cheaper on output; V4-Flash is dramatically cheaper still. Context caching, which DeepSeek enables by default and bills transparently via cache-hit/cache-miss token counts in usage, makes V4 especially attractive for workflows with long shared system prompts, repeated document prefixes, or stable tool schemas.
10. How to Actually Use It
In the web app
Use the DeepSeek chat interface for ordinary interaction. The API docs are clearer about behavior: thinking is enabled by default, with high effort unless you explicitly request otherwise.
Via the API (OpenAI-compatible)
DeepSeek’s API is compatible with both OpenAI and Anthropic SDK formats. The base URL is https://api.deepseek.com (or https://api.deepseek.com/anthropic for the Anthropic-style interface). The model names are deepseek-v4-flash and deepseek-v4-pro.
pythonCopyimport os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["DEEPSEEK_API_KEY"],
base_url="https://api.deepseek.com",
)
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "You are a careful technical analyst."},
{"role": "user", "content": "Analyze this design doc and identify the top risks."},
],
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}},
)
print(response.choices[0].message.content)
For maximum reasoning:
pythonCopyresponse = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[{"role": "user", "content": "Solve this hard programming contest problem."}],
reasoning_effort="max",
extra_body={"thinking": {"type": "enabled"}},
)
For cheap, fast non-thinking use:
pythonCopyresponse = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "Summarize this email thread."}],
extra_body={"thinking": {"type": "disabled"}},
)
DeepSeek notes that temperature, top_p, presence penalty, and frequency penalty have no effect in thinking mode. For local deployment, the model card recommends using the encoding folder for tokenization rather than a Jinja chat template, temperature=1.0, top_p=1.0, and at least a 384K context window for Think Max.
Tool use
V4 supports tool calls. In thinking mode, the docs warn that after a tool call you must pass back both reasoning_content and content; otherwise the API can return a 400 error.
Local deployment
The weights are on Hugging Face under an MIT license. But “local deployment” is not “run this on a laptop.” V4-Pro is a 1.6T-parameter MoE (49B active per token). V4-Flash is smaller but still a 284B-parameter MoE. Expect serious multi-GPU or specialized inference infrastructure unless you are using a quantized community serving stack.
11. Which Model, When
| Use case | Best starting choice |
|---|---|
| Cheap summarization, extraction, long-document Q&A | V4-Flash, non-think or high |
| Hard reasoning, math, coding competitions | V4-Pro-Max |
| Software engineering agents where top quality matters more than price | GPT-5.5 or Opus 4.7; compare V4-Pro |
| 1M-token enterprise document workflows | V4-Pro or V4-Flash with caching |
| Chinese writing or search workloads | V4-Pro |
| Local/open-weight experimentation | V4-Flash first; V4-Pro if you have the hardware |
| Best closed frontier capability regardless of cost | GPT-5.5 / GPT-5.5 Pro / Opus 4.7 |
12. Caveats
A few things worth being honest about:
- Most numbers are self-reported. DeepSeek’s figures are detailed and internally consistent, but independent leaderboards like Artificial Analysis have not fully re-evaluated V4 yet.
- “Open source” here means open-weight under MIT license, not full openness of training data, pipeline, or serving stack.
- V4 is not presented as a multimodal-first model. If you need vision, screen use, or computer-use workflows, GPT-5.5, Claude Opus 4.7, Gemini, and multimodal Qwen/Kimi variants remain better starting points.
- Serving infrastructure matters. The advertised 1M-token economics depend on DeepSeek’s caching, sparse-attention, and heterogeneous KV cache stack. Third-party hosts may price or rate-limit differently.
Bottom Line
DeepSeek V4 is the most important open-weight model launch of this wave if your priorities are 1M context, low cost, and strong reasoning/coding performance. It does not clearly beat GPT-5.5 or Claude Opus 4.7 across the board — on the newest frontier comparisons, GPT-5.5 looks stronger for many agentic tasks, and Opus 4.7 looks stronger on several hard coding and knowledge benchmarks.
But V4-Pro-Max is close enough in many areas, ahead in some, and dramatically cheaper in all of them. V4-Flash is the sleeper: if its real-world quality holds up at scale, it could quietly become the default model for long-context production systems that previously had no economically viable option at all.
Kingy Launch Brief
Put the week’s verified AI launches in your inbox.
Every Friday, the verified AI launches, apps, funding rounds, pricing changes and under-the-radar moves worth knowing—source-linked and explained in five minutes.
Free · Every Friday · Unsubscribe anytime · No daily email