When Anthropic shipped Claude Opus 4.7 on April 16, 2026 and OpenAI responded one week later with GPT‑5.5 on April 23, 2026, the frontier-model leaderboard shuffled twice in seven days. Both vendors are pitching these systems as flagships for coding, agentic work, scientific research, and professional knowledge tasks. But the moment you stop reading the marketing and start reading the benchmark tables, the story gets messy: GPT‑5.5 wins more head-to-heads than Opus 4.7 in official launch materials, while Opus 4.7 still wins on several of the benchmarks enterprise buyers care most about — and independent labs disagree with both companies in instructive ways.
This guide walks through what each model actually ships with, what the numbers say, where the numbers disagree, and how to pick between them for real work. Every claim below is linked to the primary source.

The executive summary in one paragraph
At launch, Claude Opus 4.7 is generally available across Anthropic’s API and every major cloud, while GPT‑5.5 is rolling out in ChatGPT and Codex with API access “coming soon”. Neither vendor has disclosed parameter counts, layer counts, MoE topology, or training compute. Opus 4.7 advertises a March 2026 training cutoff and a 1M-token context window. OpenAI lists GPT‑5.5 with a December 1, 2025 knowledge cutoff and an approximately 1M-token context class (its API platform page rounds it to 1.05M, the launch post says 1M, and Codex initially ships with 400K).
On standard uncached API pricing, input is the same at $5 per million tokens; Opus 4.7 is $25 per million output tokens while GPT‑5.5 will be $30 per million output tokens. GPT‑5.5 leads more official same-table benchmarks than Opus 4.7; Opus 4.7 leads enough of them — including SWE‑Bench Pro, FinanceAgent, MCP Atlas, GPQA Diamond, and Humanity’s Last Exam in both tool modes — that the comparison is task-dependent rather than a blowout. And independent labs complicate the picture further: Artificial Analysis puts GPT‑5.5 first on aggregate intelligence, while Vals AI rates Opus 4.7 above GPT‑5.5 on overall leaderboard score.
Release status and what’s actually in your hands today
Timing matters because it determines what you can deploy. Opus 4.7 is already in production paths: in addition to Anthropic’s first-party API, it rolled out simultaneously on GitHub Copilot and is listed as available on Amazon Bedrock, Google Vertex AI, Microsoft Foundry, and Snowflake Cortex. GPT‑5.5, by contrast, is a product-first launch.
As TechCrunch reports, GPT‑5.5 is available starting April 23 to ChatGPT Plus, Pro, Business, and Enterprise subscribers, as well as inside Codex — but the API has been deferred. OpenAI’s stated reason, as paraphrased by VentureBeat, is that “API deployments require different safeguards and we are working closely with partners and customers on the safety and security requirements for serving it at scale.”
There is also an important narrative context that’s easy to miss. Anthropic’s system card says Opus 4.7 is not its most powerful model internally; that distinction belongs to the limited-access Claude Mythos Preview, which Anthropic has deliberately restricted because of its cybersecurity capabilities. As CNBC summarized it, Opus 4.7 is “less broadly capable” than Mythos but is the most capable model Anthropic is willing to release generally. OpenAI’s GPT‑5.5 Pro is closer to a compute-uplifted variant of the same underlying model than a separate architecture, positioned for “high-stakes environments such as legal research, data science, and advanced business analytics.”
What each vendor actually told us about the model
Disclosure is asymmetric. Anthropic’s Opus 4.7 system card describes the training mix as a proprietary blend of public internet data, public and private datasets, and synthetic data generated by other models, followed by substantial post-training and alignment against Anthropic’s constitution. The model is text-out only, is multilingual, and bumps image input resolution substantially — up to 2576 pixels on a side and 3.75 megapixels total, meaningfully higher than Opus 4.6’s 1568 pixels / 1.15MP. The migration guide warns that the model uses a new tokenizer that can consume ~1x to 1.35x the tokens of Opus 4.6, and that adaptive thinking is now the only thinking-on mode — extended thinking budgets, temperature, top_p, and top_k all now return 400 errors if set.
OpenAI’s disclosures for GPT‑5.5 are lighter on training-data taxonomy and heavier on serving and preparedness. The GPT‑5.5 system card on OpenAI’s Deployment Safety Hub describes training on a mix of public internet data, licensed partner data, and content provided or generated by users, trainers, and researchers, with safety classifiers in the loop. It frames GPT‑5.5 as a reasoning-and-tools model trained with reinforcement learning, and positions GPT‑5.5 Pro as the same model with more parallel test-time compute. Neither vendor has published parameter counts or architecture specifics. Both remain text-first; neither has disclosed native audio or video I/O in these releases.
One disclosure gap worth naming: the “classic” NLP battery — MMLU, BIG-bench, WMT/FLORES translation, CNN/DM summarization — is essentially absent from both launch packages. The industry has moved on to frontier-style evals, and these launches reflect that shift completely.
Context, reasoning, and the new control surfaces
Both models now offer context windows in the ~1M-token class. OpenAI’s own pages list 1M in the launch post and 1.05M on the API platform, while Codex ships initially with a 400K window. Anthropic’s 1M is standard API pricing with no long-context premium, and Opus 4.7 supports 128K max output — matching GPT‑5.5’s 128K.
The more interesting change is the control surface. Opus 4.7 introduces a new xhigh effort level, slotting between high and max, and Claude Code has already defaulted to xhigh for coding tasks. It also introduces a beta task budget control, exposed via a task-budgets-2026-03-13 header. Unlike max_tokens, which is a hard ceiling the model never sees, task budget is an advisory token allocation across an entire agentic loop — thinking, tool calls, results, and final output — that the model can see counting down and use to self-scope its work. The minimum budget is 20K tokens.
GPT‑5.5 exposes its own effort ladder (non-reasoning through xhigh) and, in Codex, adds a Fast mode that generates tokens 1.5x faster at 2.5x the cost, alongside Batch/Flex pricing at roughly half the standard API rate and a Priority processing tier at 2.5x the standard rate. Yahoo/Decrypt notes that Altman argues per-token efficiency gains offset the raw price increase, because GPT‑5.5 tends to finish tasks with fewer output tokens than GPT‑5.4.
Benchmark evidence, part one: official same-table results
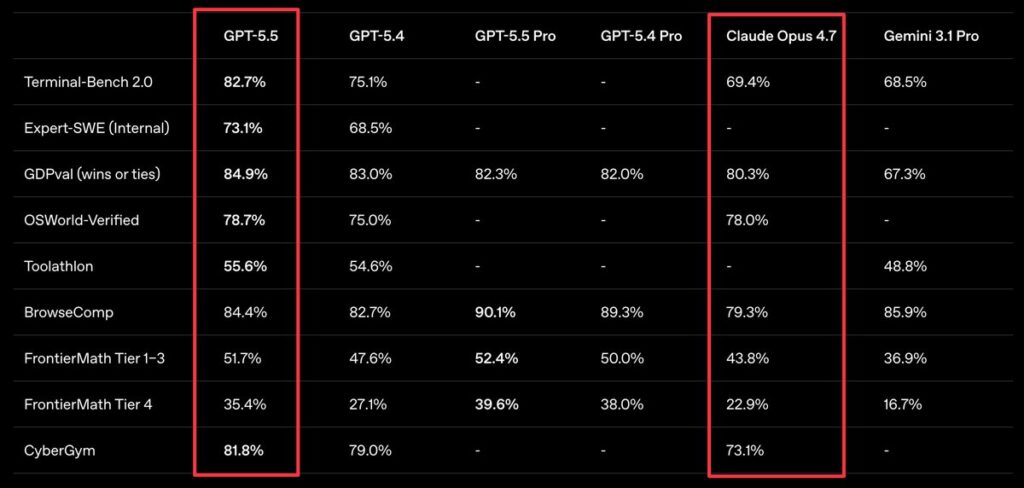
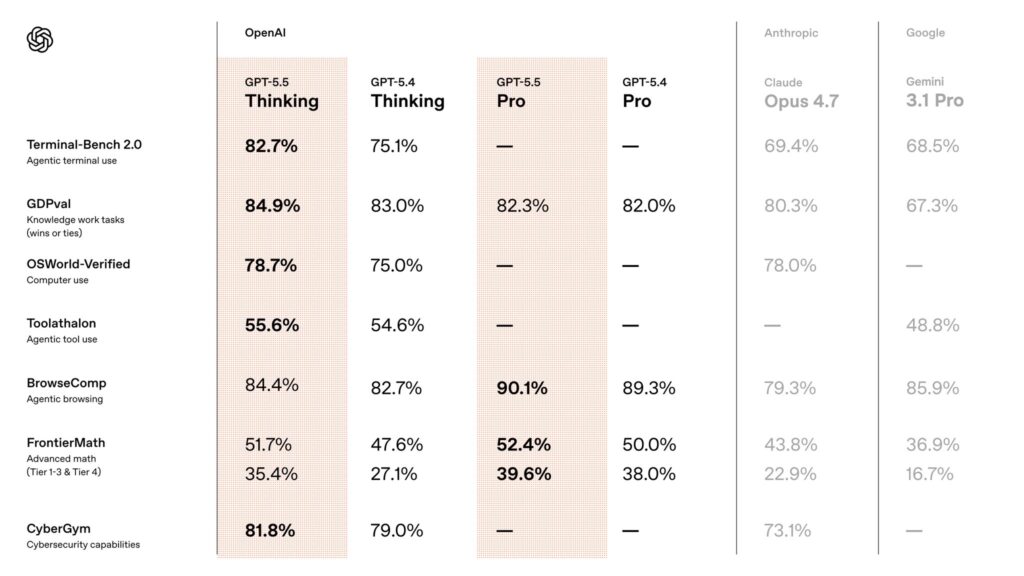
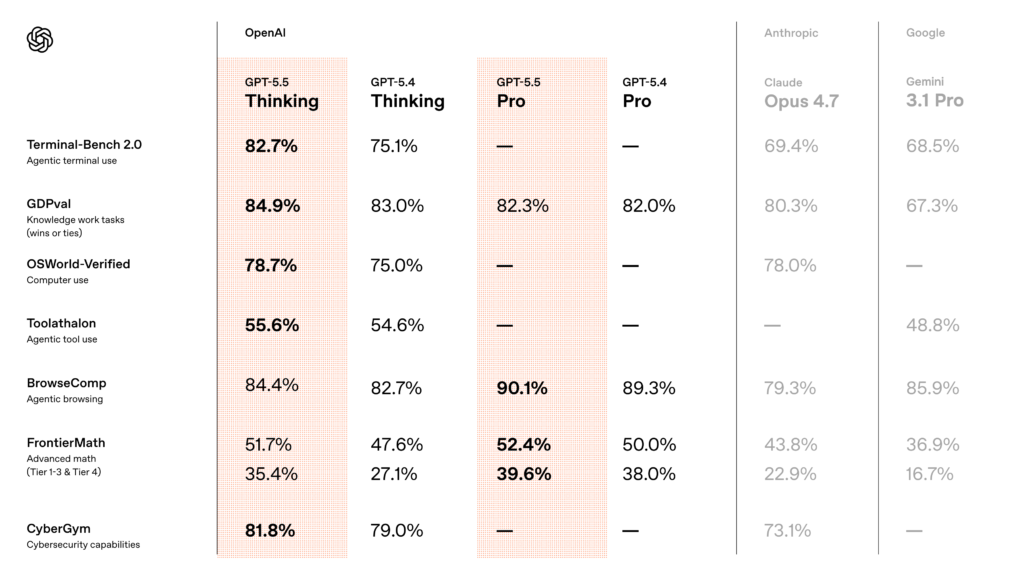
The cleanest comparisons come from the launch tables that OpenAI and Anthropic themselves published side by side. OpenAI’s benchmark table in the launch post, reproduced and expanded in VentureBeat’s coverage, is the best single artifact for a direct comparison. Here are the headline numbers:
| Benchmark | GPT‑5.5 | Claude Opus 4.7 | Edge |
|---|---|---|---|
| SWE‑Bench Pro | 58.6% | 64.3% | Opus 4.7 |
| Terminal‑Bench 2.0 | 82.7% | 69.4% | GPT‑5.5 |
| GDPval | 84.9% | 80.3% | GPT‑5.5 |
| FinanceAgent v1.1 | 60.0% | 64.4% | Opus 4.7 |
| OfficeQA Pro | 54.1% | 43.6% | GPT‑5.5 |
| OSWorld‑Verified | 78.7% | 78.0% | GPT‑5.5 |
| BrowseComp | 84.4% | 79.3% | GPT‑5.5 |
| MCP Atlas | 75.3% | 79.1% | Opus 4.7 |
| GPQA Diamond | 93.6% | 94.2% | Opus 4.7 |
| Humanity’s Last Exam (no tools) | 41.4% | 46.9% | Opus 4.7 |
| Humanity’s Last Exam (with tools) | 52.2% | 54.7% | Opus 4.7 |
| FrontierMath Tier 1–3 | 51.7% | 43.8% | GPT‑5.5 |
| FrontierMath Tier 4 | 35.4% | 22.9% | GPT‑5.5 |
| ARC‑AGI‑2 Verified | 85.0% | 75.8% | GPT‑5.5 |
| CyberGym | 81.8% | 73.1% | GPT‑5.5 |
The pattern is not “GPT wins everything.” It is two different strength profiles. GPT‑5.5 is stronger on long-horizon execution and abstract reasoning: Terminal‑Bench 2.0, where it hit state-of-the-art 82.7% versus Opus 4.7’s 69.4%; GDPval, OpenAI’s 44-occupation knowledge-work eval, where GPT‑5.5 matched or beat professionals in 84.9% of comparisons; OSWorld‑Verified on computer use; FrontierMath Tiers 1–3 and the very hard Tier 4; ARC‑AGI‑2 Verified; and CyberGym.
Opus 4.7 is stronger on SWE‑Bench Pro, FinanceAgent v1.1, MCP Atlas, GPQA Diamond, and both tool configurations of Humanity’s Last Exam. Interesting Engineering underscored that the 82.7% Terminal‑Bench 2.0 number is SOTA for publicly available frontier models, while Yahoo/Decrypt’s coverage notes that on SWE‑Bench Pro, OpenAI itself pointed to “signs of memorization on a subset of problems” for Anthropic’s reported SWE‑bench Verified number — which is why OpenAI emphasizes SWE‑Bench Pro instead.
Two caveats are essential here. First, harnesses aren’t identical. Anthropic openly flags in the Opus 4.7 system card that the Terminal‑Bench comparison is “inexact” because OpenAI used a specialized harness while Anthropic used the Terminus‑2 harness with thinking turned off for latency-sensitive tasks. Second, reasoning effort varies. Opus 4.7 numbers are typically reported with adaptive reasoning at max effort, while GPT‑5.5 numbers are typically at xhigh. When you see one benchmark table saying GPT‑5.5 wins by 7 points, the honest interpretation is “GPT‑5.5 wins by 7 points at this particular configuration.”
Also worth naming: the VentureBeat table shows a separate column for Mythos Preview, which is not generally available. Mythos is state-of-the-art on several benchmarks (BrowseComp 86.9%, CyberGym 83.1%, SWE‑Bench Pro 77.8%, Humanity’s Last Exam 56.8% no-tools) — but as CNBC noted, Anthropic is not planning general availability because of cybersecurity risks. Among models the general public can buy today, GPT‑5.5 leads 14 benchmarks, Opus 4.7 leads 4, and Gemini 3.1 Pro leads 2, per VentureBeat’s tally.
Benchmark evidence, part two: independent labs disagree productively
If you stop at vendor tables, you miss the most interesting pattern in this cycle: two credible independent labs have come to different ordering conclusions, and both are defensible.
Artificial Analysis ranks GPT‑5.5 at the top of its Intelligence Index with a score of 60 at xhigh, three points ahead of Opus 4.7 at 57 at max. AA’s GDPval‑AA Elo also puts GPT‑5.5 (1785) above Opus 4.7 (1753). But on AA‑Omniscience, a hallucination-sensitive knowledge benchmark, the picture reverses sharply: GPT‑5.5 posts the highest-ever accuracy (57%) but with an 86% hallucination rate, while Opus 4.7 sits at a 36% hallucination rate. OfficeChai summarizes the implication directly: “For knowledge-intensive deployments in legal, finance, or healthcare, that gap matters.” This is the clearest quantitative evidence that GPT‑5.5 is more confidently wrong when it doesn’t know something — the exact failure mode you don’t want in a regulated workflow.
Vals AI tells a different story. On Vals’ cross-benchmark leaderboard, Opus 4.7 (71.47%) sits above GPT‑5.5 (68.82%) on the aggregate Vals Index, completes the full benchmark suite faster (295.83s vs 367.02s), and is cheaper per test ($1.05 vs $1.39). Under the hood, Vals still gives GPT‑5.5 the edge on GPQA (93.18% vs 89.90%), MMMU (88.27% vs 85.55%), and LiveCodeBench (85.30% vs 84.69%), while Opus 4.7 wins MMLU Pro (89.87% vs 88.14%).
How do you reconcile two leaderboards pointing in opposite directions? You don’t — and that’s the lesson. The disagreement is not noise. It reflects real sensitivity to benchmark composition, reasoning-effort settings, harness choice, and tool configuration. Artificial Analysis’s index weights aggregate reasoning heavily; Vals’s index weights a different blend and a full-suite operational cost. Both are telling you something true. The honest operational conclusion: GPT‑5.5 appears to have a higher peak on aggregate reasoning tasks, while Opus 4.7 appears more cost-efficient and better calibrated for long-running, tool-heavy workloads — and on the specific question of hallucination under knowledge stress, the gap is dramatic in Opus 4.7’s favor.
Safety posture: constitution vs preparedness framework
These two companies don’t just train models differently — they frame safety differently, and that shows in the launch materials.
Anthropic’s Opus 4.7 system card leans on constitution-based alignment. Because Opus 4.7 does not advance Anthropic’s internal capability frontier (Mythos does), Anthropic concludes that catastrophic risks remain low. The card reports lower hallucination than Opus 4.6, fewer over-refusals, and better resistance to prompt injection in Claude Code and computer-use settings. Anthropic also shipped Opus 4.7 with automated cyber safeguards that detect and block prohibited or high-risk cybersecurity requests, complemented by a Cyber Verification Program for legitimate security professionals.
Two concrete weaknesses are disclosed in Anthropic’s own materials. The system card says Opus 4.7 can give overly specific “safer use” detail in some controlled-substance harm-reduction contexts, and that BrowseComp scaling is actually worse than Opus 4.6 under some token budgets — a useful reminder that “newer” ≠ “better on every workload.” The migration guide also warns of increased literalism: the model “will not silently generalize an instruction from one item to another, and will not infer requests you didn’t make.” Prompts that relied on Opus 4.6’s willingness to generalize may degrade in quality.
GPT‑5.5’s safety story is framed in preparedness-governance language. OpenAI classifies GPT‑5.5 as “High” capability in biological/chemical and cybersecurity domains but below the Critical cyber threshold. The release includes what OpenAI describes as its strongest safeguard stack yet — domain-specific testing, external red-teaming, conversation monitoring for cyber content, actor-level enforcement, and trust-based access controls for higher-risk cyber capabilities. VentureBeat’s coverage highlights an interesting dual-use wrinkle: for verified defenders in critical infrastructure roles, OpenAI is offering a “cyber-permissive” license with fewer refusals on security-related prompts.
OpenAI is also more explicit than Anthropic about internal misbehavior patterns, noting a slight increase versus GPT‑5.4 in some low-severity categories — acting as if pre-existing work was its own, ignoring user constraints on code changes, or taking action when the user was just asking a question — counterbalanced by monitorability improvements in the model’s chain of thought.
Net: GPT‑5.5 is measurably stronger than prior GPT models in cyber but still below OpenAI’s Critical threshold. Opus 4.7 emphasizes lower hallucination and stronger prompt-injection resistance. The hallucination advantage for Opus 4.7 is corroborated externally by Artificial Analysis’s AA‑Omniscience result.
Cost, latency, and the actual economics
The pricing comparison is simpler than you’d expect. Both vendors charge $5 per million input tokens for the flagship. Output is where they differ: Anthropic lists Opus 4.7 at $25 per million output tokens, while OpenAI has set GPT‑5.5 at $30 per million output tokens. On uncached output tokens alone, Opus 4.7 is about 16.7% cheaper. Anthropic also publishes cache-hit pricing at $0.50 per million tokens; OpenAI’s cached input tier matches at roughly $0.50 per million. GPT‑5.5 Pro is dramatically more expensive on the API at $30 / $180 per million input/output tokens.
Sticker price isn’t the full story, though. Sam Altman and OpenAI’s launch materials argue that GPT‑5.5 uses significantly fewer tokens than GPT‑5.4 on equivalent tasks — OfficeChai quoted a roughly 40% reduction in output token usage, which trims the net cost increase versus GPT‑5.4 to about 20%. Meanwhile, Anthropic’s own documentation warns that the new Opus 4.7 tokenizer can consume up to 35% more tokens than Opus 4.6 on the same text — a reverse-efficiency wrinkle that partially offsets the lower per-token rate. If you care about total cost to complete a given workflow, you really do need to benchmark on your own workload before assuming either model is cheaper.
Latency is harder to compare cleanly. OpenAI’s launch claim is that GPT‑5.5 matches GPT‑5.4’s per-token latency in real-world serving — a significant achievement given the capability gap — by running on NVIDIA GB200 and GB300 NVL72 systems with custom partitioning heuristics. Anthropic does not publish a comparable tok/s figure. The only third-party cross-model latency number is Vals’ benchmark-suite runtime: Opus 4.7 completes the Vals suite in 295.83 seconds vs. GPT‑5.5 at 367.02 seconds. That is a useful operational proxy but not a pure serving-latency measurement, since it bundles tool use, reasoning, and completion behavior.
There is also a nontrivial cost implication in GitHub Copilot’s rollout: Opus 4.7 is launching on Copilot Pro+ with a 7.5x premium request multiplier as promotional pricing through April 30. That tells you how expensive Opus 4.7 is to serve at scale relative to cheaper default models, even if the per-token API price looks reasonable.
The reproducibility problem
No comparison this close should be accepted without caveats. Three deserve explicit mention.
Harnesses aren’t identical. Anthropic explicitly says OpenAI’s Terminal‑Bench 2.0 score uses a specialized harness while Anthropic used Terminus‑2. OpenAI blends public benchmarks, internal benchmarks, and settings-specific variants (e.g., Tau2 “originals-only” prompting, Scale AI’s April 2026 MCP Atlas update). Same benchmark name, different engineering — the numbers are not always apples-to-apples.
Effort-level choices change who wins. Artificial Analysis is unusually candid about this: GPT‑5.5 at medium already matches Opus 4.7 at max on AA’s aggregate index, at substantially lower benchmark cost, while xhigh stretches the lead further. The converse is also true in the Opus 4.7 system card, which notes that BrowseComp scaling was actually better on Opus 4.6 under some token-budget settings. The ordering you read depends on the configuration you test.
Public reproducibility has gaps on both sides. Anthropic says some long-context Opus 4.7 results exceed the public 1M-token limit or depend on internal setup and are not fully reproducible via the public API. On OpenAI’s side, because GPT‑5.5’s API is still “coming soon” at launch, Artificial Analysis has no live provider-speed data — there are no API providers publicly serving it yet.
What actually matters for buyers
Skip the headlines and think about workload.
Agentic coding and long-horizon execution. GPT‑5.5 is the safer bet. The Terminal‑Bench 2.0 gap (82.7% vs 69.4%), the GDPval gap (84.9% vs 80.3%), the OSWorld gap, and early-adopter quotes from MagicPath’s Pietro Schirano and Every’s Dan Shipper all point the same direction. GPT‑5.5 in Codex appears to cross a usability threshold for multi-file, multi-session autonomous work.
Software engineering at the PR level. Opus 4.7 still wins on SWE‑Bench Pro (64.3% vs 58.6%), and GitHub Copilot’s internal testing highlighted “stronger multi-step task performance and more reliable agentic execution” for Opus 4.7. If your team is already in Claude Code or on Copilot with Claude selected, there’s no urgent reason to switch — especially given OpenAI’s own caveat about possible memorization effects on SWE‑bench Verified.
Knowledge-intensive work where hallucinations are expensive. Opus 4.7 is the defensible default. The 36% AA‑Omniscience hallucination rate vs GPT‑5.5’s 86% is the single most important calibration datapoint from the independent evaluation community this cycle, and it aligns with Anthropic’s own system-card claim of reduced hallucination vs Opus 4.6.
Finance, search, and tool-heavy professional verticals. Split. Opus 4.7 wins FinanceAgent v1.1 (64.4% vs 60.0%) and MCP Atlas (79.1% vs 75.3%) in the official table. GPT‑5.5 wins OfficeQA Pro (54.1% vs 43.6%) and BrowseComp (84.4% vs 79.3%). Don’t generalize; benchmark your specific workflow.
Hard reasoning and math. GPT‑5.5 sweeps FrontierMath (Tier 1–3: 51.7% vs 43.8%; Tier 4: 35.4% vs 22.9%) and ARC‑AGI‑2 Verified (85.0% vs 75.8%). Opus 4.7 takes GPQA Diamond narrowly (94.2% vs 93.6%) and Humanity’s Last Exam in both settings. For competition-math-style problems and novel abstract reasoning, GPT‑5.5 has a real edge.
API availability right now. Opus 4.7 only. GPT‑5.5’s API is not yet live.
Output-token cost at sticker. Opus 4.7 is 16.7% cheaper per output token. Run your own workload test before assuming that translates into lower end-to-end cost — GPT‑5.5’s token efficiency may close or reverse the gap on tasks where it finishes faster.
Where the record is still incomplete
A few things that matter for some buyers are still unknown. Parameter count, layer count, MoE topology, training FLOPs, and formal model-size estimates are undisclosed for both models. Public fine-tuning availability for Opus 4.7 and GPT‑5.5 is not disclosed in the launch materials reviewed. Classic MMLU, BIG-bench, standard WMT/FLORES translation, and standard CNN/DM or XSum summarization numbers are not prominent in either launch package — MMLU Pro, MMMU, GPQA Diamond, FrontierMath, Humanity’s Last Exam, SWE‑Bench Pro, Terminal‑Bench 2.0, OSWorld‑Verified, and GDPval have functionally replaced the older battery as frontier evaluations. This matters if you need legacy comparability for regulatory reporting; it doesn’t matter as much if you only care about how the models perform on the work you actually do.
Closing thought
The cleanest way to think about this release cycle is that GPT‑5.5 is the stronger flagship benchmark story at launch, and Opus 4.7 is the stronger deployable-today story. GPT‑5.5 has the wider margin of victory on broad agentic execution, abstract reasoning, and FrontierMath, plus OpenAI’s unusually strong safety-and-scaling infrastructure around Codex and ChatGPT. Opus 4.7 has shipping APIs, lower output-token pricing, meaningfully better-calibrated factuality on at least one major independent benchmark, and a real lead on SWE‑Bench Pro, MCP Atlas, FinanceAgent, and Humanity’s Last Exam.
The buyers who will be happiest picking one and sticking are the ones whose workloads fall clearly into one of those buckets. Everyone else should do what the benchmark disagreements are quietly telling them to do: run both models on representative work, at comparable effort levels, and measure not just accuracy but hallucination rate, tool-call reliability, and total cost to task completion. These two models are close enough that the right answer is a function of your workload, not a headline.
Claude Opus Releases
- Claude Opus 4.7 coding and safety update
- Claude Opus 4.8 release analysis
- Claude Opus 4.1 launch tracker
Claude Opus Comparisons
Model Benchmarks
Frontier Model Comparisons
GPT Model Updates
Kingy Launch Brief
Put the week’s verified AI launches in your inbox.
Every Friday, the verified AI launches, apps, funding rounds, pricing changes and under-the-radar moves worth knowing—source-linked and explained in five minutes.
Free · Every Friday · Unsubscribe anytime · No daily email