The landscape of artificial intelligence has witnessed an extraordinary metamorphosis with the emergence of Large Language Model (LLM) agents—sophisticated systems that transcend the limitations of passive language models by engaging in autonomous problem-solving, iterative reasoning, and dynamic interaction with external environments.
Yet, despite their remarkable capabilities, these agents face a fundamental dichotomy that has plagued the field: they must choose between rigid, handcrafted workflows that lack adaptability, or computationally intensive parameter fine-tuning that demands substantial resources and risks catastrophic forgetting.
Enter Memento, a groundbreaking paradigm that shatters this false dichotomy by introducing memory-based continual learning for LLM agents—a revolutionary approach that enables continuous adaptation without ever touching the underlying model parameters. This isn’t merely an incremental improvement; it’s a paradigmatic shift that mirrors human cognitive processes, where experiences accumulate in episodic memory and inform future decision-making through sophisticated case-based reasoning mechanisms.
The Cognitive Architecture Revolution
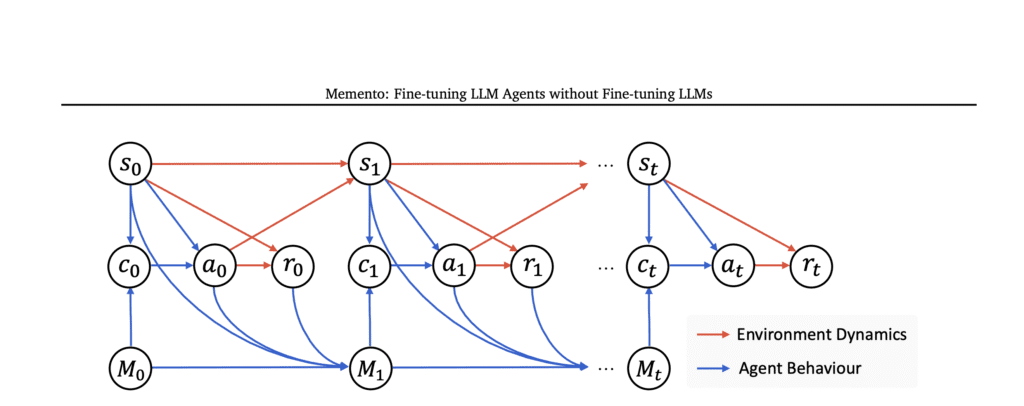
The brilliance of Memento lies in its biomimetic foundation, drawing inspiration from the intricate workings of human memory systems. Just as humans encode experiences as episodic traces, distill abstract rules during consolidation, and retrieve analogous situations when confronting novel problems, Memento implements a Memory-augmented Markov Decision Process (M-MDP) that fundamentally reimagines how AI agents learn and adapt.
This cognitive architecture operates through a sophisticated interplay of three core components: a strategic planner that decomposes complex tasks, a tool-enabled executor that interfaces with external environments, and most crucially, a growing Case Bank that serves as the agent’s episodic memory repository.
Unlike traditional approaches that rely solely on parametric memory frozen after training, Memento’s case-based reasoning system continuously accumulates rich experiential traces—both successes and failures—creating a dynamic knowledge base that grows more sophisticated with each interaction.
The theoretical foundation rests upon a formal M-MDP framework where the memory space M = (S × A × R)* represents the set of all past experiences. At each timestep t, the agent maintains a case bank Mt = {cj}j=1^Nt, where each case cj encapsulates a tuple (sj, aj, rj) representing state, action, and reward.
The agent’s behavior follows a principled case-based reasoning cycle: Retrieve relevant cases using a learned policy μ(·|st, Mt), Reuse and Revise through LLM adaptation P_LLM(·|st, ct), Evaluate performance, and Retain new experiences for future reference.
Dual Memory Architectures: Non-Parametric vs. Parametric
Memento’s architectural sophistication manifests through its dual memory implementation, offering both non-parametric and parametric variants that cater to different computational constraints and performance requirements.
The non-parametric approach embodies computational elegance through simplicity. During the Write operation, new cases are straightforwardly appended to the case bank: Write(st, at, rt, Mt) = Mt+1 = Mt ∪ {(st, at, rt)}. The Read operation leverages semantic similarity, retrieving the K nearest past cases through cosine similarity between encoded states: ReadNP(st, Mt) = TopK(si,ai,ri)∈Mt sim(enc(st), enc(si)). This approach mirrors classical case-based reasoning paradigms, operating under the fundamental assumption that similar problems warrant similar solutions.
Conversely, the parametric approach introduces sophisticated learning dynamics through a neural Q-function that continuously refines case selection policies. Rather than relying solely on surface-level similarity, this method learns deeper patterns between states and cases, implementing a binary classification objective: L(θ) = E(s,c,r)[-r log Q(s,c;θ) – (1-r) log(1-Q(s,c;θ))]. The parametric memory doesn’t just store cases—it actively learns which cases provide the most valuable guidance for specific situations, creating an adaptive retrieval mechanism that becomes increasingly sophisticated over time.
The Deep Research Implementation: A Planner-Executor Symphony
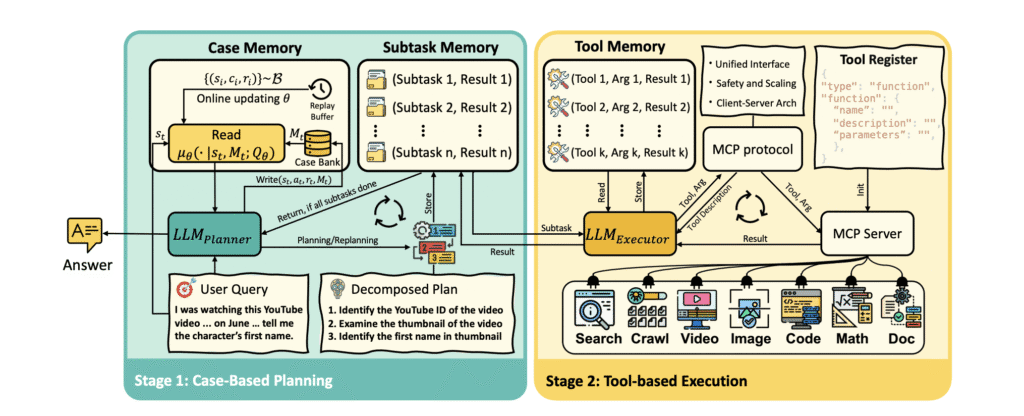
The practical instantiation of Memento as a deep research agent showcases the framework’s versatility and power. The system operates through an elegant alternation between two core stages: Case-Based Planning and Tool-Based Execution, orchestrated through three specialized memory modules.
The Case Memory serves as the system’s cognitive core, implementing both Write operations that record new experiences and online Q-function refinement, and Read operations that retrieve relevant cases through either similarity-based retrieval or learned Q-function guidance. This memory system enables the planner—powered by GPT-4.1—to leverage accumulated experiences when decomposing complex tasks into manageable subtasks.
The Subtask Memory functions as the coordination hub between planner and executor, maintaining text-based storage of active subtasks and their execution outcomes. This intermediate layer ensures seamless information flow and enables iterative refinement of task execution strategies.
The Tool Memory provides granular logging of tool interactions for each subtask, supporting the executor’s decision-making process through detailed historical context. The executor, implemented as a Model Context Protocol (MCP) client, can seamlessly integrate with diverse external tools and data sources through a standardized interface.
Empirical Validation: Achieving State-of-the-Art Performance
The empirical validation of Memento across multiple challenging benchmarks demonstrates its exceptional capabilities and broad applicability. On the prestigious GAIA benchmark—widely regarded as the gold standard for evaluating long-horizon tool use and autonomous planning—Memento achieved remarkable results: 87.88% Pass@3 on the validation set (securing top-1 ranking) and 79.40% on the private test set, outperforming numerous established frameworks including Manus, AWorld, and OWL.
The DeepResearcher evaluation across seven open-domain QA datasets revealed Memento’s superiority in real-time web research and multi-hop reasoning. With an average 66.6% F1 score and 80.4% PM (Partial Match), Memento nearly doubled the performance of CoT + RAG baselines (37.7% F1), demonstrating that real-time, online retrieval tools can rival or exceed carefully curated static databases.
Perhaps most impressively, on SimpleQA—a benchmark specifically designed to evaluate factual accuracy and hallucination resistance—Memento achieved 95.0% accuracy, establishing a new state-of-the-art while outperforming WebSailor (93.5%), WebDancer (90.5%), and other leading web-agent baselines.
The Continual Learning Paradigm: Memory as the Engine of Adaptation
One of Memento’s most compelling attributes lies in its demonstrated continual learning capabilities. Through systematic ablation studies across five learning iterations, the framework consistently improved performance: from 78.65% in iteration 1 to 84.47% by iteration 5 for the baseline, with parametric CBR achieving even more substantial gains (80.46% to 85.44%).
This learning trajectory isn’t merely statistical noise—it represents genuine knowledge accumulation and refinement. The case bank doesn’t simply grow larger; it becomes more discriminating, more nuanced, and more effective at guiding decision-making. The parametric Q-function learns to identify which historical experiences provide the most valuable guidance for specific situations, creating an increasingly sophisticated retrieval mechanism.
The out-of-distribution generalization results provide particularly compelling evidence of Memento’s learning efficacy. When evaluated on unseen datasets (MusiQue, Bamboogle, PopQA) after training on different domains (NQ, TriviaQA, HotpotQA, 2Wiki), Memento achieved substantial improvements ranging from 4.7% to 9.6% absolute gains. This cross-domain transfer capability suggests that the case-based reasoning system captures generalizable problem-solving patterns rather than merely memorizing domain-specific solutions.
Architectural Insights: The Synergy of Planning and Execution
The sophisticated interplay between Memento’s planner and executor components reveals fascinating insights about optimal AI system design. Counterintuitively, the empirical analysis demonstrated that fast, non-deliberative planning (GPT-4.1) consistently outperformed more deliberative approaches (o3) when paired with the same executor, achieving 70.9% vs. 63.03% average accuracy on GAIA.
This finding challenges conventional wisdom about the value of extensive deliberation in AI systems. The analysis revealed that overly deliberative planners often either skip plan generation entirely or produce verbose, potentially misleading instructions. In contrast, concise, structured planning enables more effective downstream execution by providing clear, actionable guidance without overwhelming the executor with unnecessary complexity.
The tool usage statistics across GAIA’s three difficulty levels illuminate how Memento adapts its behavior to task complexity. While code, search, and crawl operations dominate across all levels, their usage patterns reveal that the most challenging problems increasingly rely on sophisticated evidence integration and reasoning rather than simply invoking more tools. This suggests that Memento’s strength lies not just in tool orchestration, but in its ability to synthesize and reason about complex, multi-modal information.
Memory Optimization: The Goldilocks Principle of Case Retrieval
The hyperparameter analysis reveals a fascinating “Goldilocks principle” in case-based reasoning: too few cases provide insufficient context, while too many introduce noise and computational overhead. The optimal performance occurred at K=4 retrieved cases, yielding the highest F1 (64.5%) and PM (78.5%) scores on DeepResearcher. This finding suggests that effective continual learning requires careful curation and selection rather than indiscriminate accumulation of experiences.
This principle extends beyond mere computational efficiency—it reflects deeper insights about how knowledge should be organized and accessed. The parametric Q-function learns to identify not just similar cases, but the most relevant and informative cases for specific situations. This selective retrieval mechanism prevents the “swamping problem” that has historically plagued case-based reasoning systems, where retrieval costs outweigh utility benefits.
Multimodal Integration: Beyond Text-Based Reasoning
Memento’s sophisticated tool ecosystem demonstrates remarkable versatility in handling heterogeneous data sources and modalities. The system seamlessly processes images through vision-language models, transcribes audio via automated speech recognition, parses PowerPoint presentations slide-by-slide with embedded image descriptions, converts spreadsheets to readable formats, and provides natural-language summaries of video content.
This multimodal capability isn’t merely additive—it’s transformative. By providing a unified interface for accessing and interpreting content across diverse file types and modalities, Memento enables reasoning patterns that would be impossible with text-only systems. The integration of code execution environments, mathematical computation tools, and web crawling capabilities creates a comprehensive problem-solving ecosystem that mirrors human researchers’ diverse toolkit.
Theoretical Implications: Soft Q-Learning for Case Selection
The theoretical foundation of Memento’s learning mechanism rests upon an elegant application of soft Q-learning principles to case selection. By formulating case retrieval as an action selection problem within the maximum entropy reinforcement learning framework, the system optimizes both performance and exploration diversity.
The optimal retrieval policy emerges as a softmax distribution over Q-values: μ*(c|s,M) = exp(Q*(s,M,c)/α) / Σc’ exp(Q*(s,M,c’)/α), where α controls the entropy-performance trade-off. This formulation ensures that while high-value cases receive preferential selection, the system maintains sufficient exploration to discover novel problem-solving strategies.
The kernel-based Q-function approximation Q_EC(s,M,c;θ) = Σ(s’,c’,Q’)∈D_c [k_θ(s,s’)Q’] / Σ(s̃,c̃,Q̃)∈D_c k_θ(s,s̃) provides computational tractability while maintaining theoretical rigor. This approach enables the system to generalize across similar states while learning from limited experience, addressing the fundamental challenge of sample efficiency in continual learning scenarios.
Future Horizons: Implications for AI Development
Memento’s success has profound implications for the future trajectory of AI development. By demonstrating that sophisticated continual learning can be achieved without parameter updates, the framework opens new pathways for developing AI systems that can adapt and improve in real-time deployment scenarios.
The memory-based approach offers several compelling advantages over traditional fine-tuning paradigms: computational efficiency (no gradient computations required), catastrophic forgetting resistance (new experiences don’t overwrite existing knowledge), interpretability (case-based decisions can be traced and understood), and modularity (memory systems can be shared across different base models).
Perhaps most significantly, Memento demonstrates that the path to artificial general intelligence need not require ever-larger models with ever-more parameters. Instead, sophisticated memory architectures and case-based reasoning systems may provide a more sustainable and interpretable route to advanced AI capabilities.
The framework’s success across diverse domains—from factual question answering to complex multi-step reasoning—suggests that memory-based learning represents a fundamental cognitive capability that can enhance virtually any AI system. As we continue to push the boundaries of what’s possible with artificial intelligence, Memento stands as a testament to the power of learning from experience, adaptation through memory, and the enduring relevance of cognitive science insights in advancing machine intelligence.
In conclusion, Memento represents more than a technical achievement—it embodies a new philosophy of AI development that prioritizes adaptability, efficiency, and human-like learning mechanisms. As we stand on the threshold of increasingly sophisticated AI systems, this memory-based approach offers a compelling vision for creating agents that truly learn, adapt, and grow from their experiences, much like the remarkable cognitive systems that inspired their creation.