A deep dive into MiniMax’s latest frontier model — benchmarks, speed, pricing, live demos, and whether it lives up to the hype.
There’s a familiar pattern in AI releases: a company drops a new model, publishes jaw-dropping benchmark numbers, and the developer community spends the next two weeks arguing about whether any of it holds up in the real world. MiniMax M2.5, released in early 2026, follows that arc — but with some genuinely unusual twists that make it worth taking seriously.
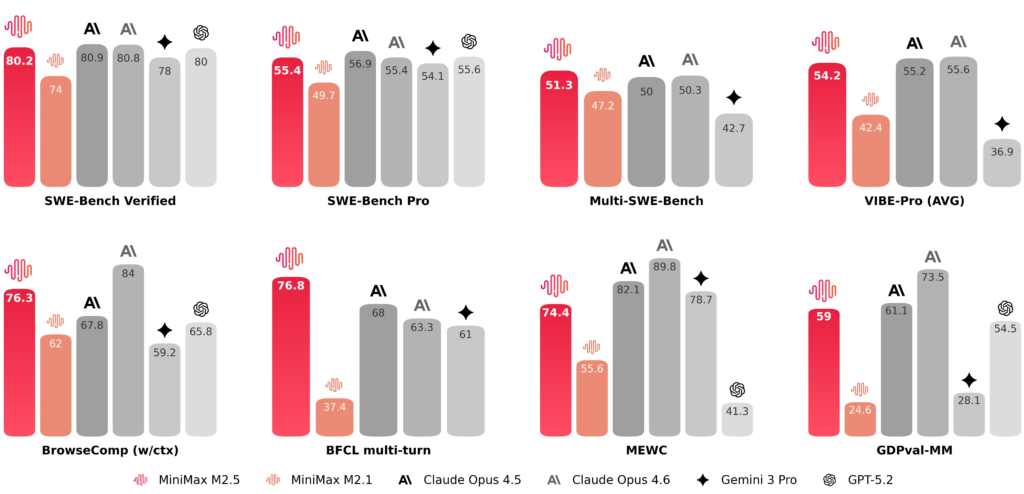
For one, it’s open source, released under an MIT license, which is still relatively rare among frontier-level models. For another, it claims to run at 100 tokens per second for roughly $1 per hour — a figure that sounds almost absurdly cheap compared to the likes of Anthropic’s Claude Opus 4.6. And it’s scoring 80.2% on SWE-Bench Verified, the gold-standard benchmark for evaluating whether an AI can actually solve real GitHub issues — not toy problems, but messy, production-grade code bugs in open-source repositories.
But numbers are easy to publish. What does MiniMax M2.5 actually feel like to use? What does it get right, what does it get wrong, and who should genuinely be excited about it? This is what we set out to answer.
What Is MiniMax M2.5?
MiniMax is a Chinese AI company that has quietly been building out a competitive stack of foundation models. M2.5 is their latest release and represents a significant step forward from its predecessor, M2.1. According to the official release notes, M2.5 was “extensively trained with reinforcement learning in hundreds of thousands of complex real-world environments,” a design philosophy that places it firmly in the agentic AI category — models not just meant to answer questions, but to do things.
The model is built around a specific vision: become the most cost-effective, highest-throughput AI for sustained developer workloads. That means coding, code review, multi-step agent execution, office automation, and long-running pipelines. It is not trying to be a generalist chatbot. It is, by design and by admission, a specialist — and that specialisation turns out to be one of its most interesting characteristics.
MiniMax offers two variants: M2.5 (the standard version) and M2.5-Highspeed (a distilled or optimised version optimised for maximum throughput). Both are available via the MiniMax API, and the Highspeed variant is what powers the higher-tier Coding Plans that the company sells to developers. The weights are MIT-licensed, meaning you can, in principle, self-host the model — though in practice, most developers will access it via the API or through third-party integrations.
Benchmarks: What the Numbers Actually Say
Let’s start with the headline figure: 80.2% on SWE-Bench Verified. This is a big deal. SWE-Bench Verified is a curated subset of the larger SWE-Bench dataset, where AI models are evaluated on their ability to resolve real GitHub issues — given a codebase, a bug report, and the expectation that the model will produce a working patch. It’s widely considered one of the most realistic proxies for developer usefulness in AI evaluation.
For context, Claude Opus 4.6 scores 80.8% on this same benchmark. GPT-5.4 sits in a comparable range. The fact that an open-source model from a company outside the traditional Silicon Valley AI orbit is competing within a hair’s breadth of the best closed-source models in the world is, by any measure, remarkable. And M2.5 isn’t just close on one benchmark — it’s consistently in the same tier across multiple evaluations.
On Multi-SWE-Bench, which evaluates more complex, multi-step coding scenarios (think: tasks that require touching multiple files, understanding system architecture, or coordinating changes across a codebase), M2.5 scores 51.3%. Claude Opus 4.6 scores 50.3%. M2.5 is ahead. That gap is small, but directionally significant — the open model outperforms the closed one on the harder task.
The benchmark story gets more interesting when you look beyond pure coding:
- BrowseComp: 76.3% — this tests the model’s ability to conduct web research and search tasks, an increasingly important capability as AI agents are asked to gather live information.
- BFCL Multi-Turn: 76.9% — this measures multi-turn function-calling accuracy, which is critical for agentic use cases where the model needs to chain tool calls across a conversation.
- GDPVal-MM: M2.5 reportedly achieves a 59% win rate against mainstream models on this document and office productivity benchmark, which is relevant given its claimed ability to generate Excel models, PowerPoint presentations, and Word documents.
- SWE-Bench Pro and TerminalBench: While exact publicly verifiable numbers here are pending full independent replication, the DataCamp analysis places M2.5 at or near the top among open models across these agentic coding suites.
One caveat worth stating plainly: benchmark numbers published by model vendors should always be treated with some skepticism. MiniMax is reporting these results, and while they’re in line with third-party analyses, independent replication across all benchmarks is still ongoing. That said, multiple external sources — including DataCamp, VentureBeat, and Kilo Code’s independent testing blog — arrive at broadly similar conclusions: M2.5 is genuinely competitive at the frontier level for coding tasks.
Speed: The 100 Tokens-Per-Second Story
If the benchmark performance is impressive, the speed claims are where MiniMax M2.5 starts to feel genuinely disruptive.
The model operates in what MiniMax calls “Lightning” mode, capable of sustained throughput of 100 tokens per second. For comparison, Claude Opus 4.6 runs at approximately 30 tokens per second under typical conditions. That means M2.5 at full speed is roughly 3x faster than one of the world’s leading proprietary models.
Speed in AI is often treated as a luxury feature — nice to have, but not essential. That framing misunderstands the economics of agentic workflows. When you’re running a coding agent that needs to generate, test, revise, and deploy code across a multi-hour session, token generation speed becomes a direct multiplier on productivity. A 3x speed advantage means tasks that take three hours with Opus can potentially be done in one with M2.5. For CI/CD pipelines, automated code review systems, and long-running development agents, this is transformative.
M2.5 also benchmarks approximately 37% faster than its own predecessor, M2.1, on the same tasks — suggesting this isn’t just a theoretical ceiling but a genuine generational improvement in throughput engineering.
Pricing: The “$1 Per Hour” Claim
Let’s be direct: when a company says you can run a frontier AI model continuously for $1 per hour, your first instinct should be to look for the catch. In this case, there largely isn’t one — but the details matter.
The $1/hour figure applies at 100 tokens per second of output generation, using the Lightning API tier. Input tokens are priced at approximately $0.30 per million tokens; output tokens at $2.40 per million under the standard Lightning pricing. The $1/hour works out mathematically if you’re running at full sustained output throughput, which in practice means a heavily loaded agent workflow. At 50 tokens per second (a more realistic sustained rate for most workloads), the cost drops to roughly $0.30 per hour. That is, frankly, extraordinary.
For pay-as-you-go API users, the effective blended cost — especially with token caching support — can drop as low as $0.06 per million tokens when cache hits are factored in. The MiniMax API pricing documentation lays this out clearly.
Beyond the pay-as-you-go API, MiniMax offers tiered Coding Plans for developers who want predictable monthly billing:
| Plan | Price | Prompts/Hours |
|---|---|---|
| Starter | $10/month | 100 prompts / 5 hours |
| Plus | $20/month | 300 prompts / 5 hours |
| Max | $50/month | 1000 prompts / 5 hours |
| Plus Highspeed | $40/month | 300 prompts / 5 hours (3x faster) |
| Max Highspeed | $80/month | 1000 prompts / 5 hours (10x faster) |
| Ultra Highspeed | $150/month | 2000 prompts / 5 hours (20x faster) |
The Highspeed tiers are powered by M2.5-Highspeed and are positioned for intensive developer workflows — professional engineers who are essentially running a coding co-pilot all day. The value proposition becomes clear when you compare $150/month for 2,000 prompts at up to 20x faster throughput versus what you’d spend on comparable usage of a closed proprietary model billed per token.
MiniMax has also partnered with platforms like Kilo Code to offer promotional access — a one-week free trial allowed developers to experiment with the model before committing to a plan, which is a smart way to build adoption.
Developer Tools and Workflow Integration
MiniMax M2.5 is designed to slot into existing developer workflows rather than demand you rebuild your entire toolchain around it. The primary integration story, as demonstrated in practice, runs through the Kilo Code extension for Visual Studio Code.
The setup process is straightforward: install the Kilo Code extension, navigate to the API provider settings, point it to api.minimax.io, enter your Coding Plan API key (note: this is separate from a standard pay-as-you-go key), and select minimax-m2.5 or minimax-m2.5-highspeed as your model. Within a few minutes, you have a coding agent running inside VS Code, ready to take natural language instructions and produce code.
What’s notable about M2.5’s workflow behaviour is its spec-first approach. Rather than diving immediately into code generation, the model consistently generates a structured plan first — a breakdown of the components it will build, the data structures it will use, the API endpoints it will expose. This behaviour mirrors how a senior software architect would approach a task: think first, code second. In live testing, this approach produced notably coherent outputs, with the generated code mapping cleanly back to the stated design.
One specific example from testing: given the prompt “Build a React/Node app with authentication,” M2.5 first produced a comprehensive design document covering wireframes, API endpoint definitions, data models, and component hierarchy. It then generated approximately 1,200+ lines of TypeScript and JavaScript. The tests passed on the first run, and the entire process took 22 minutes — reportedly faster than comparable prompts typically take with Claude Opus 4.6. That specific claim is harder to independently verify at scale, but it’s consistent with what the throughput numbers would predict.
Live Demo Analysis: Three Tests That Matter
The video review puts M2.5 through three live coding challenges that are instructive precisely because they span different domains:
Demo 1: Premium Landing Page
The prompt asked M2.5 to build a single-page website for a fictional AI workstation called “AURA-1” — with specific requirements including cinematic autoplay video, gradient design, dramatic lighting, Apple/Tesla-style minimalism, scroll storytelling, and animated metrics. The output was a production-ready HTML/CSS/JS file that hit all the visual marks: clean typography, smooth animations, a professional layout with feature sections, pricing tiers, and a call-to-action. For a single prompt with no iteration, this is genuinely impressive output quality.
Demo 2: Mobile App — “Ritual”
The second task was more architecturally demanding: a mobile habit and focus tracker with onboarding, a home dashboard, habit tracking with streaks, weekly progress visualisation, reminder notifications, tab navigation, micro-animations, and local data persistence — all with a “modern iOS/Android-friendly, minimal, high-end design.” M2.5 generated a complete application architecture and implementation, including all the specified features. The interface was clean and the feature set complete. For a zero-shot prompt producing a full app skeleton, this represents a significant leap over what most models produce on similar prompts.
Demo 3: 3D Empire State Building in Three.js
The third test pushed into more specialised territory: a realistic 3D model of the Empire State Building using Three.js, incorporating Art Deco geometry, vertical window patterns, a tall spire, realistic materials (limestone, glass, metal), sunlight and soft sky lighting, shadow rendering, and a subtle camera pan animation. The resulting output rendered correctly and demonstrated a credible understanding of Three.js APIs, 3D geometry, and lighting models. This is a challenging, niche task that requires the model to synthesise knowledge across architecture, 3D graphics, and JavaScript — and M2.5 handled it without obvious breakage.
Importantly, these demos don’t prove M2.5 is universally superior — they show what it can do with well-crafted prompts in a demonstration context. Real-world performance will depend heavily on prompt quality, task complexity, and domain specificity. But the output quality is convincingly in the same range as what you’d expect from the frontier proprietary models.
Core Strengths: What M2.5 Actually Does Well
Synthesising across the benchmarks, pricing data, and live testing, M2.5’s genuine strengths cluster around several distinct areas:
Multi-step agentic reasoning. The model was trained on reinforcement learning across complex real-world environments, and it shows. It handles long-horizon tasks — the kind that require planning, executing, checking results, and adjusting — better than most models of comparable cost. This is what makes it suitable for CI/CD automation, code review pipelines, and autonomous development agents.
Polyglot programming support. M2.5 supports over 10 programming languages including Python, JavaScript/TypeScript, Rust, Go, Java, and more. It handles full-stack domains including web, Android, iOS, and Windows desktop — making it genuinely versatile for diverse engineering teams.
Office and document automation. This is an underrated capability. M2.5 can generate fully-formatted Excel files with financial models, PowerPoint presentations with structured content, and Word documents — outputs that are immediately usable in business contexts. The 59% win rate on GDPVal-MM reflects real capability here, not a marketing flourish.
Openness and self-hosting. The MIT license matters. Enterprises with data sovereignty requirements, compliance constraints, or simply a preference for not routing sensitive code through third-party APIs can, in principle, self-host M2.5. With only approximately 10 billion active parameters, the infrastructure requirements are far more modest than you’d expect for a frontier-calibre model.
Cost at scale. At $0.30/million input tokens with cache support dropping effective costs further, M2.5 makes high-volume agentic workloads economically viable in ways that simply weren’t possible with earlier frontier models. VentureBeat’s analysis characterises this well: “the frontier of AI is no longer just about who can build the biggest brain, but who can make that brain the most useful — and affordable — worker in the room.”
Competitive Positioning: Where M2.5 Fits
The honest competitive picture for M2.5 is nuanced. On coding benchmarks, it sits comfortably in the same tier as Claude Opus 4.6 and GPT-5.2 — remarkable for an open-source model. On cost and speed, it comprehensively outclasses both of them. But the comparison isn’t uniformly favourable.
Against closed-source generalist models like Gemini 3.1 Pro or GPT-5.2, M2.5 concedes ground on broad knowledge tasks, creative writing, and general reasoning. Gemini 3.1 Pro, for example, now surpasses M2.5 on BrowseComp, indicating that for research-heavy or knowledge-intensive work, the proprietary models maintain an edge.
Against other open models — particularly GLM-5, which targets a similar market — M2.5 holds a clear advantage. Kilo Code’s head-to-head testing found M2.5 outperforming GLM-5 on coding tasks and completing them roughly twice as fast. That’s a decisive margin.
DataCamp’s assessment characterises M2.5 as “exceptionally good for targeted productivity” — grading it A+ for developer tasks, but a B+ overall. That framing is probably fair and reflects the model’s intentional design philosophy: depth over breadth, specialist over generalist.
Limitations and Honest Caveats
No review is complete without an honest accounting of where a model falls short. M2.5 has several real limitations that prospective users should understand before committing.
Specialist, not generalist. If you need a model to brainstorm marketing copy, analyse literature, reason about complex ethical dilemmas, or handle genuinely creative tasks, M2.5 is not the right tool. Its training and architecture optimise for structured, code-adjacent tasks. Its performance on broad reasoning benchmarks notably lags behind larger closed-source models.
Knowledge cutoff. Like all models, M2.5 has a training data cutoff. For tasks requiring awareness of recent events, rapidly changing APIs, or the latest library releases, the model will sometimes produce outdated suggestions.
Mixed real-world reliability. Benchmark performance doesn’t always translate directly to production reliability. For edge cases, unusual codebases, or tasks that require deep domain expertise beyond typical training data, M2.5 can and does make errors. Any production deployment should include robust testing and human review stages.

Who Should Use MiniMax M2.5?
Given everything above, the use case profile for M2.5 becomes fairly clear.
Individual developers running frequent, long coding sessions who are currently paying $20–$50/month on another model’s API would likely find M2.5’s Coding Plans more cost-effective and faster. The Starter at $10/month is a reasonable entry point for experimenting.
Startups building AI-powered developer tools — code review bots, PR automation systems, CI/CD intelligence layers — will find M2.5’s cost and throughput profile ideal for high-volume, sustained inference workloads that would be prohibitively expensive with proprietary models.
Enterprises with data sovereignty requirements who need to self-host their AI infrastructure now have a genuinely frontier-calibre option with an open MIT license. The 10B parameter footprint makes this tractable on modest GPU infrastructure.
Platform builders who want to embed AI coding assistance into their products without building their own models. MiniMax’s platform allows users to build custom agents — “landing page builder,” “PPTX maker,” “Excel processor” — on top of M2.5, effectively providing a lightweight AI app platform.
Less ideal for general-purpose chatbot use cases, creative content generation, complex research tasks, or anything requiring deep general knowledge and reasoning. For those workloads, the larger closed-source models still hold meaningful advantages.
The Broader Significance
It would be easy to read MiniMax M2.5 as just another model release — one more entry in an increasingly crowded leaderboard. But there’s something more significant happening here if you look at the trajectory.
MiniMax is a Chinese company building frontier models that are competing directly with Anthropic, OpenAI, and Google in specific benchmark categories. The open-source release under an MIT license puts that capability into the hands of any developer or company in the world, with no restrictions. The combination of frontier-level coding performance, 100 tokens per second throughput, and $1/hour pricing represents a genuine step-change in the economics of AI-assisted development.
As VentureBeat noted, MiniMax claims that “80% of our own source code is AI-generated” using these models — a statement that, if accurate, suggests M2.5 isn’t just a product they’re selling, but the infrastructure they’re actually building on. That kind of dogfooding credibility matters.
The larger story is about what happens when frontier AI performance becomes decoupled from frontier AI pricing. The assumption that you need to pay premium prices to access premium capability is breaking down. M2.5 is one of the clearer examples of that breakdown to date — not because it’s better at everything, but because it’s good enough at the things that matter most to developers, while being dramatically cheaper and faster than the alternatives.
Final Verdict
MiniMax M2.5 is a genuinely impressive specialist model that delivers on most of its headline claims. The coding benchmark performance is real and independently corroborated. The speed advantage over competing models is substantial and practically meaningful. The pricing is competitive to a degree that should force developers to at least reconsider their current model choices.
It is not a magic solution. It won’t replace your senior engineers, it won’t outthink GPT-5.2 on complex reasoning tasks, and it won’t write your next novel. But for the sustained, high-volume, code-heavy, agent-driven workloads that define modern software development, it is one of the best options currently available — and the only open-source option that can make that claim convincingly.
If you’re a developer who hasn’t tried it yet, the combination of a free trial via Kilo Code and a $10/month Starter plan makes the cost of experimentation essentially zero. That’s a low-risk way to find out whether M2.5 belongs in your development toolkit.
Given the trajectory — faster, cheaper, more capable with each iteration — the more interesting question isn’t whether M2.5 is good today. It’s what M2.6 will look like.