On April 7, 2026, Anthropic quietly released something extraordinary — and then decided not to let most of the world use it. Claude Mythos Preview, the company’s newest and most capable large language model, dropped alongside a dense 240-page system card that reads less like a product launch document and more like a cautious dispatch from the frontier. The benchmarks it contains are staggering. The context surrounding them is even more important.
This article is a deep dive into every benchmark score published for Mythos Preview — what each benchmark actually tests, how large the jumps are compared to Claude Opus 4.6, and why those numbers matter far beyond bragging rights.
The Unprecedented Decision Not to Release
Before we get into the numbers, some critical context. According to Anthropic’s official system card, Claude Mythos Preview will not be made generally available. This is a first for Anthropic — a company that has consistently shipped its frontier models commercially.
The reason is sobering: Mythos Preview demonstrated what Anthropic describes as a “striking leap in cyber capabilities,” including the ability to autonomously discover and exploit zero-day vulnerabilities in major operating systems and web browsers. The dual-use nature of those capabilities — powerful for defense, dangerous if broadly accessible for offense — led Anthropic to restrict access to a small number of partners focused exclusively on cybersecurity defense, under what the company is calling Project Glasswing.
The decision was not driven by the Responsible Scaling Policy (RSP) framework requiring a halt, but rather by a judgment call. Anthropic is being transparent in an unusual way: publishing the model’s full capability profile even though the model itself remains locked away. What we’re left with is a remarkably complete picture of what the current frontier looks like — without the ability to experience it firsthand.
The reaction from the AI research and developer communities on X has been significant, with commentary circulating from researchers and Anthropic team members here and here.
The SWE-bench Family: Redefining What AI Can Do With Code
The SWE-bench benchmarks are the gold standard for evaluating an AI model’s ability to solve real software engineering tasks. They are not toy problems — they involve patching actual open-source repositories, navigating codebases with no hand-holding, and producing solutions that pass pre-written test suites. Mythos Preview was evaluated across four variants of SWE-bench, and the results across every single one are remarkable.
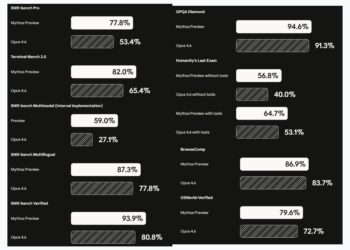
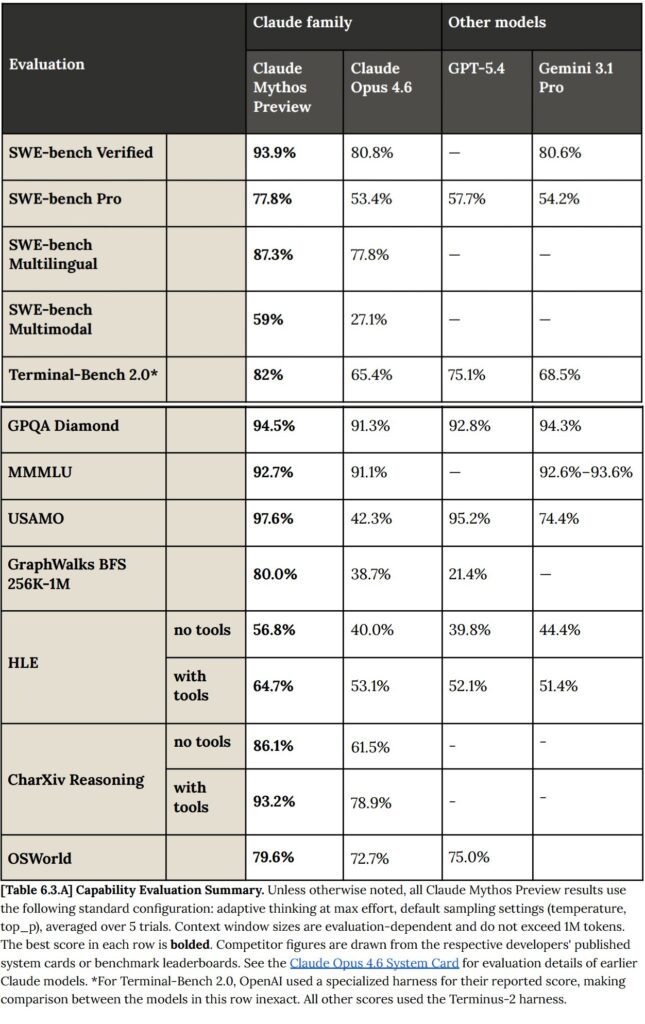
SWE-bench Verified — 93.9%
This is the canonical SWE-bench test and the one most AI labs report. Mythos Preview scored 93.9%, compared to Opus 4.6’s 80.8% — a leap of 13.1 percentage points. To put that in perspective, the jump from 80% to 93.9% represents the model going from solving roughly four-in-five issues to solving nearly nineteen-in-twenty. On a benchmark like SWE-bench Verified, where tasks are drawn from real GitHub issues across diverse Python libraries, that level of performance suggests the model can handle virtually any standard software engineering debugging task it encounters.
The 93.9% figure is not just a marginal improvement over Opus 4.6 — it represents the kind of performance level that begins to approximate what a skilled human engineer might achieve when given the same isolated task with full context.
SWE-bench Pro — 77.8%
SWE-bench Pro is harder. Where Verified uses Python-only tasks that have been filtered for quality and solubility, Pro skews toward more complex, more recent, and more challenging real-world issues. Mythos Preview scores 77.8% here, while Opus 4.6 manages only 53.4% — a gap of over 24 percentage points.
This is arguably the most striking delta in the entire benchmark suite. When the difficulty ramps up and the problems stop being predictable, Mythos Preview doesn’t drop off as sharply as its predecessor. That resilience suggests a qualitative change in the model’s reasoning capacity, not just a marginal tune. The jump from 53.4% to 77.8% is the kind of leap that shifts a model from “useful assistant” to “capable autonomous engineer” on non-trivial tasks.
SWE-bench Multilingual — 87.3%
Software engineering is not a monolingual domain. The world’s codebases are written across dozens of programming languages, and developer communities span every continent. SWE-bench Multilingual tests whether models can generalize their code reasoning to languages beyond Python.
Mythos Preview scores 87.3% on this benchmark, compared to Opus 4.6’s 77.8%. The gap here — roughly 9.5 points — is smaller than in the Pro variant, but the absolute score is still formidable. The ability to approach 90% on multilingual software tasks speaks directly to Anthropic’s stated goal of building models with broad software engineering utility, not just English-Python pipelines.
SWE-bench Multimodal (Internal Implementation) — 59.0%
This is the newest and most experimental variant. As the name suggests, it evaluates a model’s ability to handle software engineering tasks that involve visual context — UI screenshots, diagrams, or other non-text inputs woven into the problem specification.
Mythos Preview scores 59.0% on this benchmark, against Opus 4.6’s 27.1%. The gap here — over 31 percentage points — is the largest delta anywhere in the SWE-bench family. Multimodal code reasoning is genuinely difficult because it requires a model to integrate visual understanding with technical problem-solving simultaneously. More than doubling Opus 4.6’s score here suggests that Mythos Preview’s multimodal architecture has reached a new tier of integrated reasoning. Anthropic flags this as an internal implementation, noting it has not yet been externally validated, but the magnitude of the jump is too large to dismiss.
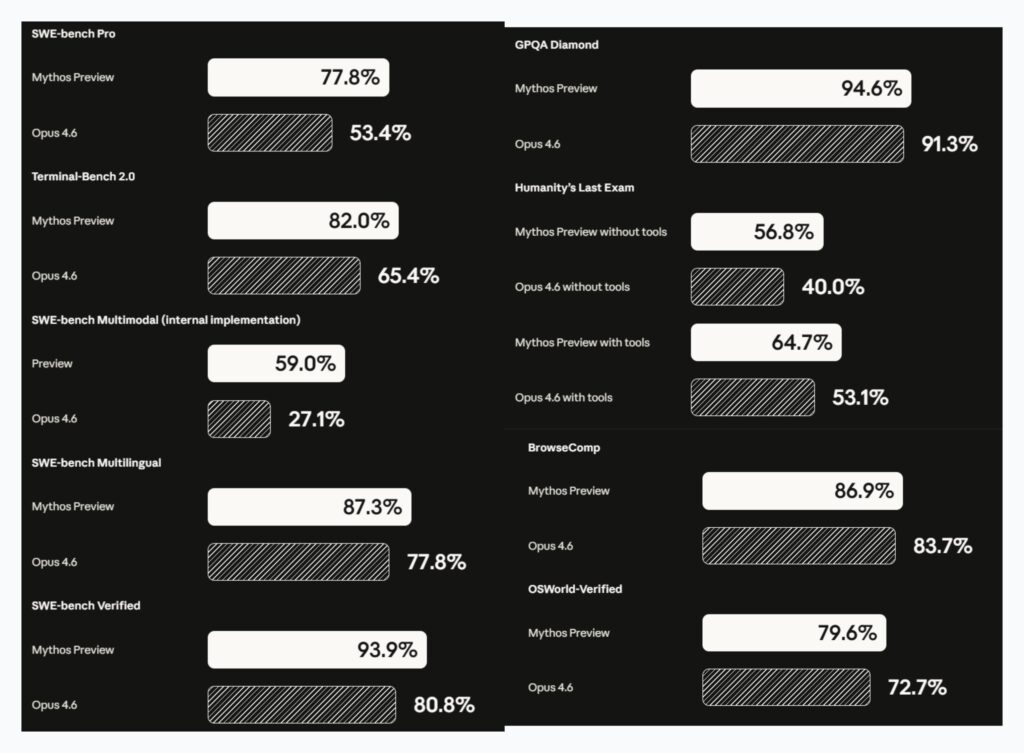
Terminal-Bench 2.0 — 82.0%
Terminal-Bench 2.0 evaluates a model’s ability to operate autonomously in a terminal environment — running commands, debugging failures, navigating file systems, managing processes, and completing multi-step computing tasks that require persistence and error recovery. It is a closer proxy for real agentic use than most academic benchmarks, because it reflects what it actually feels like to deploy an AI assistant that needs to get something done in a shell.
Mythos Preview scores 82.0% on Terminal-Bench 2.0, compared to Opus 4.6’s 65.4% — a gap of 16.6 percentage points. In the context of agentic use cases, this gap matters enormously. When an AI model is autonomously running code, debugging errors, and managing infrastructure, the difference between 65% and 82% isn’t just statistical — it’s the difference between a tool that frequently needs human rescue and one that can largely be trusted to complete a task from start to finish.
Terminal-Bench results, read alongside the SWE-bench suite, paint a coherent picture: Mythos Preview isn’t merely better at answering questions about code. It is materially better at doing things with code, autonomously, across extended tasks.
GPQA Diamond — 94.6%
The Graduate-Level Google-Proof Q&A (GPQA) Diamond benchmark tests expert-level scientific knowledge in biology, chemistry, and physics. The questions are specifically designed to be too hard to answer with a quick web search — they require actual understanding at a PhD level. Humans with relevant PhDs score around 65-70% on GPQA Diamond, making it one of the few benchmarks that still meaningfully separates AI models from genuine expert knowledge.
Mythos Preview scores 94.6% on GPQA Diamond. Opus 4.6 scores 91.3%.
Both scores are above typical human expert performance — the question now is not whether AI can match human experts on this benchmark, but whether GPQA Diamond itself has become too easy a bar. The 3.3-point gap between Mythos Preview and Opus 4.6 here is the narrowest in the dataset, which suggests GPQA Diamond may be approaching saturation for top-tier models. Nevertheless, a score of 94.6% on a benchmark that stymies most PhD-holders remains a striking demonstration of scientific reasoning.
Humanity’s Last Exam — 56.8% (without tools) / 64.7% (with tools)
Humanity’s Last Exam (HLE) was created as a response to benchmark saturation — a test specifically designed to be hard enough that even state-of-the-art AI models would struggle. It draws on contributions from domain experts worldwide, covering mathematics, science, humanities, law, and other rigorous academic fields, with questions vetted for genuine difficulty.
Mythos Preview was evaluated under two conditions, and the results are notable in both cases:
- Without tools: Mythos Preview scores 56.8%, versus Opus 4.6’s 40.0% — a gap of nearly 17 points.
- With tools: Mythos Preview scores 64.7%, versus Opus 4.6’s 53.1% — a gap of 11.6 points.
Several things stand out. First, the absolute numbers are lower than on other benchmarks — HLE is doing its job as a difficulty ceiling. Second, the delta between “without tools” and “with tools” for Mythos Preview (about 8 points) suggests the model knows how and when to leverage external resources effectively, which is a sophisticated capability in itself. Third, the jump over Opus 4.6 in the no-tools condition — 40% to 56.8% — is remarkable precisely because it occurs on a benchmark engineered to resist improvement. These aren’t marginal efficiency gains; they represent a meaningful step in knowledge depth and reasoning quality.
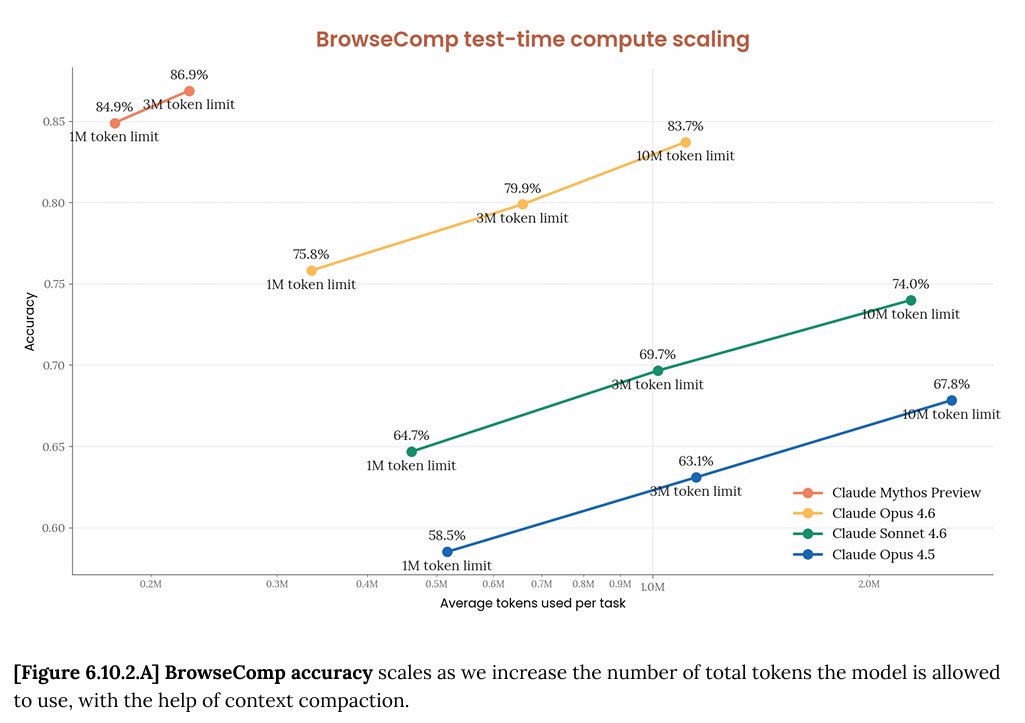
BrowseComp — 86.9%
BrowseComp tests a model’s ability to perform complex web-based research: finding specific information that requires multi-step browsing, cross-referencing sources, and synthesizing answers from scattered online content. It measures something closer to real-world information retrieval and analysis than a static knowledge benchmark.
Mythos Preview scores 86.9% on BrowseComp, compared to Opus 4.6’s 83.7% — a tighter gap of 3.2 percentage points. The fact that Opus 4.6 already performed strongly here narrows the room for improvement, and both models are clearly well above what would be needed for practical research assistance. The small delta also suggests that BrowseComp, like GPQA Diamond, may be approaching the ceiling of what this type of benchmark can distinguish at the top of the performance distribution.
OSWorld-Verified — 79.6%
OSWorld-Verified evaluates a model’s ability to complete real computer-use tasks — clicking through interfaces, navigating operating system environments, manipulating files and applications, and completing workflows in realistic desktop settings. It is one of the more demanding benchmarks for practical agentic deployment, because it requires the model to reason about visual interfaces and translate that reasoning into correct actions.
Mythos Preview scores 79.6% on OSWorld-Verified, compared to Opus 4.6’s 72.7% — a gap of 6.9 points. A score approaching 80% on real computer-use tasks is significant: it indicates that Mythos Preview can reliably navigate graphical desktop environments, complete multi-step workflows, and handle the kinds of “do this on my computer” requests that represent some of the most practically valuable AI capabilities available.
What These Numbers Mean Together
Read as a suite, the Mythos Preview benchmarks tell a consistent story: this is a model that has made meaningful, non-marginal gains on every dimension of capability evaluated, with the largest improvements concentrated precisely in the areas where AI has historically struggled most — hard-difficulty reasoning (Humanity’s Last Exam), complex agentic software tasks (SWE-bench Pro, Terminal-Bench), and multi-modal code understanding (SWE-bench Multimodal).
The pattern of the gaps is itself telling. Mythos Preview doesn’t just improve proportionally across the board — it widens the gap most sharply on the hardest tasks. On SWE-bench Pro, it leads Opus 4.6 by over 24 points. On SWE-bench Multimodal, by over 31 points. On Terminal-Bench, by 16.6 points. These are the benchmarks that demand the most from a model’s underlying reasoning architecture, and they’re where the improvement is most pronounced.
According to the Anthropic system card, Mythos Preview represents “an appreciable leap in capabilities in many domains” — and that language is understated relative to what the numbers show. The model is not a modest evolution from Opus 4.6. It is a categorically different performer on the kinds of tasks that define practical usefulness.
The Benchmark Behind the Benchmark
The most important number in the Mythos Preview story might not be any of the scores above. It’s the fact that Anthropic looked at this model’s capabilities and decided the world wasn’t ready for it.
That decision was made not because of alignment failures — Anthropic explicitly states Mythos Preview is “the best-aligned of any model we have trained to date.” It was made because a model that can autonomously discover and exploit zero-day vulnerabilities in browsers and operating systems is inherently dual-use in a way that benchmark scores can’t fully capture.
The benchmarks are a window into what the frontier currently looks like. What they can’t show is the judgment call required to decide whether that frontier should be open. For now, Anthropic has decided it shouldn’t be — and in publishing this system card in full, they’ve chosen transparency over silence. The numbers are out. The model, for now, is not.
All benchmark scores cited in this article are drawn directly from Anthropic’s official Claude Mythos Preview System Card, published April 7, 2026. Additional community discussion can be found on X here and here.