Executive summary
In early March 2026, Andrej Karpathy released autoresearch, a deliberately small repository on GitHub that turns a familiar machine-learning workflow into a tight, measurable, and automatable loop: an agent edits a single training script, runs a time-boxed experiment, measures performance, and either keeps or discards the change—then repeats, potentially all night.
The project’s novelty is not that it “self-improves” in the sci‑fi sense. Autoresearch does not rewrite its goals, change its evaluation standard, or autonomously acquire resources. Instead, it packages a credible, real LLM pretraining run (“small but real”) into a constrained harness where optimization pressure is explicit and continuous: validation bits-per-byte (val_bpb) is the primary fitness signal, and every experiment gets the same 5-minute training budget (wall-clock training time, excluding startup/compilation).
Three files encode the design:
- program.md is the human-written strategy + rules of the game for the agent. It describes what the agent is allowed to modify, how to run experiments, how to parse metrics, how to record results, and what “keep vs discard” means.
- prepare.py is the fixed trust boundary: data download, a trained tokenizer, a deterministic validation shard selection, and the evaluation function
evaluate_bpbthat defines the metric. The agent is instructed not to modify it. - train.py is the only mutable genome: model architecture, optimizer choices, hyperparameters, batch size, schedules, and training loop details.
Karpathy’s README frames the intended experience: you “point your agent” at program.md, the agent edits train.py, runs 5-minute training, checks if performance improved, and “keeps or discards” before repeating. The repo is also explicitly positioned as “a simplified single-GPU implementation” of his larger nanochat training harness.
Evidence in the repo’s Discussions and PRs shows this is not merely a conceptual demo: Karpathy reports multiple autonomous sessions with dozens to hundreds of experiments on an NVIDIA H100, improving val_bpb from about 0.9979 → 0.9773 (89 experiments) and 0.9979 → 0.9697 (126 experiments), with detailed per-experiment logs and a workflow proposal for publishing results via PRs.
At the same time, the repo and issues make clear why “autonomous loops” are not magic: reliability of agent behavior varies by tool (Karpathy notes “Codex doesn’t seem to work” due to ignoring “never stop”), runs are platform-specific because the budget is wall-clock, and there are real safety concerns—especially around trust boundaries and prompt injection when an agent reads program output back into its own context.
Finally, autoresearch is best understood as a modern packaging of older ideas—hyperparameter optimization, neural architecture search, evolutionary search, and population-based training—reframed for today’s coding agents. The conceptual leap is social and operational: write goals and constraints; let an agent generate and test code deltas indefinitely; keep only what measurably improves the objective.
Primary sources for this article include the autoresearch repo itself, its program.md, prepare.py, train.py, and the repo’s Discussions/PRs (notably Discussion #32, Discussion #43, PR #44), plus Karpathy’s posts on X that describe experiment counts and transfer claims.
What autoresearch is
Autoresearch is a minimal experimental harness designed so an external coding agent can conduct iterative ML experimentation with almost no human intervention beyond maintaining a single instruction file. In the README’s own summary: the agent is given “a small but real LLM training setup,” it “modifies the code,” trains for 5 minutes, checks whether the result improved, “keeps or discards,” then repeats.
The repo’s design choices
Autoresearch’s core design choices are explicit in the README:
- One file to modify: the agent only touches
train.py, keeping diffs “reviewable” and scope bounded. - Fixed time budget: every experiment trains for “exactly 5 minutes” (training time), yielding an expected cadence of ~12 experiments/hour and ~100 overnight.
- One metric: the optimization target is
val_bpb, described as “vocab-size-independent” so that architectural changes can be fairly compared. - Single-GPU scope: the repo “currently requires… a single NVIDIA GPU” (tested on H100), intentionally avoiding distributed training complexity.
A subtle but important consequence follows from the “fixed time budget” premise: since it is wall-clock (and depends on startup/compilation exclusions), the same code change can score differently across GPUs and software stacks. The README calls this out directly: the upside is comparability within your own platform; the downside is that results are “not comparable” across different compute platforms.
The three core files
program.md (the “skill” / spec)
The program.md file is effectively the operating manual for the agent. It defines setup steps (create a new branch, ensure data exists, initialize results.tsv), constraints (only modify train.py, don’t add dependencies, don’t modify evaluation), and the exact loop the agent should execute forever.
Crucially, program.md also encodes qualitative governance, not just mechanics:
- “VRAM is a soft constraint” (the agent may trade memory for better metric, but should not explode usage).
- “Simplicity criterion: … simpler is better” and the agent should weigh code complexity against metric deltas.
- “NEVER STOP” instructs the agent not to wait for human confirmation mid-run.
These are not incidental; they are the project’s attempt to turn research into something like an indefinitely running process with explicit guardrails.
prepare.py (fixed environment + evaluation harness)
The file prepare.py is treated as read-only by policy and by the spec in program.md. It sets global constants like:
MAX_SEQ_LEN = 2048TIME_BUDGET = 300seconds (5 minutes)EVAL_TOKENS = 40 * 524288(a fixed token budget for validation evaluation)
It also defines the evaluation function evaluate_bpb, documented as “vocab size-independent” by converting per-token cross-entropy (in nats) to bits-per-byte by dividing by the byte-lengths of tokens (special tokens excluded).
This is a key architectural point: by pinning evaluate_bpb in a file the agent is not allowed to change, the system tries to prevent the most obvious form of reward hacking (changing the score definition).
Prepare.py also defines the data pipeline. It downloads Parquet shards from a base URL pointing at a dataset hosted under Hugging Face (karpathy/climbmix-400b-shuffle), stores them in a cache directory, and pins a specific shard as validation by filename.
Tokenization is trained once using rustbpe and saved as a tiktoken encoding, along with a token_bytes lookup used for BPB evaluation.
train.py (the mutable genome)
The entire search space lives in train.py: model definition, optimization logic, and a literal “Hyperparameters (edit these directly, no CLI flags needed)” section.
Out of the box, train.py includes:
- A GPT-style model configuration with depth (
DEPTH) controlling number of transformer layers. - A windowed attention pattern constant (
WINDOW_PATTERN) suggesting a mix of “sliding” vs “full” attention blocks. - A combined optimizer approach labeled “Muon + AdamW,” where “Muon” is applied to matrix parameters and AdamW to others, implemented with fused steps and
torch.compile. - A device capability check that selects a Flash Attention 3 kernel source depending on GPU architecture.
The training loop enforces the time budget and prints a structured summary including val_bpb, training_seconds, total_seconds, peak_vram_mb, and several throughput-related measures.
Dependencies and “self-contained” in practice
Autoresearch claims to be “self-contained” aside from PyTorch and a few packages. Practically, its pyproject.toml pins torch==2.9.1 and depends on packages including pyarrow (for Parquet), tiktoken, rustbpe, and a kernels package used to load Flash Attention 3 kernels.
This matters for reproducibility and supply-chain risk: the repo is small, but it still relies on compiled kernel packages, Torch compile behavior, and GPU-specific kernels—all of which can affect determinism and performance.

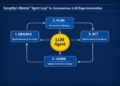
How the agent loop works
Autoresearch’s loop is spelled out directly in program.md and echoed in the README. The important point is that the repository itself does not ship an “agent.” Instead, it’s designed to be used with an external coding agent (Karpathy mentions Claude or Codex as examples) that can edit files and run shell commands inside the repo.
The loop as written in program.md
program.md defines a strict procedure:
- Create a fresh branch for the run (
autoresearch/<tag>), initialize aresults.tsvlog, and run a baseline to establish the starting score. - For each experiment: modify only
train.py; commit; runuv run train.pyredirected to a log; parseval_bpband memory; append a row toresults.tsv. - If
val_bpbimproves (lower), keep the commit and “advance” the branch; if equal/worse, reset back to the last good state. - If the run crashes or exceeds a timeout (10 minutes), treat as failure, optionally fix trivial issues, otherwise log “crash” and move on.
- After the loop begins, “NEVER STOP”—the agent should not ask for permission to continue, anticipating that the human may be asleep.
This has a clear evolutionary flavor, but it is more precise to call it a hill-climbing or incremental search loop with explicit revert semantics: the “population” is effectively a single lineage (a branch) that steadily accumulates improvements.
Mutation, selection, and fitness in this design
In evolutionary terms:
- Mutation is any edit to
train.py: architecture, optimizer, schedules, batch size, even training loop changes. - Selection happens via the keep/discard step and
git reset: only improvements remain in the branch history. - Fitness is
val_bpb, with “lower is better.” Auxiliary signals (VRAM, stability, simplicity) are constraints or secondary objectives. - Reproduction is the act of continuing from the latest kept state—each kept commit becomes the parent of the next experiment.
A key implementation detail is the fixed experiment budget: training time is capped at 300 seconds (excluding startup/compilation overhead), which makes the objective comparable across experiments on the same machine.
Agent loop flowchart
mermaidCopyflowchart TD
A[Human edits program.md strategy] --> B[Agent proposes change to train.py]
B --> C[git commit on experiment branch]
C --> D[Run: uv run train.py (TIME_BUDGET=300s)]
D --> E[Parse metrics: val_bpb, peak_vram_mb, etc.]
E --> F{val_bpb improved?}
F -->|Yes| G[KEEP: record in results.tsv; continue from new state]
F -->|No| H[DISCARD: git reset to previous best; record in results.tsv]
D -->|Crash/timeout| I[CRASH: record; optionally fix trivial errors]
G --> B
H --> B
I --> B
This diagram is conceptual but corresponds closely to the procedural steps in program.md (commit → run → grep metrics → keep/reset).
Evidence, results, and reproducibility
Autoresearch becomes interesting only if the loop produces real, measurable improvements and if those improvements generalize beyond a single 5-minute micro-benchmark. The project provides several layers of evidence: (a) documented design of the metric and time budget, (b) “session reports” posted as GitHub Discussions, and (c) PRs containing commits plus full experiment logs.
The fixed protocol and what “5 minutes” actually means
The README and program.md both emphasize that each experiment runs for “exactly 5 minutes,” but the implementation clarifies the nuance: it is training time, and it is measured as wall-clock time excluding startup/compilation overhead.
In train.py, the loop tracks total_training_time and only starts accumulating it after a small warmup (if step > 10)—a guard meant to avoid counting compilation overhead and initial transients toward the 300-second time budget.
Practically, this choice makes the benchmark more stable for agents experimenting with code that might affect compilation or kernel warmup, but it still leaves important variability sources:
- Flash attention kernel selection can differ by GPU capability.
- Throughput changes (e.g., batch size, windowed attention ratio) can change the number of optimization steps completed within 5 minutes, which can heavily influence the final validation metric—sometimes more than “better modeling ideas.”
- The “fixed time budget” means a key optimization target becomes throughput × learning effectiveness, not just final quality per parameter.
The metric: val_bpb and why it matters
Autoresearch uses val_bpb (validation bits-per-byte) as its objective. The README explicitly calls it “vocab-size-independent,” and prepare.py defines it by dividing summed token-level cross-entropy (nats) by total byte-length of the target text, converting to bits.
Two implications follow:
- Tokenizer changes matter less (in principle): BPB is meant to reduce comparability problems when vocab sizes differ, unlike perplexity measured directly over tokens.
- Metric sensitivity can still be hacked indirectly: while the agent can’t edit
evaluate_bpb, it can change training dynamics or even the data interface intrain.py(e.g., by printing misleading logs, or altering what constitutes a “step”). The system’s integrity depends on keeping strict boundaries between what’s measured and what the agent can influence.
The dataset and evaluation split
The training data is downloaded as Parquet shards from a base URL referencing karpathy/climbmix-400b-shuffle on Hugging Face.
Key known facts from primary sources:
- The Hugging Face dataset page indicates ~553M rows and a ~600GB download size for the full dataset, and notes the dataset’s README is empty.
prepare.pydownloads shards by numeric ID (default:range(0, num_shards)plus a pinned validation shard), and pins a specific validation shard filename (VAL_FILENAME = f"shard_{VAL_SHARD:05d}.parquet").- The dataloader is BOS-aligned, packs documents to maximize utilization (“100% utilization (no padding)”), and uses the pinned validation shard exclusively for validation.
Assumption note: Autoresearch does not document the corpus composition of karpathy/climbmix-400b-shuffle beyond the dataset name and storage format; the dataset card is empty. Any claims about the dataset’s provenance beyond these facts should be treated as inference.
A plausible inference (not a confirmed fact) is that the dataset name relates to “ClimbMix,” a 400B-token mixture referenced elsewhere in Karpathy’s ecosystem. For example, nanochat’s leaderboard notes a “change dataset to NVIDIA ClimbMix.” If you need a legally or scientifically rigorous description of training data, you would need additional documentation beyond what autoresearch currently provides.
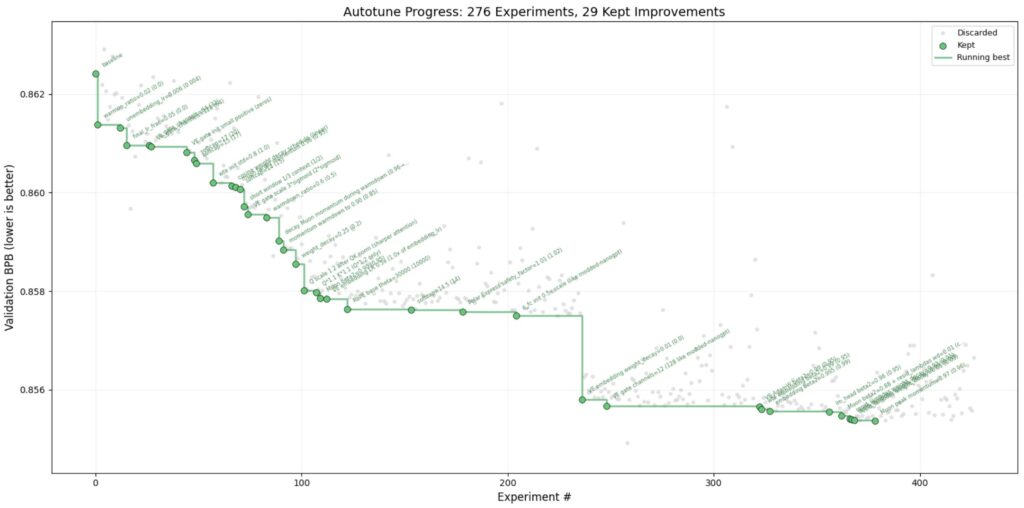
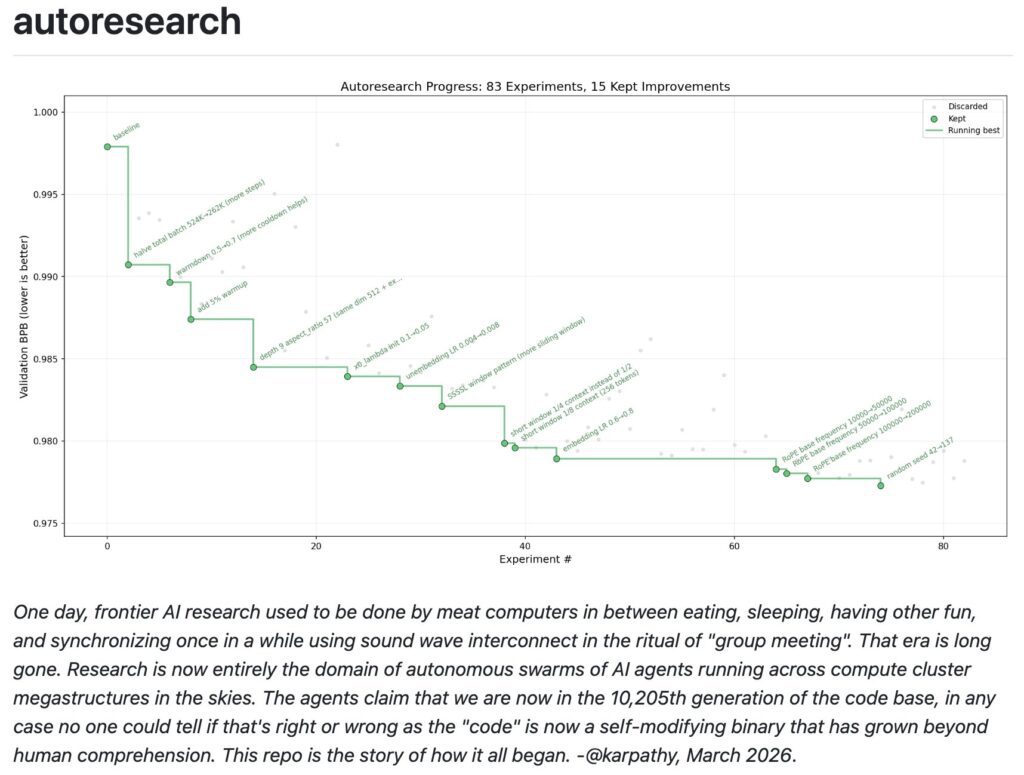
Documented results: GitHub Discussions as “lab notebooks”
The repo contains multiple “session reports” posted as GitHub Discussions that appear to be generated by an agent (“This is an automated post from an autoresearch agent running on behalf of @karpathy”).
Two key reports:
- Discussion #32 reports improving
val_bpbfrom 0.997900 → 0.977287 over 89 experiments on “NVIDIA H100 80GB,” describing top wins like halving batch size (more steps in 5 minutes), increasing depth to 9 while keeping width, tuning sliding window ratios, and raising RoPE base frequency. - Discussion #43 reports improving
val_bpbfrom 0.9979 → 0.969686 in 126 experiments, again on “NVIDIA H100 80GB,” and highlights additive gains from weight decay applied to embeddings/value embeddings, plus a narrow optimum for initialization scaling. The post includes a full per-experiment log with keep/discard decisions, and explicitly lists the final configuration.
These reports are valuable because they show the agent is not only wandering randomly—it accumulates coherent hypotheses (“more steps > more params,” “weight decay on embeddings and VEs”) and tests them. They also show “dead ends” and crashes, suggesting the loop genuinely explores and rejects ideas.
PR-based reproducibility: results.tsv + commit history
PR #44 (“exp/H100/mar8”) proposes a more formal artifact for collaboration: the PR description explains a workflow where each session runs in a branch, records a results.tsv, and publishes both the final diff and the kept-history via Git commits.
The PR explicitly argues that this makes each PR “a self-contained research contribution” where:
- the diff = final best configuration,
- commit history = the sequence of kept improvements,
- results.tsv = the full experimental trace, including discards.
It also introduces a naming convention exp/{GPU}/{tag} because the 5-minute wall-clock time budget makes results platform-specific.
This is an important methodological step: it pushes the project from “demo loop” toward something closer to a reproducible research artifact, albeit still bounded by hardware and time budget.
Karpathy’s transfer and scale claims
Karpathy’s posts on X (not fully accessible via the same mechanisms as GitHub pages, but partially captured in indexed excerpts) include two major claims that go beyond the single-GPU, 5-minute micro-benchmark:
- Autoresearch performed “(~650) experiments on depth 12” and the improvements “transfer well to depth 24,” implying that hyperparameter/architecture wins at one scale carry over to a larger model depth.
- He packaged the project as a minimal repo and described the human/agent division of labor: the human iterates on the prompt file, the agent iterates on training code.
Important limitation: these are claims, not fully reproduced within the autoresearch repo itself. The GitHub Discussions demonstrate improvements within the autoresearch harness (depths like 8–11 appear in logs), but “650 experiments” and “depth 12 → depth 24 transfer” refer to work Karpathy says he ran, likely in his broader nanochat environment.
Relationship to nanochat’s “time to GPT‑2”
Autoresearch is explicitly described as a simplified single-GPU implementation of nanochat. The nanochat README provides context on what “scaling up” means in Karpathy’s ecosystem:
- Nanochat is a broader harness covering tokenization, pretraining, finetuning, evaluation, inference, and a chat UI.
- It maintains a “Time-to-GPT-2 Leaderboard” measuring wall-clock time to reach GPT‑2 grade capability on an 8×H100 node, “as measured by the DCLM CORE score,” with
val_bpbreported alongside. - It describes GPT‑2 capability as approximately “depth 26,” and notes that code can run on a single GPU by omitting distributed launch, but will take ~8× longer.
This clarifies how autoresearch could function as a research accelerator: use the small harness to search for promising settings quickly, then test transfer to the larger leaderboard-driving runs—in line with Karpathy’s “transfer to depth 24” claim.
Conceptual timeline of an overnight run
The following mermaid chart is conceptual (not an exact trace of any particular run), but it reflects the intended cadence: one 5-minute “generation” per experiment, repeated for hours.
00:0000:0000:0100:0100:0200:0200:0300:0300:0400:0400:05Baseline (Gen 0)Gen 1 (mutation)Gen 2 (mutation)Gen 3 (mutation)Gen 4 (mutation)Gen 5 (mutation)Gen 6 (mutation)Gen 7 (mutation)Gen 8 (mutation)Gen 9 (mutation)Gen 10 (mutation)Gen 11 (mutation)Gen 12 (mutation)ExperimentsConceptual overnight autoresearch session (5-minute experiments)Show code
Limitations, failure modes, and safety considerations
Autoresearch’s appeal—“loop forever, unattended, with code execution”—is also the source of its fragility. The repo and its issues highlight several concrete limitations, and broader analysis suggests additional failure modes.
The most fundamental limitation: “self-improving” is bounded by a fixed evaluator
Autoresearch is not open-ended self-improvement; it is optimization under a fixed metric. The agent cannot (by rule) modify prepare.py or evaluate_bpb, and the goal is “get the lowest val_bpb.”
That makes the system closer to automated hyperparameter/architecture search than to recursive self-improvement. It also means that any “intelligence gain” is only meaningful insofar as val_bpb improvements translate to downstream outcomes—and how often they do is an empirical question.
Reward hacking and overfitting to the micro-benchmark
Even with a fixed evaluator, there are plausible “benchmark gaming” routes:
- Throughput tricks: because the budget is time-based, changes that increase steps within 5 minutes can dominate improvements, even if they wouldn’t be optimal at longer horizons. The session reports themselves emphasize “more steps > more params” under this regime.
- Proxy mismatch: a 5-minute run emphasizes early training dynamics; settings that win early may lose later. Autoresearch does not (by default) evaluate longer training curves.
- Transfer uncertainty: Karpathy claims transfer from depth 12 to depth 24, but transfer can fail in general when scaling changes optimization regimes. Treat transfer as a hypothesis until independently reproduced.
Variance, instability, and noisy gradients
The training script seeds random number generators (e.g., torch.manual_seed(42)), but GPU kernels, compilation, and fused ops can still introduce nondeterminism.
The session reports show evidence of fragility: seed changes sometimes help by tiny amounts, sometimes regress; some ideas “did NOT reproduce” across sessions. This is normal for small-budget experiments, but it means a “keep” decision can be partly noise-driven unless runs are repeated or uncertainty is modeled.
Agent reliability is tool-dependent
Autoresearch assumes an agent will continuously follow the “NEVER STOP” instruction. In Issue #57, Karpathy reports that “Codex doesn’t work… because it ignores instruction to never stop (unlike Claude)” and notes a preference for interactive sessions rather than non-interactive loops.
This matters operationally: even if the harness is sound, real-world outcomes depend on the agent’s obedience, persistence, context handling, and tool integration.
Concrete security risks surfaced by the community
Two repo issues articulate serious, practical security concerns that arise specifically because the system is an autonomous loop that runs code and reads back logs:
- Indirect prompt injection through run logs (Issue #64): program.md instructs the agent to read
run.log(viagrepandtail) after executingtrain.py. The issue argues that a compromised or modifiedtrain.pycould print malicious instructions that enter the agent’s context and influence subsequent actions—especially dangerous in unattended overnight mode. - Trust boundary in cached artifacts (Issue #41):
prepare.pyreloads cached artifacts such astokenizer.pklandtoken_bytes.ptwithout integrity checks; this is normally fine locally but risky on shared machines or copied caches.
Both issues point to a broader point: once an agent is allowed to execute code, any text it reads back becomes an attack surface unless strict sanitization, sandboxing, and permission boundaries are implemented.
The README already gestures toward safety by recommending disabling permissions for the agent, but this is advisory, not enforced.
Ethical concerns: compute, data, and incentives
Autoresearch also raises ethical questions typical of agentic and AutoML workflows:
- Compute externalities: even “one GPU overnight” can be substantial energy use when run continuously at scale. Autoresearch’s framing (“run forever”) encourages persistent compute usage.
- Data governance: the repo downloads large-scale text data from a dataset whose documentation is sparse (empty dataset README). Without clear provenance, it is hard to assess licensing, bias, or consent issues.
- Incentive alignment: optimizing a single metric can incentivize brittle engineering choices; program.md tries to counterbalance this with a “simplicity criterion,” but that criterion is subjective and agent-dependent.
Assumption note: this article does not assert that the dataset is improperly licensed or that the system is unsafe by default. The point is that the project’s architecture makes these questions salient, and the repo itself documents security concerns that would matter in real deployments.
Where this fits in AutoML history and what may come next
Autoresearch feels new because a coding agent is now the “researcher” modifying code, but the underlying form—search over design choices guided by a metric—has deep roots. Understanding those roots helps clarify what autoresearch does (and does not) imply.
Comparisons to prior approaches
Neural Architecture Search (NAS)
NAS popularized the idea that architectures can be generated by a controller model and optimized against validation performance. Zoph & Le (2016) describe generating network descriptions with an RNN and training the controller via reinforcement learning to maximize validation-set accuracy.
Evolutionary architecture search / regularized evolution
Real et al. (2018; published 2019) presents “regularized evolution,” adding an age property to tournament selection to favor younger genotypes, and reports strong image classifier results.
Population-Based Training (PBT)
Jaderberg et al. (2017) presents PBT as an asynchronous approach that uses a fixed computational budget to train a population of models while mutating hyperparameters, propagating successful configurations.
Hyperparameter optimization with early-stopping (Hyperband)
Li et al. (2016) proposes Hyperband: allocate resources adaptively among randomly sampled configurations, emphasizing early stopping and “over an order-of-magnitude speedup” relative to competitors on some problems.
Autoresearch differs less in “search mathematics” than in workflow packaging: it uses the strength of modern coding agents to move the search space from “declared hyperparameters” to “the entire training script,” while keeping evaluation fixed and time-boxed.
Comparison table
| Approach | Scope | Human role | Compute | Metric | Typical run time | Reproducibility |
|---|---|---|---|---|---|---|
| Autoresearch | Whole training script on one machine; architecture + optimizer + schedule + code-paths in train.py | Human writes/edits program.md; agent edits code and runs experiments | Single GPU by design; results are platform-specific due to wall-clock budget | val_bpb fixed in evaluator (evaluate_bpb) | Fixed ~5 minutes per experiment (training time) | High within one platform if frozen env; low cross-platform comparability |
| NAS (RL controller) | Architecture search in a defined space; controller generates architectures | Human defines search space; algorithm trains controller and evaluates candidates | Often large-scale in practice; paper emphasizes automated discovery via RL | Validation accuracy / perplexity depending on task | Hours to days depending on scale (varies widely; paper demonstrates end-to-end search) | Usually reproducible if search code + seeds + budget are fixed, but compute-heavy and sensitive to implementation details |
| Regularized Evolution | Architecture search via evolutionary tournament selection with aging | Human defines mutation ops and evaluation protocol | Scales with number of evaluated models; paper frames evolution as competitive and sometimes faster under same hardware | Validation/test accuracy on benchmarks (e.g., ImageNet) | Multi-day, many-model evaluation loops (varies by setup) | Reproducible when population, budget, and evaluation are controlled; sensitive to implementation and random seeds |
| Hyperband (HPO) | Hyperparameter tuning (not full code search), using early stopping/resource allocation | Human defines parameter ranges; algorithm samples and allocates resources | Efficient under fixed budgets via adaptive allocation | Task metric (loss/accuracy) | Designed to reduce wasted training; can run many short partial trainings | Often reproducible if the sampling seed and resource schedule are fixed |
This table is necessarily high-level: “typical run time” and compute vary widely across domains. The key comparison is that autoresearch makes “the search space” be code itself, while older frameworks typically search within an a priori parameterization (architectures, hyperparameters, or both).
Applications beyond ML research
The deeper pattern autoresearch illustrates is an agent loop with an objective metric and a keep/discard gate. That pattern generalizes beyond ML when three conditions hold:
- You can define a measurable fitness signal (conversion rate, latency, defect rate, revenue lift).
- You can run a controlled experiment repeatedly.
- You can automatically decide what survives (good changes) and what gets reverted.
Examples (hypotheses/inferences, not claims of current autoresearch features):
- A/B testing and growth optimization: mutate copy, UI variants, or pricing rules; keep only statistically significant improvements.
- Operational playbooks: mutate scheduling policies or incident-response workflows; keep only if on-call resolution time falls.
- Compiler/build optimization: mutate flags and code transformations; keep if runtime improves without correctness regressions.
Autoresearch’s contribution is not that it invents this loop; it shows a crisp implementation where the “mutation operator” is a coding agent and the “fitness function” is a fixed evaluator.
Collaboration, “SETI@home”-style scaling, and version control stress
Karpathy has explicitly explored how to make the loop collaborative. PR #44 proposes session PRs as “self-contained research contributions” (diff + commit history + results.tsv) so other agents can read and build on them.
In his posts about the project’s next steps, Karpathy also describes a vision of massively collaborative, asynchronous agent research and notes that existing Git workflows assume a “master” branch and short-lived PRs—an abstraction that may not map cleanly to thousands of long-lived agent branches of experimental commits.
The version-control challenge is real: Git is excellent at line-by-line diffs, but agent-driven research produces trees of experiments where you may want to adopt branches without merging, keep multiple competing lineages, and attach structured metadata/logs more like papers than PRs. Autoresearch’s emerging use of Discussions and PRs is an early attempt at this “research community” model.
Legal/IP and governance implications
Autoresearch is released under the MIT license. This makes the code highly permissive to use, fork, and incorporate. But governance questions remain:
- AI-generated contributions: session reports explicitly state they are “automated” and identify the agent used (e.g., Claude). The legal status of purely AI-generated code contributions can be jurisdiction-dependent and unsettled; practical governance may require contributor attestations or policy. (Inference; not asserted as settled law.)
- Data licensing and provenance: the training dataset is large and weakly documented (empty dataset README), which makes it difficult to reason about downstream licensing risk for trained models.
- Security posture: open issues already highlight prompt-injection and artifact-tampering risks in autonomous runs, suggesting that any serious deployment would need sandboxing, structured outputs, and integrity checks.
Realistic timelines and what autoresearch does not imply about AGI
Autoresearch is an impressive engineering artifact, but it does not, by itself, imply imminent AGI.
What it does demonstrate (grounded in primary sources):
- A practically runnable loop for autonomous ML experimentation with explicit constraints, a fixed evaluator, and a fixed per-experiment budget.
- Evidence that the loop can find meaningful improvements in the chosen metric in tens to hundreds of experiments, at least on a specific GPU platform (H100) and dataset setup.
- A plausible pathway to “scale up” by transferring discovered improvements to larger training runs (claimed by Karpathy) and integrating with a broader harness like nanochat.
What it does not establish:
- That the agent can autonomously generate genuinely new research directions without human strategy. In this repo, the human defines the goal, the evaluator, and qualitative constraints (simplicity, VRAM).
- That improvements in a 5-minute proxy necessarily translate to large-scale, long-horizon training success—though transfer is the hypothesis Karpathy is actively testing.
- That “self-evolving software” will safely run unattended without significant security hardening; the repo’s own issues show credible attack surfaces.
In short: autoresearch is best viewed as a sharp demonstration of an emerging workflow—spec-driven, metric-gated, agent-executed iteration—rather than as evidence that systems are becoming autonomously self-directing in the strong AGI sense. The project’s real significance may be social: it helps define what “research engineering” looks like when intelligence and persistence are no longer scarce, and when the bottleneck shifts toward picking objectives, defining evaluators, and securing the loop.
Primary source links (inline):
- Repository: karpathy/autoresearch
- Spec/instructions: program.md
- Fixed evaluator & data prep: prepare.py
- Mutable training script: train.py
- Session reports: Discussion #32, Discussion #43
- PR workflow proposal: PR #44
- Related larger harness: karpathy/nanochat
- Related foundational papers: NAS with RL (Zoph & Le, 2016), Regularized Evolution (Real et al., 2018), PBT (Jaderberg et al., 2017), Hyperband (Li et al., 2016)