

A technical summary of the Kimi Team’s paper on replacing fixed residual connections with learned, depth-wise attention in large language models.
TL;DR — What’s This Paper About in Plain English?
Imagine you’re building a skyscraper, and each floor needs to receive information from the floors below it. The standard approach in AI today is like a game of telephone — each floor just gets a blurry average of everything that came before it, with no way to say “actually, I really need what floor 3 said, not floor 47.” Over time, the signal gets diluted, and the deeper floors struggle to contribute meaningfully.
This paper from the Kimi Team at Moonshot AI proposes a smarter approach: instead of blindly averaging all previous floors, each floor uses a form of attention — the same mechanism that makes modern AI so powerful at understanding language — to selectively pick which earlier floors it actually wants to listen to. They call this Attention Residuals (AttnRes).
The result? A 48-billion-parameter AI model that learns better, trains more stably, and scores higher on nearly every benchmark they tested — all with minimal added computational cost.
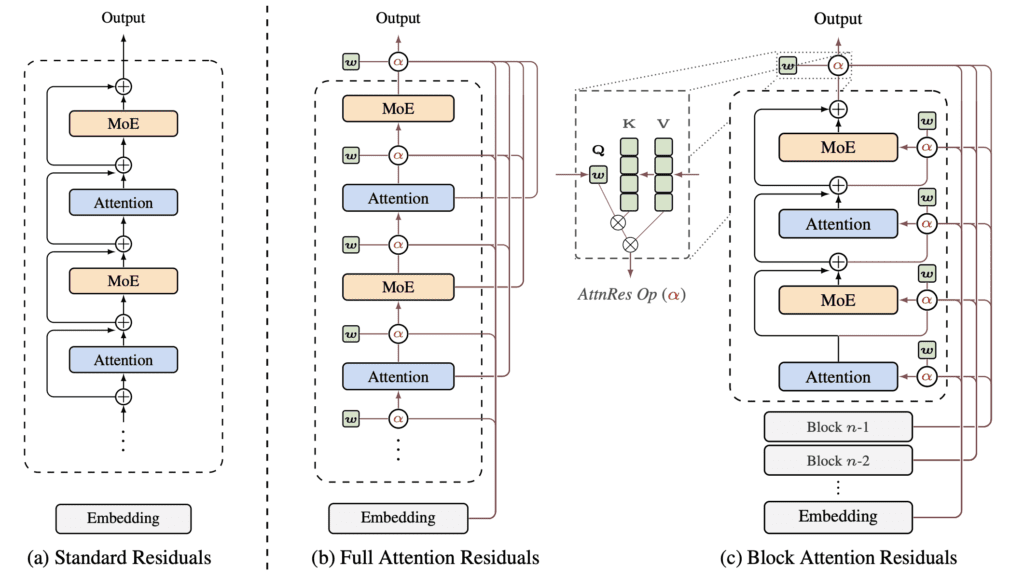
The Problem: Residual Connections Are Stuck in the Past
To understand why this matters, you need to know what a residual connection is. Introduced by He et al. in 2015 for image recognition, residual connections are the backbone of virtually every modern large language model (LLM), from GPT-4 to LLaMA to DeepSeek-V3. The idea is simple: when a layer processes information, it adds its output back to its input, creating a “shortcut” that lets gradients flow freely during training. This prevents the dreaded vanishing gradient problem that plagued deep networks before residuals came along.
The update rule looks like this: each layer’s output is just the previous layer’s state plus whatever transformation the current layer applies. Unrolled across all layers, this means every layer is receiving the same uniformly-weighted sum of all prior layer outputs — no layer gets to say “I care more about what layer 5 said than layer 50.”
This creates a well-documented problem called PreNorm dilution. As described in SiameseNorm (2026), hidden-state magnitudes grow proportionally with depth — O(L) — meaning that as you add more layers, each individual layer’s contribution gets progressively more diluted. Deeper layers are forced to produce increasingly large outputs just to stay relevant. Empirically, this is so bad that research has shown a significant fraction of layers in modern LLMs can be pruned entirely with minimal performance loss — a sign that many layers aren’t contributing much at all.
Prior attempts to fix this — like Highway Networks, DeepNet, DenseFormer, and Hyper-Connections — either use fixed weights, limit access to only the immediately preceding state, or are too expensive to scale. None of them fully solve the problem.
The Key Insight: Depth Is Just Another Sequence
The Kimi Team’s central observation is elegant: the way residual connections propagate information across depth is formally analogous to the way recurrent neural networks (RNNs) propagate information across time. And just as the Transformer architecture revolutionized sequence modeling by replacing RNN recurrence with attention, the same trick can be applied to the depth dimension.
In a standard residual network, each layer compresses all prior information into a single running state — exactly like an RNN. AttnRes breaks this bottleneck by letting each layer directly attend over all previous layer outputs with learned, input-dependent weights. Instead of h = Σ vᵢ (uniform sum), you get h = Σ αᵢ vᵢ, where the αᵢ are softmax attention weights computed from a single learned pseudo-query vector per layer.
This is a surprisingly lightweight change. Each layer only needs one extra d-dimensional vector (the pseudo-query), and the attention is computed over the depth dimension — which, unlike sequence length (potentially millions of tokens), is typically small (under 1,000 layers). The O(L²) arithmetic cost is therefore entirely manageable.
The paper also provides a beautiful theoretical unification: through a structured-matrix lens, standard residuals, Highway Networks, and Hyper-Connections can all be shown to perform depth-wise linear attention, while AttnRes performs depth-wise softmax attention — completing the same linear-to-softmax transition that proved transformative in sequence modeling.
Full AttnRes vs. Block AttnRes: Scaling the Idea
Full Attention Residuals work perfectly in small-scale training: since layer outputs are already kept in memory for backpropagation, there’s no extra memory cost. But at scale, things get complicated. Modern LLM training uses two techniques that break this assumption:
- Activation recomputation — layer outputs are discarded and recomputed during the backward pass to save memory.
- Pipeline parallelism — the model is split across multiple GPUs, and layer outputs must be transmitted between machines.
With Full AttnRes, all L layer outputs must now be explicitly stored and communicated across pipeline stages, creating O(Ld) memory and communication overhead. For a 48B-parameter model, this is prohibitive.
The solution is Block Attention Residuals (Block AttnRes). Instead of attending over all L individual layer outputs, the layers are grouped into N blocks. Within each block, layer outputs are summed into a single block-level representation. Across blocks, attention is applied over only these N compressed summaries. This reduces memory and communication from O(Ld) to O(Nd).
The key finding: empirically, N ≈ 8 blocks recovers most of the benefit of Full AttnRes across all model scales tested. That means you only need to store and communicate 8 hidden states per token — a dramatic reduction from potentially hundreds of layers.

Making It Work at Scale: Infrastructure Innovations
The paper doesn’t just propose the idea — it engineers it into a practical system. Two key infrastructure innovations make Block AttnRes viable for large-scale training and inference.
Cross-Stage Caching (Training). Under pipeline parallelism, a naïve implementation would re-transmit the full history of block representations at every pipeline stage transition, incurring quadratic communication cost. The Kimi Team’s solution: each physical GPU stage caches the block representations it has already received. When transitioning to the next virtual stage, only the incremental new blocks need to be transmitted. This reduces peak per-transition communication from O(C) to O(P) — a V× improvement (where V is the number of virtual stages per physical stage). The result: end-to-end training overhead under pipeline parallelism is less than 4%.
Two-Phase Computation (Inference). During inference, the attention residual at every layer would naively require a full pass over all preceding blocks — O(L·N) memory accesses total. The fix exploits the fact that pseudo-query vectors are learned parameters, not computed from the input. This means all S queries within a block can be batched into a single matrix multiplication against the cached block representations (Phase 1), amortizing the memory access cost from S reads to just 1. Phase 2 then handles the sequential intra-block dependencies and merges results using online softmax. The end result: inference latency overhead is less than 2% on typical workloads.
Experiments: Does It Actually Work?
Scaling Laws
The team trained five model sizes (ranging from ~194M to ~528M activated parameters) and fit power-law scaling curves. The results are clear: both Full and Block AttnRes consistently outperform the standard residual baseline across all compute budgets. At 5.6 PFLOP/s-days of compute, Block AttnRes achieves a validation loss of 1.692 versus the baseline’s 1.714 — equivalent to a 1.25× compute advantage. In other words, you’d need to train the baseline model on 25% more data to match what AttnRes achieves.
The 48B Model
The flagship experiment integrates Block AttnRes into the full Kimi Linear architecture — a 48B total / 3B activated parameter Mixture-of-Experts model — and pre-trains it on 1.4 trillion tokens. The results across downstream benchmarks are striking:
- GPQA-Diamond (graduate-level science reasoning): +7.5 points (36.9 → 44.4)
- Math: +3.6 points (53.5 → 57.1)
- HumanEval (code generation): +3.1 points (59.1 → 62.2)
- MMLU (general knowledge): +1.1 points (73.5 → 74.6)
- C-Eval (Chinese language understanding): +2.9 points (79.6 → 82.5)
AttnRes matches or outperforms the baseline on every single benchmark evaluated. The gains are especially pronounced on multi-step reasoning tasks, consistent with the hypothesis that better depth-wise information flow helps compositional reasoning — where later layers need to selectively build on specific earlier representations.
Training Dynamics
The paper provides illuminating analysis of why AttnRes works better. Two key observations:
Output magnitude: In the baseline, hidden-state magnitudes grow monotonically with depth — the PreNorm dilution problem in action. With Block AttnRes, the selective aggregation at block boundaries resets the accumulation, yielding a bounded, periodic pattern. Deeper layers no longer need to shout to be heard.
Gradient distribution: Standard residuals provide no mechanism to regulate gradient flow, leading to disproportionately large gradients in the earliest layers. The learnable softmax weights in AttnRes introduce competition among sources for probability mass, resulting in a substantially more uniform gradient distribution across all layers — a healthier training signal throughout the network.
Ablation Study: What Actually Matters?
The team ran careful ablations to validate each design choice:
- Input-dependent vs. input-independent queries: Using a fixed learned pseudo-query (input-independent) achieves loss of 1.737. Making the query input-dependent (projected from the hidden state) improves this to 1.731, but adds a d×d projection per layer and complicates decoding. The default uses the simpler fixed query.
- Softmax vs. sigmoid: Softmax wins (1.737 vs. 1.741). The competitive normalization of softmax forces sharper, more decisive selection among sources.
- RMSNorm on keys: Critical. Without it, layers with naturally larger outputs dominate the attention weights. This is especially important for Block AttnRes, where block-level representations accumulate over many layers.
- Multi-head depth attention: Surprisingly, allowing different channel groups to attend to different source layers hurts performance (1.752 vs. 1.746). The optimal depth-wise mixture is largely uniform across channels — when a layer’s output is relevant, it’s relevant as a whole.
- Comparison with DenseFormer: DenseFormer uses fixed, input-independent scalar coefficients to combine all previous layers. It shows no gain over the baseline (1.767 vs. 1.766), highlighting that input-dependent weighting is essential — not just cross-layer access.
What the Model Learns: Visualizing Depth-Wise Attention
One of the most interesting sections of the paper visualizes the learned attention weight patterns. Several clear behaviors emerge:
Locality is preserved. Each layer attends most strongly to its immediate predecessor — the standard residual path remains dominant. AttnRes doesn’t throw away locality; it augments it.
Learned skip connections. Selective off-diagonal concentrations emerge — for example, layer 4 attending strongly to very early sources, or layers 15–16 reaching back across blocks. These are learned long-range skip connections that the model discovered were useful.
Layer specialization. The token embedding (h₁) retains non-trivial weight throughout training, especially in pre-attention layers. Pre-MLP layers show sharper reliance on recent representations, while pre-attention layers maintain broader receptive fields — consistent with attention layers routing information globally and MLP layers operating more locally.
Optimal Architecture: AttnRes Prefers Depth
An intriguing finding from an architecture sweep: under a fixed compute and parameter budget, the optimal architecture shifts when using AttnRes. The baseline prefers relatively wide, shallower networks (optimal at d_model/L_b ≈ 60). AttnRes shifts the optimum toward deeper, narrower networks (d_model/L_b ≈ 45).
This makes intuitive sense — if each layer can selectively retrieve information from any earlier layer, adding more layers becomes more valuable. The authors note this doesn’t directly translate to a deployment recommendation (deeper models have higher inference latency), but it’s a useful diagnostic for architecture search.
Conclusion: A Drop-In Upgrade for Modern LLMs
Attention Residuals is a conceptually clean, practically efficient, and empirically well-validated improvement to one of the most fundamental components of modern AI. By drawing on the formal duality between depth and time, the Kimi Team shows that the same attention mechanism that transformed sequence modeling can transform depth-wise information aggregation as well.
The key contributions are:
- A new theoretical framework unifying residual variants as instances of depth-wise linear or softmax attention.
- Block AttnRes, a scalable variant that reduces overhead from O(Ld) to O(Nd) with ~8 blocks recovering most gains.
- Infrastructure innovations (cross-stage caching, two-phase inference) that make the approach practical at scale with <4% training overhead and <2% inference overhead.
- Strong empirical results on a 48B model trained on 1.4T tokens, with consistent improvements across all evaluated benchmarks.
The code is available at github.com/MoonshotAI/Attention-Residuals. As future hardware relaxes memory constraints, the authors anticipate that finer-grained block sizes — or Full AttnRes itself — will become practical, further closing the gap between fixed residual accumulation and truly selective, content-aware depth-wise reasoning.







