There’s a very specific kind of comedy that only happens in tech.
It’s the moment a company realizes the tactic it normalized as “innovation” can also be done to them — and then reacts like it’s an unprecedented moral crisis.
That’s this story.
On February 23, 2026, Anthropic published a post accusing three Chinese AI labs — DeepSeek, Moonshot AI, and MiniMax — of running “industrial-scale” distillation campaigns against Claude (https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks). Anthropic claims these operations generated over 16 million exchanges using approximately 24,000 fraudulent accounts, violating its terms of service and regional access restrictions (same link).
Reuters reported the same day that Anthropic named those three labs and repeated the core numbers. The Verge summarized Anthropic’s breakdown and the per-lab scale (https://www.theverge.com/ai-artificial-intelligence/883243/anthropic-claude-deepseek-china-ai-distillation). Business Insider framed it as a “global AI race” story and noted Anthropic says Claude isn’t commercially available in China.
And then, instantly, the internet responded with the only reply it had in the chamber:
“wait… let me get this straight
people that stole the whole internet upset that the others are stealing from them?”
That line didn’t spread because it’s legally airtight. It spread because it’s emotionally perfect.
For years, the AI industry has been anchored to some version of this argument:
- training on huge swaths of publicly accessible data is inevitable
- the learning is transformative
- the models are not “copying,” they’re “learning”
- therefore: this is progress, and it’s fair (or at least… defensible)
Now the argument is:
- harvesting Claude outputs at scale is illicit extraction
- it’s “distillation attacks”
- it’s theft
- it’s a security issue
- it requires coordinated action and possibly policy response (https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks)
Same verb. Different direction.
Which is why the situation is, yes, genuinely hilarious — even while it’s also serious.
This article is about the irony, the incentives, and the uncomfortable truth nobody wants to say out loud:
Once you turn the internet into your training set, you teach the world that extraction is the business model.
Eventually, someone uses that model on you.

The allegation (what Anthropic says happened)
Let’s be precise, because this story is built to be misunderstood.
Anthropic is not saying: “Competitors tested Claude.”
Anthropic is saying: competitors built an industrial pipeline to generate Claude outputs at scale, to use those outputs to improve their own models — while evading controls.
In its post, Anthropic says it identified industrial-scale campaigns by DeepSeek, Moonshot, and MiniMax to “illicitly extract Claude’s capabilities” (https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks). Anthropic claims:
- over 16 million exchanges with Claude
- through approximately 24,000 fraudulent accounts
- using proxy services and coordinated infrastructure
- in violation of its terms of service and regional access restrictions (same link)
Reuters repeats the same overall allegation and numbers.
Business Insider adds a practical detail that matters to Anthropic’s framing: Claude isn’t commercially offered in China, so Anthropic argues the actors used workarounds.
Also important: these are allegations. They are Anthropic’s account. At least one outlet reported the accused labs did not immediately respond to requests for comment.
But regardless of how you feel about Anthropic, the post is valuable because it reveals what “industrial-scale distillation” looks like as an operation — not as an abstract concept.
And it looks like a factory.
Distillation, explained (and why the word suddenly has fangs)
Distillation is a standard technique in machine learning: train a smaller “student” model on the outputs of a larger “teacher” model.
Anthropic itself says distillation can be legitimate — for example, when labs use it to create smaller, cheaper models for customers — but argues that “foreign labs that illicitly distill American models” can remove safeguards and feed capabilities into their own surveillance or military systems.
So here’s the industry’s line in 2026:
- Legitimate distillation: you distill your own teacher, or you do it with explicit permission / licensing.
- Distillation attack: you industrialize access abuse (fraud accounts, proxies, evasion) to siphon outputs from someone else’s frontier model to build your own.
The technique is old. The fight is about permission and scale.
And that is exactly where the irony detonates.

Why the internet is laughing: “pot, meet kettle” isn’t a meme, it’s a timeline
The reason people dunked on Anthropic isn’t that they love fraud networks.
It’s that the AI industry has a credibility problem when it talks about “permission” and “stealing.” And in Anthropic’s case, the internet didn’t even have to be vague about it — there’s a very specific public record.
In September 2025, Reuters reported Anthropic agreed to pay $1.5 billion to settle a class action by authors who alleged the company used copyrighted books sourced from pirated websites to train Claude. Reuters also reported that Judge William Alsup ruled training could be fair use, but found Anthropic violated rights by storing over 7 million pirated books.
AP covered the settlement and later reported a judge approved it, describing allegations that hundreds of thousands of books were pirated to train chatbots and noting a rough “per book” payout figure discussed publicly.
So when Anthropic publicly complains about others “stealing” Claude outputs, the internet hears a sentence with a missing second half:
“Stealing is wrong…
…unless it’s the part where we did it to get here.”
That’s why posts like this went viral. Example: Gergely Orosz’s reaction (https://x.com/GergelyOrosz/status/2026015104085496263).
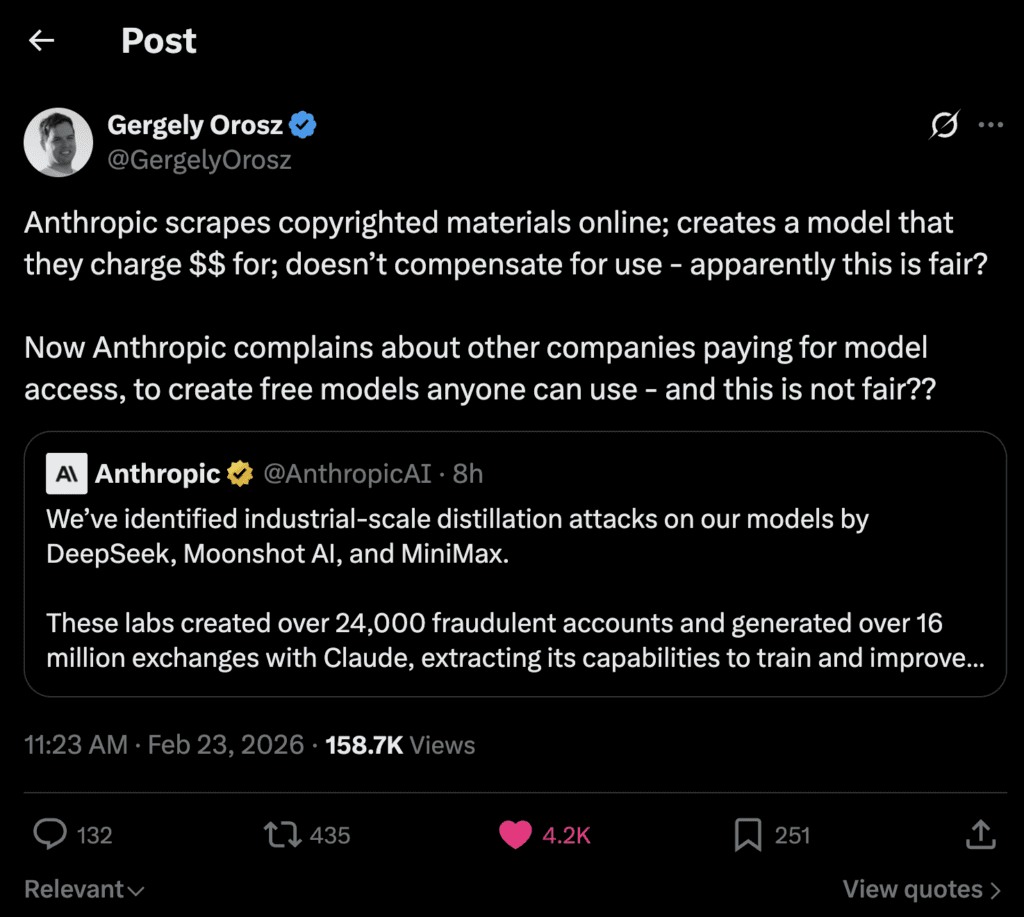
And that’s why this framing spread as a kind of meta-commentary:
Whether you agree with those takes or not, you can’t pretend they’re coming from nowhere. They’re anchored to how the public understands the last three years of AI.
The real punchline: moral language flips when the value flow flips
Here’s the core irony in one sentence:
When extraction creates value for you, it’s framed as progress.
When extraction removes value from you, it’s framed as harm.
That’s not “Anthropic bad.” That’s “incentives undefeated.”
In the training-data era, the industry’s posture was:
- “the internet is public”
- “learning is transformative”
- “we’re not reproducing”
- “fair use” (or at least “fair enough to ship”)
In the model-output era, the posture becomes:
- “outputs are proprietary capability”
- “extraction is illicit”
- “this undermines national security”
- “we need coordinated defense” see: https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks
Same pattern. New asset.
What changed?
Not the moral logic.
The direction of the value stream.
What Anthropic says each lab did (and why the details matter)
Anthropic didn’t just say “someone stole from us.” It tried to publish a case study playbook, including per-lab scale.
DeepSeek: 150,000+ exchanges, “reasoning” and “politically sensitive” redirection
Anthropic claims DeepSeek generated over 150,000 exchanges and targeted Claude’s reasoning and “rubric-based grading” tasks. Anthropic also alleges it observed prompts aimed at generating “censorship-safe alternatives to policy-sensitive queries,” which it suggests could be used to teach a model to avoid sensitive political topics (same link). The Verge highlights this allegation in its summary.
This is the detail that turbocharges the “AI cold war” narrative: it’s not just capability extraction, it’s values/guardrails extraction — selectively.
Moonshot AI: 3.4M+ exchanges, agentic behavior and “computer use”
Anthropic claims Moonshot’s campaign generated over 3.4 million exchanges, with targets including agentic reasoning, tool use, coding/data analysis, and computer-use agent development. Again, this is where the incentives get sharp: agentic patterns are not just knowledge, they’re product velocity.
MiniMax: 13M+ exchanges, and the “pivot within 24 hours” detail
Anthropic claims MiniMax generated over 13 million exchanges and focused on agentic coding and tool orchestration (https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks). Anthropic says it detected the campaign while it was still active, and when Anthropic released a new model during the campaign, MiniMax “pivoted within 24 hours,” redirecting nearly half their traffic to the latest system (same link). Business Insider highlighted that “pivot within 24 hours” line too.
That one detail makes the whole thing feel less like “someone copied us” and more like “someone built a standing operation.”
Not a heist.
A pipeline.
A subscription, except you didn’t sell it.
“Hydra clusters”: the anatomy of a prompt factory
Anthropic’s post also explains how these operations can work at scale: proxy services, distributed accounts, and a “whack-a-mole” architecture.
Anthropic describes “hydra cluster” setups — large networks of fraudulent accounts spreading requests across Anthropic’s API and third-party cloud platforms — and says that in one case, a single proxy network managed more than 20,000 fraudulent accounts simultaneously, mixing distillation traffic with unrelated customer requests to make detection harder.
That is not “a competitor hit refresh a lot.”
That’s an industry.
And the moment you say that sentence out loud — “prompt farms are now an industry” — you start to see the real game:
The internet used to be the raw dataset.
Now frontier models are the dataset.
Why model outputs are the best training data money can buy
Here’s the uncomfortable truth that makes distillation attacks inevitable:
The web is messy. Frontier outputs are clean.
The internet is raw ore.
Claude outputs are refined steel.
If you want to bootstrap a strong model quickly, you want:
- instruction → response pairs
- consistent formatting
- high signal-to-noise
- good explanations
- helpful structure
- more “aligned” defaults
A frontier model gives you all of that in a single API call.
So the economic temptation is obvious:
Why spend years cleaning the internet when you can generate millions of clean, high-quality samples from a frontier teacher?
That’s why distillation (legitimate or illicit) is so attractive.
And it’s why the “irony” isn’t just funny — it’s structurally inevitable.
Because the AI industry spent years telling the world:
- big intelligence is made by extracting from existing knowledge
- data is the lever
- scale wins
So competitors took the lesson and pointed it at the frontier.

The new “data wars” are output wars
If you want to understand why this is happening now, it’s because the bottleneck moved.
In 2021–2024, the bottleneck was data + compute
You needed:
- huge corpora
- gigantic training runs
- big clusters
- aggressive filtering
- and enough money to light a small country on fire
In 2025–2026, the bottleneck is frontier capability + iteration speed
You need:
- reliable reasoning
- tool use
- coding quality
- agentic planning
- and the ability to ship “agents” that actually work
If someone can harvest those behaviors from a frontier model, they don’t just steal “knowledge.” They steal iteration time.
They steal the last mile: the part where LLMs stop being chatbots and start being workers.
Which is why this feels existential to frontier labs.
And why it feels funny to everyone else.
The AI cold war framing (and why it’s being pushed)
Anthropic is explicitly trying to frame this as bigger than “Anthropic vs competitors.” It uses national security language and ties distillation to export controls (https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks).
TechCrunch framed Anthropic’s claims in the context of U.S. debates over AI chip exports (https://techcrunch.com/2026/02/23/anthropic-accuses-chinese-ai-labs-of-mining-claude-as-us-debates-ai-chip-exports/).
Reuters notes this announcement followed a memo from OpenAI warning U.S. lawmakers about DeepSeek attempting to replicate U.S. models via distillation (https://www.reuters.com/world/china/openai-accuses-deepseek-distilling-us-models-gain-advantage-bloomberg-news-2026-02-12/).
And it’s not just Anthropic and OpenAI talking about this. Google’s Threat Intelligence Group published a report noting that “distillation attacks” / model extraction are on the rise as a method of IP theft (Google Cloud blog: https://cloud.google.com/blog/topics/threat-intelligence/distillation-experimentation-integration-ai-adversarial-use).
So yes: the “AI cold war” storyline isn’t purely vibes. The major players are increasingly treating model extraction like a security threat category.
But here’s the thing:
Even if the threat is real, the internet still sees the irony.
Because the industry wants a world where:
- training on everyone else’s corpus was the “open commons” era
- but training on their outputs is the “protected IP” era
And the public response is essentially:
“You don’t get to retroactively invent a moral boundary that starts exactly where your profits begin.”
The key nuance: the irony is funny, but the allegation still matters
It’s possible for two things to be true:
- Anthropic may be describing real, coordinated abuse: fraudulent accounts, proxies, and industrial-scale output harvesting (https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks).
- Anthropic (and the wider industry) has a history of data extraction practices that the public sees as hypocritical, including Anthropic’s book-related settlement (Reuters: https://www.reuters.com/sustainability/boards-policy-regulation/anthropic-agrees-pay-15-billion-settle-author-class-action-2025-09-05/).
The internet is laughing at #2.
Frontier labs are panicking about #1.
Both reactions make sense.
But they point to the same underlying reality:
AI is an extraction economy.
And when your economy is built on extraction, you don’t get to act shocked when extraction shows up with a mask on.
“So… is this theft?” The real fight is permission, not technique
Strip the memes away and you’re left with the question that will define the next five years:
Does API access imply permission to learn from outputs?
There are three competing frames:
Frame A: Outputs are information, and information can be learned from
If I can observe a system, I can model it.
If I can model it, I can replicate it.
If I can replicate it, the burden is on you to defend.
This is the “security realism” view.
Frame B: Outputs are licensed behavior, not a training dataset
You can use outputs for your tasks.
You can’t use outputs to build a competing model.
If you do it by fraud and evasion, it’s abuse and a ToS violation.
This is the “contractual IP” view Anthropic is pushing.
Frame C: The public’s frame (the funny one)
You trained on people’s books and art without permission; now you’re mad someone trained on your outputs without permission.
This is not legal doctrine. It’s legitimacy doctrine.
And legitimacy is what determines how much sympathy you get.
If you’re a company that fought writers and creators in court, your sympathy budget is limited — even if your technical complaint is valid.
Why 2026 feels like “the year of open source” (and why that matters here)
When outputs can be harvested, closed models face a paradox:
- The more useful and accessible your model is, the more it becomes a dataset for competitors.
- The more you lock it down, the more you reduce adoption and goodwill — and the more you push developers toward open alternatives.
That’s why you’re seeing commentary like “2026 is the year of open source” show up in the same threads as distillation accusations (example: https://x.com/vasuman/status/2026005534126592215).
Open weight models don’t pretend they won’t be distilled.
They assume it.
They build ecosystems anyway.
So the competitive landscape may split into two philosophies:
- Lockdown labs: treat outputs like crown jewels; increase verification; rate-limit; monitor; fight proxy networks.
- Ecosystem labs: accept leakage, win on distribution, community, tooling, and iteration speed.
This story is a stress test for which philosophy wins.
What happens next: frontier labs become security companies
Anthropic’s post reads like a threat intel report because that’s where frontier labs are heading.
Anthropic says it has implemented and is developing defenses like:
- “behavioral fingerprinting systems”
- improved detection/verification for abuse pathways
- sharing threat indicators with other labs
- countermeasures to reduce the usefulness of extracted outputs for distillation without harming regular users (https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks)
Whether you love this or hate it, it implies the direction of travel:
- more KYC-style friction
- more monitoring
- more restrictions
- fewer “anonymous” ways to access frontier capability
The user experience gets worse.
The security posture gets tighter.
And the whole ecosystem becomes more “banking” than “web.”
Which is also ironic, because the early AI era sold itself as “open knowledge.” Now it’s building toll booths.
Sources:
- Anthropic post (Feb 23, 2026): https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks
- Reuters coverage (Feb 23, 2026): https://www.reuters.com/world/china/chinese-companies-used-claude-improve-own-models-anthropic-says-2026-02-23/
- The Verge summary: https://www.theverge.com/ai-artificial-intelligence/883243/anthropic-claude-deepseek-china-ai-distillation
- Business Insider summary: https://www.businessinsider.com/anthropic-deepseek-distillation-minimax-moonshot-ai-2026-2
- Reuters on Anthropic $1.5B settlement (Sep 5, 2025): https://www.reuters.com/sustainability/boards-policy-regulation/anthropic-agrees-pay-15-billion-settle-author-class-action-2025-09-05/
- AP on settlement: https://apnews.com/article/anthropic-copyright-authors-settlement-training-f294266bc79a16ec90d2ddccdf435164
- AP on approval: https://apnews.com/article/anthropic-authors-copyright-judge-artificial-intelligence-9643064e847a5e88ef6ee8b620b3a44c
- OpenAI memo reported by Reuters (Feb 12, 2026): https://www.reuters.com/world/china/openai-accuses-deepseek-distilling-us-models-gain-advantage-bloomberg-news-2026-02-12/
- Google Threat Intelligence report on distillation/model extraction: https://cloud.google.com/blog/topics/threat-intelligence/distillation-experimentation-integration-ai-adversarial-use
- Anthropic X post: https://x.com/AnthropicAI/status/2025997928242811253
- Reaction examples: https://x.com/ThePrimeagen/status/2026016322232983733 • https://x.com/vasuman/status/2026005534126592215 • https://x.com/GergelyOrosz/status/2026015104085496263