In every major technological transition, there’s a moment when the people closest to the technology realize something the rest of the world hasn’t caught up to yet. We’re in one of those moments right now.
The dominant narrative around AI and jobs goes something like this: AI is coming for white-collar work, engineers will write less code, knowledge workers will be displaced, and companies will do more with fewer people. It’s a tidy story. It’s also, based on what’s actually happening inside large enterprises right now, mostly wrong — or at least, wrong in the ways that matter most.
What’s actually emerging from the boardrooms, IT departments, and AI strategy sessions of major banks, retailers, healthcare systems, and media companies is something far more interesting: a new professional class. One that doesn’t have a clean job title yet. One that sits at the intersection of business strategy, technical systems, and AI behavior. One that is, right now, among the most sought-after and structurally secure roles in the entire economy.
Call them AI Orchestrators.

Aaron Levie, CEO of Box, recently posted a thread after spending a week on the road meeting with dozens of IT and AI leaders from large enterprises across banking, media, retail, healthcare, consulting, tech, and sports. His observation cut through the noise: “Becoming incredibly obvious that the most secure, best paying job in the next 1-3 years will be AI orchestrator — basically someone that coordinates AI agents to solve any problem a business has with EXTREMELY EFFICIENT token usage.”
This article is an attempt to unpack why he’s right, what it means for individuals, enterprises, and the broader economy — and why the conventional wisdom about AI and jobs is failing to capture what’s actually happening on the ground.
The Shift: From Chat Era to Agent Era
To understand why the AI Orchestrator role is emerging, you first have to understand what just ended and what’s beginning.
For the past two to three years, most enterprise AI adoption has lived in what you might call the chat era. This was the era of ChatGPT wrappers, Microsoft Copilot integrations, summarization tools, and AI-assisted writing. Useful, certainly. Transformative at the individual level, sometimes. But fundamentally, these tools were about answering — you asked a question, you got a response, you did something with it.
The productivity gains were real but they were also personal and siloed. An analyst who used Claude to summarize earnings reports got faster. A developer who used GitHub Copilot shipped code more quickly. But the system — the organization, the workflow, the business process — didn’t fundamentally change. The AI was a better search engine, a smarter autocomplete, a tireless assistant. It wasn’t doing work autonomously. It wasn’t connected to anything. It wasn’t making decisions.
That era is ending.
What’s replacing it is the agent era — and the distinction is not subtle. AI agents don’t just answer questions. They use tools. They access data. They execute multi-step tasks. They call APIs, write and run code, browse the web, fill out forms, process documents, and hand off work to other agents. The difference between a chatbot and an agent is roughly the difference between a consultant who gives you advice and an employee who actually does the work.
Levie’s conversations with enterprise leaders confirmed what many in the AI industry have been sensing: “Clear that we’re moving from chat era of AI to agents that use tools, process data, and start to execute real work in the enterprise.”
Complementing this shift is a change in how enterprises are approaching adoption. The early phase — what Levie calls the “let a thousand flowers bloom” approach — is giving way to something more deliberate. Companies that spent 2023 and 2024 running dozens of AI pilots across every department are now asking harder questions: Which of these actually moves the needle? Where do we concentrate resources? How do we scale what works?
This is the inflection point. And it’s precisely at this inflection point that the AI Orchestrator becomes indispensable.
The AI Orchestrator: Defining the Role
So what does an AI Orchestrator actually do?
The simplest definition: they coordinate multiple AI agents toward a business objective, managing the full stack of decisions that sit between “we have a problem” and “the agents solved it.” But that definition undersells the complexity.
In practice, an AI Orchestrator is responsible for:
- Task decomposition — breaking a complex business problem into discrete steps that agents can execute
- Model selection — choosing which AI model (or combination of models) is appropriate for each step, balancing capability against cost
- Prompt architecture — designing the instructions, context, and constraints that govern agent behavior
- Tool and data integration — ensuring agents have access to the right systems, APIs, and data sources
- Output validation — building evaluation loops that catch errors, hallucinations, and edge cases before they propagate
- Cost governance — monitoring token usage and optimizing for efficiency without sacrificing quality
- Stakeholder translation — communicating what agents can and can’t do to business leaders who don’t speak AI
This is not a software engineering role, exactly. It’s not a product management role, exactly. It’s not a data science role, exactly. It’s a new category — one that requires what might be called hybrid fluency: deep enough technical knowledge to understand how agent systems work, and deep enough business knowledge to understand what they should be doing.
The skill stack of an effective AI Orchestrator today looks something like this:
- Proficiency with agentic frameworks like LangGraph, CrewAI, AutoGen, or LlamaIndex Workflows
- Understanding of Model Context Protocol (MCP) and how agents interface with external tools and data
- Prompt engineering and chain-of-thought design at a systems level, not just a single-query level
- Workflow analysis — the ability to look at a business process and identify where agents can be inserted, and where they can’t
- Token economics — cost modeling, model routing, context compression, caching strategies
- Evaluation and observability — using tools like LangSmith or Braintrust to monitor agent performance in production
- Change management — the ability to bring humans along through a workflow transformation
This is not a list that describes any single existing job title. It’s a new role, and the people who are assembling this skill stack right now — whether they’re coming from engineering, product, consulting, or operations — are positioning themselves at the center of the most important technology transition of the decade.
One early organizational model is already emerging. As Levie noted, one enterprise he visited has “a head of AI in every business unit that roles up to a central team, just to keep all the functions coordinated.” This is the distributed orchestrator model — AI-fluent leaders embedded in the business, coordinating with a central team that sets standards, manages infrastructure, and governs costs.
It’s not unlike how data science teams were structured in the early 2010s, before the role became mainstream. The companies that built those capabilities early dominated their industries. The same dynamic is playing out now.
Tokenmaxxing: The New OpEx Battlefield
Here’s something that doesn’t get nearly enough attention in the mainstream AI conversation: running AI agents at enterprise scale is expensive, and the cost structure is unlike anything enterprises have dealt with before.

Traditional software has predictable costs. You pay for licenses, for compute, for storage. The marginal cost of one more user running your ERP system is roughly zero. AI agents are different. Every query, every reasoning step, every document processed consumes tokens — and tokens cost money. At the scale of a large enterprise running agents across dozens of workflows, those costs add up fast.
Levie’s conversations surfaced something that should be a wake-up call for anyone building or deploying AI systems: “Most companies operate with very strict OpEx budgets get locked in for the year ahead, so they’re going through very real trade-off discussions right now on how to budget for tokens.”
This is not a theoretical concern. It’s a live operational constraint. Enterprises are sitting in budget meetings right now trying to figure out how many tokens they can afford, which use-cases deserve priority access to frontier models, and how to ration compute across competing internal demands.
One company Levie spoke with came up with a creative solution: a “Shark Tank” style process for pitching compute budget. Teams present their AI use-case, make the case for why it deserves token allocation, and compete for resources. It sounds almost absurd — but it’s a rational response to a real scarcity problem. When your AI budget is finite and your internal demand is infinite, you need some mechanism for allocation. Internal markets for compute may become as common as internal markets for headcount.
Others are developing what Levie describes as a “hierarchy of needs” for compute — a framework for deciding which use-cases get access to expensive frontier models and which get routed to cheaper alternatives.
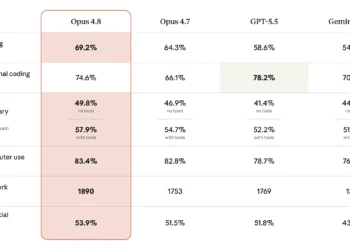
This is where the AI Orchestrator’s role as cost optimizer becomes as important as their role as capability deployer. The mandate that Levie articulates — “whoever figures out how to squeeze 90%-95%+ Opus 4.6 performance, 90%+ of the time, at 1/10th the cost is going to make AN ABSOLUTE KILLING” — is not hyperbole. It’s a precise description of the economic value at stake.
The techniques for achieving this are real and increasingly well-understood:
Model cascading / routing: Use a cheap, fast model (like Claude Haiku or GPT-4o mini) for the majority of tasks, and escalate to a frontier model only when the task genuinely requires it. Tools like LiteLLM and RouteLLM are being built specifically for this purpose.
Prompt compression and context management: Frontier models charge by the token, which means bloated prompts are literally expensive. Techniques for compressing context, summarizing conversation history, and stripping irrelevant information from prompts can dramatically reduce costs without sacrificing output quality.
Caching: Many enterprise AI workflows involve repeated queries with similar or identical inputs. Semantic caching — storing and reusing responses for semantically similar queries — can cut token costs by 40-60% in the right use-cases.
Fine-tuning smaller models: For well-defined, repetitive tasks, a fine-tuned Llama 3 or Mistral model running on your own infrastructure can match frontier model performance at a fraction of the cost. The upfront investment is higher, but the per-query economics are transformative at scale.
Structured outputs and constrained generation: Forcing models to output structured JSON rather than free-form text reduces the need for post-processing, cuts error rates, and often reduces token usage.
The AI Orchestrator who masters these techniques — who can deliver near-frontier performance at a fraction of frontier cost — is not just technically valuable. They’re financially valuable in a way that’s easy to measure and easy to justify to a CFO. That’s a rare combination.
The Infrastructure Problem: Legacy Systems as the Real Blocker
There’s a gap between the AI that gets demoed at conferences and the AI that actually runs inside large enterprises. That gap has a name: legacy infrastructure.
Most large enterprises are dealing with decades of accumulated technical debt. Systems that were built on-premises in the 1990s and 2000s. Cloud migrations that moved workloads to AWS or Azure but didn’t actually modernize the underlying architecture. Data that lives in dozens of different formats, databases, and silos, with no unified access layer.
This matters enormously for AI agents, because agents can only be as capable as the data and tools they can reach. An agent that can’t access your CRM, your ERP, your document management system, and your customer database in a unified way isn’t going to automate much. It’s going to hit walls constantly.
Levie’s conversations confirmed this is one of the top priorities for enterprise AI leaders right now: “Fixing fragmented and legacy systems remain a huge priority right now. Most enterprises are dealing with decades of either on-prem systems or systems they moved to the cloud but that still haven’t been modernized in any meaningful way. This means agents can’t easily tap into these data sources in a unified way yet.”
This creates a somewhat counterintuitive dynamic: the companies that invested in data modernization and API-first architecture over the past five years — often for reasons that had nothing to do with AI — are now dramatically better positioned to deploy agents than companies that didn’t. The boring infrastructure work of the 2010s is paying dividends in the 2020s.
For everyone else, the modernization effort is now urgent in a way it wasn’t before. AI agents are providing the business justification for infrastructure investments that IT teams have been requesting for years. “We need to modernize our data layer” is a much easier sell when the follow-up is “so that we can deploy agents that automate $50M of back-office work.”
Alongside this is what Levie calls the “headless software” mandate. Enterprises are increasingly insisting that every software system they use must be accessible to agents — not just to human users through a GUI. This means APIs, webhooks, MCP servers, and programmatic interfaces are no longer optional features. They’re table stakes. Vendors that don’t provide them will be replaced by vendors that do.
This is an existential moment for a lot of enterprise software companies. The SaaS model of the past decade was built around beautiful user interfaces and human workflows. The agent era requires a different kind of interface — one that machines can use as fluently as humans. Companies like Salesforce, ServiceNow, and Workday are racing to build agent-compatible interfaces. Others are moving more slowly, and they will feel the consequences.
The AI Orchestrator sits at the center of this infrastructure challenge. They need to understand not just how to prompt a model, but how to connect it to the systems that hold the data it needs. This requires knowledge of APIs, data pipelines, authentication systems, and increasingly, MCP — the emerging standard for how AI agents interface with external tools and data sources.
Change Management: The Human Problem No One Wants to Solve
Here’s the thing about AI agents that the technology press consistently underestimates: deploying them is a people problem as much as a technology problem.
Most business workflows were designed for humans doing discrete tasks in a specific sequence. A loan approval process. An invoice reconciliation workflow. A customer onboarding sequence. These processes have handoffs, approvals, exceptions, and edge cases that were designed around human judgment and human accountability. You can’t just drop an agent into the middle of one of these workflows and expect it to work. The workflow itself has to be redesigned.
Who owns the agent’s output? What happens when it makes a mistake? Who gets notified when an exception occurs? How do you audit what the agent did and why? These are not technical questions. They’re organizational and governance questions, and they require human decisions before a single line of agent code gets written.
Levie is direct about this: “Change management still will remain one of the biggest topics for enterprises. Most workflows aren’t setup to just drop agents directly in, and enterprises will need a ton of help to drive these efforts.”
The organizational model challenge is real. The “head of AI in every business unit” approach that one of Levie’s enterprise contacts has adopted is one solution — but it’s expensive, and it requires those AI leads to have enough credibility with their business unit to actually drive change, not just advise on it. That’s a rare combination of technical fluency and organizational influence.
There’s also a cultural dimension that’s easy to miss. The assumption in many AI discussions is that workers resist AI because they fear job loss. But Levie’s conversations reveal something more nuanced: workers are resisting — or at least struggling — because AI is making their jobs harder right now, not easier. “Unanimous sense that everyone is working more than ever before. AI is not causing anyone to do less work right now.”
This is actually a healthy sign, if a frustrating one. It means adoption is real — people are genuinely trying to integrate AI into their workflows — but the integration is still rough. The tools require more setup, more validation, more oversight than mature software. The productivity gains are coming, but they’re not here yet for most workers. Managing expectations through this trough is itself a change management challenge.

What good change management looks like in the agent era:
- Process redesign before agent deployment — map the workflow, identify the handoffs, redesign for agent participation before writing any code
- Pilot-first discipline — deploy in a controlled environment, measure rigorously, before scaling
- Internal champions — identify the people in each business unit who are genuinely excited about agents and empower them to lead adoption
- Clear accountability frameworks — define who is responsible for agent outputs and what the escalation path looks like when something goes wrong
- Honest communication about the transition period — acknowledge that things will be harder before they get easier
The AI Orchestrator who can do all of this — who can redesign a workflow, deploy an agent, and bring the humans along — is worth their weight in gold. And right now, there are very few of them.
The Jobs Narrative Is Wrong (In Both Directions)
Let’s address the elephant in the room: the widespread belief that AI agents are coming for white-collar jobs.
The fear is understandable. If an AI agent can process documents, write code, analyze data, and execute workflows autonomously, what exactly are humans supposed to do? The logical conclusion, for many observers, is mass displacement of knowledge workers.
But here’s what Levie’s conversations with enterprise leaders actually revealed: “Most companies are not talking about replacing jobs due to agents. The major use-cases for agents are things that the company wasn’t able to do before or couldn’t prioritize.”
Read that again. The primary use-cases for enterprise AI agents are net-new capabilities — work that wasn’t being done before, not work that humans were doing and agents are now replacing. Software modernization projects that were perpetually deprioritized because they required too much engineering time. Back-office automation for processes that were constraining other workflows but weren’t worth the cost of traditional automation. Processing tens of thousands of documents to extract insights that no analyst team could have produced in any reasonable timeframe.
This is a crucial distinction. When AI enables a company to do something it couldn’t do before, that’s not displacement — that’s expansion. And the economic framing that Levie’s enterprise contacts are using reflects this: “More emphasis on ways to make money vs. cut costs.”
This doesn’t mean job displacement isn’t happening or won’t happen. It will. But the timeline and the mechanism are different from the popular narrative. The displacement, when it comes, will be gradual, uneven, and concentrated in specific types of roles — particularly mid-level knowledge work that is well-defined, repetitive, and doesn’t require deep contextual judgment.
What’s happening right now, in the near term, is something different: a bifurcation of the workforce along a new axis. On one side: people who can work effectively with agent systems — who understand how to prompt them, evaluate them, integrate them, and orchestrate them. On the other side: people who can’t, or won’t.
The second half of the jobs narrative that’s wrong is the claim that AI is eliminating the need for engineers. This one is almost the opposite of the truth.
Levie’s meta-observation from his week on the road is worth quoting at length: “It seems that despite Silicon Valley’s sense that AI has made hard things easy, the most powerful ways to use agents is more ‘technical’ than prior eras of software. Skills, MCP, CLIs, etc. may be simple concepts for tech, but in the real world these are all esoteric concepts that will require technical people to help bring to life in the enterprise.”
And then the punchline: “Engineers may not be ‘writing’ software, but they will certainly be the ones to setup and operate the systems that actually automate most work in the enterprise.”
This is the insight that most AI commentary misses. The abstraction layer has moved — engineers are now orchestrating systems rather than writing every line of code — but the technical depth required to do this well has not decreased. If anything, it’s increased. Building a reliable, cost-efficient, production-grade multi-agent system requires understanding of distributed systems, API design, evaluation methodology, security, observability, and AI behavior. That’s not a skill set that disappears when LLMs get better at writing boilerplate code.
The premium on engineering talent — specifically, engineers who understand AI systems — is going up, not down. The market is already reflecting this. AI engineers, ML engineers, and now AI Orchestrators are among the highest-compensated roles in the technology industry, and the gap between them and traditional software engineers is widening.
The Multi-Agent World and the Interoperability Imperative
One of the clearest themes from Levie’s enterprise conversations is that no company is going to run a single AI system. The multi-agent world is not a future state — it’s already here.
Different use-cases require different models. Different workflows require different agent frameworks. Different data sources require different integration approaches. A large enterprise might be running Anthropic’s Claude for document analysis, OpenAI’s GPT-4o for customer-facing applications, a fine-tuned open-source model for internal classification tasks, and a specialized coding agent for software development — all simultaneously, all needing to coordinate with each other and with the underlying business systems.
This creates an interoperability challenge that is, right now, one of the hardest unsolved problems in enterprise AI. How do agents from different vendors, built on different frameworks, running on different infrastructure, share context, hand off tasks, and coordinate toward a common objective?
The emerging answer is Model Context Protocol (MCP), an open standard developed by Anthropic that defines how AI agents interface with external tools and data sources. MCP is gaining rapid adoption — major AI companies and enterprise software vendors are building MCP servers that expose their systems to any MCP-compatible agent. It’s the closest thing the industry has to a universal adapter for the agent ecosystem.
But MCP is still young, and the broader interoperability challenge extends beyond tool access to agent-to-agent communication, shared memory, and cross-system orchestration. Frameworks like Google’s Agent2Agent (A2A) protocol are attempting to address the agent communication layer. The standards are still forming.
This creates a strategic dilemma for enterprises that Levie captures precisely: “Clear sense that it can be hard to standardize on anything right now given how fast things are moving. Blessing and a curse of the innovation curve right now — no one wants to get stuck in a paradigm that locks them into the wrong architecture.”
The companies navigating this best are building for flexibility over optimization. Rather than committing deeply to any single agent framework or vendor, they’re building abstraction layers that allow them to swap components as the technology evolves. This is harder to build and harder to operate, but it’s the right bet when the underlying technology is changing as fast as it is.
The AI Orchestrator’s role in this environment is to be the architect of flexibility — designing systems that can evolve without requiring a complete rebuild every six months.
The Diffusion Gap: Why Real-World AI Adoption Moves Slower Than Silicon Valley Thinks
There’s a persistent disconnect between how AI progress looks from inside the technology industry and how it looks from inside a large enterprise in banking, healthcare, or retail.
From inside Silicon Valley, the trajectory feels almost vertical. New models drop every few weeks. Capabilities that seemed impossible six months ago are now routine. The pace of progress is genuinely staggering, and it’s easy to conclude that enterprise transformation is just around the corner.
From inside a large enterprise, the view is different. You have compliance requirements that take months to navigate. You have procurement processes that add quarters to any vendor relationship. You have IT security reviews that can block a new tool for a year. You have change management challenges that require executive sponsorship, training programs, and careful rollout plans. You have legacy systems that weren’t designed to talk to anything, let alone an AI agent.
Levie’s observation cuts to the heart of this: “Skills, MCP, CLIs, etc. may be simple concepts for tech, but in the real world these are all esoteric concepts that will require technical people to help bring to life in the enterprise. This both means diffusion will take real work and time.”
The concepts that feel obvious to an AI engineer — spinning up an MCP server, building a LangGraph workflow, evaluating agent outputs with a custom rubric — are genuinely foreign to most enterprise IT teams, let alone business users. The gap between “this is technically possible” and “this is deployed and running reliably in production at a Fortune 500 company” is measured in years, not months.
This has several important implications:
The consulting and systems integration opportunity is enormous. Companies like Accenture, Deloitte, and McKinsey are already building massive AI services practices, and the demand for people who can bridge the gap between AI capability and enterprise reality will only grow. Boutique AI implementation firms are going to have a very good decade.
The companies building internal orchestration capability now will have a durable competitive advantage. The enterprises that are investing in AI Orchestrator talent, building agent-ready infrastructure, and developing internal token governance frameworks today are not just getting a head start — they’re building organizational muscle that will be very hard for competitors to replicate quickly.
The timeline for widespread enterprise AI transformation is longer than the hype suggests. Genuinely transformative deployment of AI agents across large enterprises is a five-to-ten year story, not a one-to-two year story. The technology is ready faster than the organizations are. That’s not a criticism — it’s just the reality of how large institutions change.
What This All Means: Strategic Takeaways
The picture that emerges from all of this is more nuanced, more interesting, and more actionable than the standard AI-and-jobs narrative. Here’s what it means for the people and organizations navigating this transition:
For individuals: The most valuable investment you can make right now is in the skill stack of the AI Orchestrator. This doesn’t necessarily mean becoming a software engineer — it means developing genuine fluency with how agent systems work, how to design workflows for them, how to evaluate their outputs, and how to manage the costs of running them. The people who can do this, and who can also communicate effectively with business stakeholders, will be in extraordinary demand for the next decade. Start with LangChain’s documentation, explore Anthropic’s MCP, and build something real — even if it’s small.
For enterprises: The three investments that matter most right now are infrastructure modernization (so agents can actually reach your data), internal orchestration talent (so you have people who can deploy and manage agents effectively), and token governance frameworks (so you can scale AI usage without blowing your OpEx budget). The companies that get all three right will have a structural advantage that compounds over time.
For software vendors: The headless software mandate is not optional. If your product can’t be accessed programmatically by an AI agent — if it doesn’t have robust APIs, MCP support, or equivalent interfaces — you are at risk of being replaced by a competitor that does. This is not a future concern. Enterprise buyers are making these decisions now.
For investors: The value in the AI stack is not concentrated only at the model layer. The orchestration layer — the tools, frameworks, and platforms that help enterprises deploy, manage, and optimize AI agents — is where a significant portion of enterprise AI value will accrue. Companies building in evaluation, observability, token optimization, agent frameworks, and enterprise integration are worth close attention.
For policymakers: The jobs narrative needs to catch up to enterprise reality. The near-term story is not mass displacement — it’s a skills bifurcation and a significant increase in demand for technical talent. Policy responses focused on retraining and technical education are more relevant right now than responses focused on displacement mitigation. The displacement story may come, but it’s not the story of 2025 and 2026.
Conclusion
There’s a version of the AI future that gets told a lot: AI gets smarter, humans become redundant, the economy restructures around a small number of AI companies and a large number of displaced workers. It’s a compelling narrative. It’s also not what’s happening in the enterprises where AI is actually being deployed at scale.
What’s actually happening is messier, more human, and ultimately more interesting. Enterprises are grappling with legacy systems that agents can’t reach. They’re running Shark Tank competitions for token budgets. They’re hiring heads of AI for every business unit just to keep the coordination from breaking down. They’re redesigning workflows that were built for humans to accommodate machines that work differently. And they’re doing all of this while their teams are working harder than ever, not less.
At the center of all of it is a new kind of professional. Someone who understands AI well enough to deploy it, business well enough to direct it, and systems well enough to connect it to the data it needs. Someone who can optimize for cost without sacrificing capability, manage change without losing momentum, and navigate a technology landscape that’s shifting faster than any standards body can keep up with.
The AI Orchestrator.
In five years, this role will be as recognizable as Product Manager or Data Scientist — a standard part of the organizational chart at any company that takes technology seriously. The people who are building this skill set now, who are getting their hands dirty with agent frameworks and MCP servers and token optimization strategies, are not just preparing for a job that will exist. They’re preparing for a job that will be foundational to how the entire economy operates.
The age of AI agents has arrived. The question isn’t whether your enterprise will use them. It’s whether you’ll have anyone who knows how to run them.
Want your AI product explained to a large AI-native audience?
Kingy AI helps AI companies turn complex products into clear, useful YouTube videos that drive awareness, product understanding, demos, clicks, and search visibility.