

TL;DR
OpenAI’s gpt-oss-120b, Qwen3-235B-A22B-2507, and DeepSeek-R1 represent the cutting edge in large language models, each with its own strengths and design philosophies. GPT-OSS-120B leverages an efficient mixture-of-experts (MoE) architecture with a modest active parameter count for high-level reasoning on a single H100 GPU, making it ideal for resource-conscious deployments. Qwen3-235B-A22B-2507, offered in separate “Thinking” and “Instruct” variants, excels in long-context and multilingual tasks, featuring a native support for 262K tokens and a dynamic routing scheme across 128 experts.
DeepSeek-R1 pushes the envelope further with an enormous parameter count, advanced RL training techniques, and sophisticated tokenization innovations to excel in chain-of-thought reasoning and self-verification, all while embracing an open MIT license. Each model has been rigorously benchmarked on tasks ranging from MMLU, GSM8K, and HumanEval to domain-specific evaluations, offering a rich mix of performance, versatility, and accessibility for academic, commercial, and experimental uses.

Introduction
The landscape of large language models (LLMs) has never been more exciting or competitive. Recent releases—OpenAI’s gpt-oss-120b, Qwen3-235B-A22B-2507, and DeepSeek-R1—signal an era where open-weight models are not only pushing theoretical performance boundaries but are also being optimized for real-world deployment. Each model deploys an intricate blend of innovation in Mixture-of-Experts architectures, novel tokenization methods, and long-context understanding.
Their rigorous evaluations across standard benchmarks, coding challenges, and multilingual tasks have made them focal points for research labs, developers, and industry practitioners alike.
This article provides an exhaustive and authoritative comparison of these three models. By delving into their architectures, benchmarks, licensing models, available ecosystems, and real-world applications, the discussion serves as a comprehensive guide for anyone looking to understand the current state-of-the-art in open-weight LLMs.
Model Architecture and Technical Specifications
OpenAI GPT-OSS-120B
GPT-OSS-120B is distinguished by its lean yet efficient design. Despite having 117 billion total parameters, only about 5.1 billion parameters are activated per token during inference. This efficiency is largely attributable to its Mixture-of-Experts (MoE) architecture. The model employs native MXFP4 quantization for its MoE layers, enabling dynamic routing that minimizes computational overhead. The design particularly favors environments where hardware availability is at a premium—the entire model can be effectively run on a single H100 GPU.
A notable aspect of GPT-OSS-120B’s architecture is its focus on chain-of-thought reasoning. The design incorporates configurable reasoning efforts, allowing the model to adjust its computational depth depending on the complexity of the task at hand. Its deployment across popular frameworks—ranging from Hugging Face Transformers to vLLM and Ollama—ensures that developers have a robust infrastructure to build upon. This model also employs a standard Byte Pair Encoding (BPE) tokenizer, ensuring a reliable encoding of language across many domains. For further technical details, consult the OpenAI Model Card.
Qwen3-235B-A22B-2507
In contrast, Qwen3-235B-A22B-2507 represents the next step in scalability combined with specialized task optimization. With a total of 235 billion parameters and 22 billion active parameters per token, it offers substantial raw computational power. The model’s architecture incorporates 128 experts with a dynamic gating mechanism that statically or adaptively activates 8 experts per token. This design is especially beneficial for managing long-context tasks, complemented by native support for up to 262,144 tokens—a feature that stands out for applications involving lengthy documents or intricate reasoning scenarios.
The development of Qwen3 has been cautiously segmented into two distinct variants: the “Thinking” variant, which is optimized for deep reasoning, coding, and mathematical problem solving, and the “Instruct” variant, which is tailored for instruction-following and general-purpose interaction. This bifurcation not only allows targeted improvements based on use cases but also provides developers with a flexible toolkit calibrated to specific domain requirements.
Its tokenizer deviates from the conventional by deploying a customized BPE algorithm with a vocabulary exceeding 150,000 tokens, enhancing its prowess in handling non-Latin scripts and multilingual challenges. More technical details can be found on Qwen’s Hugging Face page.
DeepSeek-R1
DeepSeek-R1 enters the fray with an ambitious scale—boasting 671 billion total parameters with about 37 billion active during inference. This model leverages a similarly dynamic MoE design but couples it with reinforcement learning (RL) techniques to refine its chain-of-thought pathways and self-verification mechanisms. The architecture is built on the premise of adaptive reasoning, where the model not only produces answers but is capable of checking and refining them via internal self-reflection loops.
To aid in efficient handling of lengthy contexts, DeepSeek-R1 supports up to 128,000 tokens, striking a balance between extreme long-context applications and computational feasibility. Its tokenization process incorporates advanced methods such as Soft Token Merging and Dynamic Token Inflation, innovations that allow the model to represent complex linguistic structures more efficiently. As a product of iterative refinement through RL, DeepSeek-R1 also leverages external sources such as distilled models ranging from 1.5B to 70B parameters to ensure that even scaled-down variants retain robust performance. Additional information can be found via the DeepSeek-R1 GitHub repository.

Benchmarking and Performance
The true test of any large language model lies in its performance across a range of interdisciplinary benchmarks. With benchmarks such as MMLU (Massive Multitask Language Understanding), GSM8K (Grade School Math Benchmark), HumanEval, and BigBench, these models have been evaluated on their abilities to demonstrate reasoning, coding, and multilingual competencies.
Reasoning and Multitask Performance
GPT-OSS-120B has emerged as a strong contender in reasoning benchmarks due to its configurable depth of computation. Independent evaluations reveal that its chain-of-thought reasoning abilities allow it to navigate multi-step problems with commendable accuracy. Its performance on MMLU tasks suggests a balanced approach between general language understanding and specialized problem-solving. The efficient activation of a reduced parameter set per token further contributes to its readiness for real-time applications, a claim substantiated by benchmarks carried out on similar open-weight models.
Qwen3-235B-A22B-2507, with its “Thinking” variant specifically optimized for reasoning tasks, has demonstrated leading performance on benchmarks like AIME25—a competition-style assessment of mathematical reasoning. Its dynamic expert activation, combined with a long-context window, permits it to engage with complex multi-step problems more adeptly than many contemporaries. The “Instruct” variant, meanwhile, consistently ranks high on benchmarks that evaluate instruction-following capabilities, making it versatile in both technical and conversational tasks. Evaluations on multilingual benchmarks have also highlighted its superior performance, particularly in tasks demanding nuanced language understanding across languages.
DeepSeek-R1, designed with reinforcement learning in its training loop and self-verification modules, excels in benchmarks that rely on chain-of-thought reasoning. Reports from controlled evaluations consistently place DeepSeek-R1 at the upper end of scoring on the MMLU and GSM8K benchmarks, thanks largely to its iterative solution refinement mechanism. Its performance on coding benchmarks such as HumanEval is especially notable—the model not only generates correct solutions but is also capable of self-diagnosis and re-optimization in complex coding scenarios. Testimonies from independent third-party evaluations and community leaderboards, as reported on platforms like Hugging Face’s benchmarking page, underscore its strength in dynamic reasoning and long-context processing.
Coding and Problem-Solving
The MicroBenchmarks for coding, such as HumanEval and LiveCodeBench, present telling comparisons. GPT-OSS-120B shows remarkable competence in generating syntactically and semantically valid code snippets, a direct consequence of its robust training on technical documents and programming languages. Its design also allows for on-the-fly function calling and rudimentary debugging, attributes that have not gone unnoticed in developer circles.
Qwen3-235B-A22B-2507 raises the bar further—particularly in its “Thinking” variant—with its tailored training data that includes sophisticated chain-of-thought prompts specifically designed for programming challenges. Benchmarks indicate that it handles code generation and debugging tasks with a fluency that rivals industry front-runners. Its multilingual capabilities ensure that it supports code documentation and commentary in multiple languages, broadening its use in international development teams.
DeepSeek-R1 is particularly celebrated for its performance on complex coding challenges. Its reinforcement learning component emphasizes a cycle of production, verification, and correction—a cycle that enables the model to exceed standard performance and minimize errors. In scenarios where iterative refinement is necessary (for instance, in generating multi-file projects or intricate algorithm implementations), DeepSeek-R1’s performance metrics tend to reflect a superior ability to self-correct without external intervention, a critical quality for both research and commercial applications. This has been documented in technical analyses available from community benchmarking platforms and detailed in various Medium articles covering its performance statistics.
Multilingual Capabilities
Multilingual support is an area where both Qwen3-235B-A22B-2507 and DeepSeek-R1 demonstrate substantial advantages. The customized tokenizer in Qwen3, with its vocabulary exceeding 150,000 tokens, is expressly optimized for handling diverse scripts ranging from Latin-based languages to ideogram-heavy languages like Chinese and Japanese. This optimization not only improves accuracy in translation tasks but also enriches its performance in cross-lingual retrieval and conversation.
DeepSeek-R1 leverages advanced tokenization techniques to efficiently handle language nuances, including idiomatic expressions and cultural context factors. Its adaptability makes it effective in generating content that respects the semantic boundaries of different languages, an aspect that increasingly finds favor in multicultural application environments. GPT-OSS-120B, while competitive in English language benchmarks, does not emphasize multilingual optimizations to the same extent, making it a more targeted solution for environments with a single dominant language.
Long-Context Processing
A unique selling point for Qwen3-235B-A22B-2507 is its support for extremely long contexts—up to 262,144 tokens—allowing it to tackle tasks involving extensive documents, lengthy codebases, or intricate legal texts. This long-context capability is instrumental in domains such as legal research, large-scale academic writing, and comprehensive technical documentation.
DeepSeek-R1, with support for up to 128,000 tokens, strikes a balance between extended context and computational efficiency. Its advanced attention mechanisms ensure that long-context processing remains both accurate and resource-conscious. GPT-OSS-120B, while competitive in handling long contexts (up to 128,000 tokens), is traditionally optimized for environments where real-time performance and resource utilization are prioritized over ultra-long document processing.
Availability, Licensing, and Ecosystem Integration
Open-Source Philosophies and Licensing
Each of these models is designed with a commitment to accessibility, but they diverge in terms of licensing and overall integration within different ecosystems. GPT-OSS-120B is released under the Apache 2.0 license, aligning with OpenAI’s long-term vision of encouraging experimentation and commercial deployment. This permissive licensing model has contributed to its adoption across research labs and smaller startups alike, where the balance between intellectual property concerns and the need for technological advancement is carefully managed.
Qwen3-235B-A22B-2507 also embraces an Apache 2.0 license model. This ensures that both its “Thinking” and “Instruct” variants can be integrated into a wide array of applications—from multilingual chatbots to sophisticated document analysis tools. Its active presence on platforms like Hugging Face further underscores its widespread accessibility and the active role of its developer community in continually refining the model.
DeepSeek-R1 distinguishes itself not only with its formidable scale but also with its adoption of the MIT license. This license is well-regarded for its simplicity and permissiveness, fostering rapid innovation and adaptation in academic and enterprise circles alike. The MIT license has enabled DeepSeek-R1 to be forked and adapted for numerous specialized use cases, ensuring that even distilled versions (ranging from 1.5B to 70B parameters) maintain strong performance metrics while being accessible for local deployment. The availability of distilled variants has been particularly useful for developers who operate in environments with limited computational resources.
Ecosystem and Platform Availability
The ecosystem support for these models is as critical as their raw performance in determining their long-term impact. GPT-OSS-120B benefits from a robust presence across a diverse range of inference frameworks. Its compatibility with platforms such as Hugging Face justifiably places it at the nexus of innovation for cloud-based deployment, academic research, and industry-grade applications. In many cases, the ability to fine-tune GPT-OSS-120B on a single H100 GPU has lowered the barrier to entry for startups and individual developers.

Qwen3-235B-A22B-2507’s dual-variant approach has made it the model of choice for varied applications within enterprise environments. Its success in integrating with Alibaba Cloud and other advanced GPU-based infrastructures has accelerated its adoption in commercial settings. The comprehensive documentation and active community contributions on GitHub further enhance its appeal for organizations looking to rapidly prototype and deploy next-generation conversational agents or automated content generation systems.
DeepSeek-R1 has made significant inroads by targeting both large-scale corporate deployments and research institutions keen on pushing the envelope of reinforcement learning applied to language modeling. Its detailed guidelines for fine-tuning on local hardware, combined with extensive documentation on its distilled variants, have offered a rich ecosystem of tools and plugins for both research and production-level applications. Community-led projects and third-party integrations on platforms such as Hugging Face attest to its growing influence on the open-source LLM ecosystem.
Use Cases and Real-World Applications
Academic and Research Applications
In academic settings, the ability to fine-tune models for specialized use cases is invaluable. GPT-OSS-120B’s efficient activation of its MoE layers makes it particularly suited for research projects that require rapid iterations of chain-of-thought reasoning without significant computational overhead. Researchers have employed GPT-OSS-120B to experiment with novel reasoning paradigms, test hypothetical decision-making models, and explore the limits of low-resource model deployment on high-performance GPUs.
Qwen3-235B-A22B-2507, with its extended context window and dual variants, finds application in deep academic research that involves extensive document analysis, literature review, and multilingual textual synthesis. Its strong performance on benchmarks related to mathematical reasoning further enhances its prospects for academic inquiries spanning fields such as cryptography, algorithm theory, and quantitative social sciences.
DeepSeek-R1 is uniquely positioned for research projects that require dynamic problem solving and iterative solution refinement. Its reinforcement learning training loop has attracted researchers interested in exploring self-verification, iterative improvement, and meta-cognition in LLMs. The ability to distill DeepSeek-R1 into smaller variants also proves highly valuable in academic environments where computational resources are limited yet the need for robust chain-of-thought reasoning remains paramount.
Commercial and Enterprise Deployments
On the commercial front, the scalability and flexibility of these models lend themselves to a variety of applications. GPT-OSS-120B’s lean activation model is ideal for businesses focused on rapid customer support, real-time data analysis, and interactive virtual assistants. Its deployment across cloud infrastructures like Microsoft Azure and its compatibility with inference frameworks ensure minimal latency even under heavy loads.
Qwen3-235B-A22B-2507’s dual-variant design enables enterprises to deploy tailored solutions for both technical use cases (e.g., code generation, computational document analysis) and customer-facing applications that require refined instruction-following. Its expanded token limit ensures that documents of significant length—such as legal contracts, technical manuals, or healthcare records—can be processed in a single inference pass. This capability has made Qwen particularly popular among financial institutions, legal tech startups, and multinational corporates with diverse multilingual needs.
DeepSeek-R1’s approach to iterative reasoning and self-verification also caters to high-stakes environments where accuracy is critical. Industries such as healthcare, legal research, and governing bodies, where decisions depend on both speed and precision, have begun exploring DeepSeek-R1 as a solution for real-time document synthesis, risk assessment, and regulatory compliance. The flexibility provided by its MIT licensing model and distilled versions further assists in bridging the gap between cutting-edge research and rigorous industrial standards.
Creative, Content Generation, and Developer Applications
The creative industries and content development communities are also benefiting from these model innovations. GPT-OSS-120B’s ability to generate coherent narratives, tailored poems, or even technical documentation with a coherent chain-of-thought has made it a favorite among writers and digital content creators. Its open-source nature allows for rapid prototyping of creative applications that can be integrated directly into writing and editorial software.
Qwen3-235B-A22B-2507, with its enhanced multilingual capabilities and extended context acceptance, is finding applications in areas such as screenplay writing, long-form journalism, and academic thesis development. Its precise handling of long documents makes it an ideal tool for story generators that need to maintain narrative consistency over extended text passages.
DeepSeek-R1’s robust reinforcement learning pipeline and self-refinement capabilities open new avenues for developers. Its iterative process not only aids in reducing error rates in complex tasks but also provides a framework for building adaptive systems that continuously improve their outputs. This has significant implications for AI-powered coding assistants, automated research aggregators, and evolving digital art projects that explore novel intersections between language, art, and technology.
Unique Architectural Innovations and Feature Comparisons
Each model brings distinct innovations to the table, setting them apart from one another in meaningful ways.
GPT-OSS-120B
The innovations in GPT-OSS-120B primarily revolve around its efficient use of MoE architecture combined with native MXFP4 quantization. By activating only 5.1 billion out of 117 billion parameters per token, the system achieves a computational efficiency that reduces resource consumption without sacrificing performance. This design is particularly innovative in scenarios where real-time reasoning is required without the overhead normally associated with high-parameter models. Its flexibility in scaling reasoning effort—from low to high—enables dynamic adjustment based on task complexity, an innovative trait rarely seen in dense LLMs.
Qwen3-235B-A22B-2507
Qwen3-235B-A22B-2507 distinguishes itself with a dual-strategy approach. The modular “Thinking” and “Instruct” variants allow specialized tuning for either advanced problem-solving or responsive instruction processing. Its use of Rotary Position Embeddings (RoPE) enhances its capability to understand long-range dependencies, while the integration of a custom BPE tokenizer with a vast vocabulary increases its adaptability in multilingual settings.
The dynamic gating mechanism—activating only the most relevant experts from a pool of 128 per inference token—ensures that every computational resource is optimally deployed, especially in environments that demand processing extended contexts.
DeepSeek-R1
DeepSeek-R1 steps beyond traditional feed-forward reasoning by incorporating reinforcement learning strategies directly into its model training. This self-verification and iterative refinement process enables the model not only to produce outputs but also to internally gauge and, if necessary, correct them. The advanced tokenization strategies, such as Soft Token Merging and Dynamic Token Inflation, further push the envelope by enabling nuanced understanding and efficient representation of unusually complex sequences. The result is a model that exhibits an emergent form of metacognition—a feature that, although still under active research, offers significant promise for improving the reliability and safety of generative outputs.
Limitations and Challenges
While each model presents robust performance and innovative features, they are not without limitations.
GPT-OSS-120B
The primary constraint with GPT-OSS-120B is its reliance on a streamlined activation mechanism. Although beneficial for reducing computational overhead, the relatively low active parameter count may limit the model’s depth in handling ultra-complex queries. Additionally, its focus on English-centric reasoning tasks means it occasionally lags in multilingual nuances compared to models specifically optimized for that purpose.
Qwen3-235B-A22B-2507
Despite its impressive long-context handling and dual-variant structure, Qwen3-235B-A22B-2507’s extensive resource requirements pose a potential barrier to adoption in resource-limited environments. The model’s differentiation between “Thinking” and “Instruct” variants may also lead to occasional misfires where a task’s requirements fall in-between the two optimization strategies. Furthermore, the enormous token window, while a technological marvel, necessitates careful management to avoid runaway memory and latency issues in deployment settings.
DeepSeek-R1
With its sheer scale and reliance on reinforcement learning, DeepSeek-R1 can be computationally expensive to deploy and fine-tune. Although its self-verification capabilities provide an edge in robustness during complex tasks, these same features add to the model’s latency in time-critical applications. Moreover, while the licensing is permissive and the ecosystem is growing, the operational complexity introduced by the iterative refinement process demands expertise both in hardware orchestration and in tailoring RL strategies to domain-specific tasks.
Comparative Synthesis and Future Outlook
The comparisons drawn herein underscore that the choice of a language model must be guided by specific application requirements and resource considerations.
For developers and researchers with limited hardware availability who still require robust reasoning capabilities, GPT-OSS-120B offers a compelling blend of efficiency and performance. Its design ensures that advanced language understanding can be achieved without necessitating an extensive computational budget—a quality that positions it as a potential workhorse for academic and startup environments alike.
Conversely, for applications where long-context processing, multilingual capability, and the ability to fine-tune based on the task (via distinct variants) are paramount, Qwen3-235B-A22B-2507 proves to be a formidable candidate. Its dual-path strategy not only caters to varying task-specific requirements but also fosters innovation in environments that demand a high degree of adaptability, such as global enterprises and research institutions with varied linguistic needs.
DeepSeek-R1, on the other hand, represents the pinnacle of iterative reasoning and model refinement. Its heavy parameterization and integration of reinforcement learning make it ideally suited for applications where the stakes are particularly high—scenarios where self-correction and a deep, iterative chain-of-thought process are non-negotiable. Despite its higher operational costs, DeepSeek-R1’s promise in revolutionizing problem-solving accuracy and adaptability offers a tantalizing glimpse into the future of LLM capabilities, especially as further optimizations in hardware and RL strategies are likely to reduce deployment complexities.
Looking ahead, the evolution of these models is expected to continue along multiple dimensions. Innovations in hardware acceleration, more efficient quantization techniques, and further refinements in dynamic routing are set to influence the next generation of LLMs. Additionally, the expanding ecosystem around these open-weight models promises to further democratize access, enabling a broader array of real-world applications—from personalized medicine and regulatory compliance to automated creative content generation.
Conclusion
OpenAI’s gpt-oss-120b, Qwen3-235B-A22B-2507, and DeepSeek-R1 each represent a significant milestone in the evolution of large language models. Their diverse architectural innovations—from efficient MoE designs and advanced tokenization techniques to reinforcement learning-based self-verification—underscore a vibrant landscape of technological progress.
GPT-OSS-120B excels in resource-sensitive environments where rapid reasoning and efficient inference are vital, serving as an accessible solution for many research and startup applications. Qwen3-235B-A22B-2507, with its dual-variant architecture and unrivaled long-context processing, caters to both complex reasoning and extensive multilingual applications, making it particularly appealing for global enterprises and academic research projects.
DeepSeek-R1, through its iterative self-correction and scalable reinforcement learning strategies, sets a new standard for high-stakes, accuracy-driven tasks by pushing the boundaries of what is achievable with current hardware and training methodologies.
Each model’s performance benchmark—spanning MMLU, GSM8K, HumanEval, and beyond—reinforces the idea that no single design dominates every scenario; rather, these innovations offer complementary strengths tailored to distinct application domains. As the field continues to mature, their respective licensing, ecosystem integrations, and developer communities will play an increasingly important role in shaping the future of intelligent systems.
Ultimately, the choice among these models depends on a careful evaluation of the intended application’s requirements, computational constraints, and desired performance metrics. Whether it is the lean efficiency of GPT-OSS-120B, the versatile, long-context mastery of Qwen3-235B-A22B-2507, or the iterative, self-improving intelligence of DeepSeek-R1, these models stand as robust tools ready to propel both academic inquiry and commercial innovation.
For further updates, discussions, and technical deep-dives, refer to the official documentation and community forums on OpenAI, Hugging Face, and the DeepSeek GitHub repository. As breakthroughs continue to emerge, keeping abreast of these developments is not only intellectually stimulating but also crucial for harnessing the full potential of artificial intelligence in the real world.
This comprehensive comparison of GPT-OSS-120B, Qwen3-235B-A22B-2507, and DeepSeek-R1 demonstrates that, while each model is rooted in similar fundamental principles, their divergent architectural innovations and performance metrics cater to varied application landscapes.
As adoption accelerates and further advancements are integrated, these models are set to redefine the limits of what is achievable in natural language processing, paving the way for a future where large-scale reasoning and creative problem solving become the norm.
Want your AI product explained to a large AI-native audience?
Kingy AI helps AI companies turn complex products into clear, useful YouTube videos that drive awareness, product understanding, demos, clicks, and search visibility.
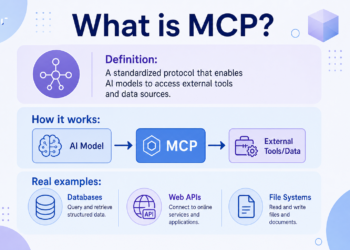




Thorough model comparison — the structured breakdown across reasoning, coding, and multilingual tasks makes it easy to see where each model has an edge. The open-source angle is important too; for teams that need control over their inference stack, model choice looks different than for API consumers. One thing the comparison touches on implicitly: the image generation side is evolving just as fast. GPT Image 2 (the image counterpart) has had a similar step-change moment. For developer stacks that need both language and image capabilities, combining open-source LLMs with purpose-built image APIs like Nano Banana API is a common pattern. Excellent reference piece.