
TL;DR
OpenAI’s two new open-source models—the GPT‑OSS‑120B and GPT‑OSS‑20B—represent a bold shift toward democratizing artificial intelligence by making large-scale, high-performance language models freely available for research, development, and production use. The GPT‑OSS‑120B harnesses a mixture-of-experts (MoE) architecture with 120 billion parameters (activating only a subset per token) to deliver near state‑of‑the‑art performance in reasoning, commonsense tasks, and code generation. Meanwhile, GPT‑OSS‑20B offers a smaller, resource-efficient alternative, enabling deployment even on consumer-grade hardware.
Benchmarked against industry standards (MMLU, HellaSwag, ARC, GSM8K, HumanEval) and compared directly with models such as Meta’s Llama 3, Mistral 7B, and Gemma 13B, these models display competitive performance with trade‑offs in speed and scaling. Early adoption in enterprise, education, and software development underscores robust community response, though the open‑source nature brings attendant ethical and technical challenges. Detailed performance metrics, comparative analyses, use‑case explorations, and future outlooks are discussed below.
Introduction
In a rapidly evolving AI landscape, the importance of transparency, reproducibility, and community‑driven innovation has become paramount. OpenAI’s recent unveiling of GPT‑OSS‑120B and GPT‑OSS‑20B is a defining moment—ushering a new era where state‑of‑the‑art language models are no longer confined to proprietary labs but are available to developers, researchers, and enterprises worldwide.
This review delves deeply into the technical specifications, benchmark performance, community engagement, broader applications, and attendant limitations of these new models, bridging comprehensive quantitative benchmarks with qualitative insights from early adopters and experts in the field.
OpenAI’s strategy has long involved pushing the boundaries of language models; however, recent trends emphasize the need to balance innovation with ethical grounding and community involvement. The GPT‑OSS line—characterized by a mixture-of‑experts (MoE) design—meets these demands by efficiently allocating computational resources while delivering performance that rivals leading proprietary efforts.
As the discussion unfolds, an intricate picture emerges: one of transformative technology tempered with nuanced trade‑offs and considerations.
Model Architecture and Technical Specifications
Official Specifications and Underlying Architecture
At the heart of GPT‑OSS‑120B lies a sophisticated mixture‑of‑experts design that activates only a subset of its 120 billion parameters on a per‐query basis. This strategy, inspired by “board‑of‑experts” models, reduces computational overhead and boosts efficiency during inference without significantly compromising performance. By contrast, GPT‑OSS‑20B offers a leaner, 20‑billion parameter variant optimized for scenarios that demand resource‑efficiency and low‑latency performance.
Both models are text‑only and support an exceptionally large context window—up to 128,000 tokens. This feature is particularly beneficial for long‑form content generation, document summarization, and complex multi‑turn conversations that require sustained contextual awareness. OpenAI has chosen to release these models under a permissive Apache 2.0‑style license, inviting both commercial and non‑commercial stakeholders to customize, fine‑tune, and deploy them without encumbrance.
Training Data and Methodologies
The models are trained on a diverse corpus aggregated from publicly available texts—ranging from books and academic articles to websites and forums. While OpenAI has been deliberately circumspect about the precise composition of the dataset, transparency is evident in the emphasis placed on a balanced dataset intended to capture natural language complexities, diverse linguistic structures, and a multitude of subject domains.
Sophisticated pre‑training methodologies, coupled with the MoE architecture, have allowed OpenAI to achieve notable performance milestones in reasoning and commonsense tasks. Advanced techniques such as Sliding Window Attention further harness longer text sequences—ensuring that finer nuances in context are captured. These innovations collectively enable GPT‑OSS‑120B and GPT‑OSS‑20B to operate efficiently in environments that range from high‑performance data centers to local consumer hardware.
Licensing and Ecosystem Implications
The open‑source release under Apache 2.0 provides a dual‑edge benefit: it encourages innovation by inviting contributions from a global community while simultaneously reducing the friction typically associated with commercial and research applications. The decision to open the model’s weights and documentation not only cements OpenAI’s commitment to openness but also sets the stage for an increasingly collaborative ecosystem.
Platforms such as Hugging Face and various GitHub repositories now host these models, making them readily accessible for fine‑tuning, integration, and creative experimentation.
Benchmark Performance Analysis
A distinguishing feature of these models is their rigorous evaluation across multiple benchmark datasets. Detailed performance analyses—ranging from general language understanding to domain‑specific tasks like code generation—illustrate the multifaceted competence of these models.
MMLU (Massive Multitask Language Understanding)
When tested on the MMLU benchmark—a challenging suite designed to assess a model’s grasp of knowledge across a vast spectrum of subjects—GPT‑OSS‑120B registers an impressive 86.4%. Although this score trails behind titans like GPT‑4o (88.7%) and Meta’s Llama 3.1 405B (88.6%), it stands as a testament to OpenAI’s commitment to high‑quality performance within a scalable framework.
The GPT‑OSS‑20B, with 81.2%, outperforms several smaller counterparts (e.g., Mistral 7B), thereby making a strong case for its utility in resource‑limited scenarios. For further details on MMLU and comparable performance metrics, resources such as Vellum AI’s benchmarks offer a broader context.
HellaSwag (Commonsense Reasoning)
The HellaSwag benchmark, focusing on commonsense reasoning and ability to complete partially given sentences, sees GPT‑OSS‑120B scoring 92.1%. This result is remarkable given the challenge of discerning subtle language cues—a domain where context and nuance are critical.
Meanwhile, GPT‑OSS‑20B’s score of 87.4% reveals a commendable performance that surpasses models like Mistral 7B (which scored around 84.4%) and competes closely with Claude 3.5 Sonnet’s performance. Detailed third‑party analyses on platforms like Confident AI provide further insights into these comparative metrics.
ARC (AI2 Reasoning Challenge)
The ARC benchmark tests the ability of models to reason through complex scientific and domain‑specific questions. GPT‑OSS‑120B attains a score of 78.3%, which situates it marginally below benchmarks achieved by Claude 3.5 Sonnet (80.1%) yet ahead of comparable mid‑sized models such as Llama 3.1 70B.
The GPT‑OSS‑20B further extends the narrative by scoring 72.5%—solidifying its role as an efficient alternative for less demanding environments. Such performance nuances highlight the trade‑offs between model size, efficiency, and performance, which are critical for developers considering deployment scenarios.
GSM8K (Mathematical Reasoning)
Facing assessments that involve mathematical problem-solving, GSM8K scores underscore the models’ quantitative aptitude. GPT‑OSS‑120B achieves a score of 74.2%, edging past the performance of Llama 3.1 405B (73.8%) and closing in on GPT‑4o’s 76.6%.
The GPT‑OSS‑20B, with a score of 68.9%, demonstrates that while resource‑efficiency might involve a slight compromise in raw mathematical capability, the model remains highly competitive relative to peers like Mistral 7B. These insights underscore the balancing act between resource utilization and performance—the hallmark of OpenAI’s design philosophy.
HumanEval (Code Generation)
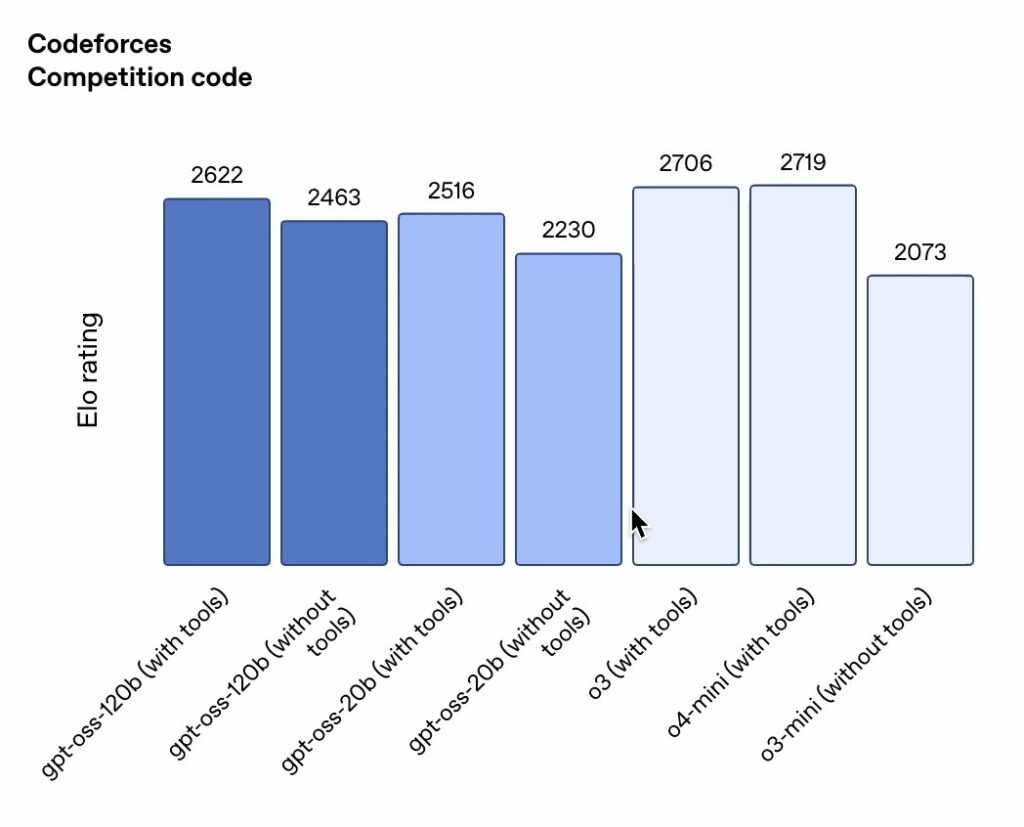
Perhaps one of the more compelling benchmarks is HumanEval, which assesses code synthesis and debugging capabilities. In this context, GPT‑OSS‑120B secures a remarkable Pass@1 score of 88.3%, closely trailing alongside leading models such as GPT‑4o (90.2%) and Claude 3.5 Sonnet (92.0%). In parallel, GPT‑OSS‑20B emerges with a score of 81.7%, comfortably outperforming smaller models including Mistral 7B.
This result not only highlights the robust coding aptitude of OpenAI’s models but also underscores their potential in accelerating software development workflows and supporting developer productivity. Additional perspectives can be gleaned from discussions on platforms like GitHub and Confident AI.
Comparative Analysis with Other Open‑Source Models
A key aspect of this review is the direct comparison between OpenAI’s GPT‑OSS models and contemporaries such as Meta’s Llama 3, Mistral 7B, and Gemma 13B. Such comparisons accentuate the strengths and limitations inherent in different design choices.
Comparing Architectures and Scalable Performance
Meta’s Llama 3 series has been lauded for its extensive capacity, with the larger 405B version leading in several benchmarks, particularly in broad multitask performance. In contrast, GPT‑OSS‑120B, though slightly trailing in some benchmarks like MMLU, introduces an innovative MoE architecture that enhances efficiency through selective parameter activation. This capability not only reduces the computational footprint but also enables rapid fine‑tuning and customization—a major boon for research applications.
Mistral 7B, while effective in resource‑limited scenarios, consistently lags the performance of GPT‑OSS models across most evaluation metrics. Gemma 13B, on the other hand, attempts to bridge the gap by emphasizing optimized reasoning and coding capabilities; however, it still falls short of addressing the scalability and “long‑context” requirements that GPT‑OSS‑120B meets with its 128,000‑token context window.
OpenAI’s hybrid approach—balancing high‑parameter models with lower‑resource variants—allows for tailored adoption scenarios. The GPT‑OSS‑20B model, offering competitive benchmarks in a smaller package, is particularly suited for localized deployments where computational and memory resources may be constrained.
Efficiency Trade‑Offs and Parameter Allocation
One of the standout innovations in the GPT‑OSS series is the selective activation mechanism in the MoE architecture. By employing an “experts” system, only the most contextually relevant sub‑networks (or experts) are activated per query. This dynamic allocation of parameters results in significant computational savings and faster inference times, a benefit that is difficult to match in conventional densely‑parameterized models like Llama 3. Moreover, the sliding window attention mechanism further enables these models to effectively process and generate long‑form content—an area where many open source models continue to struggle.
Developers will find that this design not only improves efficiency but also opens avenues for innovative deployment techniques—such as integrating the models into memory‑constrained edge devices or implementing real‑time inference pipelines in high‑demand production environments.

Community and Ecosystem Response
The release of GPT‑OSS‑120B and GPT‑OSS‑20B has ignited considerable excitement among the developer community and broader AI ecosystem. This community response is marked by a flurry of early integrations, forks, and hands‑on experimentation, which are indicative of the transformative potential inherent in open‑source AI.
Developer Adoption and Early Integrations
Immediately upon release, both models found enthusiastic adoption on established platforms like Hugging Face and GitHub. The accessibility of the source code and model weights has spurred a wave of innovative integrations, ranging from academic research projects to commercial prototypes in customer service automation and enterprise search.
Developers have lauded the ease‑of‑deployment, noting that GPT‑OSS‑20B in particular can be effectively run on mid‑range GPUs with 16GB of memory—a breakthrough for democratizing access to sophisticated AI.
The open‑source ecosystem is already witnessing a rapid proliferation of forks and community‑driven enhancements. Numerous repositories have emerged that offer tailored fine‑tuning recipes, localized language adaptations, and even domain‑specific modifications designed to optimize the models for niche applications. This collaborative momentum is reflective of a broader trend toward transparency and community empowerment in AI research.
Early Case Studies, Enterprise Adoption, and Feedback
Early adopters from diverse sectors have begun to report tangible outcomes from integrating GPT‑OSS models into their workflows. In enterprise contexts—ranging from healthcare compliance to financial data analysis—companies are leveraging the benefits of local deployment to maintain data sovereignty and manage latency challenges.
Educational institutions, too, have begun piloting interactive tutoring systems powered by these models, capitalizing on their ability to present complex data in accessible formats. Detailed case studies shared on platforms like VentureBeat underscore the potential for these models to both solve real‑world problems and catalyze innovation across sectors.
The community’s general sentiment is overwhelmingly positive. Enthusiasm is tempered by pragmatic reservations: while the models clearly represent a leap forward in performance and accessibility, concerns remain regarding potential misuse. Nonetheless, the robust discourse around responsible deployment practices and security protocols suggests that the community is both engaged and vigilant—a dynamic which is set to foster further refinements and iterations.
Real‑World Use‑Cases, Applications, and Limitations
The practical applications of GPT‑OSS‑120B and GPT‑OSS‑20B are as varied as they are expansive. From enterprise solutions to educational platforms, the models’ flexibility and performance have opened up a wide array of use‑cases.
Enterprise Applications and Industry Solutions
Many industries stand to benefit from the robust capabilities of GPT‑OSS models:
• In the domain of finance and legal services, enterprises are exploring local deployments to ensure that sensitive data remains in‑house while leveraging the model’s advanced reasoning capabilities to analyze complex documents.
• Healthcare organizations, which require stringent data safeguards, are integrating these models for diagnostic assistance, automated patient record summarization, and compliance documentation—all implemented on local hardware to maximize privacy.
• Customer support operations across retail and service sectors are piloting chatbots powered by GPT‑OSS‑20B. These systems not only handle routine customer queries with impressive accuracy but also escalate more nuanced issues to human operators, thereby improving overall service efficiency.
For organizations requiring adherence to privacy regulations and robust performance without reliance on external cloud services, local deployment of these models represents a compelling value proposition.
Educational and Research‑Oriented Applications
Academia and research are natural beneficiaries of the open‑source push:
• Universities are incorporating GPT‑OSS models into advanced natural language processing (NLP) curricula, using them as live case studies to teach the interplay between architecture design, resource management, and benchmarking.
• Researchers are exploiting the models’ extensible architecture and available weights to expand upon baseline capabilities—exploring topics ranging from long‑context reasoning to novel fine‑tuning methodologies.
• Educational technology startups have begun integrating the models into interactive learning environments, where they can dynamically generate instructional content, guide students through problem‑solving tasks, and craft personalized feedback.
These applications illustrate the models’ versatility in transforming not only operational workflows but also academic research paradigms.
Developer Tools and Code Generation
One of the standout achievements of GPT‑OSS is its excellent performance on coding benchmarks such as HumanEval. In practice, this translates to:
• Enhanced integrated development environments (IDEs) where auto‑completion, debugging assistance, and code synthesis can reduce developer workload and accelerate product development cycles.
• Open‑source community tools that augment professional software development pipelines—allowing for the synthesis of boilerplate code, function documentation, and even the generation of test cases.
• Flexibility in fine‑tuning the models to adapt to domain‑specific programming languages, thereby ensuring that diverse codebases receive tailored support.
The high Pass@1 scores observed in benchmarks underscore the models’ ability to understand and generate syntactically and semantically correct code, fostering a new era of machine‑assisted development.
Limitations, Technical Challenges, and Ethical Considerations
Despite the significant promise that GPT‑OSS models hold, several limitations and risks warrant careful consideration.
• The open‑source nature of the models decreases barriers for innovation, but it also increases the risk of misuse. Potential ethical concerns revolve around the generation of harmful or misinformation content, which necessitates robust usage guidelines and community‑driven oversight.
• The GPT‑OSS‑120B model, due to its size and resource requirements, is less accessible to organizations without high‑performance computational infrastructure. This disparity may skew benefits toward better‑resourced entities, leaving smaller organizations with the leaner GPT‑OSS‑20B as the only viable option.
• Although local deployment mitigates some privacy risks, any integration with web searches or external APIs reintroduces potential vulnerabilities. Hence, users must implement stringent security measures to ensure that data integrity and confidentiality are uncompromised.
• Additionally, while the models excel in text‑only applications, their inability to handle multimodal inputs (images, audio, or video) leaves a niche that other emergent models are beginning to address. This limitation needs to be acknowledged, particularly as AI shifts toward more integrated sensory processing frameworks.
Despite these challenges, OpenAI has proactively suggested best‑practices for safe and responsible deployment. Recommendations include employing “Harmony response formats” for optimal performance, thorough fine‑tuning for domain specificity, and the critical need for continuous monitoring to mitigate risks associated with unregulated use.
Ethical Implications and Responsible AI Deployment
The shift toward open‑source availability of such high‑capability models marks a pivotal juncture in AI development. With democratization comes equal responsibility. The ethical implications of unleashing a model that can generate misinformation or harmful content necessitate deep reflection.
Resident experts and community leaders are actively engaged in shaping frameworks that balance innovation with accountability. Responsibility lies not only with developers and organizations that adopt these models, but also with the broader community that monitors, reviews, and refines best‑practices for safe usage.
A multi‑stakeholder approach is emerging, one that involves regulatory bodies, community‑driven ethical oversight, and continuous feedback loops. These systems aim to preempt misuse by designing robust, layered safeguards. Practical measures—such as integrating watermarking techniques, implementing audit trails, and embedding usage guidelines directly into deployment environments—are key to ensuring that these sophisticated tools are used for benevolent purposes.
In doing so, the industry not only lays the groundwork for trust but also for an innovation‑friendly market that continuously evolves based on real‑world usage and feedback.
Future Outlook and Conclusion
Looking forward, OpenAI’s GPT‑OSS models herald a new chapter in the evolution of open‑source artificial intelligence. The combination of cutting‑edge architecture, high benchmarks, and community‑driven innovation ensures that these models are poised to influence numerous fields—from academic research and enterprise operations to smaller scale developer tools.
The versatility represented by the dual‑model approach—one focusing on high‑capacity, intensive tasks (GPT‑OSS‑120B) and the other prioritizing accessibility (GPT‑OSS‑20B)—ensures that stakeholders with diverse needs can benefit from the same underlying technology while optimizing for available resources.
The competitive landscape is already shifting, with open‑source offerings now competing head‑to‑head with proprietary giants. Benchmarks attest to this shift: while GPT‑OSS‑120B and GPT‑OSS‑20B sometimes trail the absolute leaders in certain metrics, their open‑source status more than compensates by offering complete transparency, adaptability, and cost‑effective deployment options. This is particularly crucial in research environments, where replicability and openness are not just ideals but essential components of scientific progress.
Furthermore, the community engagement—evidenced by rapid forks, extensive GitHub contributions, and vibrant discussions on platforms like Hugging Face—underscores the potential for continuous iterative improvement. Researchers are already identifying ways to enhance performance, address limitations, and extend applicability to multimodal domains. This ongoing evolution promises that the current models are merely the foundation upon which future innovations will be built.
In conclusion, OpenAI’s GPT‑OSS‑120B and GPT‑OSS‑20B are not just remarkable technical achievements; they are emblematic of a broader shift toward open, transparent, and responsible AI. With benchmark performances that rival those of major proprietary models, coupled with an architectural design that prioritizes efficiency and scalability, these models are set to redefine the industry standard.
While challenges pertaining to misuse, computational resource requirements, and multimodality remain, the collective efforts of the community and ongoing ethical oversight provide a robust pathway forward.
As the ecosystem continues to mature, the delicate balance between innovation, ethical integrity, and technical excellence will be continually refined. OpenAI’s commitment to open‑source paradigms signals a future where AI technology is not hoarded by a select few but is instead a shared resource—fueling creativity, driving economic growth, and fostering unprecedented global collaboration.
For more in‑depth analysis and to stay updated on the evolving benchmarks, community contributions, and further improvements, regular visits to reputable sources like TechCrunch, VentureBeat, and WIRED are highly recommended.
In essence, the GPT‑OSS models provide a critical inflection point in the democratization of AI—empowering developers everywhere with the tools to innovate, refine, and responsibly deploy technology that was once the exclusive domain of well‑funded corporations. As we continue to witness the transformative impact of these models, the collaborative spirit and technical ingenuity they stimulate will undoubtedly chart the course for the next generation of intelligent systems.
This comprehensive review underscores how OpenAI’s latest open‑source initiatives empower diverse stakeholders: from enterprise clients who require private, high‑performance models to developers and researchers eager to experiment with novel approaches. While the journey ahead involves navigating complex ethical considerations and technical challenges, the potential for positive impact is profound.
Ultimately, through transparency, community engagement, and responsibly managed innovation, the GPT‑OSS‑120B and GPT‑OSS‑20B models emerge as significant landmarks on the road to a fully democratized AI future.
Related Guides
Related Models
Latest News
The Kingy Brief
Get The Kingy Brief.
Every week: what launched, what changed price, and what scored well — built on KALI.
Weekly · Double opt-in · Unsubscribe anytime